все новости по филиалам
Поиск
Облако к вашим услугам

Свобода, скорость и простота
Глядя на управляемую среду для ваших веб — проектов?
Бета-тестирование и в настоящее время завершены, решение Web Cloud позволяет настроить переменные окружения и развивать свой веб — сайт или ваш API в PHP или Node.js, изолированный на сервере, оснащенный SSD.
www.ovh.com/fr/hebergement-web/
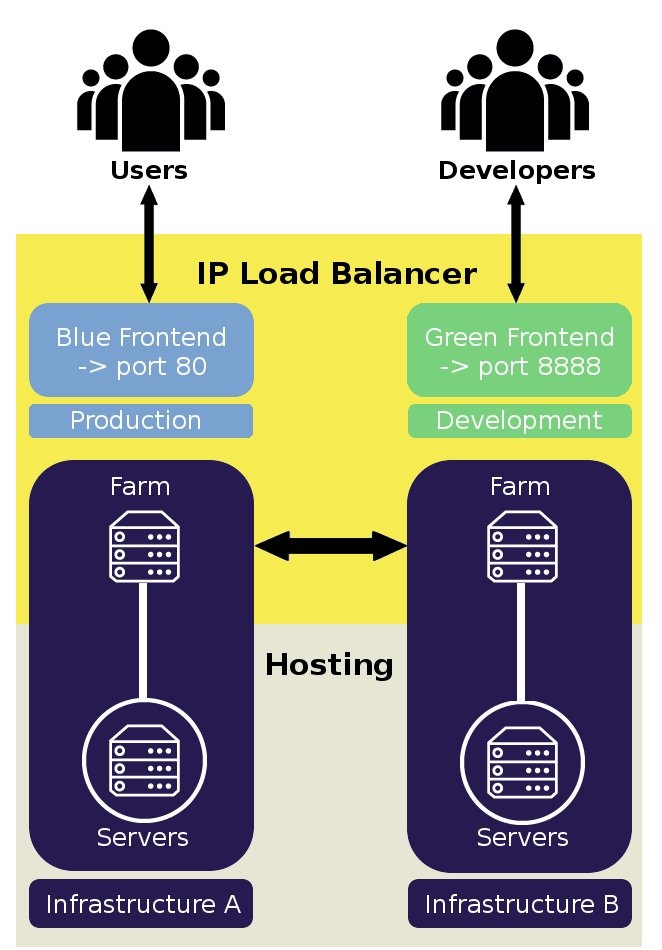
«Инфра есть код»
Кстати, чтобы построить свой суб
не в автоматизированной среде, инфраструктура как код больше не факультативная. Yann Degat Наше решение архитектор, говорит вам об инструменте облако оркестровка терраформировать.
www.ovh.com/fr/public-cloud/instances/
registry.terraform.io/modules/ovh/publiccloud-k8s/ovh/
registry.terraform.io/modules/ovh/publiccloud-k8s/ovh/0.1.0/examples/public-cluster-cl
github.com/ovh/terraform-ovh-commons
Создать Мультирегион блог
Пример гармонические и автоматизации
Узнайте, как использовать конкретные терраформировать с Public Cloud, развертывать и обновлять блог или высокодоступную mulitrégion сайта!
www.ovh.com/fr/blog/infra-as-code-creer-blog-multi-regions-avec-terraform-sur-public-cloud/
VPS SSD
Места для хранения вещей х 2
Всегда хранить больше…
… не платить больше! Мы рады сообщить, что емкость твердотельных накопителей три наши предложения в два раза, чтобы ваши проекты росли.
www.ovh.com/fr/vps/vps-ssd.xml
Выделенные серверы новые объявления
Три региона
Ваши спецификации или клиенты приглашают вас на заказ серверов хранения в Англии, Германии или Польше?
www.ovh.com/fr/serveurs_dedies/stockage/
Network:: CHARTER AS20115, Ashburn, VA
We are going to add a PNI with CHARTER at Ashburn
Here the new capacity with Charter after the upgrade
— Chicago: 4x10G
— San Jose: 2x10G
— Ashburn: 4x10G
Here the new capacity with Charter after the upgrade
— Chicago: 4x10G
— San Jose: 2x10G
— Ashburn: 4x10G
Public Cloud: новые экземпляры для вашего проекта
Несколько месяцев назад, мы улучшили наше решение путем создания нового поколения экземпляров (B2, C2, и т.д.), которые доступны только для новых проектов.
После отличной обратной связью, мы получили, теперь мы хотели бы, чтобы унифицировать наше решение путем расширения применения этого нового поколения, для того, чтобы более точно соответствовать вашим потребностям (локальное хранение SSD, высокой доступности дополнительных дисков, экземпляры GPU). Со временем, они заменят старые экземпляры (EG, HG, SP).
В целях повышения качества наших услуг, мы в скором времени будет прекращая старый диапазон экземпляров, которые вы сейчас используете.
После этого, вы не сможете создавать новые проекты на основе старого поколения, хотя существующие облачные серверы будут продолжать нормально функционировать.
Мы посылаем вам это письмо, как у вас есть проект Public Cloud развернутого в наших Страсбургских центрах обработки данных, которые будут затронуты этой миграцией.
Пожалуйста, примите к сведению меры, шаг за шагом ниже, которые будут иметь место в SBG1 регионе:
После отличной обратной связью, мы получили, теперь мы хотели бы, чтобы унифицировать наше решение путем расширения применения этого нового поколения, для того, чтобы более точно соответствовать вашим потребностям (локальное хранение SSD, высокой доступности дополнительных дисков, экземпляры GPU). Со временем, они заменят старые экземпляры (EG, HG, SP).
В целях повышения качества наших услуг, мы в скором времени будет прекращая старый диапазон экземпляров, которые вы сейчас используете.
После этого, вы не сможете создавать новые проекты на основе старого поколения, хотя существующие облачные серверы будут продолжать нормально функционировать.
Мы посылаем вам это письмо, как у вас есть проект Public Cloud развернутого в наших Страсбургских центрах обработки данных, которые будут затронуты этой миграцией.
Пожалуйста, примите к сведению меры, шаг за шагом ниже, которые будут иметь место в SBG1 регионе:
- OVH добавил новое поколение экземпляров в каталог вашего проекта. Теперь вы можете развернуть проекты как на старом и новом каталоге одновременно. Это идеальное время для планирования миграции.
- OVH скоро деактивировать старые поколения экземпляров из каталога. Никакие изменения не будут иметь место для ваших серверов, которые в настоящее время функционирует. Тем не менее, вы сможете только развернуть экземпляры из нового каталога.
Почему OVH становится OVHcloud?

В течение 2016 года я осознал сложность предложения очень широкого спектра продуктов под одной торговой маркой. Действительно, в OVH мы предлагаем, например, доменные имена и веб-хостинг для веб-мастеров и цифровых агентств, а также выделенные серверы для системных администраторов, Public Cloud для разработчиков или Cloud Hybrid для разработчиков. компании. В целом, OVH предлагает 25 продуктовых линий, более 92 коммерческих предложений с более чем 1000 коммерческих ссылок, которые используются 1,4 миллионами клиентов в 138 странах мира. Для этого разнообразия продуктов мы должны добавить сложность единой поддержки клиентов по телефону и электронной почте на нескольких языках.
В 2017 году мы работали над разъяснением того, что мы хотим предложить всем нашим клиентам, партнерам и интеграторам. Именно поэтому на Саммите 2017 я объявил о создании 3 суб-брендов: OVHmarket, OVHspirit и OVHenterprise.
Теперь мы будем говорить о OVHcloud коммерчески, что помогает лучше понять, что такое наш бизнес. OVHcloud соберет 3 суб-бренда OVHmarket, OVHspirit и OVHenterprise. Таким образом, мы будем общаться через один и тот же бренд OVHcloud и с теми же продуктами по всему миру. Это амбициозный выбор и эмоционально очень сложный. Мы много думали, и у нас было несколько колебаний. После 20 лет, я думаю, что, чтобы дать глобальный масштаб, OVH должен частично изменить свое название, именно по этой цене мы предоставим все возможности для того, чтобы стать действительно глобальной компанией, стремящейся обеспечить все его услуги по всему миру.
OVHmarket
Подмаркет OVHmarket, доступный только в Европе, объединяет продукты для МСП, SMI, TPI и подрядчиков, чтобы помочь им использовать цифровые технологии. Здесь мы находим все продукты доступа в Интернет, ADSL, SDSL, оптоволокно для бизнеса, IP-телефонию с арендой или покупкой предварительно настроенных телефонов Plug & Phone, более 100 расширений имени домены, службы DNS, почтовые службы и обмен, WebHosting или CloudWeb.
Помимо продуктов, которые мы создаем и управляем самостоятельно, мы работаем над интеграцией двух типов продуктов от наших партнеров:
- внешние продукты, которые позволяют, например, цифровой биллинг, управление взаимоотношениями с клиентами (CRM), цифровой маркетинг и т. д. чтобы наши клиенты могли использовать все свои базы данных;
- продукты управления услугами, предлагать такие продукты, как помощь в настройке Exchange, настройка WordPress или обновление Prestashop через нашу сеть партнеров.
OVHspirit
OVHspirit — это историческое сердце нашего бизнеса. Мы известны тем, что предлагаем непревзойденные предложения по соотношению цена / производительность. OVHspirit позволит нам продолжать выступать на этом рынке в Европе и США. Он включает в себя все облачные продукты, такие как выделенные серверы, VPS или выделенное облако для системных администраторов. Здесь мы хотим предложить все предложения Kimsufi и SoYouStart.
С OVHspirit мы хотим быть более агрессивными с точки зрения цены. Цель: предложить клиентам наиболее «чувствительную к цене» возможность платить только то, что им нужно, четко объясняя объем и пределы предлагаемой услуги. С 28 центрами обработки данных в 12 точках в Европе, США, Канаде и Азии мы стремимся предлагать ряд серверов VPS и Dedicated Cloud по самой привлекательной цене, доступной на местном уровне, независимо от того, где в мире являются нашими центрами обработки данных. Например, играя в моменты доступности, мы сможем снизить цены примерно на 4%, плюс 5%.
Клиенты OVHspirit являются техническими экспертами в своих областях. Они не обращаются в службу поддержки, чтобы понять продукт или помочь им использовать Linux, но они ищут очень быструю поддержку в случае инцидента, не более того. При всей прозрачности каждый может скорректировать уровень поддержки, который он хочет извлечь, чтобы заплатить только то, что ему подходит лучше всего (я буду развиваться более подробно OVHspirit в будущем блоге).
OVHenterprise
Мы хотим предложить бескомпромиссное обслуживание для клиентов, которые ищут качество, прежде всего, и для которых цена не является самым важным критерием. Для них мы разработали в 2006 году первое предложение выделенных серверов HG. Затем в 2013 году мы создали выделенное облако на основе vSphere как службы.
В настоящее время мы работаем над предложением Public Cloud для OVHentreprise. С переносом всех наших API-интерфейсов в API OpenStack наше Public Cloud будет соответствовать рыночным стандартам и позволит нашим клиентам использовать Terraform, Ansible и т. Д. с кодом с открытым исходным кодом экосистемы. Используя все эти стандартные API внутри, и благодаря принципу микросервиса, мы ускоряем время инноваций (я буду говорить более широко в блоге).
Чтобы продолжить качество, мы внедрили новый стандарт, включающий сертификаты ISO27000, PCI-DSS, SecNumCloud и т. Д. Чтобы предложить частное облако для всех критических миссий компании, клиент полностью изолирован от всех остальных и может попросить нас развернуть все облачные сервисы в этой полностью частной среде.
В OVHentreprise мы хотим поддержать клиента с 3 уровнями поддержки:
- включенная в цену, первая позволяет иметь случайную поддержку, которая фиксирует проблемы с очень быстрым временем отклика, мы не будем предлагать здесь советы по использованию наших продуктов;
- второй уровень обеспечивает доступ к консультационной поддержке при многопользовательском использовании и поддержке инцидентов для решений, которые по определению намного сложнее контролировать и поддерживать;
- третий уровень поддержки предназначен для компаний, которые используют продукты и решения OVHentreprise посредством конкурсов, требующих конкретной поддержки на ежедневной основе. Это зачастую очень сложные инфраструктуры, Hybrid Cloud, между центрами обработки данных клиентов, OVH и иногда предложениями наших конкурентов. (Я буду развивать OVHenterprise больше в будущем блоге)
Все эти 3 суб-бренды поступят в ближайшие месяцы на наших сайтах в Европе, Канаде и США. Чтобы избежать путаницы, мы решили постепенно перенести все сайты OVH на один веб-сайт. Отныне все предложения будут на OVHcloud.com, а также в Европе, Канаде и США. Мы будем действовать и думать в компании мирового класса, чтобы сделать OVH уникальным, быть на вершине во всех областях и показать нам при любых обстоятельствах высоту наших обязательств и нашей ответственности. Мы хотим стать альтернативным технологическим гигантом.
Обновление нового положения о размещении данных о здоровье
OVH является уполномоченным поставщиком медицинских данных с 24 октября 2016 года. Это утверждение, касающееся частного облака OVH, позволило нам запустить предложение OVH Healthcare. Мы предоставляем нашим клиентам виртуальные центры обработки данных, работающие на инструментах VMware и обладающие всеми функциями автоматизированного управления (Sofware Defined Datacenter).
Начиная с коммерческого запуска предложения в начале 2017 года, бренды интереса умножились, и многие клиенты подписали это предложение. Ставка успешна для OVH Healthcare с устойчивым темпом подписки. В соответствии с нашими ценностями, наши клиенты могут менять свой хост каждый месяц. Тем не менее, большинство из них поддерживает доверие к нашим инфраструктурам и нашим командам.

ovh.healthcare
История основного бизнеса
Предложение OVH Healthcare основано на простом принципе: обеспечить лучшее ноу-хау OVH для клиентов, принимающих персональные медицинские данные. Мы не знаем, как лечить пациентов, но мы заботимся о нашей инфраструктуре! Точно так же мы не претендуем на то, чтобы овладеть всеми тонкостями информационных систем здравоохранения. С другой стороны, мы знаем, как создавать ИТ-инфраструктуры, обеспечивать их безопасность и техническое обслуживание в рабочем состоянии.
Именно поэтому мы решили развивать хостинг данных о здоровье в предложениях Private Cloud.
Новая сертификация HDS
С появлением облака старое одобрение, принципы которого были определены в 2006 году, уже не соответствовало рынку и многим типам существующих услуг (IaaS, PaaS, SaaS ...). Юридические ограничения, связанные с размещением данных о здоровье, больше не связаны только с утвержденным хостинг-провайдером, который иногда предоставлял только физическое жилье. Теперь они охватывают всю цепочку создания стоимости информационной системы здравоохранения.
В последнем постановлении № 2018-137 определены шесть сертифицируемых видов деятельности:
Указ 2018-137 — статья CSP R.1111-9 Иными словами
«Хост медицинских данных» будет сертифицирован по всем или некоторым из перечисленных выше видов деятельности. Предложение OVH Healthcare охватывает действия 1-3. Благодаря нашему варианту Veeam Backup мы частично покрываем активность 6. Однако наши клиенты должны обеспечить согласованность резервных копий и их способность восстанавливать их. Поэтому они также несут ответственность за гарантии. Мероприятия 4-6 должны быть сертифицированы в помещении клиента.
Ожидаемое изменение регулирования
Новая сертификация для размещения данных о здоровье была закреплена в законе с указом № 2018-137 и указом от 11 июня 2018 года, утверждающим систему сертификации.
Эта модификация была предметом многочисленных консультаций, проведенных ASIP Santé. Дискуссии были оживленными с государством, которое хотело укрепить безопасность информационных систем. Согласно новым правилам, государство убивает двух зайцев одним камнем:
Репозитории публично доступны на веб-сайте ASIP Santé (см. Ниже).
До тех пор, пока все данные о состоянии здоровья не будут сертифицированы, применяются переходные меры. Например, утверждения продолжают применяться до истечения срока их действия. В случае OVH наши клиенты будут продолжать пользоваться нашим одобрением до 23 октября 2019 года. Все наши клиенты Healthcare должны быть готовы к этой эволюции.
Как будет применяться это новое правило?
Как поставщик компьютерных услуг для медицинских работников, вы не можете избежать этого правила. Это тем более верно, что ASIP Santé уже начал повышать осведомленность своих клиентов об этой проблеме.
Медицинским работникам необходимо будет обеспечить соответствие всей цепочки создания стоимости в соответствии с законом. Для этого они будут ссылаться на таблицу действий для сертификации выше. В течение переходного периода между аккредитацией и сертификацией каждая компания должна будет иметь возможность объяснить, где она соответствует новым правилам.
OVH помогает заказчикам адаптироваться к новым правилам
Нелегко понять новую законодательную базу и привести к более сильной приверженности наших клиентов соблюдению.
OVH Healthcare, основанная на частном облаке, будет включать сертификацию по действиям с 1 по 3. В зависимости от деятельности наших клиентов возможны две стратегии для сертификации деятельности 4-6:
СОДЕРЖАНИЕ РЕФЕРЕНЦИАЦИИ HDS
Репозиторий основан на:
Начиная с коммерческого запуска предложения в начале 2017 года, бренды интереса умножились, и многие клиенты подписали это предложение. Ставка успешна для OVH Healthcare с устойчивым темпом подписки. В соответствии с нашими ценностями, наши клиенты могут менять свой хост каждый месяц. Тем не менее, большинство из них поддерживает доверие к нашим инфраструктурам и нашим командам.
ovh.healthcare
История основного бизнеса
Предложение OVH Healthcare основано на простом принципе: обеспечить лучшее ноу-хау OVH для клиентов, принимающих персональные медицинские данные. Мы не знаем, как лечить пациентов, но мы заботимся о нашей инфраструктуре! Точно так же мы не претендуем на то, чтобы овладеть всеми тонкостями информационных систем здравоохранения. С другой стороны, мы знаем, как создавать ИТ-инфраструктуры, обеспечивать их безопасность и техническое обслуживание в рабочем состоянии.
Именно поэтому мы решили развивать хостинг данных о здоровье в предложениях Private Cloud.
- Наши механизмы, обеспечивающие установку, безопасность и оперативное обслуживание гипервизоров, хранилищ и блоков управления инфраструктурой, управляются нашими командами: это наш основной бизнес.
- Наш клиент устанавливает, обеспечивает и поддерживает в рабочем состоянии медицинскую информационную систему, которую он предоставляет от наших инфраструктур: это его основной бизнес.
- Профессионал здравоохранения полагается на информационную систему, которую предоставляет наш клиент для лечения пациентов.
Новая сертификация HDS
С появлением облака старое одобрение, принципы которого были определены в 2006 году, уже не соответствовало рынку и многим типам существующих услуг (IaaS, PaaS, SaaS ...). Юридические ограничения, связанные с размещением данных о здоровье, больше не связаны только с утвержденным хостинг-провайдером, который иногда предоставлял только физическое жилье. Теперь они охватывают всю цепочку создания стоимости информационной системы здравоохранения.
В последнем постановлении № 2018-137 определены шесть сертифицируемых видов деятельности:
Указ 2018-137 — статья CSP R.1111-9 Иными словами
- Предоставление и обслуживание в рабочем состоянии физических сайтов для размещения физической инфраструктуры информационной системы, используемой для обработки медицинских данных. Корпус
- Предоставление и обслуживание в условиях эксплуатации физической инфраструктуры информационной системы, используемой для обработки медицинских данных. Серверы, сети, хранилища
- Предоставление и обслуживание в рабочем состоянии виртуальной инфраструктуры информационной системы, используемой для обработки данных о состоянии здоровья. IaaS
- Предоставление и обслуживание в рабочем состоянии платформы для размещения приложений информационной системы. PaaS
- Администрирование и функционирование информационной системы, содержащей данные о состоянии здоровья. SaaS
- Сохранение данных о состоянии здоровья.
«Хост медицинских данных» будет сертифицирован по всем или некоторым из перечисленных выше видов деятельности. Предложение OVH Healthcare охватывает действия 1-3. Благодаря нашему варианту Veeam Backup мы частично покрываем активность 6. Однако наши клиенты должны обеспечить согласованность резервных копий и их способность восстанавливать их. Поэтому они также несут ответственность за гарантии. Мероприятия 4-6 должны быть сертифицированы в помещении клиента.
Ожидаемое изменение регулирования
Новая сертификация для размещения данных о здоровье была закреплена в законе с указом № 2018-137 и указом от 11 июня 2018 года, утверждающим систему сертификации.
Эта модификация была предметом многочисленных консультаций, проведенных ASIP Santé. Дискуссии были оживленными с государством, которое хотело укрепить безопасность информационных систем. Согласно новым правилам, государство убивает двух зайцев одним камнем:
- он исправляет проблемы, связанные с аккредитацией хостинга медицинских данных: его время получения было длинным, файл не адаптировался ко всем ситуациям с постулантами;
- он передает валидационные действия будущих хостов специалистам: органам по сертификации.
Репозитории публично доступны на веб-сайте ASIP Santé (см. Ниже).
До тех пор, пока все данные о состоянии здоровья не будут сертифицированы, применяются переходные меры. Например, утверждения продолжают применяться до истечения срока их действия. В случае OVH наши клиенты будут продолжать пользоваться нашим одобрением до 23 октября 2019 года. Все наши клиенты Healthcare должны быть готовы к этой эволюции.
Как будет применяться это новое правило?
Как поставщик компьютерных услуг для медицинских работников, вы не можете избежать этого правила. Это тем более верно, что ASIP Santé уже начал повышать осведомленность своих клиентов об этой проблеме.
Медицинским работникам необходимо будет обеспечить соответствие всей цепочки создания стоимости в соответствии с законом. Для этого они будут ссылаться на таблицу действий для сертификации выше. В течение переходного периода между аккредитацией и сертификацией каждая компания должна будет иметь возможность объяснить, где она соответствует новым правилам.
OVH помогает заказчикам адаптироваться к новым правилам
Нелегко понять новую законодательную базу и привести к более сильной приверженности наших клиентов соблюдению.
OVH Healthcare, основанная на частном облаке, будет включать сертификацию по действиям с 1 по 3. В зависимости от деятельности наших клиентов возможны две стратегии для сертификации деятельности 4-6:
- Поставщики и интеграторы SaaS будут сертифицированы для мероприятий с 4 по 6, что станет гарантией их опыта в их бизнесе. OVH (сертифицированный для мероприятий с 1 по 3) предоставляет список поставщиков услуг, способных обучать, помогать в процессе сертификации и проходить сертификацию;
- поставщики программного обеспечения будут использовать сертифицированных менеджеров для деятельности с 4 по 6. OVH (сертифицированный для деятельности с 1 по 3) предоставляет список профессионалов, которые имеют опыт управления областями здравоохранения OVH.
СОДЕРЖАНИЕ РЕФЕРЕНЦИАЦИИ HDS
Репозиторий основан на:
- все требования ISO 27001, некоторые требования ISO 20000-1 и около 15 конкретных требований ASIP Health;
- набор лучших практик стандартов ISO27002, ISO27017 и ISO27018.
New monitoring system GSCAN
docs.ovh.com/gb/en/dedicated/monitoring-ip-ovh/
mrtg-rbx-100 37.187.231.251 icmp
mrtg-sbg-100 37.187.231.251 icmp
mrtg-gra-100 37.187.231.251 icmp
mrtg-bhs-100 37.187.231.251 icmp
mrtg-rbx-101 151.80.231.244 icmp
mrtg-rbx-102 151.80.231.245 icmp
mrtg-rbx-103 151.80.231.246 icmp
mrtg-gra-101 151.80.231.247 icmp
a2.ovh.net 213.186.33.62 icmp
92.222.184.0/24 icmp
92.222.185.0/24 icmp
92.222.186.0/24 icmp
167.114.37.0/24 icmp
proxy.p19.ovh.net 213.186.45.4 icmp
proxy.rbx.ovh.net 213.251.184.9 icmp
proxy.sbg.ovh.net 37.59.0.235 icmp
proxy.bhs.ovh.net 8.33.137.2 icmp
ping.ovh.net 213.186.33.13 icmp
proxy.ovh.net 213.186.50.98 icmp
xxx.xxx.xxx.250 (xxx.xxx.xxx.aaa is the server ip) icmp
xxx.xxx.xxx.251 (xxx.xxx.xxx.aaa is the server ip) icmp + Port monitored by the monitoring servicePrice increase for .space & .pw domain names
The pricing for our .space and .pw domain names will increase on 21st August 2018.
From this date onwards, .space and .pw domain name renewals will be charged at £18.99 ex. VAT/year instead of £7.99 ex. VAT/year.
Any .space and .pw domain names renewed before 21st August 2018 will not be affected by this price increase.
You have until 20th August 2018 to renew your domain name at the lower price.
From this date onwards, .space and .pw domain name renewals will be charged at £18.99 ex. VAT/year instead of £7.99 ex. VAT/year.
Any .space and .pw domain names renewed before 21st August 2018 will not be affected by this price increase.
You have until 20th August 2018 to renew your domain name at the lower price.
Découvrez les nouvelles références So you Start

Quelles sont les différences entre les serveurs Kimsufi et So you Start?
Les serveurs So you Start disposent d'une puissance hardware supérieure, idéale pour accompagner vos projets exigeants en ressources.

www.soyoustart.com/fr/
Экономия до 45% на голых серверах металла

В течение ограниченного времени, OVHcloud снизил цены на голых серверах металла. Выберите из нашей универсальной инфраструктуры, настраиваемого для хранения или мощных игровых серверов. Все выделенные сервера поставляются с защитой от DDoS, неограниченным трафиком с гарантированной пропускной способностью, а также супер-быстрой доставкой.
Посмотреть предложения
info.ovhcloud.com/bare-metal-servers
Сеть OVHcloud и обнаженные сервера металла дают вам производительность и управлять вам нужно запускать наиболее важные рабочие нагрузки. Не пропустите на этой невероятной цене!
С Уважением, OVHcloud Team