Мы рады объявить о доступности нашего технический превью SolusIO!
Наша цель — предоставить интернет-провайдерам, MSP, CSP и WebPros решения, которые им необходимы для их уникальных путешествий в области цифровых преобразований. Поскольку компании используют наши инновационные технологии, они приносят новые результаты для своего бизнеса и своих клиентов.
SolusIO является потомком SolusVM. SolusIO знаменует собой новый этап в упрощении управления виртуальной инфраструктурой. Это новый продукт с чистым пользовательским интерфейсом самообслуживания, предлагающий новый UX, и мы планируем включить в него наиболее востребованные функции наших партнеров и сообщества.
Изучите интерфейс администратора
Интерфейс администратора предоставляет администраторам полный контроль над всей системой SolusIO. Управлять вычислительными ресурсами (серверами, на которых впоследствии работают виртуальные машины) так же просто, как добавить новый образ ОС.
Это обзор вычислительных ресурсов. Каждому вычислительному ресурсу также может быть назначено место, которое может быть этажом, комнатой, городом, страной или чем угодно.
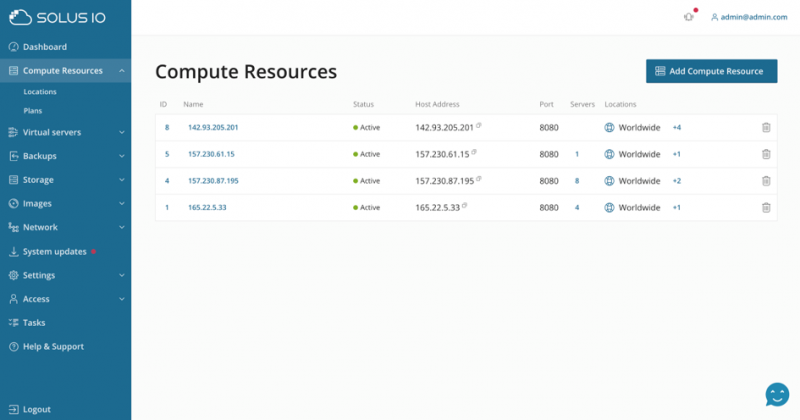
Здесь также можно изменить настройки вычислительных ресурсов, такие как пути, системные настройки, ограничения и другие.
Параметры использования диска и памяти можно контролировать с одного и того же интерфейса. Ценной особенностью SolusIO является его встроенный планировщик задач с очередями. Это означает, что каждое действие выполняется не только в режиме «запусти и забывай», но и может быть добавлено в очередь, а его выполнение отслеживается.
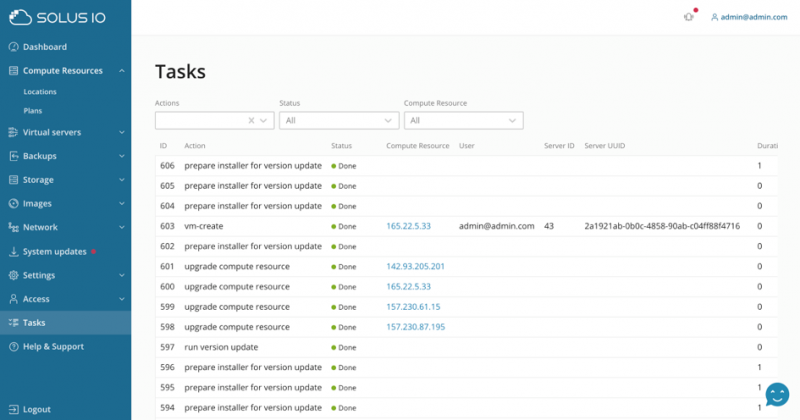
Администратор может просмотреть все задачи и проверить дополнительную информацию в случае сбоя задачи. Неудачные задачи, конечно, также могут быть перезапущены, а зависшие задачи могут быть остановлены. Ход выполнения показан для каждой длительной задачи (например, установка операционной системы).
С SolusIO мы отдаем приоритет опыту работы с клиентами и создаем лучший способ упростить управление виртуализацией
Владелец системы может создавать планы, которые могут быть выбраны конечным пользователем позже в процессе создания сервера. Планы могут быть использованы для предложения виртуальных машин разных размеров, например различное количество памяти или vCPU.
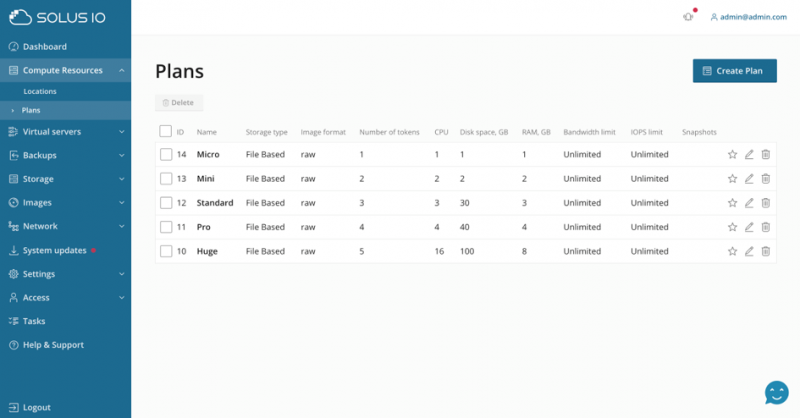
Планам может быть назначен так называемый «счетчик токенов», который представляет виртуальную валюту. Таким образом, владельцу системы не нужно напрямую связываться с ценами в SolusIO, так как это является исключительно обязанностью биллинговой системы. Счетчик токенов задает значение для часа безотказной работы и будет преобразован в реальную цену с помощью API биллинга или, соответственно, системы биллинга.
Возвращаемая реальная цена может быть рассчитана по количеству токенов, типу пользователя, стране пользователя и т. Д. Так, например, европейский покупатель увидит цены в евро, отличные от покупателя в США, который увидит цены в долларах США.
Создать новый проект
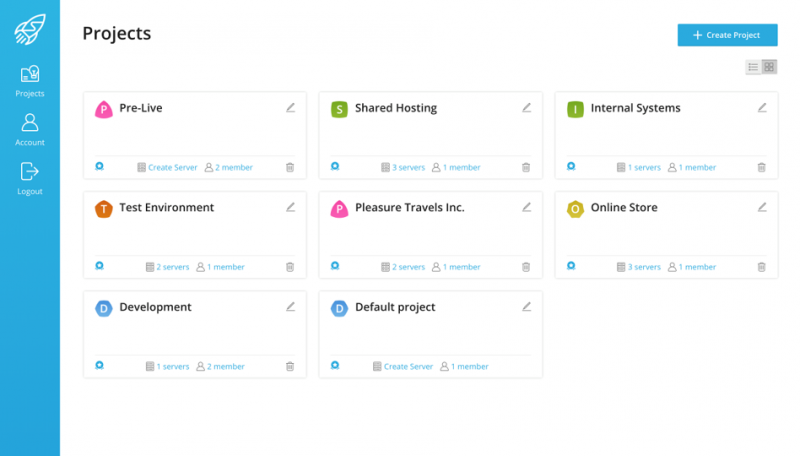
Проекты используются для разделения виртуальных серверов на группы — например, для разных клиентов или разных клиентских проектов.
Новые проекты могут быть добавлены при необходимости. В каждом проекте могут участвовать различные участники с разными ролями и разрешениями. Например, администратор может назначить разрешения, чтобы один пользователь или группа пользователей могли только просматривать консоль сервера, но не имеет права удалять ее.
 Создать сервер
Создать сервер
Чистый пользовательский интерфейс самообслуживания дает вашим клиентам полный контроль с функциями по требованию, от развертывания до уничтожения их серверов. После выбора местоположения, операционной системы и плана пользователь готов создать сервер.
При желании также можно указать ключи SSH, пользовательские данные cloud-init, имя и описание.
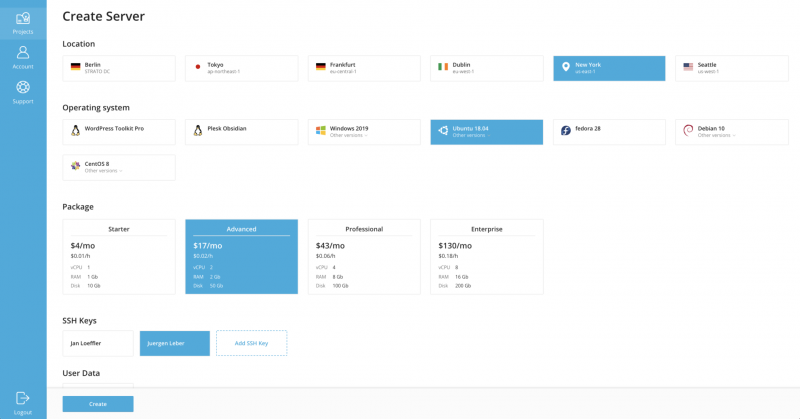
Новый сервер будет показан в обзоре проекта. Вот например он может быть выключен или может быть запрошена консоль VNC. Конечно, работающие серверы также могут быть прерваны и удалены здесь.
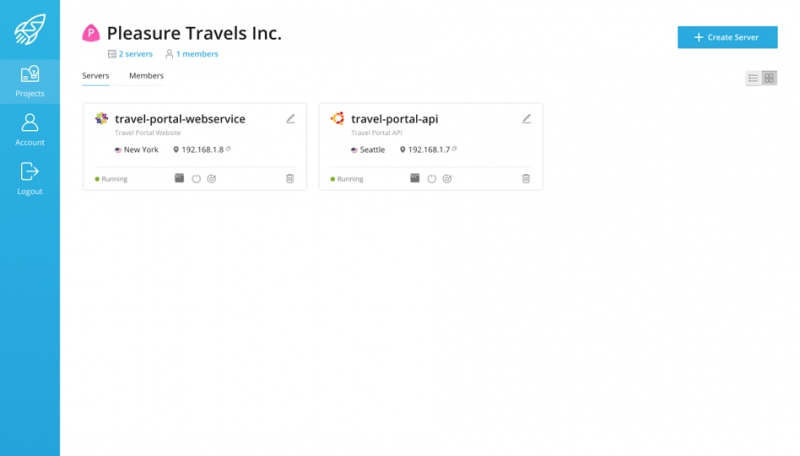
После нажатия на конкретный сервер пользователь может увидеть подробную информацию, такую как выбранный пакет, текущие затраты на использование, потребление трафика, ввод-вывод и использование ЦП.
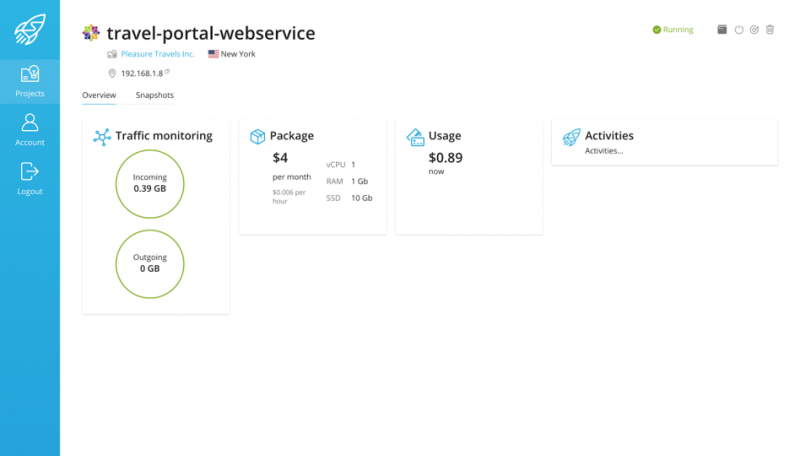
«Но с SolusIO можно устанавливать не только простые операционные системы».
Создать приложение
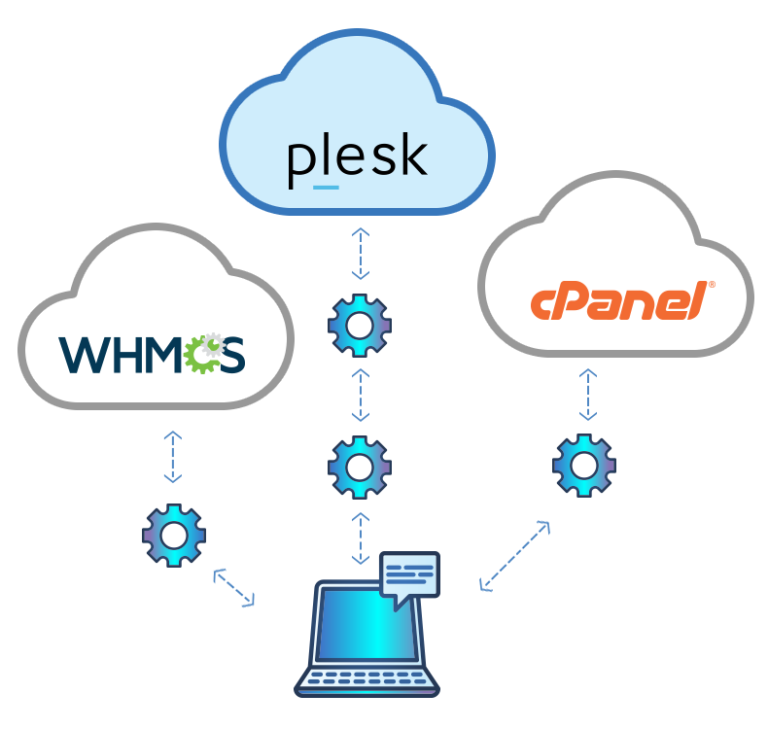
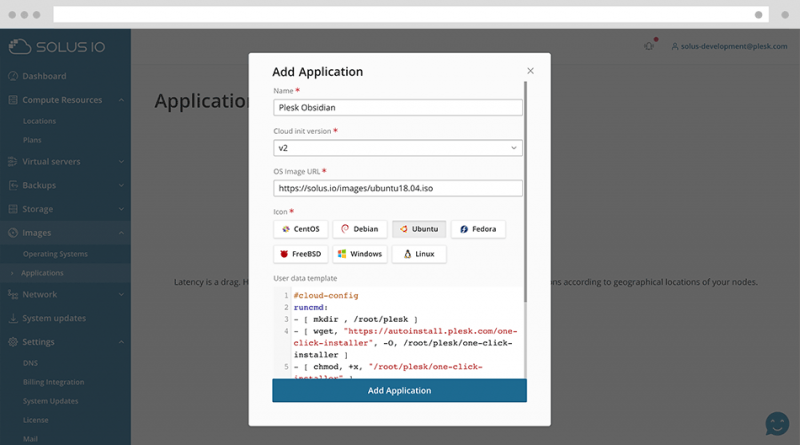
Помимо выбора «ванильной» (аналогично чистой / без изменений) операционной системы, пользователь может выбрать прямое развертывание приложения на виртуальном сервере. Это может быть Plesk, cPanel, WHMCS или даже экземпляр WordPress, работающий на Plesk с использованием WordPress Toolkit.

Все управляется из одного интерфейса. Конечно, весь пользовательский интерфейс можно настроить в соответствии с потребностями поставщика услуг, изменив базовый CSS и изображения.
Пригласить участников
Пригласите других участников, будь то семья, друзья или коллеги, безопасно управлять серверами в рамках проекта, не предоставляя им полных прав доступа к вашей учетной записи.
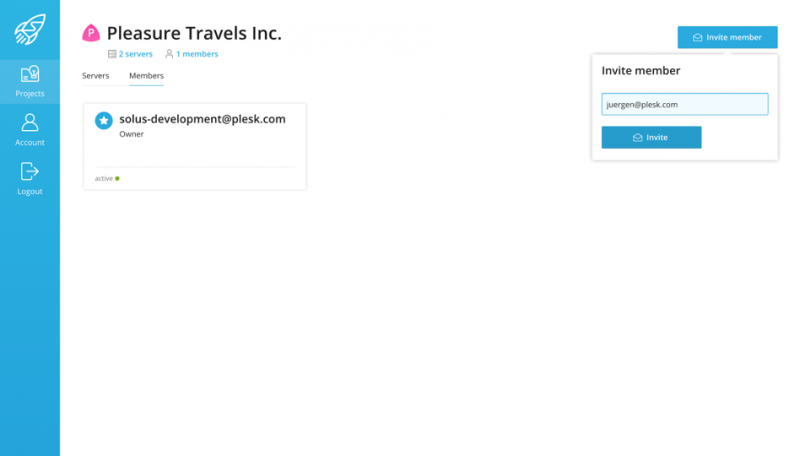
Новые участники могут быть легко добавлены в проект и получат приглашение зарегистрироваться и получить доступ.
Вся эта функция может контролироваться администратором и, конечно, также может быть отключена, если не требуется. После того, как пользователь успешно зарегистрировался и вошел в систему, можно управлять существующими серверами или создавать новые серверы.
Но пользовательский опыт идет еще дальше… есть не только графический интерфейс пользователя, но и…
API отдыха
Полноценный REST API, поскольку SolusIO был полностью построен с использованием подхода «сначала API».
Весь API REST документирован как с помощью Swagger, так и в письменной форме, с множеством примеров использования. Чтобы облегчить работу разработчиков, мы также предоставляем SDK для основных языков программирования в ближайшее время.
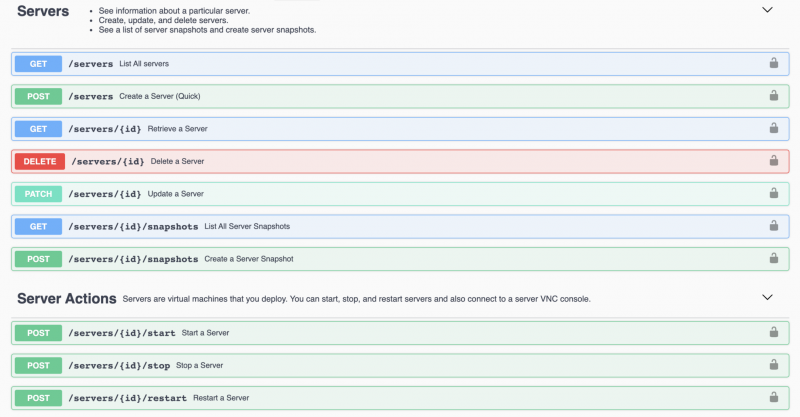
«Все, что вы можете делать в графических пользовательских интерфейсах (то есть в административном и пользовательском интерфейсах), также доступно через RESTful API».
Администраторы могут автоматизировать такие задачи, как добавление вычислительных ресурсов или мониторинг серверов. Разработчики могут создавать ключи API для предоставления и управления своими серверами из своего кода.
Миграция
Для существующих клиентов SolusVM, которые хотят перейти на SolusIO, мы вскоре предоставим набор инструментов, которые сделают переход максимально простым, сведя к минимуму ручные усилия.
Конечно, существующие клиенты SolusVM могут продолжать использовать продукт, и он все еще будет поддерживаться. Мы настоятельно рекомендуем как можно скорее перейти на SolusIO, чтобы расширить ваш бизнес с помощью нашего интеллектуального решения!
Для поставщиков услуг и предприятий
SolusIO создан как для поставщиков услуг, так и для организаций.
Поставщики услуг могут предлагать продукт своим клиентам, предоставляя портал самообслуживания или просто перепродавая лицензии, чтобы они могли строить свой собственный бизнес, такой как DigitalOcean, Vultr, Hetzner Cloud и т.д.
- Продавайте виртуальные серверы своим клиентам через портал самообслуживания, предоставляя возможность развертывания и управления виртуальными серверами по требованию.
- Позвольте веб-профессионалам работать более эффективно, чтобы они могли удовлетворить быстро меняющиеся потребности клиентов.
Организации или предприятия могут использовать solus.io для внутренней виртуализации для развертывания и управления серверами по требованию в рамках своей частной инфраструктуры.
- Предоставьте разрешения вашим командам разработчиков на управление и создание серверов по требованию.
- Автоматизируйте создание тестовых сред с помощью задач сборки или интегрируйте с помощью REST API.