В 2024 году мы запустили просто так
от делать нечего серверы с ISPmanager
Сколько мы потратили на это ?
На серверы = 0р потому что они на коло валяются, ну да покупка серверов это разовый расход конечно, но это вовсе не убыток, это просто ненужный сервер валялся. Энергия и интернет там покрывается короче соседями по стойке.
Далее, лицензии ISPmanager
Вот это уже реальный расход который высасывает бабки

Получилось 9594 ₽ / Месяц
*12 мес = 115128 рублей потратили, ну за год это мелочь по сути
Сколько людей заказало хостинг ?
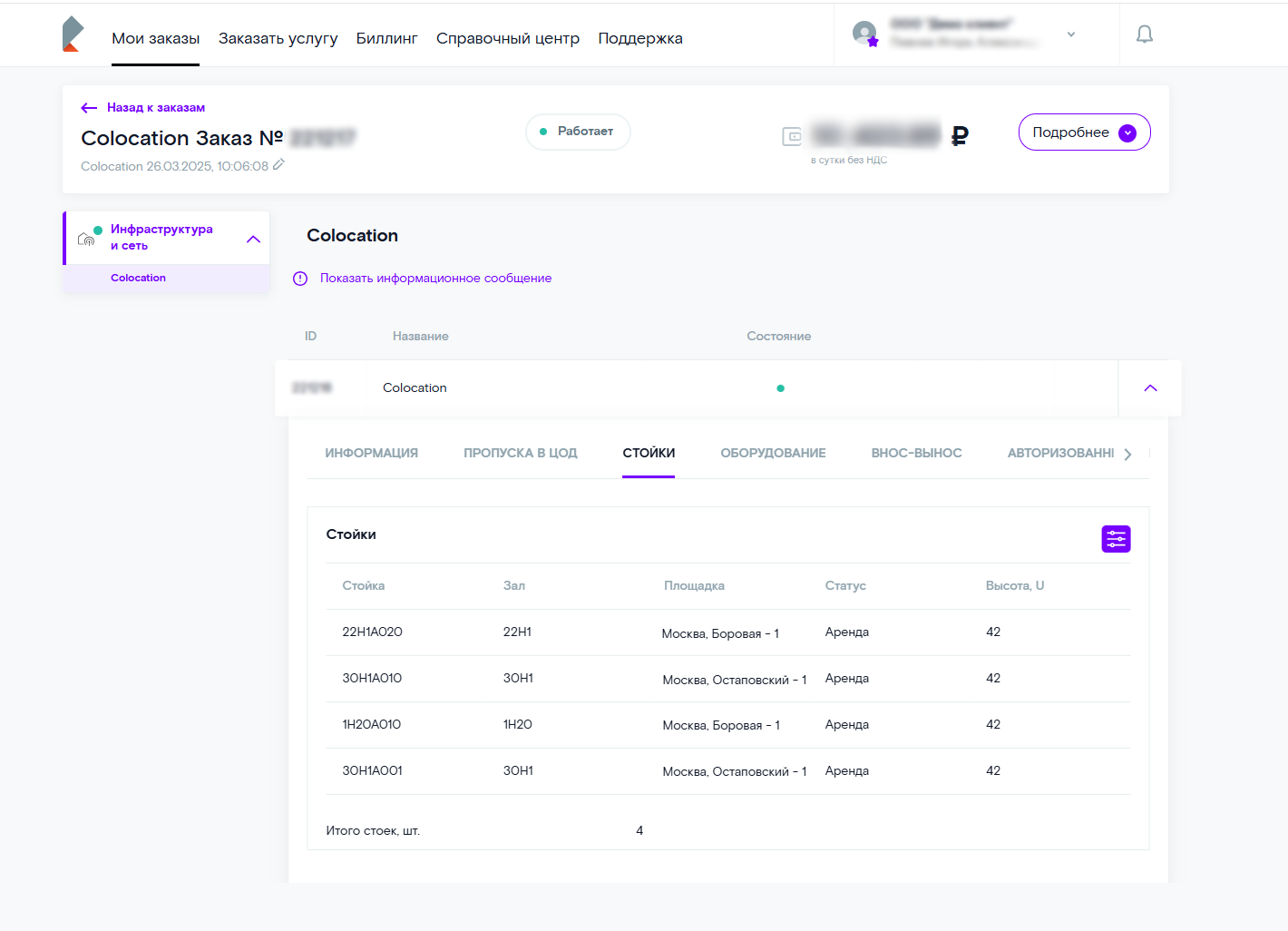
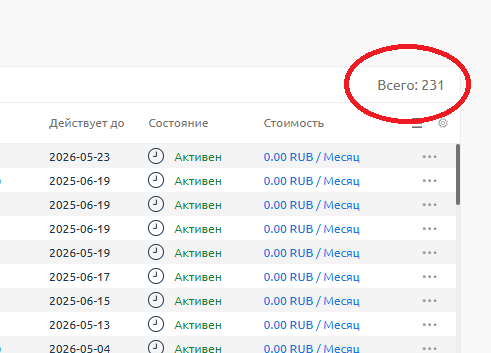 Заплатил лишь 1 человек, докупил себе «диска» за 50р
Заплатил лишь 1 человек, докупил себе «диска» за 50р
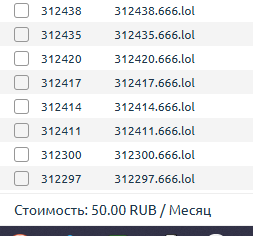 Бесплатные вечные домены у нас попросило всего 6 человек
С чем мы столкнулись ?
Бесплатные вечные домены у нас попросило всего 6 человек
С чем мы столкнулись ?
Во первых был один инцидент. Когда Пермь локация перешла к нам, я сделал там в уже созданной челом VMmanager жирную виртуалку под хостинг. Под своим аккаунтом, даже написал там маркировку сервера. А чел короче ему стало нехватать IP и он пошел чистить и увидел сервер и взял просто его удалил ) Так бывает.
Пострадало всего 2 человека, остальные аккаунты на том сервере были пустые созданные от балды.
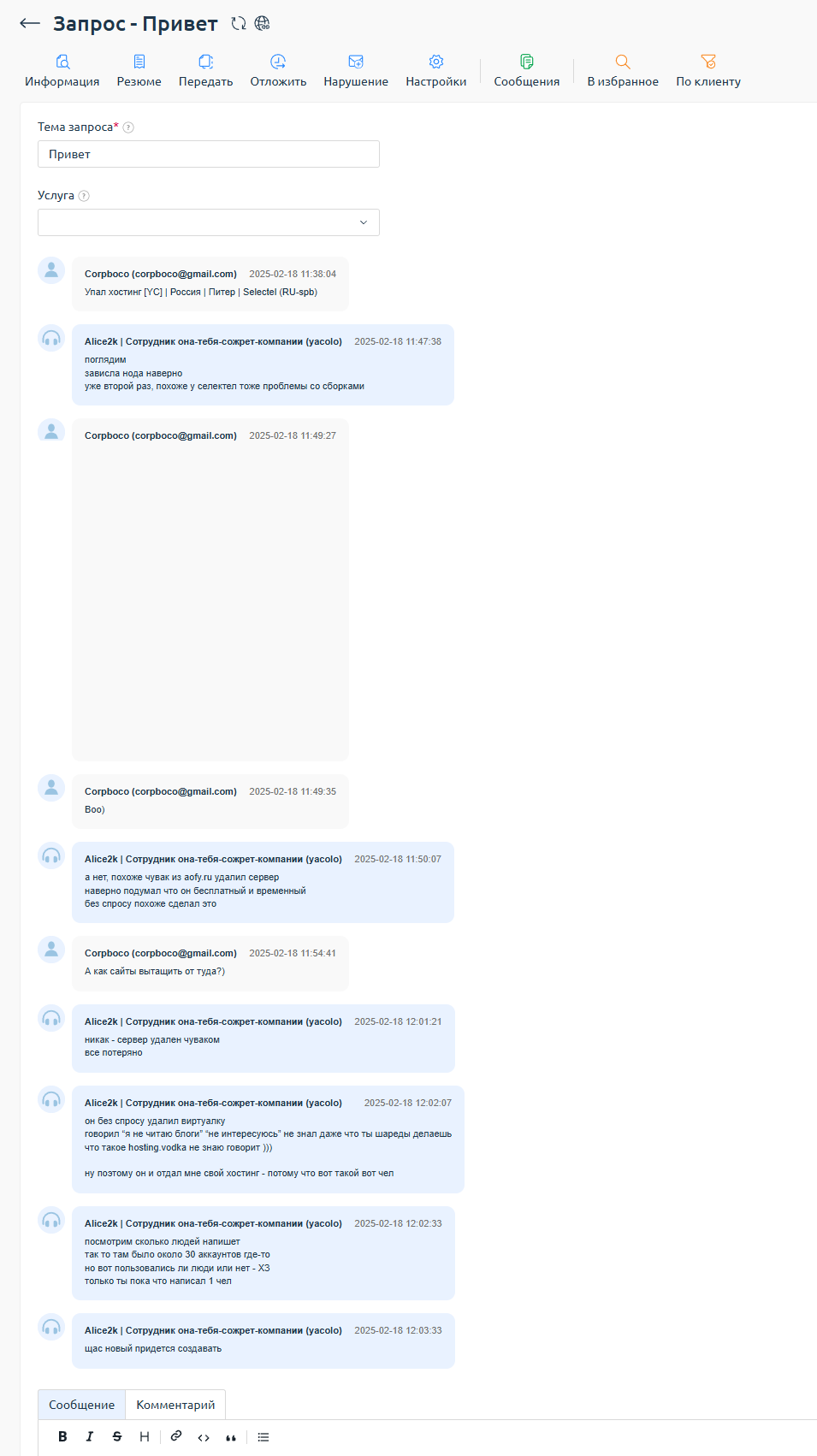
Больше ничего с серверами не случалось, просто работали «пока не сгорят»
Ничего разумеется за 1 год сгореть не могло.
Был еще чел какой-то, создавал клоны и закачивал туда диск абсолютно по максимуму всяким говном, видосы, архивы. Ну короче вероятно хотел забить диск на сервере на максимум. Может быть хотел провести эксперимент какой-то удалю я его или нет. В итоге да, он забил около 200 ГБ из 2 ТБ и сдался. Пока что места свободного дохуя поэтому я до сих пор даже не удалил те его мусорные 10-30 аккаунтов.
Сколько вообще пользуются хостингом ?
если 1 домен — то это технический домен авто создание
если 2 домена — значит кто-то реально пытался что-то создать

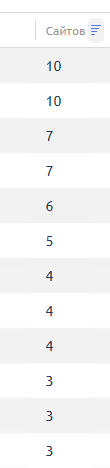
на другом сервере как видите не одного кто пользуется
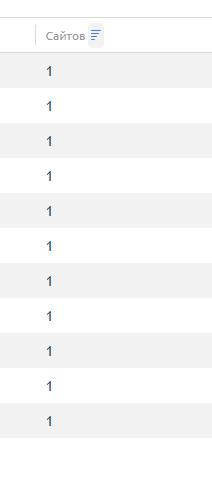
еще на другом пара человек
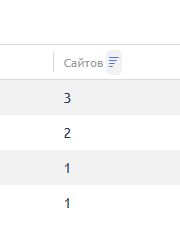
еще 3 человека
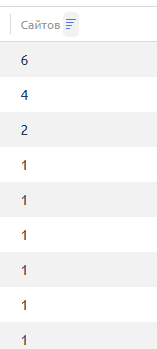
и вот тут люди пользуются видно
 Какая локация больше пользуется спросом?
Какая локация больше пользуется спросом?
- ОВХ сервер (за 12 евро с распродажи с двумя дисками 2x960 nvme в raid0) — первое место
- ОВХ сервер (за 14 евро с распродажи с двумя дисками 2x480 ssd в raid0) — второе место
- МСК сервер — третье место
- Кемерово сервер — четвертое место
- Пермь и Питер — пятое и шестое место
Так же мы скупили все Силикон Поверы какие в РФ шли — более 20 штук оказалось в наличии :)) Потом резко кончились, возможно партия которая была типо одноразовая партия ХЗ ХЗ, ведь такой удобный usb диск реально за 20 лет никто не разу не делал.
Сначала они стоили 9000р потом 12000р потом 18000р потом 20000р, потом 25000р, сейчас последняя штука (которая уже пол года лежит последняя именно т.к. оверпрайс) стоит

Прошло уже 15 лет с первой складчины ISPmanager — но у меня так и не пользуется спросом «шаред хостинг» ) Ни за 100р когда я делал, ни за 0 рублей. НО МОЖЕТ БЫТЬ ЧЕРЕЗ РЕЕСТР удастся?
Нада попробовать будет. 15 лет неудач — не останавливают меня, я все равно хочу узнать истину потребительского поведения.
Ведь именно сам функционал ISPmanager и дал мне намек на то, чтобы я захотел создать свой хостинг. Как только я купил VDS за 1000р у ihc.ru в 2010 году и поделил на 4 человек по 250р — я увидел функционал деления сервера на части и сразу осознал, как же хостинг провайдеры создают и как именно они зарабатывают.