Ралли, от бенчмаркинга до постоянного улучшения
Сохранение высокого уровня качества при постоянном улучшении наших предложений требует от нас возможности определять и измерять это качество, обнаруживать вариации и исследовать, есть ли деградация.
Чтобы достичь этого, мы определили OpenStack (решение, на котором построено предложение Public Cloud), два основных момента, которые, по нашему мнению, необходимы для клиентов:
В этой статье основное внимание уделяется первому вопросу: как в OVH мы измеряем производительность API Public Cloud. Я представлю решение, которое мы создали и как оно вписывается в экосистему ОВХ. Я закончу конкретный случай, который пока
Ралли: ориентированный на клиента инструмент тестирования OpenStack
Ралли — это кирпич проекта OpenStack, который определяется как Benchmarking как сервисное решение. Его роль заключается в проверке платформы OpenStack с точки зрения клиента и извлечении мер времени выполнения.
Проект, разработанный в Python, был начат в 2013 году. Версия 1.0.0 только что была выпущена в июле 2018 года. Выбор использования этого проекта в OVH был относительно прост, так как он является частью экосистемы OpenStack и что она обеспечивает функциональность, которая отвечает нашим потребностям.
Ралли предлагает запустить сценарии, которые являются наборами последовательных тестов, которые могут быть параметризованы с большей или меньшей степенью сложности. Таким образом, можно, например, просто протестировать создание маркера аутентификации и подтвердить операцию. Возможны и другие более сложные манипуляции: протестировать в одном сценарии аутентификацию и создание нескольких экземпляров путем присоединения томов. Эта гибкость позволяет нам представить довольно легко и без ограничений очень конкретные тесты. Ралли изначально обеспечивает очень много сценариев, классифицированных функциональными кирпичами (Nova, Neutron, Keystone, Glance, например).
Ралли измеряет время отклика на каждом этапе сценария и целиком. Данные сохраняются в базах данных и могут быть экспортированы в виде отчетов HTML или JSON. Инструмент способен повторять несколько раз по одному сценарию и вычислять средние значения, а также другие статистические данные (медиана, 90-й процентиль, 95-й процентиль, минимум, максимум) путем итерации и по всем из них.
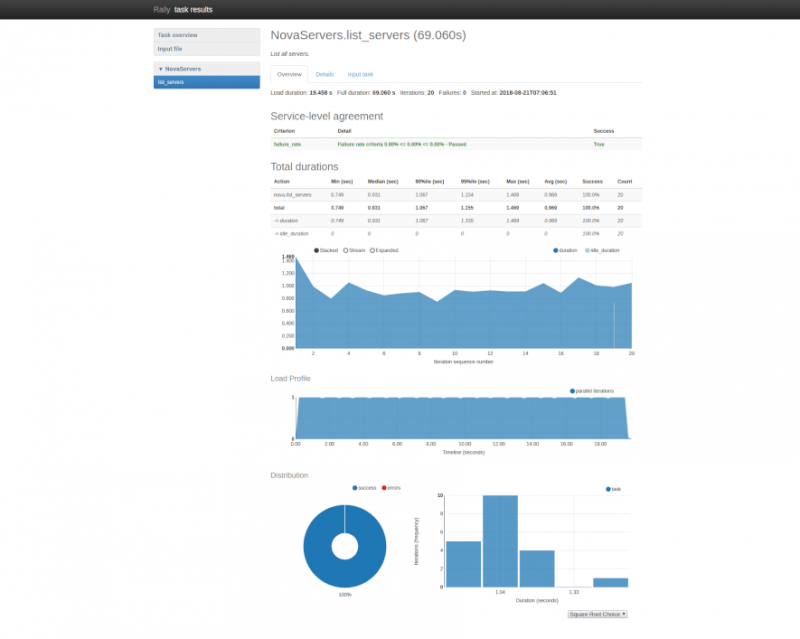
Ралли также поддерживает концепцию соглашения об уровне обслуживания (SLA), то есть возможность определить приемлемую частоту ошибок по количеству итераций, чтобы считать, что общий тест является успешным.
Еще один момент, который обратился к нам в этом проекте, — это возможность запуска тестов как конечного пользователя без роли администратора. Таким образом, мы можем полностью погрузиться в наши клиенты.
Показатель эффективности
Наша первоначальная потребность — квалифицировать API для существующей платформы. Поэтому мы выполняем несколько раз в час ряд итераций тестов Rally для каждого функционального блока OpenStack во всех регионах.
Программная квалификация
Другое использование предусмотрено, когда мы должны выполнять патчи кода или выполнять обновления безопасности или программного обеспечения. В каждом из этих случаев трудно, без инструментов, измерять воздействие этих изменений. В качестве примера можно привести обновление ядра для последних недостатков безопасности (Spectre и Meldwon), которые объявили о снижении производительности. Ралли теперь позволяет нам легко оценить возможные последствия.
Аппаратная квалификация
Случай также может возникнуть, когда мы хотим протестировать новый ряд физических серверов для использования на панели управления OpenStack. Затем ралли позволяет нам проверить, есть ли разница в производительности.
Измерение хорошее, но ...
Давайте не будем забывать, что мы хотим визуализировать эволюцию времени отклика с течением времени. Ралли может предоставить HTML-отчет о выполнении сценария, поэтому в течение очень короткого периода времени. Тем не менее, он не может собрать отчеты обо всех своих выступлениях.
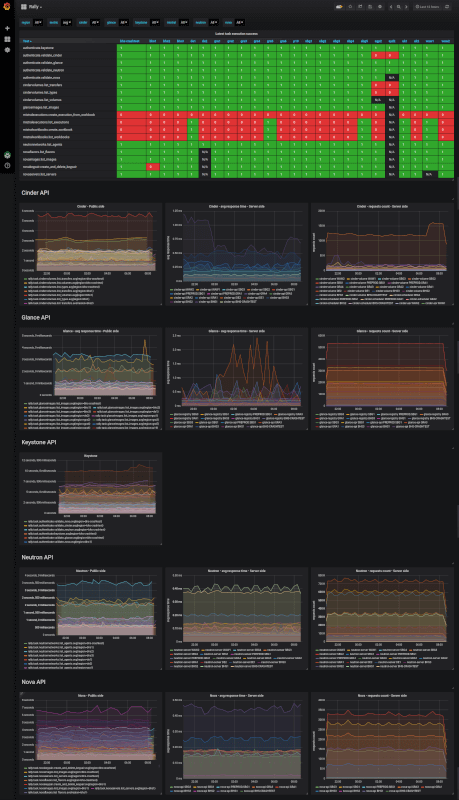
Таким образом, нам нужен способ извлечь данные из отчетов о запуске и суммировать их как график. Именно на этой платформе входит наша внутренняя платформа показателей, основанная на Warp10 для хранения и Grafana для информационных панелей.
Мы использовали экспорт JSON, реализованный в Rally, для извлечения измеренных значений во время тестов и нажатия их на платформу показателей. Затем мы создали приборную панель, которая позволяет нам визуализировать эти времена ответа с течением времени для каждого теста и по регионам. Мы можем легко визуализировать их эволюцию с течением времени и сравнивать время отклика по регионам. В соседних регионах (например, в Франции: GRA, RBX и SBG) мы должны получить практически одинаковое время отклика. Если это не так, мы ищем происхождение разницы, чтобы исправить проблему.
Конкретный корпус
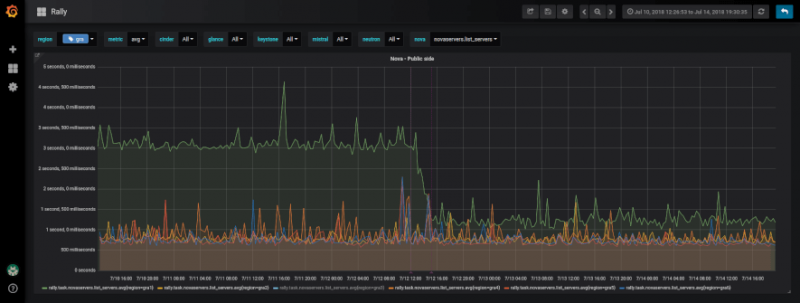
После настройки всех кирпичей мы сравнили эволюцию времени отклика между разными регионами. Мы поняли, что со временем и в некоторых регионах производительность ухудшилась для конкретных тестов нашего проекта. Например, есть тест, чтобы перечислить все экземпляры ралли проекта: среднее время составляет 600 мс, а в некоторых областях мы достигли 3 секунд.
Мы начали с проверки того, что неисправность связана только с нашим проектом, а не со всеми клиентами, что и было.
После дальнейших исследований мы обнаружили, что узкое место было на уровне базы данных для версии Juno OpenStack. Действительно, OpenStack применяет мягкое удаление при удалении данных. Это означает, что он помечает данные как удаленные, но фактически не удаляет их из таблицы. В нашем случае таблица «экземпляры» состоит из столбца «project_id» и «deleted». Когда Rally перечисляет серверы проекта, запрос имеет тип:
К сожалению, в Juno версии OpenStack в этой таблице нет индекса («project_ id», «deleted»), в отличие от версии OpenStack от Newton. В проекте Rally в каждом регионе тесты начинаются примерно с 3000 новых экземпляров каждый день. Через 3 месяца в наших базах данных было 270 000 экземпляров мягкого удаления. Этот большой объем данных в базах данных, связанных с отсутствием индексов в таблице, объясняет задержки, которые мы обнаружили в определенных регионах (только в версии Juno).
Таким образом, корректирующее действие, которое мы развернули, должно было внедрить в наши внутренние проекты механизм постоянного удаления данных с маркированным мягким удалением. Результат сразу же ощущался, разделив на четыре времени отклика на тест, чтобы отобразить серверы проекта Rally.
В этом случае мы создадим для наших клиентов, которым могут быть затронуты одни и те же проблемы, автоматическое архивирование данных с мягкими удалёнными данными в теневых таблицах OpenStack, предназначенных для этой цели.
Благодаря этому эталонному инструменту мы теперь имеем средства для выделения аномалий, которые могут существовать между регионами, и это приводит к различию в опыте пользователя. Мы внедряем необходимые решения для устранения этих диспропорций, чтобы получить наилучшие ощущения для соседних регионов. С помощью этого инструмента мы, естественно, входим в процесс непрерывного совершенствования, чтобы поддерживать и повышать качество использования наших API OpenStack.
Чтобы достичь этого, мы определили OpenStack (решение, на котором построено предложение Public Cloud), два основных момента, которые, по нашему мнению, необходимы для клиентов:
- Использование OpenStack API через клиенты OpenStack, библиотеки или API OVH v6;
- гарантированная производительность на экземплярах (процессор, оперативная память, диск, сеть).
В этой статье основное внимание уделяется первому вопросу: как в OVH мы измеряем производительность API Public Cloud. Я представлю решение, которое мы создали и как оно вписывается в экосистему ОВХ. Я закончу конкретный случай, который пока
Ралли: ориентированный на клиента инструмент тестирования OpenStack
Ралли — это кирпич проекта OpenStack, который определяется как Benchmarking как сервисное решение. Его роль заключается в проверке платформы OpenStack с точки зрения клиента и извлечении мер времени выполнения.
Проект, разработанный в Python, был начат в 2013 году. Версия 1.0.0 только что была выпущена в июле 2018 года. Выбор использования этого проекта в OVH был относительно прост, так как он является частью экосистемы OpenStack и что она обеспечивает функциональность, которая отвечает нашим потребностям.
Ралли предлагает запустить сценарии, которые являются наборами последовательных тестов, которые могут быть параметризованы с большей или меньшей степенью сложности. Таким образом, можно, например, просто протестировать создание маркера аутентификации и подтвердить операцию. Возможны и другие более сложные манипуляции: протестировать в одном сценарии аутентификацию и создание нескольких экземпляров путем присоединения томов. Эта гибкость позволяет нам представить довольно легко и без ограничений очень конкретные тесты. Ралли изначально обеспечивает очень много сценариев, классифицированных функциональными кирпичами (Nova, Neutron, Keystone, Glance, например).
Ралли измеряет время отклика на каждом этапе сценария и целиком. Данные сохраняются в базах данных и могут быть экспортированы в виде отчетов HTML или JSON. Инструмент способен повторять несколько раз по одному сценарию и вычислять средние значения, а также другие статистические данные (медиана, 90-й процентиль, 95-й процентиль, минимум, максимум) путем итерации и по всем из них.
Ралли также поддерживает концепцию соглашения об уровне обслуживания (SLA), то есть возможность определить приемлемую частоту ошибок по количеству итераций, чтобы считать, что общий тест является успешным.
Еще один момент, который обратился к нам в этом проекте, — это возможность запуска тестов как конечного пользователя без роли администратора. Таким образом, мы можем полностью погрузиться в наши клиенты.
Показатель эффективности
Наша первоначальная потребность — квалифицировать API для существующей платформы. Поэтому мы выполняем несколько раз в час ряд итераций тестов Rally для каждого функционального блока OpenStack во всех регионах.
Программная квалификация
Другое использование предусмотрено, когда мы должны выполнять патчи кода или выполнять обновления безопасности или программного обеспечения. В каждом из этих случаев трудно, без инструментов, измерять воздействие этих изменений. В качестве примера можно привести обновление ядра для последних недостатков безопасности (Spectre и Meldwon), которые объявили о снижении производительности. Ралли теперь позволяет нам легко оценить возможные последствия.
Аппаратная квалификация
Случай также может возникнуть, когда мы хотим протестировать новый ряд физических серверов для использования на панели управления OpenStack. Затем ралли позволяет нам проверить, есть ли разница в производительности.
Измерение хорошее, но ...
Давайте не будем забывать, что мы хотим визуализировать эволюцию времени отклика с течением времени. Ралли может предоставить HTML-отчет о выполнении сценария, поэтому в течение очень короткого периода времени. Тем не менее, он не может собрать отчеты обо всех своих выступлениях.
Таким образом, нам нужен способ извлечь данные из отчетов о запуске и суммировать их как график. Именно на этой платформе входит наша внутренняя платформа показателей, основанная на Warp10 для хранения и Grafana для информационных панелей.
Мы использовали экспорт JSON, реализованный в Rally, для извлечения измеренных значений во время тестов и нажатия их на платформу показателей. Затем мы создали приборную панель, которая позволяет нам визуализировать эти времена ответа с течением времени для каждого теста и по регионам. Мы можем легко визуализировать их эволюцию с течением времени и сравнивать время отклика по регионам. В соседних регионах (например, в Франции: GRA, RBX и SBG) мы должны получить практически одинаковое время отклика. Если это не так, мы ищем происхождение разницы, чтобы исправить проблему.
Конкретный корпус
После настройки всех кирпичей мы сравнили эволюцию времени отклика между разными регионами. Мы поняли, что со временем и в некоторых регионах производительность ухудшилась для конкретных тестов нашего проекта. Например, есть тест, чтобы перечислить все экземпляры ралли проекта: среднее время составляет 600 мс, а в некоторых областях мы достигли 3 секунд.
Мы начали с проверки того, что неисправность связана только с нашим проектом, а не со всеми клиентами, что и было.
После дальнейших исследований мы обнаружили, что узкое место было на уровне базы данных для версии Juno OpenStack. Действительно, OpenStack применяет мягкое удаление при удалении данных. Это означает, что он помечает данные как удаленные, но фактически не удаляет их из таблицы. В нашем случае таблица «экземпляры» состоит из столбца «project_id» и «deleted». Когда Rally перечисляет серверы проекта, запрос имеет тип:
SELECT * FROM instances WHERE project_id=’xxx’ AND deleted = 0 ;К сожалению, в Juno версии OpenStack в этой таблице нет индекса («project_ id», «deleted»), в отличие от версии OpenStack от Newton. В проекте Rally в каждом регионе тесты начинаются примерно с 3000 новых экземпляров каждый день. Через 3 месяца в наших базах данных было 270 000 экземпляров мягкого удаления. Этот большой объем данных в базах данных, связанных с отсутствием индексов в таблице, объясняет задержки, которые мы обнаружили в определенных регионах (только в версии Juno).
Таким образом, корректирующее действие, которое мы развернули, должно было внедрить в наши внутренние проекты механизм постоянного удаления данных с маркированным мягким удалением. Результат сразу же ощущался, разделив на четыре времени отклика на тест, чтобы отобразить серверы проекта Rally.
В этом случае мы создадим для наших клиентов, которым могут быть затронуты одни и те же проблемы, автоматическое архивирование данных с мягкими удалёнными данными в теневых таблицах OpenStack, предназначенных для этой цели.
Благодаря этому эталонному инструменту мы теперь имеем средства для выделения аномалий, которые могут существовать между регионами, и это приводит к различию в опыте пользователя. Мы внедряем необходимые решения для устранения этих диспропорций, чтобы получить наилучшие ощущения для соседних регионов. С помощью этого инструмента мы, естественно, входим в процесс непрерывного совершенствования, чтобы поддерживать и повышать качество использования наших API OpenStack.
0 комментариев
Вставка изображения
Оставить комментарий