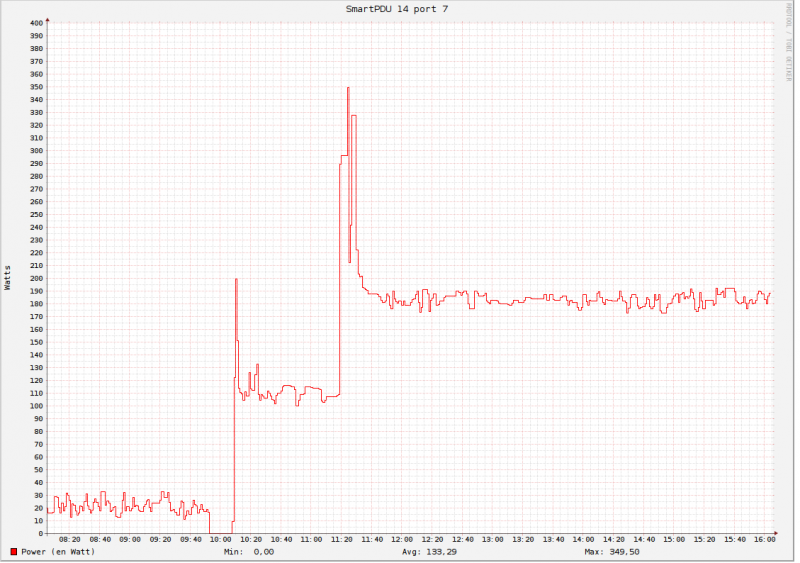
Каждые 5 секунд мы отправляем 1 пакет icmp на все наши IP-адреса (около 2M), сначала с 1-го DC, затем со 2-го, затем с 3-го. (ЕС, США) каждые 5 секунд, мы запускаем машинное обучение, чтобы выяснить, anti-paterns (время простоя, потеря пакетов, CRC, DDoS-воздействие, отключение ссылок) в январе 19 года SLA составил 99,994%