Новая зона доступности ru‑central1‑e введена в эксплуатацию


Спасибо, что используете Yandex Cloud. Мы постоянно работаем над тем, чтобы ваш опыт взаимодействия с сервисами был еще лучше, и сегодня хотим поделиться отличной новостью.
Мы ввели в эксплуатацию новую зону доступности — ru‑central1‑e.
Зона базируется в новом дата-центре Яндекса, с независимой системой питания и сети. Ru‑central1‑e расположена совсем рядом с зоной ru-central1-a, поэтому задержка передачи данных между ними минимальна — меньше 1 мс.
Новая зона доступности — полноценный дата‑центр с независимой системой питания и сети. Её ключевые характеристики:
- Расположение рядом с зоной ru‑central1‑a обеспечивает минимальную задержку передачи данных (менее 1 мс).
- Мощность — 40 МВт, 2,8 тыс. стоек.
- Пропускная способность — 25,6 Тб/сек.
- Энергоэффективность: средний показатель PUE — 1,1 (на 27% ниже мировых средних значений). Достичь такого результата позволила технология фрикулинга — охлаждения серверных стоек уличным воздухом круглый год.
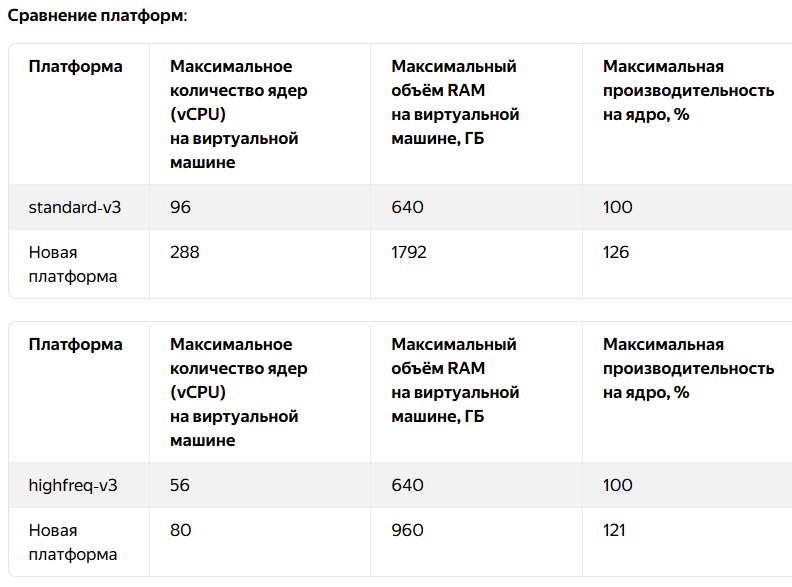
Какие платформы доступны в ru‑central1‑e
Пользователи новой зоны могут подключать:
- платформа прошлого поколения: standard‑v3;
- новые платформы.
Как новая зона улучшает работу с управляемыми базами данных
Низкая задержка между ru‑central1‑a и ru‑central1‑e (~1 мс) кардинально меняет возможности построения отказоустойчивых кластеров. Теперь можно создавать решения, которые работают практически как «в одном дата-центре», сохраняя сценарии высокой доступности и аварийного восстановления без роста задержки.
Основные преимущества:
- Высокая доступность без заметного штрафа по задержкам. Синхронная или кворумная репликация «стоит» ~1 мс — подтверждение записи ускоряется.
- Разнесение приложения и базы данных по зонам без ощущения «разных дата-центров». Если приложение находится в зоне A, а кластер «растянут» между A и E, доступ к базе данных выглядит почти как локальный.
- Снижение потребности «отключать надёжность ради скорости». При задержке в 1 мс многие сценарии можно держать на безопасных настройках без потери производительности.
- Более предсказуемые задержки. Меньше шансов, что кворумные подтверждения упрутся в таймауты на пиках нагрузки — кластеры стабильнее переживают всплески без каскадных эффектов.
Кроме того:
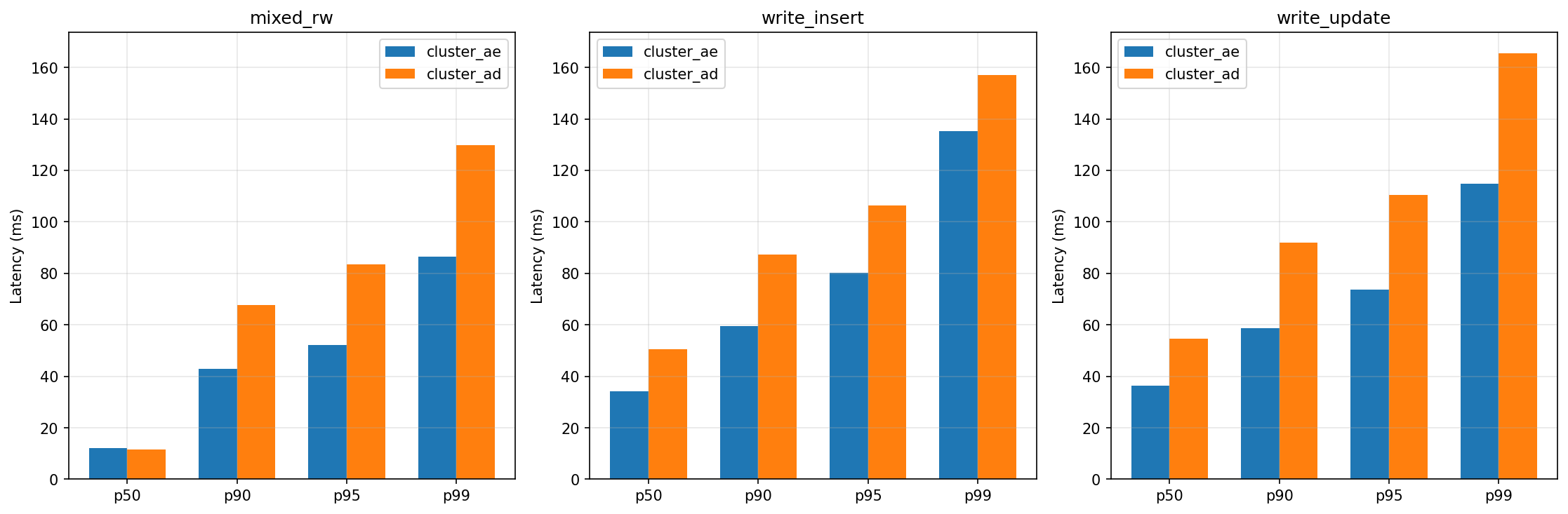
Кластер A‑E (мастер в зоне A, реплика в зоне E) быстрее кластера A‑D (реплика в зоне D) по всем метрикам записи.
Снижение задержки (latency):
- p50 при write_update — на ~36% (35 мс против 55 мс);
- p99 при write_update — на ~30% (115 мс против 165 мс).
- write_update — на ~33% (2000 против 1500 QPS);
- write_insert — на ~37% (2000 против 1460 QPS);
- mixed_rw — на ~25% (3500 против 2800 QPS).
Стабильнее по динамике задержек: у A‑E снижение задержки держится в диапазоне 60–65 мс, у A‑D — колеблется от 75 до 127 мс.
Меньше «медленных» запросов: кривая распределения задержек у A‑E левее, хвост (p99) короче.
Общий выигрыш по QPS — 25–45% в зависимости от нагрузки и уровня конкурентности.
Конкретные выгоды для разных СУБД
Yandex Managed Service for MySQL и синхронная или кворумная репликации
- Ускорение подтверждения транзакции за счёт меньшей задержки по времени между дата-центрами.
- «Как в одном дата-центре». Раньше из‑за задержек приложение приходилось держать в одной зоне, и распределять хосты кластера по зонам было бессмысленно. Теперь вы можете повысить отказоустойчивость: разместить и приложение, и базы данных в разных зонах — если приложение поддерживает такую конфигурацию.
- Больше свободы в топологии. Межзональная высокая доступность становится стандартом, а не премиум‑опцией.
Yandex StoreDoc
Раньше клиенты сталкивались с проблемой: при массовых записях с writeConcern: 1 реплики начинали отставать, а последующие запросы с writeConcern: majority падали по таймаутам. Это выглядело так, будто кластер недоступен на запись. Низкая межзональная задержка снижает мотивацию включать асинхронные подтверждения, которые ускоряют запись ценой надёжности. В результате повышается и доступность на запись, и устойчивость при отказах.
При задержке ~1 мс можно:
- держать первичную и вторичную реплики в двух зонах (A–E);
- писать с безопасным writeConcern (например, majority или в кворумном режиме);
- получать скорость, близкую к «одному дата-центру», без задержки репликации и рисков для высокой доступности.
Кому особенно полезна новая зона
Пользователи, для которых критичны задержки, теперь могут:
- уже имеющееся приложение в зоне А разнести и на зону E;
- «растянуть» кластер базы данных между ними;
- получить межзональную отказоустойчивость без заметной потери по задержкам.
yandex.cloud
0 комментариев
Вставка изображения
Оставить комментарий