Стражи публичных облаков: как мы внедряли анклавы Intel SGX для защиты чувствительных данных
Как развеять предубеждения потенциальных пользователей относительно безопасности публичных облаков? На помощь приходит технология Intel Software Guard Extensions (Intel SGX). Рассказываем, как мы внедрили её в своём облаке и какие преимущества от нашего решения получила компания Aggregion.

Принципы работы. Для хранения кода и данных анклавов технология Intel SGX выделяет область памяти – Processor Reserved Memory (PRM). ЦП защищает её от всех внешних обращений, в том числе от доступа со стороны ядра и гипервизора. В PRM содержится Enclave Page Cache (EPC), состоящий из блоков страниц объёмом 4 КиБ, при этом каждая страница должна принадлежать только одному анклаву, а их состояние фиксируется в Enclave Page Cache Metadata (EPCM) и контролируется ЦП.
Безопасность EPC обеспечивается за счёт Memory Encryption Engine (MEE), который генерирует ключи шифрования, хранящиеся в ЦП. Предполагается, что страницы могут быть расшифрованы только внутри физического ядра процессора.
Преимущества. Intel SGX позволяет повысить уровень доверия к публичному облаку со стороны организаций, использующих в своей работе чувствительные данные (пароли, ключи шифрования, идентификационные, биометрические, медицинские данные, а также информацию, относящуюся к интеллектуальной собственности). Речь идёт о представителях самых разных отраслей — финансового сектора, медицины и здравоохранения, ритейла, геймдева, телекома, медиасферы.
Проверили секцию /dev/sgx/virt_epc в файле /proc/$PID/smaps:
И воспользовались данным shell-скриптом, предварительно поставив SGX-драйвер (все действия осуществлялись внутри ВМ):
Стоит учитывать, что, если одна страница занимает 4 КиБ, то для 2048 страниц требуется 8 МиБ (2048 x 4 = 8192).
Найденная информация помогла понять, над чем именно нам предстоит работать. В результате мы сформировали следующие задачи:
Их выполнения было достаточно для интеграции Intel SGX в наше публичное облако.
Кроме того, мы дописали сбор статистики с учетом EPC:
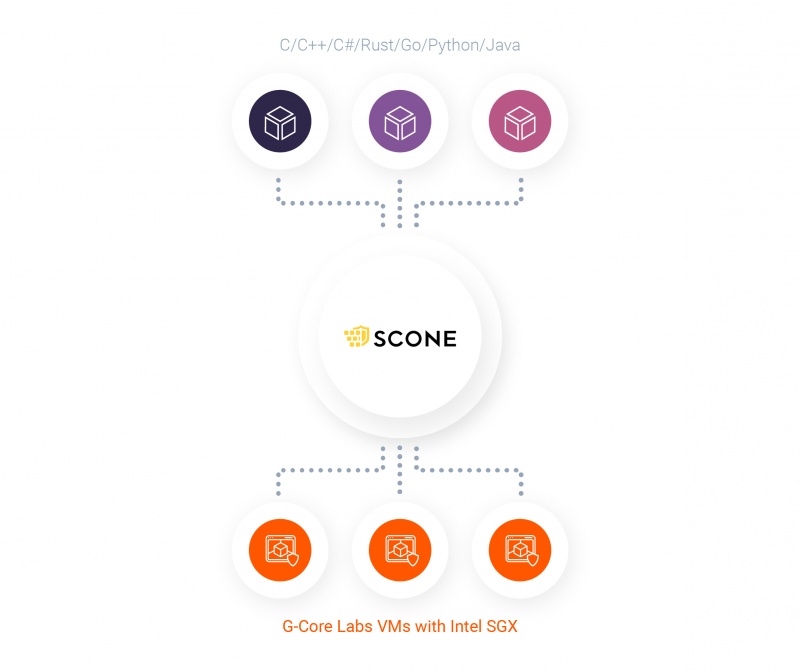
Научившись выделять виртуальные машины с поддержкой Intel SGX, мы использовали платформу SCONE компании Scontain, чтобы обеспечить возможность безопасного запуска контейнеризированных приложений в случае угроз со стороны привилегированного программного обеспечения. При использовании данного решения для прозрачной защиты файловых систем в средах Docker, Kubernetes и Rancher достаточно наличия процессора Intel с поддержкой SGX и драйвера Linux SGX.
Запуск каждого из контейнеров возможен лишь при наличии файла конфигурации, создаваемого клиентским расширением платформы SCONE. В нём содержатся ключи шифрования, аргументы приложения и переменные среды. Файлы, сетевой трафик и стандартные потоки ввода/вывода (stdin/stdout) прозрачно зашифрованы и недоступны даже для пользователей с правами root.
Платформа SCONE оснащена встроенной службой аттестации и конфигурации, проверяющей приложения на соответствие принятой политике безопасности. Она генерирует приватные ключи и сертификаты, которые должны быть доступны только в пределах анклава. Конфиденциальность и целостность данных в процессе их передачи обеспечиваются криптографическим протоколом TLS.
С помощью драйвера SGX для каждого анклава в виртуальном адресном пространстве резервируется до 64 ГБ памяти. Платформа SCONE поддерживает языки программирования C/C++/C#/Rust/Go/Python/Java. За счёт специального компилятора исходный код автоматически (без необходимости дополнительных модификаций) подготавливается к использованию совместно с Intel SGX.
Она предназначена для реализации совместных маркетинговых проектов представителями различных отраслей — финансовых и страховых услуг, государственного управления, телекоммуникаций, ритейла. Партнёры анализируют поведение потребителей, развивают таргетированное продвижение товаров и услуг, разрабатывают востребованные программы лояльности, обмениваясь и обрабатывая обезличенные массивы данных на платформе Aggregion. Поскольку утечка конфиденциальной информации крайне не желательна и грозит серьёзными репутационными рисками, компания уделяет особое внимание вопросам безопасности.
Софт Aggregion целиком ставится в контур поставщика данных, что подразумевает наличие в его распоряжении инфраструктуры с поддержкой Intel SGX. Теперь клиенты компании могут рассматривать подключение к нашему публичному облаку в качестве альтернативы аренде или покупке физических серверов.
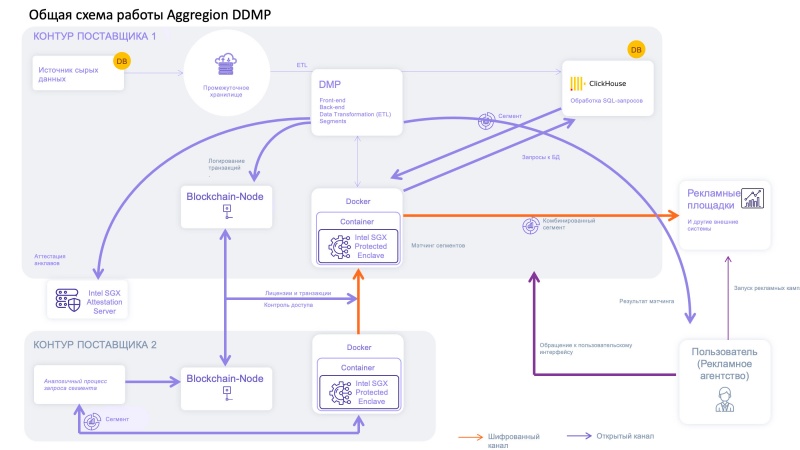
Принципы безопасной работы на платформе Aggregion. В контуре каждого поставщика чувствительные данные изолируются в анклавы Intel SGX, которые фактически представляют собой чёрные ящики: что происходит внутри, недоступно никому, в том числе и провайдеру облачной инфраструктуры. Проверка первоначального состояния анклава и возможности его использования для хранения конфиденциальной информации осуществляется за счёт удалённой аттестации, когда MrEnclave определяет хеш-значение.
Потенциальная польза для клиентов. Комбинирование баз данных нескольких поставщиков позволяет повысить эффективность совместных рекламных кампаний. При выделении целевой аудитории по заданным параметрам мэтчинг (сопоставление) сегментов выполняется непосредственно внутри контейнеров с поддержкой анклавов Intel SGX. За пределы выводится только конечный результат: например, численность пользователей, соответствующих выбранным атрибутам. Аналогичным образом оценивается эффективность проведенных кампаний: в анклавы выгружаются данные о рекламных показах и совершённых продажах для вычисления прироста покупок целевой группы относительно контрольной, который и выдаётся наружу для дальнейшего использования.
Почему же мы всё-таки решили внедрить данную технологию? Мы видим в применении Intel SGX возможность сократить потенциальную область кибератак за счёт создания дополнительного контура защиты облачной инфраструктуры G-Core Labs наряду с уже задействованными технологиями информационной безопасности и тем самым повысить доверие наших пользователей к хранению и обработке конфиденциальных данных. Надеемся, что в будущем нам ещё предстоит поделиться с вами успешными клиентскими кейсами, хотя и не берёмся утверждать, что наши статьи не будут основаны на историях обнаружения и устранения новых уязвимостей.
Кратко об Intel SGX и его роли в облаке
Intel Software Guard Extensions (Intel SGX) — набор инструкций ЦП, с помощью которых в адресном пространстве приложения создаются частные защищённые области (анклавы), где размещается код уровня пользователя. Технология обеспечивает конфиденциальность и целостность чувствительных данных. Путём изоляции в анклаве они получают дополнительную защиту как от несанкционированного внешнего доступа, в том числе со стороны провайдера облачных услуг, так и от внутренних угроз, включая атаки со стороны программного обеспечения привилегированного уровня.Принципы работы. Для хранения кода и данных анклавов технология Intel SGX выделяет область памяти – Processor Reserved Memory (PRM). ЦП защищает её от всех внешних обращений, в том числе от доступа со стороны ядра и гипервизора. В PRM содержится Enclave Page Cache (EPC), состоящий из блоков страниц объёмом 4 КиБ, при этом каждая страница должна принадлежать только одному анклаву, а их состояние фиксируется в Enclave Page Cache Metadata (EPCM) и контролируется ЦП.
Безопасность EPC обеспечивается за счёт Memory Encryption Engine (MEE), который генерирует ключи шифрования, хранящиеся в ЦП. Предполагается, что страницы могут быть расшифрованы только внутри физического ядра процессора.
Преимущества. Intel SGX позволяет повысить уровень доверия к публичному облаку со стороны организаций, использующих в своей работе чувствительные данные (пароли, ключи шифрования, идентификационные, биометрические, медицинские данные, а также информацию, относящуюся к интеллектуальной собственности). Речь идёт о представителях самых разных отраслей — финансового сектора, медицины и здравоохранения, ритейла, геймдева, телекома, медиасферы.
Наш подход к внедрению Intel SGX
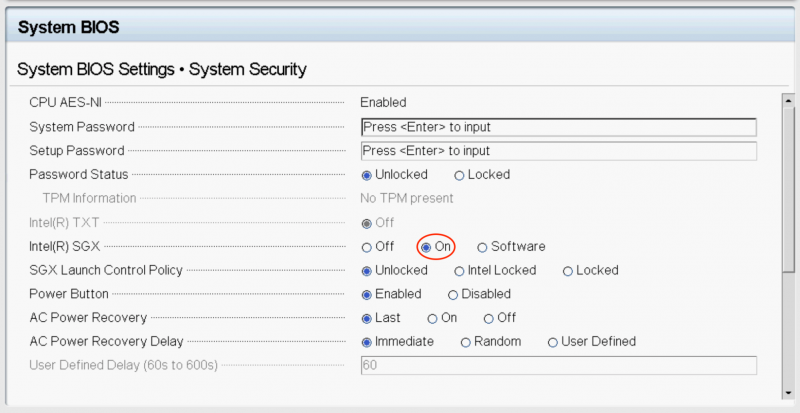
Чтобы в публичном облаке G-Core Labs появилась возможность выделять виртуальные машины с анклавами Intel SGX, нам пришлось пройти путь от компиляции патченного ядра KVM и QEMU до написания Python-скриптов в сервисах OpenStack Nova. Вычислительные узлы, которые планировалось использовать для выделения виртуальных машин повышенной безопасности, мы решили определить в отдельный агрегатор — тип вычислительных ресурсов, требующий дополнительной настройки. На таких узлах было необходимо:Включить поддержку Intel SGX на уровне BIOS.
Поставить патченные QEMU/KVM.
Изначально у нас не было понимания, как это должно работать и что в итоге мы должны прикрутить, чтобы получить ВМ нужной конфигурации. Разобраться с этим вопросом нам частично помогло руководство Intel для разработчиков. С его помощью мы узнали, как подготовить вычислительный узел для работы с SGX и какими дополнительными параметрами должен обладать конфигурационный XML-файл виртуальной машины. Здесь же мы нашли исчерпывающую информацию, как с помощью виртуализации KVM сделать гостевую машину с использованием Intel SGX. Чтобы убедиться, что мы смогли обеспечить поддержку данной технологии, мы использовали два способа:Проверили секцию /dev/sgx/virt_epc в файле /proc/$PID/smaps:
[root@compute-sgx ~]# grep -A22 epc /proc/$PID/smaps
7f797affe000-7f797b7fe000 rw-s 00000000 00:97 57466526 /dev/sgx/virt_epc
Size: 8192 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Rss: 0 kB
Pss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Referenced: 0 kB
Anonymous: 0 kB
LazyFree: 0 kB
AnonHugePages: 0 kB
ShmemPmdMapped: 0 kB
FilePmdMapped: 0 kB
Shared_Hugetlb: 0 kB
Private_Hugetlb: 0 kB
Swap: 0 kB
SwapPss: 0 kB
Locked: 0 kB
THPeligible: 0
VmFlags: rd wr sh mr mw me ms pf io dc dd hgИ воспользовались данным shell-скриптом, предварительно поставив SGX-драйвер (все действия осуществлялись внутри ВМ):
[root@sgx-vm ~]# cat check_sgx.sh
#!/bin/bash
METRICS="sgx_nr_total_epc_pages \
sgx_nr_free_pages \
sgx_nr_low_pages \
sgx_nr_high_pages \
sgx_nr_marked_old \
sgx_nr_evicted \
sgx_nr_alloc_pages \
"
MODPATH="/sys/module/isgx/parameters/"
for metric in $METRICS ; do
echo "$metric= `cat $MODPATH/$metric`"
done
[root@sgx-vm ~]# curl -fsSL https://raw.githubusercontent.com/scontain/SH/master/install_sgx_driver.sh | bash -s - install -p metrics -p page0
[root@sgx-vm ~]# ./check_sgx.sh
sgx_nr_total_epc_pages= 2048
sgx_nr_free_pages= 2048
sgx_nr_low_pages= 32
sgx_nr_high_pages= 64
sgx_nr_marked_old= 0
sgx_nr_evicted= 0
sgx_nr_alloc_pages= 0Стоит учитывать, что, если одна страница занимает 4 КиБ, то для 2048 страниц требуется 8 МиБ (2048 x 4 = 8192).
Трудности разработки и их преодоление
Отсутствие какой-либо технической документации по интеграции Intel SGX в OpenStack было нашей основной трудностью на момент внедрения. Поиск привел нас к статье проекта SecureCloud, где был представлен способ управления виртуальными машинами с анклавами SGX.Найденная информация помогла понять, над чем именно нам предстоит работать. В результате мы сформировали следующие задачи:
- Добиться от сервиса OpenStack Nova генерации XML-файла с дополнительными параметрами для виртуальных машин с поддержкой Intel SGX.
- Написать фильтр планировщика OpenStack Nova с целью определения доступной памяти для анклавов на вычислительных узлах и осуществления некоторых других проверок.
Их выполнения было достаточно для интеграции Intel SGX в наше публичное облако.
Кроме того, мы дописали сбор статистики с учетом EPC:
# openstack usage show
Usage from 2020-11-04 to 2020-12-03 on project a968da75bcab4943a7beb4009b8ccb4a:
+---------------+--------------+
| Field | Value |
+---------------+--------------+
| CPU Hours | 47157.6 |
| Disk GB-Hours | 251328.19 |
| EPC MB-Hours | 26880.02 |
| RAM MB-Hours | 117222622.62 |
| Servers | 23 |
+---------------+--------------+Безопасная среда для запуска контейнеризированных приложений
Научившись выделять виртуальные машины с поддержкой Intel SGX, мы использовали платформу SCONE компании Scontain, чтобы обеспечить возможность безопасного запуска контейнеризированных приложений в случае угроз со стороны привилегированного программного обеспечения. При использовании данного решения для прозрачной защиты файловых систем в средах Docker, Kubernetes и Rancher достаточно наличия процессора Intel с поддержкой SGX и драйвера Linux SGX.
Запуск каждого из контейнеров возможен лишь при наличии файла конфигурации, создаваемого клиентским расширением платформы SCONE. В нём содержатся ключи шифрования, аргументы приложения и переменные среды. Файлы, сетевой трафик и стандартные потоки ввода/вывода (stdin/stdout) прозрачно зашифрованы и недоступны даже для пользователей с правами root.
Платформа SCONE оснащена встроенной службой аттестации и конфигурации, проверяющей приложения на соответствие принятой политике безопасности. Она генерирует приватные ключи и сертификаты, которые должны быть доступны только в пределах анклава. Конфиденциальность и целостность данных в процессе их передачи обеспечиваются криптографическим протоколом TLS.
С помощью драйвера SGX для каждого анклава в виртуальном адресном пространстве резервируется до 64 ГБ памяти. Платформа SCONE поддерживает языки программирования C/C++/C#/Rust/Go/Python/Java. За счёт специального компилятора исходный код автоматически (без необходимости дополнительных модификаций) подготавливается к использованию совместно с Intel SGX.
Кейс Aggregion
Завершив все необходимые работы по интеграции Intel SGX, мы подключили к нашему публичному облаку платформу управления распределёнными данными компании Aggregion.Она предназначена для реализации совместных маркетинговых проектов представителями различных отраслей — финансовых и страховых услуг, государственного управления, телекоммуникаций, ритейла. Партнёры анализируют поведение потребителей, развивают таргетированное продвижение товаров и услуг, разрабатывают востребованные программы лояльности, обмениваясь и обрабатывая обезличенные массивы данных на платформе Aggregion. Поскольку утечка конфиденциальной информации крайне не желательна и грозит серьёзными репутационными рисками, компания уделяет особое внимание вопросам безопасности.
Софт Aggregion целиком ставится в контур поставщика данных, что подразумевает наличие в его распоряжении инфраструктуры с поддержкой Intel SGX. Теперь клиенты компании могут рассматривать подключение к нашему публичному облаку в качестве альтернативы аренде или покупке физических серверов.
Принципы безопасной работы на платформе Aggregion. В контуре каждого поставщика чувствительные данные изолируются в анклавы Intel SGX, которые фактически представляют собой чёрные ящики: что происходит внутри, недоступно никому, в том числе и провайдеру облачной инфраструктуры. Проверка первоначального состояния анклава и возможности его использования для хранения конфиденциальной информации осуществляется за счёт удалённой аттестации, когда MrEnclave определяет хеш-значение.
Потенциальная польза для клиентов. Комбинирование баз данных нескольких поставщиков позволяет повысить эффективность совместных рекламных кампаний. При выделении целевой аудитории по заданным параметрам мэтчинг (сопоставление) сегментов выполняется непосредственно внутри контейнеров с поддержкой анклавов Intel SGX. За пределы выводится только конечный результат: например, численность пользователей, соответствующих выбранным атрибутам. Аналогичным образом оценивается эффективность проведенных кампаний: в анклавы выгружаются данные о рекламных показах и совершённых продажах для вычисления прироста покупок целевой группы относительно контрольной, который и выдаётся наружу для дальнейшего использования.
Выводы
Мы понимаем, что Intel SGX не является панацеей по защите данных и можно найти ряд статей, порицающих эту технологию, в том числе и на Хабре. Периодически появляются сообщения об атаках, способных извлечь конфиденциальные данные из анклавов: так, в 2018 году бреши в SGX пробили Meltdown и Spectre, в 2020 году – SGAxe и CrossTalk. В свою очередь компания Intel устраняет выявленные уязвимости с помощью обновлений микрокода процессоров.Почему же мы всё-таки решили внедрить данную технологию? Мы видим в применении Intel SGX возможность сократить потенциальную область кибератак за счёт создания дополнительного контура защиты облачной инфраструктуры G-Core Labs наряду с уже задействованными технологиями информационной безопасности и тем самым повысить доверие наших пользователей к хранению и обработке конфиденциальных данных. Надеемся, что в будущем нам ещё предстоит поделиться с вами успешными клиентскими кейсами, хотя и не берёмся утверждать, что наши статьи не будут основаны на историях обнаружения и устранения новых уязвимостей.