Ни на что не намекаем, но до Нового года остался всего 31 день. Декабрь пролетит в два счёта, поэтому если вы спросите, не рановато ли для создания праздничной атмосферы и новогоднего настроения, то мы уверенно ответим — сейчас самое время :) Так что разбираемся с текущими задачами и бежим за ёлкой!
 Статьи и инструкции
Статьи и инструкции
Как перенести сервер Windows с помощью Кибер Бэкап
Кибер Бэкап (ex-Acronis) поможет вам не только в вопросах резервного копирования, с его помощью вы сможете выполнить перенос ОС Windows с одного сервера на другой путём снятия полной копии системы и разворачивания бэкапа на новом сервере. О том, как это сделать, рассказали в инструкции.
firstvds.ru/technology/perenos-servera-windows-s-pomoschyu-kiber-bekap-ex-acronis
Как обновить веб-окружение Битрикс
Как и любое другое программное обеспечение, веб-окружение Битрикс также нуждается в обновлении, и для этого у него есть собственные инструменты. О том, как ими воспользоваться, рассказываем в статье.
firstvds.ru/technology/obnovlenie-veb-okruzheniya-bitriks
Главное о резервном копировании Linux
Кажется, о резервном копировании можно говорить вечно, и вопросы всё равно никогда не перестанут поступать.Что копировать, куда, как и когда? Сколько хранить данные и как их проверять? В новой статье мы постарались ответить на эти вопросы и обозначить основные моменты, на которые следует обратить внимание при настройке резервного копирования ОС Linux.
firstvds.ru/blog/rezervnoe-kopirovanie-na-linux
Как установить и настроить nginx
Приготовили для вас большой гайд, с помощью которого вы сможете разобраться во всех нюансах установки и настройки веб-сервера nginx, а также познакомитесь с его основными возможностями.
firstvds.ru/technology/ustanovka-i-nastroyka-nginx
Habr: самое интересное за ноябрь
Иногда нам кажется, что ну вот теперь-то уже не о чем писать… Но наши авторы без передышки находят всё новые и новые темы. Если вы тоже хотите узнать, кто повлиял на массовое распространение флешек, зачем строится плавучая страна-датацентр и как выбрать блок питания в 2023 году — приглашаем в наш блог!
habr.com/ru/companies/first/articles/
- Битва за флешку: кто изобрел USB-накопитель?
- Страна-датацентр: корабль с 10 000 Nvidia H100 хочет стать убежищем для разработчиков ИИ. Но всё ли то, чем кажется?
- Радиоприёмник в стиле японского минимализма
- Топ-10 блоков питания в 2023 году: от бюджетных и компактных до дорогих и мощных
 VC: самое интересное за ноябрь
VC: самое интересное за ноябрь
Тем временем в блоге на VC тоже вышло много интересного. Но не будем спойлерить, это лучше прочитать самому :)
vc.ru/s/1252651-firstvds
- Наш след в высоких технологиях: топ-5 IT-продуктов, которые придумали в России
- История клавиатуры: как все начиналось и чем сейчас удивляют производители
- Скажем нет кифосколиозу: как выбрать удобное компьютерное кресло под себя
- Кодинг в СССР: языки программирования, которые оставили яркий след в истории IT
Стань автором FirstVDS
Ищем технических писателей для блогов на Хабре и VC
 firstvds.ru/blog/ischem-avtorov-dlya-bloga-firstvds-na-habr-i-vc
Новости
firstvds.ru/blog/ischem-avtorov-dlya-bloga-firstvds-na-habr-i-vc
Новости
А теперь к главной новости ноября.
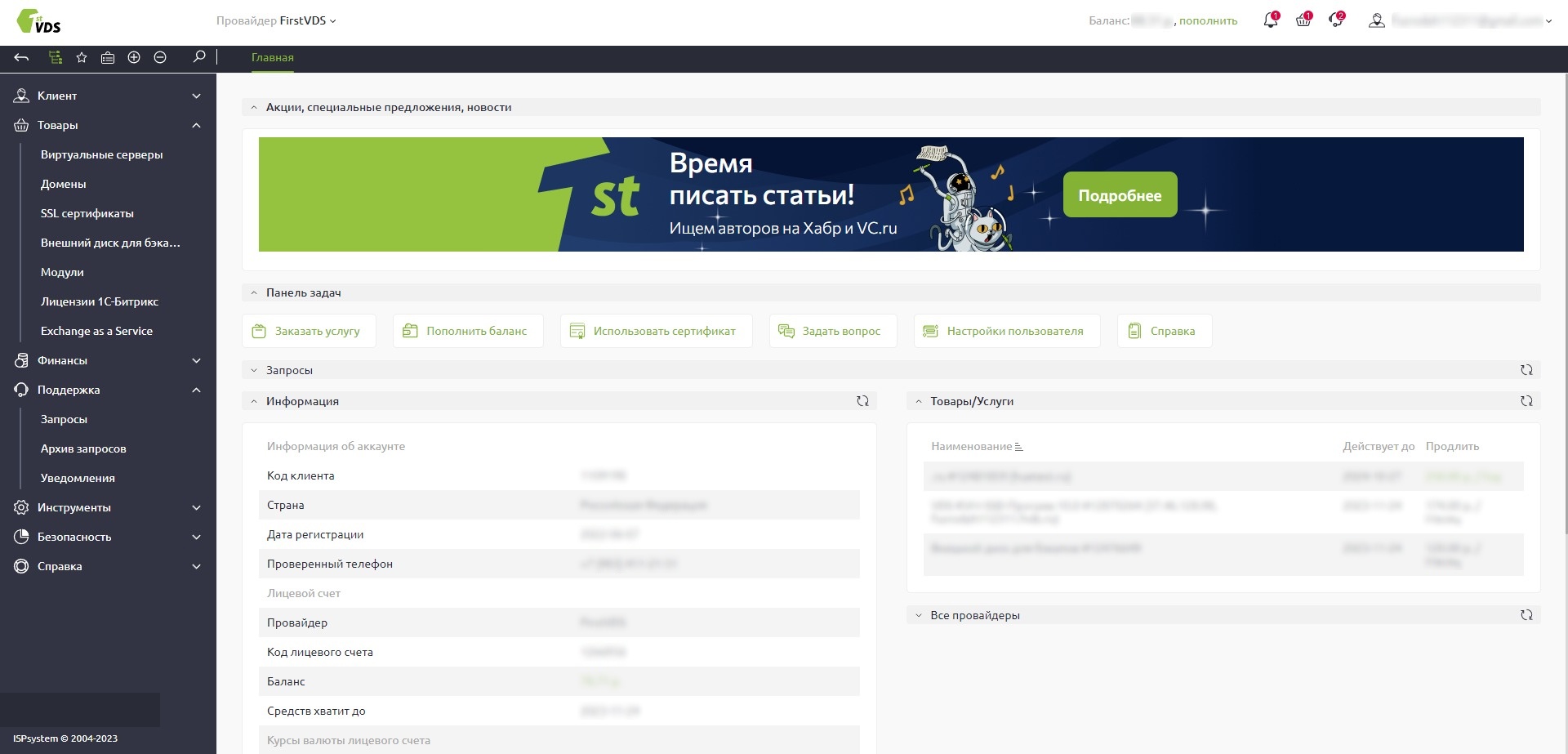
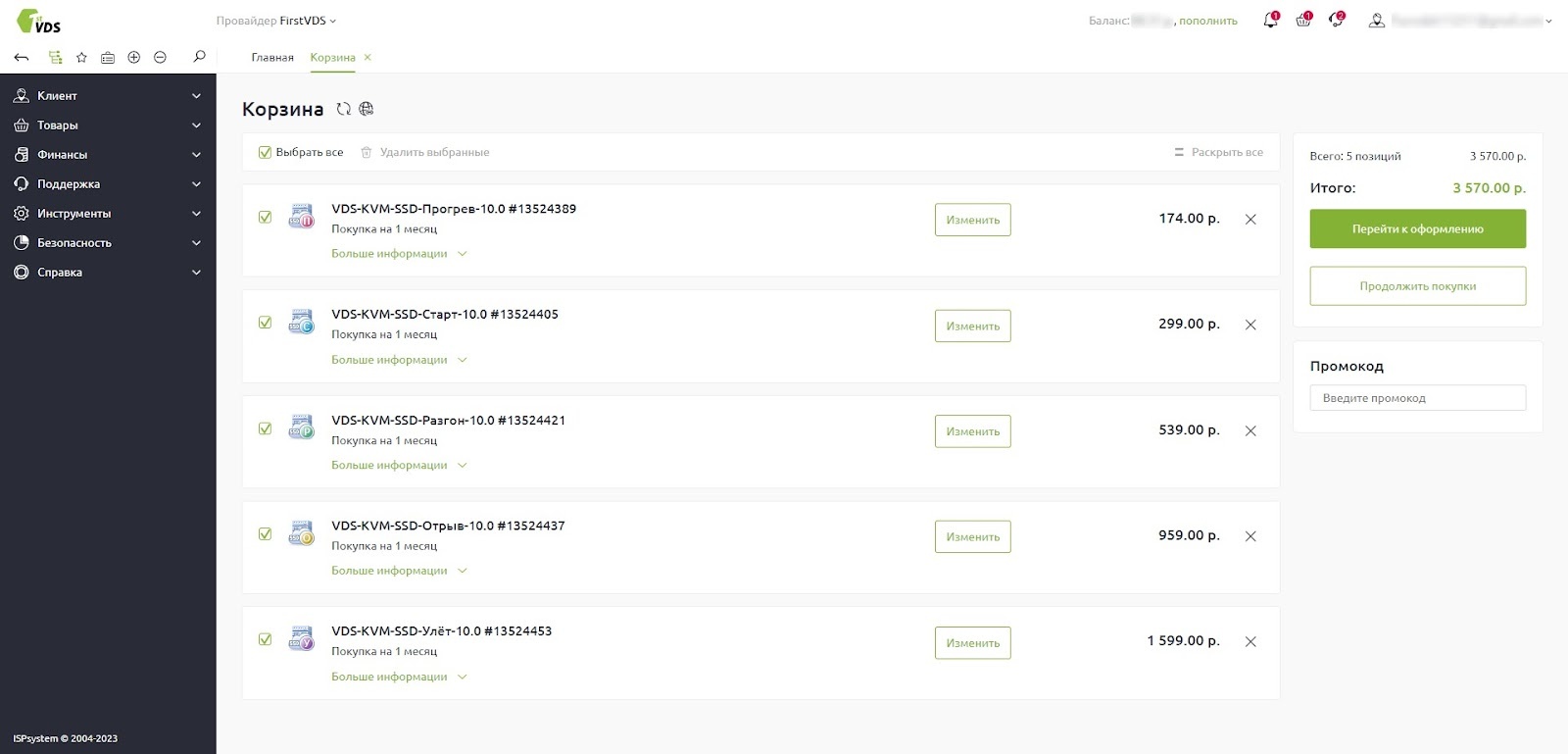
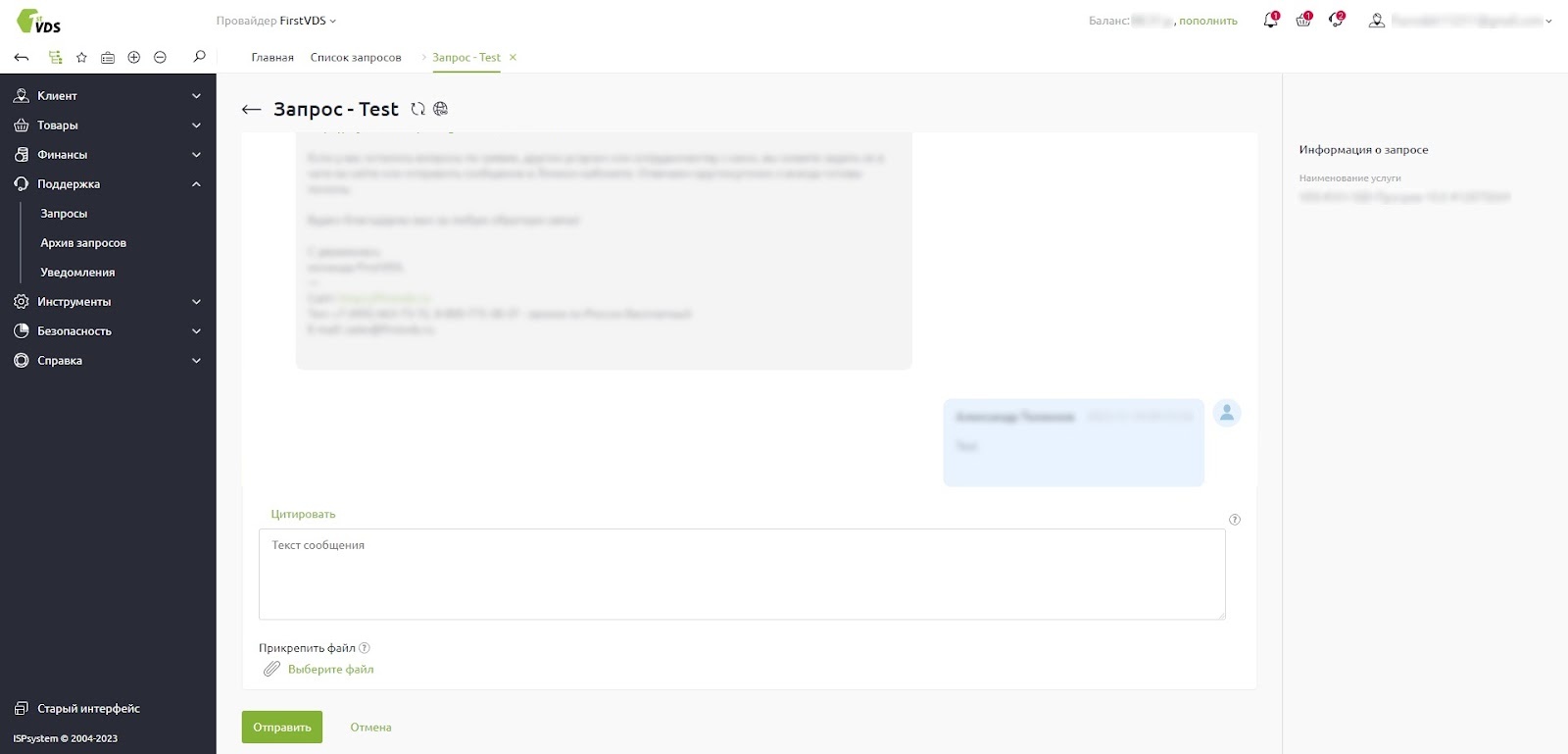
 Обновили личный кабинет: современный дизайн и удобный интерфейс
Обновили личный кабинет: современный дизайн и удобный интерфейс
Личный кабинет получил масштабное обновление. Дизайн стал более современным и лёгким, а интерфейс — удобным и интуитивно понятным. Несмотря на изменения в дизайне, Личный кабинет сохранил прежнюю логику и структуру — всё осталось на своих местах. Конечно, не обошлось без моментов, которые мы хотели бы улучшить, поэтому в будущем продолжим работать над Личным кабинетом, чтобы вам было ещё удобнее пользоваться им.
firstvds.ru/blog/obnovili-lichnyy-kabinet-sovremennyy-dizayn-i-udobnyy-interfeys
Релизы и уязвимости
Релиз FreeBSD 14.0
Спустя 2,5 года разработки опубликован релиз FreeBSD 14.0, эта ветка станет последней с поддержкой 32-разрядных платформ. Среди основных изменений: в качестве командного интерпретатора по умолчанию выставлен /bin/sh, улучшена поддержка облачных систем, добавлены новые утилиты fwget, base64, tcpsso, файловая система tarfs, а также инструментарий boottrace для отслеживания событий, произошедших на этапе загрузки и завершении работы системы.
www.opennet.ru/opennews/art.shtml?num=60120
Релиз OpenSSL 3.2.0
После восьми месяцев разработки сформирован релиз криптографической библиотеки OpenSSL 3.2.0. Добавлена поддержка: QUIC, сжатия с использованием библиотек zlib, zstd и Brotli, детерминированного варианта цифровых подписей ECDSA, расширенных вариантов цифровых подписей с открытым ключом Ed25519 и Ed448, режима шифрования AES-GCM-SIV, механизма быстрого открытия TCP-соединений.
www.opennet.ru/opennews/art.shtml?num=60174
Новый метод кражи ключей SSH
Исследователи обнаружили новый метод хищения криптографических ключей в протоколе Secure Shell (SSH). Уязвимость ограничена шифрованием RSA и может быть использована для перехвата данных между корпоративными серверами и удалёнными клиентами, также угроза распространяется на соединения IPsec, включая VPN-сервисы. Уязвимость активируется при искусственно вызванной или случайно возникшей ошибке в процессе «рукопожатия» (handshake). Злоумышленники могут использовать похищенный ключ для имитации скомпрометированного сервера и перехвата учётных данных пользователей.
3dnews.ru/1095953/obnarugen-noviy-metod-kragi-klyuchey-ssh-millioni-soedineniy-okazalis-pod-ugrozoy
Три уязвимости в контроллере ingress-nginx от Kubernetes
В контроллере ingress-nginx от проекта Kubernetes обнаружены три уязвимости, позволяющие в конфигурации по умолчанию получить доступ к настройкам объекта ingress, а с их помощью и привилегированный доступ к кластеру. Две из них проявляются только в выпусках ingress-nginx до версии 1.9.0, а третья — до версии 1.8.0. Для осуществления атаки злоумышленник должен иметь доступ к конфигурации ingress-объекта.
www.opennet.ru/opennews/art.shtml?num=60055
Ботнет Ddostf атакует серверы MySQL
Специалисты AhnLab Security Emergency response Center (ASEC) предупредили, что серверы MySQL подвергаются атакам ботнета Ddostf, который работает по схеме DDoS-as-a-Service. Злоумышленники сканируют интернет в поисках доступных серверов MySQL и пытаются взломать их, брутфорсом подбирая учётные данные администратора, а затем создают на скомпрометированных серверах DLL-файлы с вредоносными функциями. Компания ASEC рекомендует администраторам MySQL своевременно устанавливать обновления и ответственно подходить к паролям.
xakep.ru/2023/11/17/ddostf-mysql/