От 15 000 подключений к базам данных до 100: история о долговых обязательствах DigitalOcean
Недавно за обедом меня попросил новый сотрудник: «Как выглядит технический долг DigitalOcean?»
Я не мог удержаться от улыбки, когда услышал вопрос. Инженеры-программисты, спрашивающие о техническом долге компании, равносильны задаче о кредитном балле. Это их способ оценить сомнительное прошлое компании и то, какой багаж они несут. И DigitalOcean не привыкать к техническому багажу.
Как поставщик облачных услуг, который управляет нашими собственными серверами и оборудованием, мы столкнулись с трудностями, с которыми многие другие стартапы не сталкивались в эту новую эру облачных вычислений. Эти сложные ситуации в конечном итоге привели к компромиссам, которые мы должны были сделать в самом начале нашего существования. И, как известно любой быстро растущей компании, технические решения, которые вы принимаете на раннем этапе, как правило, догоняют вас позже.
Глядя на новый прокат через стол, я глубоко вздохнул и начал. «Позвольте мне рассказать вам о времени, когда у нас было 15 000 прямых подключений к нашей базе данных…»

История, которую я рассказал нашему новобранцу, — это история крупнейшей на сегодняшний день технической реархитектуры DigitalOcean. Это было усилие всей компании, которое длилось несколько лет и преподало нам много уроков. Надеюсь, что это поможет будущим разработчикам DigitalOcean — или любым разработчикам, попавшим в непростую головоломку с техническими проблемами.
С чего все началось
DigitalOcean был одержим простотой с самого начала. Это одна из наших основных ценностей: стремиться к простым и элегантным решениям. Это относится не только к нашей продукции, но и к нашим техническим решениям. Нигде это так заметно, как в нашей первоначальной конструкции системы.
Как и GitHub, Shopify и Airbnb, DigitalOcean была запущена как приложение Rails в 2011 году. Приложение Rails, внутренне известное как Cloud, управляло всеми взаимодействиями пользователей как в пользовательском интерфейсе, так и в открытом API. В оказании помощи Rails работали две службы Perl: планировщик и DOBE (DigitalOcean BackEnd). Планировщик планировал и назначал Droplets гипервизорам, а DOBE отвечал за создание реальных виртуальных машин Droplet. В то время как облако и планировщик работали как отдельные службы, DOBE работал на каждом сервере в парке.
Ни Cloud, ни Scheduler, ни DOBE не общались напрямую друг с другом. Они общались через базу данных MySQL. Эта база данных выполняла две функции: хранение данных и посредничество в общении. Все три службы использовали одну таблицу базы данных в качестве очереди сообщений для передачи информации.
Каждый раз, когда пользователь создавал новую каплю, Cloud вставлял новую запись события в очередь. Планировщик непрерывно опрашивает базу данных каждую секунду на предмет новых событий Droplet и планирует их создание на доступном гипервизоре. Наконец, каждый экземпляр DOBE будет ожидать создания новых запланированных капель и выполнения задачи. Чтобы эти серверы могли обнаружить какие-либо новые изменения, каждый из них должен будет опросить базу данных на предмет новых записей в таблице.
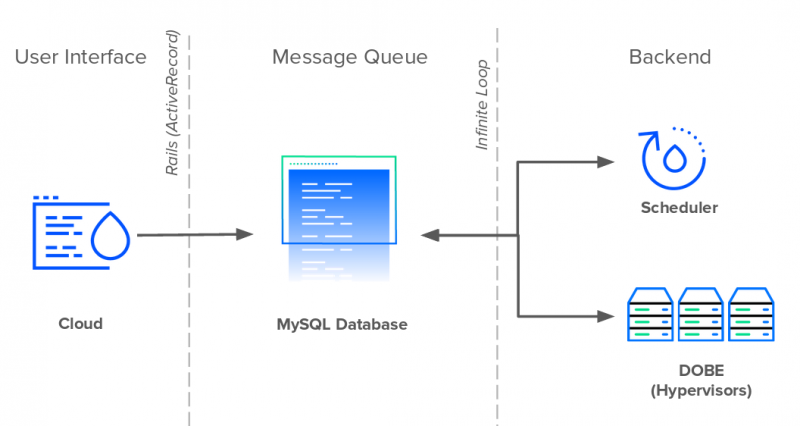
Хотя бесконечные циклы и предоставление каждому серверу прямого подключения к базе данных, возможно, были элементарными с точки зрения проектирования системы, это было просто, и это работало — особенно для технической команды с небольшим персоналом, работающей в сжатые сроки и быстро растущей пользовательской базы.
В течение четырех лет очередь сообщений базы данных составляла основу технологического стека DigitalOcean. В течение этого периода мы приняли микросервисную архитектуру, заменили HTTPS на gRPC для внутреннего трафика и вытеснили Perl в пользу Golang для внутренних сервисов. Однако все дороги все еще вели к этой базе данных MySQL.
Важно отметить, что просто потому, что что-то является «наследием», не означает, что оно не функционирует и должно быть заменено. Bloomberg и IBM имеют устаревшие сервисы, написанные на Fortran и COBOL, которые приносят больший доход, чем целые компании. С другой стороны, каждая система имеет предел масштабирования. И мы собирались ударить наших.
С 2012 по 2016 год пользовательский трафик DigitalOcean вырос более чем на 10 000%. Мы добавили больше продуктов в наш каталог и услуг для нашей инфраструктуры. Это увеличило вход событий в очередь сообщений базы данных. Повышенный спрос на Droplets означал, что планировщик работал сверхурочно, чтобы назначить их всем серверам. И, к сожалению, для Планировщика, количество доступных серверов не было статичным.
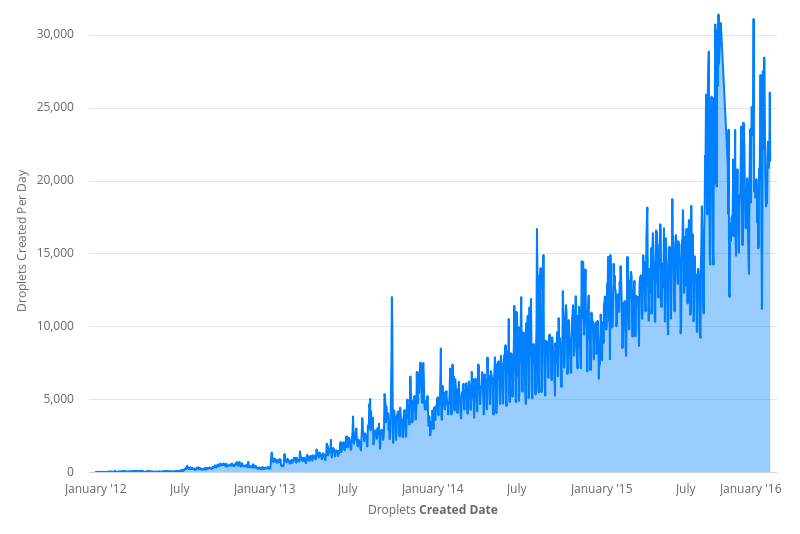
Чтобы не отставать от возросшего спроса на капли, мы добавляли все больше и больше серверов для обработки трафика. Каждый новый гипервизор означал другое постоянное соединение с базой данных. К началу 2016 года база данных имела более 15 000 прямых соединений, каждое из которых запрашивало новые события каждые одну-пять секунд. Если это было не так уж плохо, SQL-запрос, который каждый гипервизор использовал для извлечения новых событий Droplet, также усложнялся. Он стал колоссом длиной более 150 строк и присоединился к 18 столам. Это было столь же внушительно, как это было ненадежно и трудно поддержать.
Неудивительно, что именно в этот период начали появляться трещины. Единственная точка отказа с тысячами зависимостей, захваченных общими ресурсами, неизбежно приводила к периодам хаоса. Блокировки таблиц и задержки запросов привели к сбоям и снижению производительности.
И из-за тесной связи в системе не было четкого или простого решения проблем. Облако, планировщик и DOBE — узкие места. Исправление только одного или двух компонентов только сместит нагрузку на оставшиеся узкие места. Поэтому после долгих размышлений инженерный персонал разработал трехэтапный план исправления ситуации:
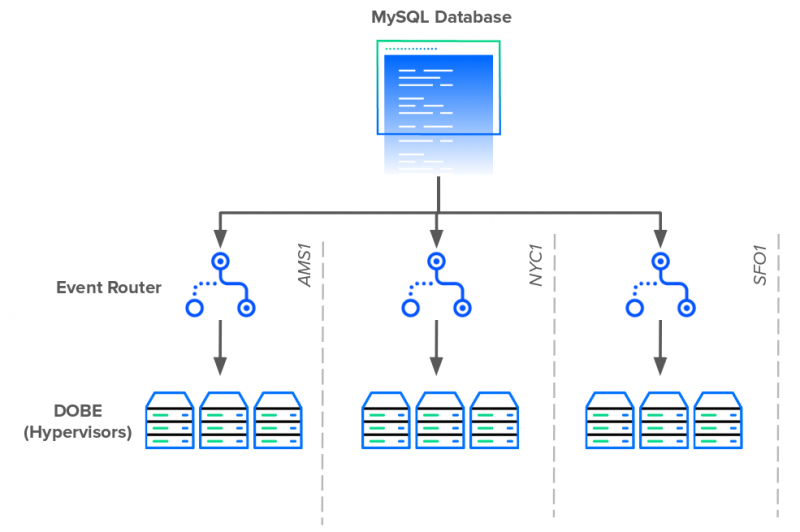
После запуска Event Router количество подключений к базе данных сократилось с 15 000 до менее 100.
Далее инженеры нацеливаются на следующую цель: планировщик. Как упоминалось ранее, Scheduler был Perl-скриптом, который определял, какой гипервизор будет содержать созданную каплю. Это было сделано с помощью ряда запросов для ранжирования и сортировки серверов. Каждый раз, когда пользователь создавал дроплет, планировщик обновлял строку таблицы, выбирая лучший компьютер.
Хотя это звучит достаточно просто, у Scheduler было несколько недостатков. Его логика была сложной и сложной для работы. Он был однопоточным, и его производительность пострадала во время пиковой нагрузки. Наконец, был только один экземпляр планировщика — и он должен был обслуживать весь флот. Это было неизбежное узкое место. Чтобы решить эти проблемы, команда разработчиков создала Scheduler V2.
Обновленный планировщик полностью обновил систему ранжирования. Вместо того, чтобы запрашивать базу данных для метрик сервера, он собирал их из гипервизоров и сохранял их в своей собственной базе данных. Кроме того, команда планировщика использовала параллелизм и репликацию, чтобы сделать свою новую службу эффективной под нагрузкой.
Event Router и Scheduler v2 были большими достижениями, которые устраняли многие архитектурные недостатки. Несмотря на это, было явное препятствие. Централизованная очередь сообщений MySQL все еще использовалась — даже суетливо — к началу 2017 года. Она обрабатывала до 400 000 новых записей в день и 20 обновлений в секунду.
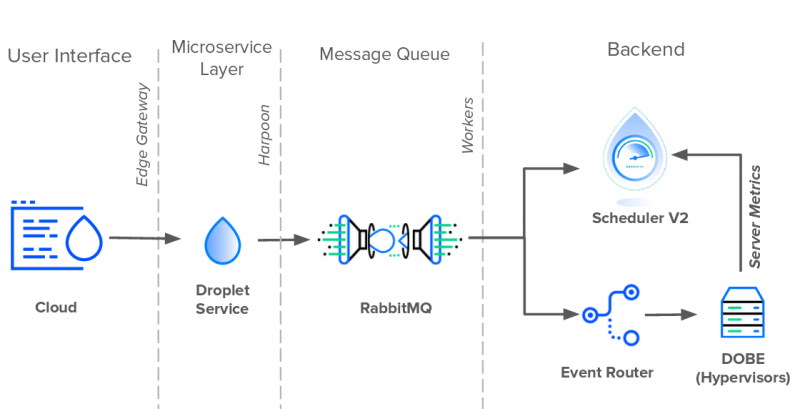
К сожалению, удаление очереди сообщений базы данных было нелегким делом. Первым шагом было предотвращение прямого доступа к сервисам. База данных нуждалась в уровне абстракции. И ему нужен API для агрегирования запросов и выполнения запросов от его имени. Если какой-либо сервис хочет создать новое событие, он должен сделать это через API. И вот, Гарпун родился.
Однако создание интерфейса для очереди событий было легкой задачей. Получить бай-ин от других команд оказалось сложнее. Интеграция с Harpoon означала, что командам придется отказаться от доступа к базе данных, переписать части своей кодовой базы и в конечном итоге изменить то, как они всегда делали что-то. Это было нелегко продать.
Команда за командой и сервис за сервисом, инженеры Harpoon смогли перенести всю кодовую базу на свою новую платформу. Это заняло лучшую часть года, но к концу 2017 года Harpoon стал единственным издателем в очереди сообщений базы данных.
Теперь настоящая работа началась. Полный контроль над системой событий означал, что у Harpoon была возможность заново изобрести рабочий процесс Droplet.
Первая задача Гарпуна состояла в том, чтобы извлечь из базы данных обязанности очереди сообщений. Для этого Harpoon создал собственную внутреннюю очередь сообщений, состоящую из RabbitMQ и асинхронных рабочих. Когда Гарпун выдвинул новые события в очередь с одной стороны, рабочие вытянули их с другой. И так как RabbitMQ заменил очередь базы данных, работники могли свободно общаться непосредственно с Планировщиком и Маршрутизатором событий. Таким образом, вместо того, чтобы Scheduler V2 и Event Router опрашивали новые изменения в базе данных, Harpoon отправлял обновления прямо в них. На момент написания статьи в 2019 году именно здесь находится архитектура событий Droplet.
За последние семь лет DigitalOcean выросла из корней гаражных групп в признанного поставщика облачных услуг, которым она является сегодня. Как и другие переходные технологические компании, DigitalOcean регулярно занимается устаревшим кодом и техническими долгами. Независимо от того, разбиваете ли вы монолиты, создаете многорегиональные сервисы или устраняете отдельные точки отказа, мы, инженеры DigitalOcean, всегда работаем над созданием элегантных и простых решений.
Я надеюсь, что эта история о том, как наша инфраструктура масштабировалась с нашей базой пользователей, была интересной и яркой. Я хотел бы услышать ваши мысли в комментариях ниже!
Я не мог удержаться от улыбки, когда услышал вопрос. Инженеры-программисты, спрашивающие о техническом долге компании, равносильны задаче о кредитном балле. Это их способ оценить сомнительное прошлое компании и то, какой багаж они несут. И DigitalOcean не привыкать к техническому багажу.
Как поставщик облачных услуг, который управляет нашими собственными серверами и оборудованием, мы столкнулись с трудностями, с которыми многие другие стартапы не сталкивались в эту новую эру облачных вычислений. Эти сложные ситуации в конечном итоге привели к компромиссам, которые мы должны были сделать в самом начале нашего существования. И, как известно любой быстро растущей компании, технические решения, которые вы принимаете на раннем этапе, как правило, догоняют вас позже.
Глядя на новый прокат через стол, я глубоко вздохнул и начал. «Позвольте мне рассказать вам о времени, когда у нас было 15 000 прямых подключений к нашей базе данных…»
История, которую я рассказал нашему новобранцу, — это история крупнейшей на сегодняшний день технической реархитектуры DigitalOcean. Это было усилие всей компании, которое длилось несколько лет и преподало нам много уроков. Надеюсь, что это поможет будущим разработчикам DigitalOcean — или любым разработчикам, попавшим в непростую головоломку с техническими проблемами.
С чего все началось
DigitalOcean был одержим простотой с самого начала. Это одна из наших основных ценностей: стремиться к простым и элегантным решениям. Это относится не только к нашей продукции, но и к нашим техническим решениям. Нигде это так заметно, как в нашей первоначальной конструкции системы.
Как и GitHub, Shopify и Airbnb, DigitalOcean была запущена как приложение Rails в 2011 году. Приложение Rails, внутренне известное как Cloud, управляло всеми взаимодействиями пользователей как в пользовательском интерфейсе, так и в открытом API. В оказании помощи Rails работали две службы Perl: планировщик и DOBE (DigitalOcean BackEnd). Планировщик планировал и назначал Droplets гипервизорам, а DOBE отвечал за создание реальных виртуальных машин Droplet. В то время как облако и планировщик работали как отдельные службы, DOBE работал на каждом сервере в парке.
Ни Cloud, ни Scheduler, ни DOBE не общались напрямую друг с другом. Они общались через базу данных MySQL. Эта база данных выполняла две функции: хранение данных и посредничество в общении. Все три службы использовали одну таблицу базы данных в качестве очереди сообщений для передачи информации.
Каждый раз, когда пользователь создавал новую каплю, Cloud вставлял новую запись события в очередь. Планировщик непрерывно опрашивает базу данных каждую секунду на предмет новых событий Droplet и планирует их создание на доступном гипервизоре. Наконец, каждый экземпляр DOBE будет ожидать создания новых запланированных капель и выполнения задачи. Чтобы эти серверы могли обнаружить какие-либо новые изменения, каждый из них должен будет опросить базу данных на предмет новых записей в таблице.
Хотя бесконечные циклы и предоставление каждому серверу прямого подключения к базе данных, возможно, были элементарными с точки зрения проектирования системы, это было просто, и это работало — особенно для технической команды с небольшим персоналом, работающей в сжатые сроки и быстро растущей пользовательской базы.
В течение четырех лет очередь сообщений базы данных составляла основу технологического стека DigitalOcean. В течение этого периода мы приняли микросервисную архитектуру, заменили HTTPS на gRPC для внутреннего трафика и вытеснили Perl в пользу Golang для внутренних сервисов. Однако все дороги все еще вели к этой базе данных MySQL.
Важно отметить, что просто потому, что что-то является «наследием», не означает, что оно не функционирует и должно быть заменено. Bloomberg и IBM имеют устаревшие сервисы, написанные на Fortran и COBOL, которые приносят больший доход, чем целые компании. С другой стороны, каждая система имеет предел масштабирования. И мы собирались ударить наших.
С 2012 по 2016 год пользовательский трафик DigitalOcean вырос более чем на 10 000%. Мы добавили больше продуктов в наш каталог и услуг для нашей инфраструктуры. Это увеличило вход событий в очередь сообщений базы данных. Повышенный спрос на Droplets означал, что планировщик работал сверхурочно, чтобы назначить их всем серверам. И, к сожалению, для Планировщика, количество доступных серверов не было статичным.
Чтобы не отставать от возросшего спроса на капли, мы добавляли все больше и больше серверов для обработки трафика. Каждый новый гипервизор означал другое постоянное соединение с базой данных. К началу 2016 года база данных имела более 15 000 прямых соединений, каждое из которых запрашивало новые события каждые одну-пять секунд. Если это было не так уж плохо, SQL-запрос, который каждый гипервизор использовал для извлечения новых событий Droplet, также усложнялся. Он стал колоссом длиной более 150 строк и присоединился к 18 столам. Это было столь же внушительно, как это было ненадежно и трудно поддержать.
Неудивительно, что именно в этот период начали появляться трещины. Единственная точка отказа с тысячами зависимостей, захваченных общими ресурсами, неизбежно приводила к периодам хаоса. Блокировки таблиц и задержки запросов привели к сбоям и снижению производительности.
И из-за тесной связи в системе не было четкого или простого решения проблем. Облако, планировщик и DOBE — узкие места. Исправление только одного или двух компонентов только сместит нагрузку на оставшиеся узкие места. Поэтому после долгих размышлений инженерный персонал разработал трехэтапный план исправления ситуации:
- Уменьшить количество прямых соединений с базой данных
- Алгоритм ранжирования Refactor Scheduler для повышения доступности
- Освободить базу данных от своих обязанностей в очереди сообщений
- Рефакторинг начинается
После запуска Event Router количество подключений к базе данных сократилось с 15 000 до менее 100.
Далее инженеры нацеливаются на следующую цель: планировщик. Как упоминалось ранее, Scheduler был Perl-скриптом, который определял, какой гипервизор будет содержать созданную каплю. Это было сделано с помощью ряда запросов для ранжирования и сортировки серверов. Каждый раз, когда пользователь создавал дроплет, планировщик обновлял строку таблицы, выбирая лучший компьютер.
Хотя это звучит достаточно просто, у Scheduler было несколько недостатков. Его логика была сложной и сложной для работы. Он был однопоточным, и его производительность пострадала во время пиковой нагрузки. Наконец, был только один экземпляр планировщика — и он должен был обслуживать весь флот. Это было неизбежное узкое место. Чтобы решить эти проблемы, команда разработчиков создала Scheduler V2.
Обновленный планировщик полностью обновил систему ранжирования. Вместо того, чтобы запрашивать базу данных для метрик сервера, он собирал их из гипервизоров и сохранял их в своей собственной базе данных. Кроме того, команда планировщика использовала параллелизм и репликацию, чтобы сделать свою новую службу эффективной под нагрузкой.
Event Router и Scheduler v2 были большими достижениями, которые устраняли многие архитектурные недостатки. Несмотря на это, было явное препятствие. Централизованная очередь сообщений MySQL все еще использовалась — даже суетливо — к началу 2017 года. Она обрабатывала до 400 000 новых записей в день и 20 обновлений в секунду.
К сожалению, удаление очереди сообщений базы данных было нелегким делом. Первым шагом было предотвращение прямого доступа к сервисам. База данных нуждалась в уровне абстракции. И ему нужен API для агрегирования запросов и выполнения запросов от его имени. Если какой-либо сервис хочет создать новое событие, он должен сделать это через API. И вот, Гарпун родился.
Однако создание интерфейса для очереди событий было легкой задачей. Получить бай-ин от других команд оказалось сложнее. Интеграция с Harpoon означала, что командам придется отказаться от доступа к базе данных, переписать части своей кодовой базы и в конечном итоге изменить то, как они всегда делали что-то. Это было нелегко продать.
Команда за командой и сервис за сервисом, инженеры Harpoon смогли перенести всю кодовую базу на свою новую платформу. Это заняло лучшую часть года, но к концу 2017 года Harpoon стал единственным издателем в очереди сообщений базы данных.
Теперь настоящая работа началась. Полный контроль над системой событий означал, что у Harpoon была возможность заново изобрести рабочий процесс Droplet.
Первая задача Гарпуна состояла в том, чтобы извлечь из базы данных обязанности очереди сообщений. Для этого Harpoon создал собственную внутреннюю очередь сообщений, состоящую из RabbitMQ и асинхронных рабочих. Когда Гарпун выдвинул новые события в очередь с одной стороны, рабочие вытянули их с другой. И так как RabbitMQ заменил очередь базы данных, работники могли свободно общаться непосредственно с Планировщиком и Маршрутизатором событий. Таким образом, вместо того, чтобы Scheduler V2 и Event Router опрашивали новые изменения в базе данных, Harpoon отправлял обновления прямо в них. На момент написания статьи в 2019 году именно здесь находится архитектура событий Droplet.
За последние семь лет DigitalOcean выросла из корней гаражных групп в признанного поставщика облачных услуг, которым она является сегодня. Как и другие переходные технологические компании, DigitalOcean регулярно занимается устаревшим кодом и техническими долгами. Независимо от того, разбиваете ли вы монолиты, создаете многорегиональные сервисы или устраняете отдельные точки отказа, мы, инженеры DigitalOcean, всегда работаем над созданием элегантных и простых решений.
Я надеюсь, что эта история о том, как наша инфраструктура масштабировалась с нашей базой пользователей, была интересной и яркой. Я хотел бы услышать ваши мысли в комментариях ниже!
0 комментариев
Вставка изображения
Оставить комментарий