все новости по филиалам
Поиск

Объедините ваше частное облако с вашим Active Directory
Федерация — это бета-функция, предлагаемая всем пользователям OVH Private Cloud с vCenter 6.5. Если вы хотите принять участие в бета-тестировании, свяжитесь с нашей службой поддержки. Это позволяет использовать внешний Microsoft Active Directory в качестве источника аутентификации для доступа к серверу VMware vCenter. Реализация этой функции стала возможной благодаря команде DevOps OVH, которая разработала инновационный и уникальный API, который добавляет дополнительные функции к тем, которые предлагает VMware. Действительно, в настоящее время невозможно настроить источники удостоверений через собственный API vCenter.
Зачем?
По умолчанию права доступа к vCenter в частном облаке управляются непосредственно этим vCenter. Пользователи создаются локально (localos или домен SSO), а все механизмы управления на основе доступа (RBAC) управляются службой SSO. Включение федерации делегирует управление пользователями в Microsoft Active Directory (AD). В результате сервер vCenter будет взаимодействовать с контроллером домена, чтобы гарантировать, что пользователь, пытающийся подключиться, является тем, кем он себя считает. VCenter сохраняет управление ролями и привилегиями для объектов, которыми он управляет. После настройки федерации можно связать пользователей AD с ролями vCenter, чтобы они могли получать доступ и / или управлять определенными объектами в инфраструктуре (виртуальные машины, сети, папки и т. Д.).
Одним из основных применений этого будет облегчение доступа vCenter для администраторов за счет сокращения количества учетных записей, необходимых для поддержки различных элементов инфраструктуры. Кроме того, станет возможным расширить и унифицировать политику управления паролями между Active Directory и vCenter Private Cloud.
Тот факт, что Федерацией можно управлять через API OVH, позволяет автоматизировать конфигурацию, а также обеспечить ее поддержание в рабочем состоянии. Наконец, очень просто добавить проверки в любой инструмент мониторинга (Nagios, Zabbix, Sensu и т. Д.), Чтобы отслеживать состояние Федерации и права, назначенные пользователям.
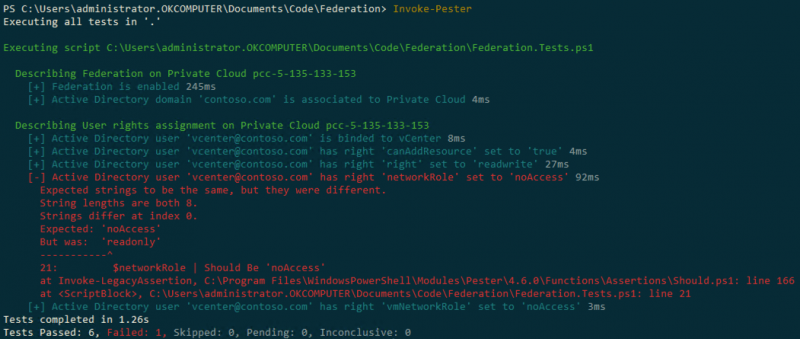
Вот пример простого скрипта PowerShell, который будет периодически проверять, находится ли конфигурация федерации в желаемом состоянии:
Архитектура и предпосылки
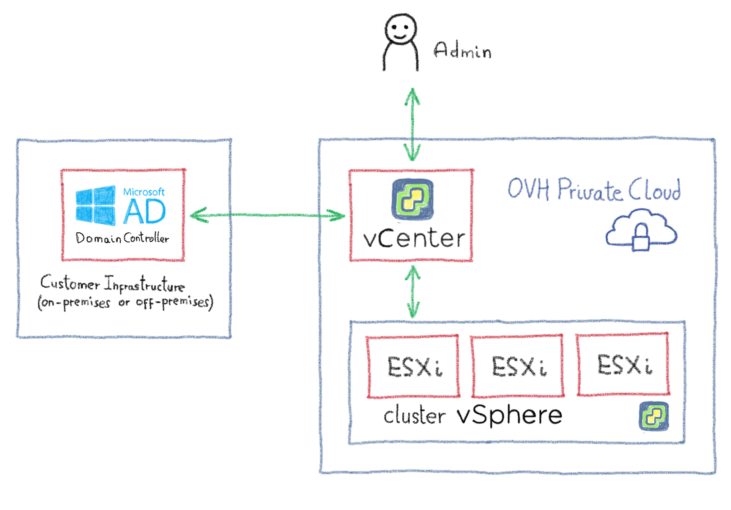
Поскольку vCenter должен будет обмениваться данными с контроллерами домена, первым шагом будет разрешение потоков между этими элементами. Есть несколько способов достижения этой цели, например, объединение OVHCloud Connect с частным шлюзом. Изучение всех этих возможностей потребует целой статьи, поэтому мы советуем вам связаться с OVH или одним из наших партнеров, чтобы помочь вам выбрать наиболее подходящую архитектуру. Следующая диаграмма дает вам упрощенный обзор того, как это может выглядеть:
После подключения вам необходимо убедиться, что вы собрали следующую информацию перед началом процесса настройки:
Активация и настройка
Как только вы соберете всю необходимую информацию, появится возможность активировать и настроить Федерацию. Операция будет проходить в три этапа:
Включение соединения между AD и частным облаком
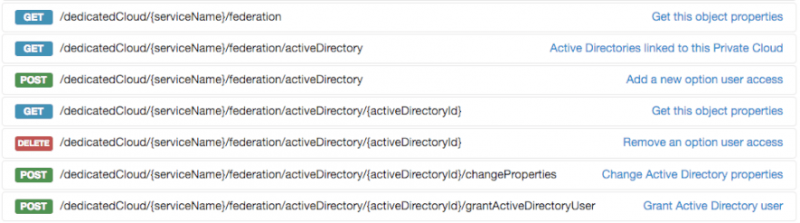
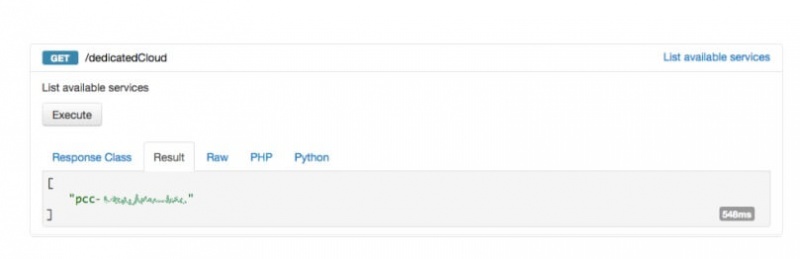
Перейдите на сайт обозревателя API и выполните аутентификацию, используя свои учетные данные OVH. Если у вас его еще нет, получите имя (также называемое serviceName в API) вашего частного облака, так как оно будет обязательным для всех остальных этапов настройки. Вы можете получить доступ к этой информации, выполнив GET для /edicCloud URI:
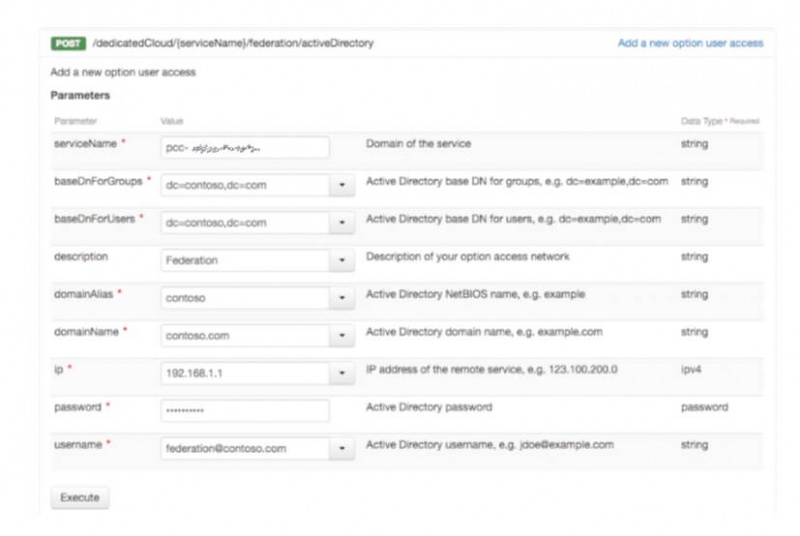
Включите федерацию, предоставив всю информацию о вашей Active Directory через POST в URI /edicCloud / {имя_службы} / federation / activeDirectory. Вся запрашиваемая информация обязательна:
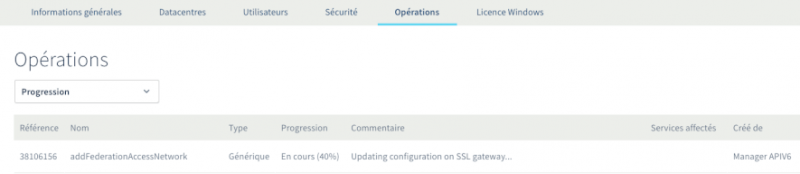
Активация федерации займет некоторое время и пройдет в фоновом режиме. Вы можете следить за ходом операции через панель управления OVH:
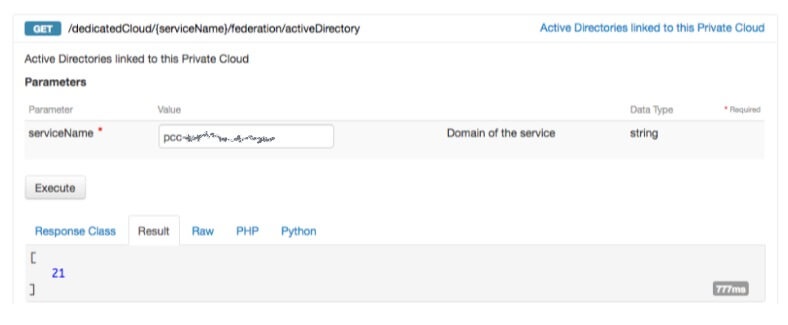
По завершении вы можете получить идентификатор федерации, отправив запрос GET на URI-адрес /edicCloud / {имя-службы} / federation / activeDirectory:
Связывание одного или нескольких пользователей AD
Теперь, когда ваша AD объявлена в vCenter Private Cloud, мы сможем привязать к ней пользователей Active Directory. Обратите внимание, что даже если ваши пользователи связаны, у них не будет связанных ролей vCenter, поэтому они не смогут войти в систему.
Чтобы связать пользователя, вам нужно будет отправить запрос POST в URI /edicCloud / {имя_службы} / federation / activeDirectory / {activeDirectory} / grantActiveDirectoryUser, указав полное имя пользователя:
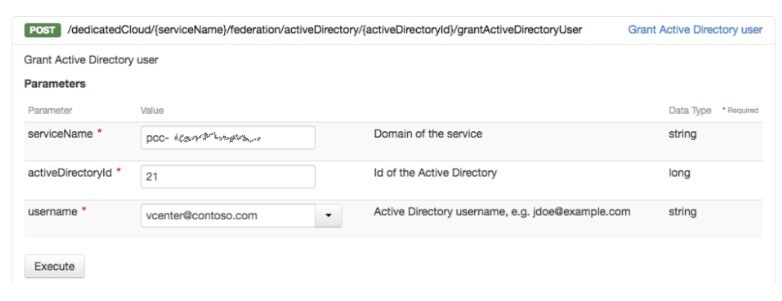
Убедитесь, что пользователь присутствует в поисковом подразделении, которое вы указали при сопоставлении вашей AD с vCenter. Еще раз, вы можете проверить, что задача импорта выполняется через API или через панель управления:

Назначение прав доступа
Последним шагом будет предоставление пользователям прав доступа к различным объектам в виртуальной инфраструктуре. Этот шаг не отличается от обычного способа управления правами пользователей Private Cloud. Это можно сделать через API или панель управления OVH.

Теперь вы сможете войти в vCenter с пользователями вашей AD и начать управлять своим частным облаком!
Зачем?
По умолчанию права доступа к vCenter в частном облаке управляются непосредственно этим vCenter. Пользователи создаются локально (localos или домен SSO), а все механизмы управления на основе доступа (RBAC) управляются службой SSO. Включение федерации делегирует управление пользователями в Microsoft Active Directory (AD). В результате сервер vCenter будет взаимодействовать с контроллером домена, чтобы гарантировать, что пользователь, пытающийся подключиться, является тем, кем он себя считает. VCenter сохраняет управление ролями и привилегиями для объектов, которыми он управляет. После настройки федерации можно связать пользователей AD с ролями vCenter, чтобы они могли получать доступ и / или управлять определенными объектами в инфраструктуре (виртуальные машины, сети, папки и т. Д.).
Одним из основных применений этого будет облегчение доступа vCenter для администраторов за счет сокращения количества учетных записей, необходимых для поддержки различных элементов инфраструктуры. Кроме того, станет возможным расширить и унифицировать политику управления паролями между Active Directory и vCenter Private Cloud.
Тот факт, что Федерацией можно управлять через API OVH, позволяет автоматизировать конфигурацию, а также обеспечить ее поддержание в рабочем состоянии. Наконец, очень просто добавить проверки в любой инструмент мониторинга (Nagios, Zabbix, Sensu и т. Д.), Чтобы отслеживать состояние Федерации и права, назначенные пользователям.
Вот пример простого скрипта PowerShell, который будет периодически проверять, находится ли конфигурация федерации в желаемом состоянии:
Архитектура и предпосылки
Поскольку vCenter должен будет обмениваться данными с контроллерами домена, первым шагом будет разрешение потоков между этими элементами. Есть несколько способов достижения этой цели, например, объединение OVHCloud Connect с частным шлюзом. Изучение всех этих возможностей потребует целой статьи, поэтому мы советуем вам связаться с OVH или одним из наших партнеров, чтобы помочь вам выбрать наиболее подходящую архитектуру. Следующая диаграмма дает вам упрощенный обзор того, как это может выглядеть:
После подключения вам необходимо убедиться, что вы собрали следующую информацию перед началом процесса настройки:
- Ваши учетные данные OVH (ник и пароль)
- Название вашего частного облака (в форме pcc-X-X-X-X)
- Требуемая информация об инфраструктуре Active Directory, а именно:
- Короткое и длинное имя домена Active Directory (например, contoso и contoso.com)
- IP-адрес контроллера домена
- Имя пользователя и пароль учетной записи AD с достаточными правами для просмотра каталога
- Расположение групп и пользователей в иерархии AD как «базовое DN» (пример: OU = Users, DC = contoso, DC = com). Следует отметить, что хотя информация о группе является обязательной, в настоящее время ее невозможно использовать для управления аутентификацией.
- Список пользователей Active Directory, которых вы хотите привязать к vCenter. Необходимо будет указать имена пользователей в форме username@FQDN.domain (например, federation@contoso.com).
Активация и настройка
Как только вы соберете всю необходимую информацию, появится возможность активировать и настроить Федерацию. Операция будет проходить в три этапа:
- Активация связи между Active Directory и частным облаком
- Привязка одного или нескольких пользователей AD к частному облаку
- Назначение прав пользователям
Включение соединения между AD и частным облаком
Перейдите на сайт обозревателя API и выполните аутентификацию, используя свои учетные данные OVH. Если у вас его еще нет, получите имя (также называемое serviceName в API) вашего частного облака, так как оно будет обязательным для всех остальных этапов настройки. Вы можете получить доступ к этой информации, выполнив GET для /edicCloud URI:
Включите федерацию, предоставив всю информацию о вашей Active Directory через POST в URI /edicCloud / {имя_службы} / federation / activeDirectory. Вся запрашиваемая информация обязательна:
Активация федерации займет некоторое время и пройдет в фоновом режиме. Вы можете следить за ходом операции через панель управления OVH:
По завершении вы можете получить идентификатор федерации, отправив запрос GET на URI-адрес /edicCloud / {имя-службы} / federation / activeDirectory:
Связывание одного или нескольких пользователей AD
Теперь, когда ваша AD объявлена в vCenter Private Cloud, мы сможем привязать к ней пользователей Active Directory. Обратите внимание, что даже если ваши пользователи связаны, у них не будет связанных ролей vCenter, поэтому они не смогут войти в систему.
Чтобы связать пользователя, вам нужно будет отправить запрос POST в URI /edicCloud / {имя_службы} / federation / activeDirectory / {activeDirectory} / grantActiveDirectoryUser, указав полное имя пользователя:
Убедитесь, что пользователь присутствует в поисковом подразделении, которое вы указали при сопоставлении вашей AD с vCenter. Еще раз, вы можете проверить, что задача импорта выполняется через API или через панель управления:
Назначение прав доступа
Последним шагом будет предоставление пользователям прав доступа к различным объектам в виртуальной инфраструктуре. Этот шаг не отличается от обычного способа управления правами пользователей Private Cloud. Это можно сделать через API или панель управления OVH.
Теперь вы сможете войти в vCenter с пользователями вашей AD и начать управлять своим частным облаком!
Генеральный директор OVH предлагает европейскую альтернативу публичным облачным гигантам США
Через шесть месяцев после своего пребывания на посту генерального директора OVH Мишель Полен излагает работу, которую делает фирма, чтобы выделиться из общей массы публичных облаков благодаря локальному знанию европейского ландшафта защиты данных и учетных данных с открытым исходным кодом.
Кэролайн Доннелли
Старший редактор, Великобритания
В то время как Amazon, Microsoft и Google могут казаться, что рынок публичных облаков зашит весь, есть ряд других (предположительно меньших) провайдеров в этом пространстве, которые также борются за внимание C-suite.
Главным из них является парижский игрок OVH, работающий в сфере инфраструктуры как услуги (IaaS), который последние несколько лет строил свое присутствие за пределами своей родины, открывая центры обработки данных в Лондоне, Сингапуре, Сиднее и США.
Он также повысил свой авторитет благодаря приобретениям, таким как бизнес VMware vCloud Air IaaS еще в 2017 году, что также помогло увеличить его глобальный охват центра обработки данных.
В настоящее время компания находится в процессе позиционирования на рынке для своего предложения в публичном облаке, уделяя особое внимание учетным данным своего предприятия, открытым исходным кодом и конфиденциальности данных, а также расширению своего присутствия во всем мире.
За этой работой наблюдает генеральный директор Мишель Полен, который присоединился к OVH около шести месяцев назад с (весьма) конкретной целью — создать фирму в качестве европейской альтернативы крупнейшим трем облачным провайдерам США, которые, как и они, присутствуют во всем мире.
По словам Полина, европейский провайдерский провайдер становится все более важным пунктом продажи услуг OVH, учитывая некоторые недавние изменения в законодательстве США в сфере защиты данных, которые побуждают организации переосмыслить свои стратегии размещения облачных данных.
Мишель Паулин, OVH
Расширяя эту тему, он указывает на принятие правительством США Акта о разъяснении законного использования данных за рубежом (он же Закон об облаке) в марте 2018 года, который позволяет правоохранительным органам запрашивать доступ к данным, хранящимся на серверах, размещенных в США. фирмы, в том числе серверы, расположенные за рубежом.
Как европейский поставщик, OVH освобождается от необходимости выполнять такие запросы, что немаловажно, говорит Полин.
Европейская альтернатива
Маркетинг «альтернативного провайдера» не сводится исключительно к OVH, узурпирующему Google, Amazon или Microsoft в привязанности к C-suite, хотя, признается Полин, приятно, когда это происходит.
Вместо этого, это больше связано с оказанием поддержки предприятиям, которые хотят реализовать многоблаковую стратегию.
Эта «обратимость», характерная для облака OVH, основана на приверженности фирмы использованию технологий с открытым исходным кодом, таких как операционная система OpenStack, которая является особенностью ее общедоступной облачной платформы.
Общедоступные облачные провайдеры, приветствующие поддержку открытого исходного кода как точку конкурентного различия, не являются чем-то новым. В течение последних 18 месяцев он стал постоянной темой для обсуждения в отрасли, чему способствовал, в немалой степени, корпоративный интерес к развертыванию в нескольких и гибридных облаках.
В конце концов, для предприятий, которые хотят смешивать и сопоставлять облачные сервисы и продукты конкурирующих поставщиков, функциональная совместимость, предоставляемая открытым исходным кодом, является большим плюсом для предприятий.
По словам Полина, поддержка OVH открытого исходного кода также важна, поскольку она помогает выровнять игровое поле, когда фирма конкурирует с более крупными конкурентами.
Кэролайн Доннелли
Старший редактор, Великобритания
В то время как Amazon, Microsoft и Google могут казаться, что рынок публичных облаков зашит весь, есть ряд других (предположительно меньших) провайдеров в этом пространстве, которые также борются за внимание C-suite.
Главным из них является парижский игрок OVH, работающий в сфере инфраструктуры как услуги (IaaS), который последние несколько лет строил свое присутствие за пределами своей родины, открывая центры обработки данных в Лондоне, Сингапуре, Сиднее и США.
Он также повысил свой авторитет благодаря приобретениям, таким как бизнес VMware vCloud Air IaaS еще в 2017 году, что также помогло увеличить его глобальный охват центра обработки данных.
В настоящее время компания находится в процессе позиционирования на рынке для своего предложения в публичном облаке, уделяя особое внимание учетным данным своего предприятия, открытым исходным кодом и конфиденциальности данных, а также расширению своего присутствия во всем мире.
За этой работой наблюдает генеральный директор Мишель Полен, который присоединился к OVH около шести месяцев назад с (весьма) конкретной целью — создать фирму в качестве европейской альтернативы крупнейшим трем облачным провайдерам США, которые, как и они, присутствуют во всем мире.
Большинство наших клиентов считают, что хорошим способом бросить вызов этим крупным игрокам является наличие альтернативных, инновационных решений на основе открытого исходного кода, которые хорошо позиционируются и имеют предсказуемую ценуговорит Полин в интервью Computer Weekly.
Поэтому сегодня мы считаем, что мы можем дать людям другой выбор по отношению к основным игрокам, таким как Amazon и Google, но также потому, что мы европейцы
По словам Полина, европейский провайдерский провайдер становится все более важным пунктом продажи услуг OVH, учитывая некоторые недавние изменения в законодательстве США в сфере защиты данных, которые побуждают организации переосмыслить свои стратегии размещения облачных данных.
Мы считаем, что мы можем дать людям другой выбор по отношению к основным игрокам, таким как Amazon и Google
Мишель Паулин, OVH
Расширяя эту тему, он указывает на принятие правительством США Акта о разъяснении законного использования данных за рубежом (он же Закон об облаке) в марте 2018 года, который позволяет правоохранительным органам запрашивать доступ к данным, хранящимся на серверах, размещенных в США. фирмы, в том числе серверы, расположенные за рубежом.
Как европейский поставщик, OVH освобождается от необходимости выполнять такие запросы, что немаловажно, говорит Полин.
Как мы видели в Европе, существует большая озабоченность по поводу конфиденциальности данных и защиты данных, а также того факта, что мы сегодня жалуемся на GDPR (Общее положение о защите данных), и тот факт, что мы не подпадаем под действие Закона об облаке или Патриотический закон означает, что мы можем предложить клиентам альтернативный подход к защите данных [в облаке]
Это дифференциатор, но это не единственный дифференциатор. Цена, открытость, обратимость и прозрачность — другие сильные отличия для нас
Европейская альтернатива
Маркетинг «альтернативного провайдера» не сводится исключительно к OVH, узурпирующему Google, Amazon или Microsoft в привязанности к C-suite, хотя, признается Полин, приятно, когда это происходит.
Вместо этого, это больше связано с оказанием поддержки предприятиям, которые хотят реализовать многоблаковую стратегию.
У нас есть клиенты, которые в основном используют OVH, а иногда и только OVH, и у нас есть клиенты, которые имеют AWS [Amazon Web Services] для некоторых своих приложений, но OVH для другихговорит он.
Мы не пытаемся придерживаться монопольного подхода и стараемся всегда предоставлять нашим клиентам выбор, поэтому мы позиционируем себя как альтернативу.
Конечно, когда клиент решает воспользоваться услугами OVH, мы очень гордимся этим, но если клиенты недовольны нашими услугами, они обратимы [поэтому они могут уйти], но мы уверены, что они достаточно хороши. чтобы люди захотели остаться
Эта «обратимость», характерная для облака OVH, основана на приверженности фирмы использованию технологий с открытым исходным кодом, таких как операционная система OpenStack, которая является особенностью ее общедоступной облачной платформы.
Общедоступные облачные провайдеры, приветствующие поддержку открытого исходного кода как точку конкурентного различия, не являются чем-то новым. В течение последних 18 месяцев он стал постоянной темой для обсуждения в отрасли, чему способствовал, в немалой степени, корпоративный интерес к развертыванию в нескольких и гибридных облаках.
В конце концов, для предприятий, которые хотят смешивать и сопоставлять облачные сервисы и продукты конкурирующих поставщиков, функциональная совместимость, предоставляемая открытым исходным кодом, является большим плюсом для предприятий.
По словам Полина, поддержка OVH открытого исходного кода также важна, поскольку она помогает выровнять игровое поле, когда фирма конкурирует с более крупными конкурентами.
С открытым исходным кодом у нас есть экосистема, в которой мы совместимы с любым видом открытого кода и открытым исходным кодом
an another colo is cleaned up


and an another colo cleaned up




OVH представляет собственный управляемый сервис Kubernetes
Kubernetes великолепен, но довольно сложен. Теперь OVH, поставщик услуг облачных вычислений и центров обработки данных, внедряет управляемую услугу Kubernetes. Это должно позволить клиентам легко использовать оркестровку с открытым исходным кодом в инфраструктуре OVH.
По сути, предложение, по словам Алена Фиокко, технического директора OVH, является постоянным кластерным контроллером. Клиенты, которые вносят свои правила использования компьютеров и ресурсов хранения, могут устанавливать их постоянно, даже если они не используют Kubernetes постоянно в OVH. Политика сохраняется.
Номера не нужны клиентам, этот контроллер. «Правда в том, заявляет Fiocco, что нам требуются сравнительно небольшие ресурсы от нас». Однако, как только клиенты используют ресурсы OVH для своего кластера Kubernetes, они платят за фактическое «потребление» или необходимые ресурсы. «В свою очередь, клиенты имеют доступ ко всему общедоступному облаку OVH», согласно CTO, а также к различным виртуальным машинам, например, в OpenStack или VMware.
Таким образом, предложение OVH должно характеризоваться несложным развертыванием, а также отказоустойчивыми и масштабируемыми приложениями. Тот, кто больше не нуждается в контроллере или правилах, хранящихся там и забывающих их, не нуждается в штрафах, как говорит Fiocco.
Предложение для разных потребителей Кубернеца
Kubernetes обещает общий стандарт для поставщиков гибридных и мультиоблачных услуг. Являясь одним из немногих сертифицированных поставщиков Cloud Native Computing Foundation (CNCF) в Европе, OVH решила выпустить альтернативу существующим вариантам Kubernetes. Предложение, которое теперь доступно, начинает OVH, чтобы расширить свой облачный портфель 18 октября 2018 года с частной бета-программой. Теперь управляемый сервис Kubernetes состоит из следующих компонентов:
Это то, что говорят клиенты
Например, клиенты получают кластер с гарантированной постоянной производительностью ЦП и ОЗУ, начиная с 26,18 евро (включая НДС) в месяц, а инфраструктура, состоящая из пяти рабочих узлов с общим объемом оперативной памяти 35 гигабайт и 10 vCores для 130,90. Евро (с учетом НДС) доступно в месяц. Для клиентов, которые хотят использовать Kubernetes и их контейнеры в облаке OVH, дополнительные расходы не требуются, поскольку входящая и исходящая пропускная способность уже включена.
Три из клиентов, которые уже знают предложение OVH, описывают свое преимущество:
Дальнейшее развитие управляемого сервиса Kubernetes
Управляемая служба Kubernetes уже доступна для всех клиентов через центр обработки данных OVH в Гравелине (Франция) и будет постепенно внедряться в различных регионах OVH Public Cloud в течение следующих нескольких месяцев. Кроме того, он скоро будет совместим с технологией «vRack». Это позволяет клиентам OVH


www.ovh.com/fr/kubernetes/
По сути, предложение, по словам Алена Фиокко, технического директора OVH, является постоянным кластерным контроллером. Клиенты, которые вносят свои правила использования компьютеров и ресурсов хранения, могут устанавливать их постоянно, даже если они не используют Kubernetes постоянно в OVH. Политика сохраняется.
Номера не нужны клиентам, этот контроллер. «Правда в том, заявляет Fiocco, что нам требуются сравнительно небольшие ресурсы от нас». Однако, как только клиенты используют ресурсы OVH для своего кластера Kubernetes, они платят за фактическое «потребление» или необходимые ресурсы. «В свою очередь, клиенты имеют доступ ко всему общедоступному облаку OVH», согласно CTO, а также к различным виртуальным машинам, например, в OpenStack или VMware.
Таким образом, предложение OVH должно характеризоваться несложным развертыванием, а также отказоустойчивыми и масштабируемыми приложениями. Тот, кто больше не нуждается в контроллере или правилах, хранящихся там и забывающих их, не нуждается в штрафах, как говорит Fiocco.
Предложение для разных потребителей Кубернеца
Kubernetes обещает общий стандарт для поставщиков гибридных и мультиоблачных услуг. Являясь одним из немногих сертифицированных поставщиков Cloud Native Computing Foundation (CNCF) в Европе, OVH решила выпустить альтернативу существующим вариантам Kubernetes. Предложение, которое теперь доступно, начинает OVH, чтобы расширить свой облачный портфель 18 октября 2018 года с частной бета-программой. Теперь управляемый сервис Kubernetes состоит из следующих компонентов:
- Балансировщик нагрузки, изначально встроенный в Kubernetes
- Настраиваемые политики для обновлений безопасности
- Выбор между двумя последними версиями Kubernetes, доступными на рынке, в настоящее время 1.11 и 1.12
- Используйте стандартный открытый API, который выигрывает от большого сообщества и широкой экосистемы, включая 627 компаний и проектов, перечисленных на сайте CNCF landscape.cncf.io/. API также предоставляет все преимущества OVH, включая поддержку 24x7, бесплатную защиту от DDoS и доступ к ведущей европейской оптоволоконной сети со скоростью 16 Тбит / с, ведущему европейскому облачному провайдеру.
- В комплекте с Kubernetes-совместимой управляемой службой: хотя службы других поставщиков не работают из-за настройки с некоторыми инструментами, служба OVH Managed Kubernetes полностью совместима с Kubernetes. Например, клиенты могут использовать оригинальное устройство контроля доступа Kubernetes (RBAC).
- Модель биллинга с оплатой по факту использования в публичном облаке OVH обеспечивает прозрачное ценообразование. OVH бесплатно предоставляет программное обеспечение для оркестровки Kubernetes, а также необходимую инфраструктуру. Поэтому клиенты платят только за постоянную систему хранения и вычислительную инфраструктуру, в которой работают их контейнеры, по стандартной цене общедоступного облака OVH и необходимого объема.
Это то, что говорят клиенты
Например, клиенты получают кластер с гарантированной постоянной производительностью ЦП и ОЗУ, начиная с 26,18 евро (включая НДС) в месяц, а инфраструктура, состоящая из пяти рабочих узлов с общим объемом оперативной памяти 35 гигабайт и 10 vCores для 130,90. Евро (с учетом НДС) доступно в месяц. Для клиентов, которые хотят использовать Kubernetes и их контейнеры в облаке OVH, дополнительные расходы не требуются, поскольку входящая и исходящая пропускная способность уже включена.
Три из клиентов, которые уже знают предложение OVH, описывают свое преимущество:
В Saagie мы предлагаем оркестратор Data Labs, который изощренно использует Kubernetes. Мы протестировали несколько управляемых сервисов Kubernetes от других поставщиков. Основанный на стандартах сервис OVH Managed Kubernetes обеспечивает нам отличную мобильностьсказал Юн Чене, технический директор комплексного оператора платформы данных Saagie.
Мы уже пытались построить наш кластер Kubernetes самостоятельно, но мы не смогли сделать это, потому что установка и обслуживание были слишком сложными для нас. Благодаря сервису OVH Managed Kubernetes мы смогли перенести наши приложения в Kubernetes, не беспокоясь об установке и обслуживании платформы. Бета-фаза проекта Kube прошла гладко благодаря присутствию и отзывчивости команды OVHсказал Винсент Дэви, ответственный за DevOps в ITK, специалисте по решениям для интеллектуального фермерства.
Служба OVH Managed Kubernetes дает нам все необходимое для бесперебойной работы наших служб, и при рассмотрении счета нет никаких неприятных сюрпризовговорит Жером Балдуччи, технический директор Whoz, поставщик инструментов для искусственного интеллекта в этой области. HR.
Дальнейшее развитие управляемого сервиса Kubernetes
Управляемая служба Kubernetes уже доступна для всех клиентов через центр обработки данных OVH в Гравелине (Франция) и будет постепенно внедряться в различных регионах OVH Public Cloud в течение следующих нескольких месяцев. Кроме того, он скоро будет совместим с технологией «vRack». Это позволяет клиентам OVH
- Создание гибридной частной инфраструктуры на глобальном уровне в нескольких центрах обработки данных с 28 собственными центрами обработки данных OVH на четырех континентах.
- доступ к кластерам Kubernetes как в частной, так и в стандартной общедоступной сети,
- Благодаря расширению «Облачное соединение OVH» объединяются все имеющиеся у них ресурсы как в облаке OVH, так и на локальном уровне.
www.ovh.com/fr/kubernetes/
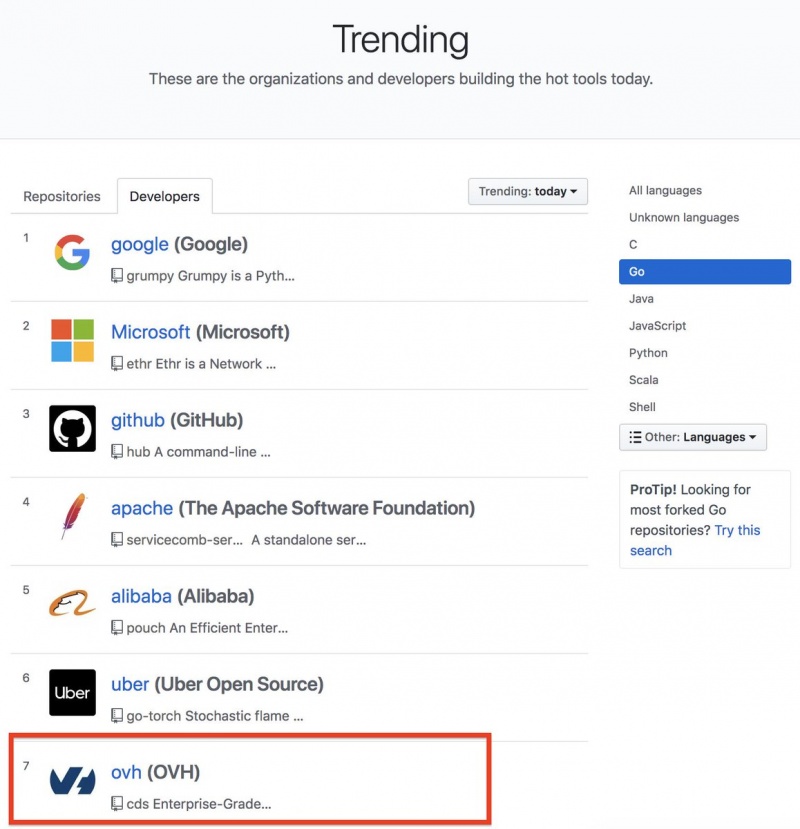
Top 10 Developers on GitHub
On the way to the 1000 stars today with cds, ovh is 7th on the Top 10 Developers on GitHub
ovh deals 02/2019

Public Cloud: Singapur i Australia

cdns.ovh.net
Уважаемый клиент, к сожалению, из-за большого количества запросов, проходящих через наш DNS (213.186.33.99), OVH пришлось приостановить разрешение DNS для следующего DNSBL:
zen.spamhaus.org
pbl.spamhaus.org
sbl.spamhaus.org
xbl.spamhaus.org
multi.surbl.org
Следовательно, запрос к одному из этих DNSBL будет последовательно представлять собой ответ NXDOMAIN по состоянию на 25 февраля 2019 года.
В соответствии с рекомендациями последнего, вам следует использовать собственный распознаватель DNS для использования этих служб, а не общедоступного поставщика DNS:
https://www.spamhaus.org/faq/section/DNSBL%20Usage#261
Спасибо за Ваше понимание.
zen.spamhaus.org
pbl.spamhaus.org
sbl.spamhaus.org
xbl.spamhaus.org
multi.surbl.org
Следовательно, запрос к одному из этих DNSBL будет последовательно представлять собой ответ NXDOMAIN по состоянию на 25 февраля 2019 года.
В соответствии с рекомендациями последнего, вам следует использовать собственный распознаватель DNS для использования этих служб, а не общедоступного поставщика DNS:
https://www.spamhaus.org/faq/section/DNSBL%20Usage#261
Спасибо за Ваше понимание.