Меня зовут Владимир Аксёнов, я работаю в Yandex Infrastructure и руковожу IT‑поддержкой в том самом дата‑центре Яндекса, который стал первой площадкой в собственности компании. Это определило его судьбу первопроходца: именно здесь мы тестируем множество технологий, которые затем распространяются на другие дата‑центры.
За 13 лет на этой площадке мы наблюдали радикальные изменения форм‑фактора сетевого и серверного оборудования, что повлекло за собой серьёзные метаморфозы во всём дата‑центре. Мы прошли путь от стандартной 19-дюймовой стойки до четвёртого поколения стоек собственного дизайна, а от холодных коридоров с доохлаждением — пришли к энергоэффективному фрикулингу.
В этой статье покажу, как за это время поменялось IT‑оборудование, как это повлияло на облик дата‑центров, и что интересного ждём в наших дата‑центрах в 2026 году.
2012: построили свой дата-центр!

Наша первая собственная площадка была построена в бывших помещениях станкостроительного завода. На тот момент это было оптимальное решение: есть надёжный источник питания, который даст электричество в нужном количестве, есть подвод природного газа, а в просторных помещениях можно строить машинные залы круглый год, невзирая на погодные условия.
Сначала здесь появился минимальный набор IT‑инфраструктуры для запуска: NOC‑room и два первых кластера. Туда мы устанавливали оборудование, которое зарекомендовало себя и на предыдущих площадках: серверы и дисковые полки в стойки 19".
Чтобы поддерживать нужную температуру в кластерах, было необходимо охлаждение. С инженерной точки зрения, существующая на тот момент схема кондиционирования использовала доохлаждение — для получения холода требовалась дополнительная энергия. Поэтому был запущен Центр холодоснабжения с абсорбционными холодильными машинами:

Нагретый серверами воздух удалялся из каждой стойки по индивидуальным вентканалам. Стойка была скорее частью инженерной системы.
Наши масштабы росли всё быстрее, и нам было нужно всё больше таких стоек с серверами. Деплой каждой требовал времени:
- Каждый сервер вынуть из коробки.
- Снять упаковочные материалы.
- В стойку установить 360+ сухарей/собачек.

- Накрутить 94 салазки.
- Установить 47 серверов.
- Распаковать и скоммутировать сеть управления, сеть передачи данных, подключить кабели питания.
На каждую стойку уходило примерно 1,5–2 человекодня… Мы стали думать, как сократить это время.
2013: первые стоечные решения
В следующем году запустился новый модуль с разделением на горячий и холодный коридор, где можно было ставить не только стандартные стойки 19", но и стоечные решения по стандарту The Open Rack.
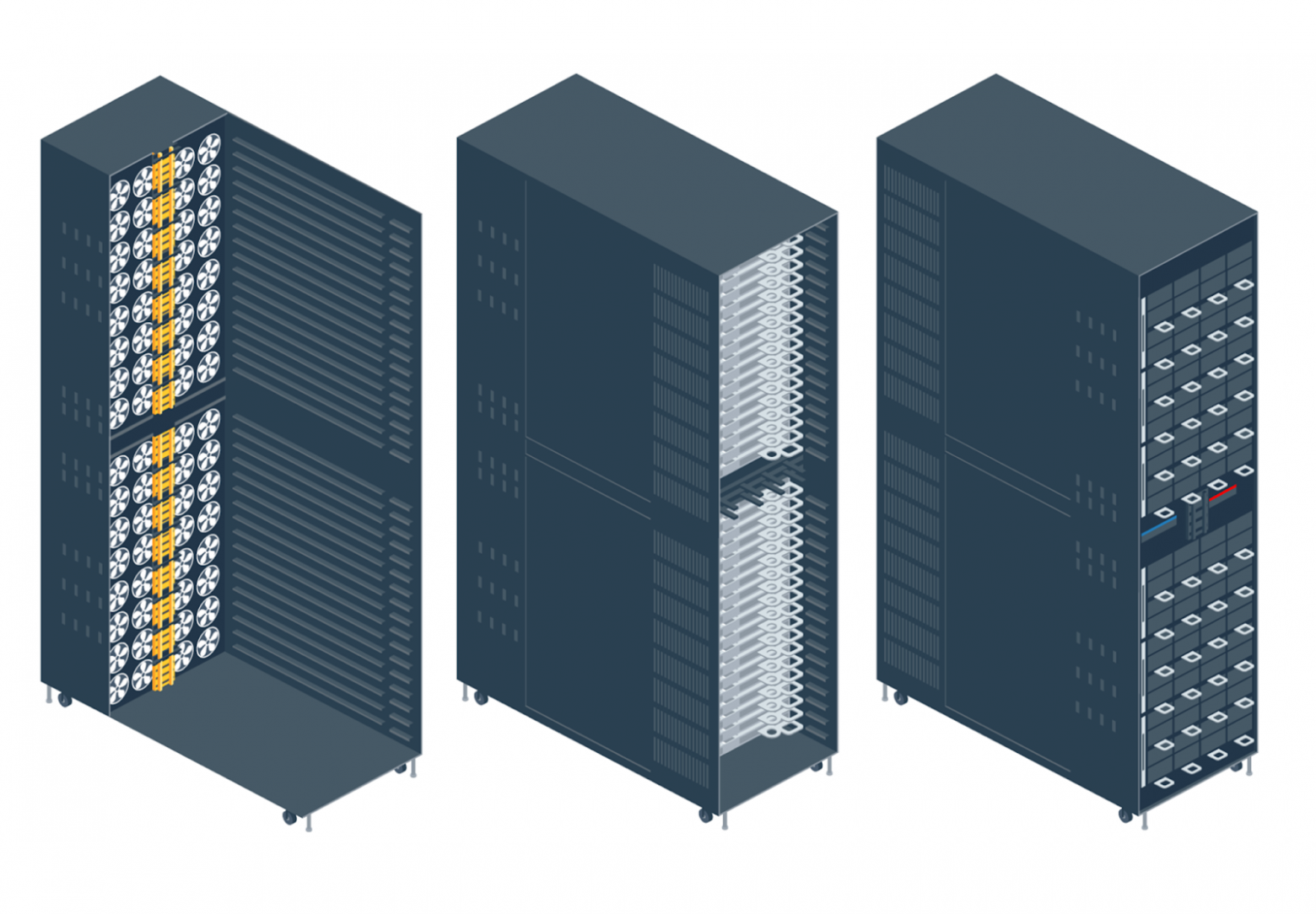
Это стойка, в которой серверы не имеют собственного активного охлаждения и блоков питания, а подключены к централизованной системе: всё подключение к питанию предусмотрено в задней части с помощью специальной шины питания — тогда она была на 12 В. Охлаждение тоже интегрированное.

Самое главное — такие решения можно доставить в дата‑центр уже в собранном виде. Некоторые модели приезжали даже с коммутацией, и это был настоящий прорыв. Первые подобные стойки мы заказали у сторонних производителей, а затем наладили своё производство с опорой на стандарты Open Compute Project Foundation (OCP) и стали устанавливать стоечные решения, разработанные Яндексом.
2017: переход на фрикулинг
Следующие годы были посвящены повышению эффективности работы всей системы. Инженеры дата‑центра тестировали фрикулинг — систему, где всё оборудование охлаждается исключительно уличным воздухом. В плане инженерной инфраструктуры это также было прорывное решение, которое обещало серьёзную экономию ресурсов, так что мы использовали его при проектировании и строительстве новых модулей в нашем дата‑центре.

Суть фрикулинга в том, что в холодный коридор поступает воздух БЕЗ доохлаждения: летом — это уличный воздух, а зимой используется уличный воздух с подмесом нагретого воздуха из горячего коридора, чтобы довести минусовую температуру до комфортных 20 градусов. Такое решение позволило отказаться от использования громоздких, сложных в эксплуатации холодильных машин.
На Хабре уже было несколько статей о разных системах охлаждения дата‑центров, поэтому лишь вкратце напомню, как именно в случае фрикулинга поддерживается нужная температура:
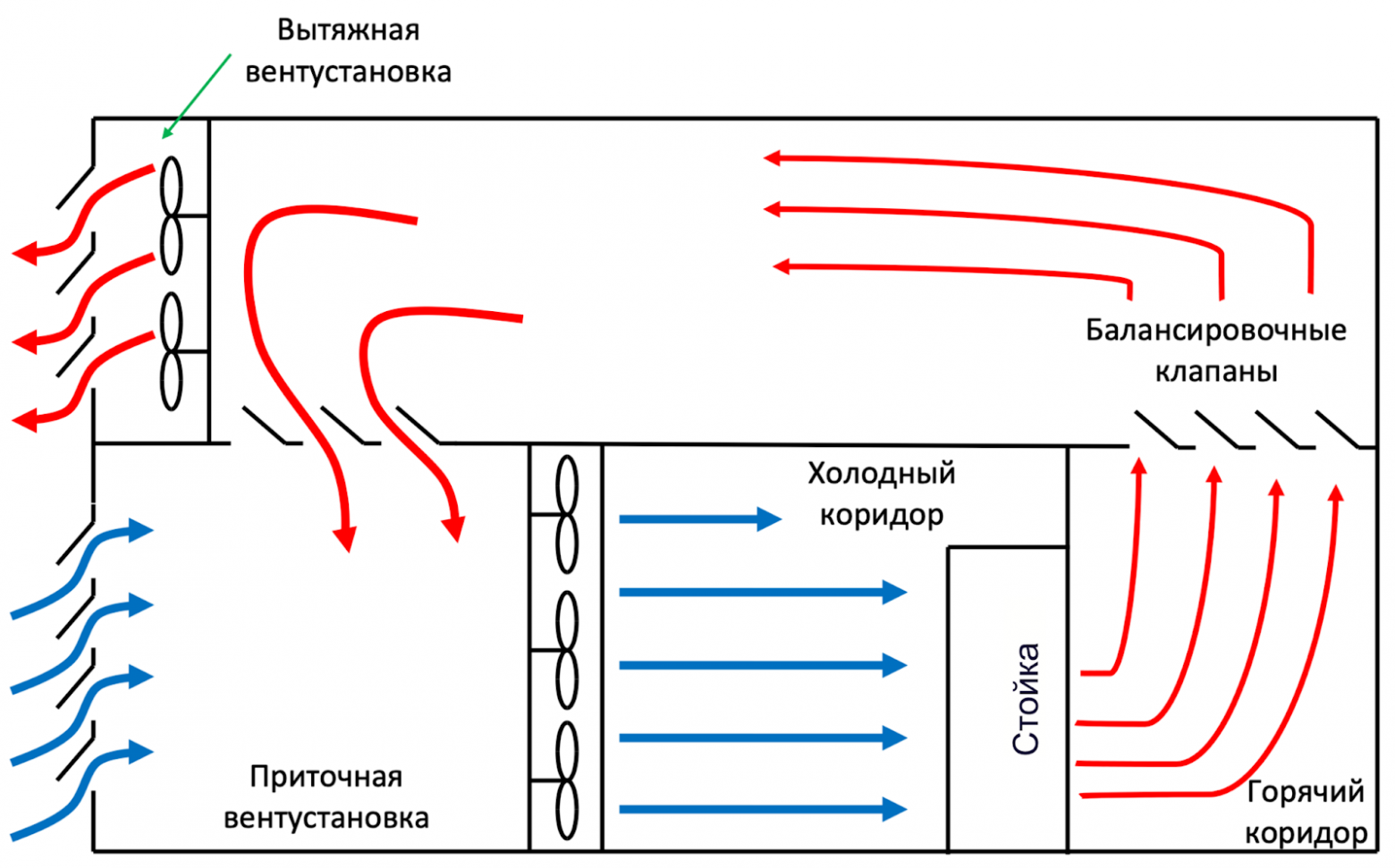
- В приточной установке установлены фильтры грубой и тонкой очистки.
- В холодном коридоре поддерживается положительное давление, в горячем — отрицательное.
- Сам расход холодного воздуха определяется потребностью стоек.
С точки зрения IT‑поддержки важно, что отказ от доохлаждения помогает улучшить PUE (Power Usage Effectiveness) — коэффициент, отражающий эффективность использования энергии в дата‑центре. При использовании доохлаждения PUE находился в районе 1,5, а без него — держится на отметке 1,1, а иногда и меньше. Это значит, что только 10% от всего потребления дата‑центра уходит не на IT‑нужды.
К тому моменту мы уже разработали стоечные решения, которые умели работать при температурах до +40 градусов. Поскольку все наши дата‑центры находятся в средней полосе России, такая температура — скорее аномалия. Но периодически кратковременные периоды жары всё же случаются, и было важно убедиться, что система справится.
Поэтому даже стойки OCP первого и второго поколения подвергались самым разным испытаниям в нашей термолаборатории, и показали хорошую работоспособность при высоких температурах. А следующие поколения стоек нашей разработки изначально проектировались для нормальной работы в таких условиях. Это делало систему ещё эффективнее, так как доохлаждать было не нужно.
2017: новый дата-центр с новыми подходами

В том же году запустился новый дата‑центр во Владимире, который изначально был спроектирован под фрикулинг и построен с нулевого цикла — такие строительные работы включали целый комплекс подготовительных мер, например, создание фундамента, прокладку необходимых коммуникаций и так далее. Если в старом дата‑центре для строительства кластера на фрикулинге в бывшем заводском помещении понадобилось убирать старые полы и заливать новые, чтобы разместить инженерное оборудование по высоте, то здесь эти моменты учли ещё на старте строительства. Заодно избавились от проблемы строительной пыли, которая неизбежно появлялась при модернизации старого здания.
Новый дата‑центр спроектировали как четыре отдельных помещения с сетевой связностью между ними. Строили его по мере роста масштабов: как только начинало заполняться первое здание — вводилось в эксплуатацию следующее. Так мы могли избежать простаивающих помещений. Строительной пыли тоже стало меньше.
Но со временем стало понятно, что нам не очень удобно перемещаться по улице между отдельными зданиями, а тем более транспортировать стойки из здания в здание.
2022: проектирование «жука»
Учитывая весь накопленный опыт эксплуатации, новую площадку мы задумали как возможность объединить всё лучшее из существующих дата‑центров, а также избежать тех неудобств, которые возникли со временем. Так появился новый проект дата‑центров:
- с фрикулингом;
- с безразрывной крышей, как в первом дата-центре;
- с помещениями машинных залов, которые отделены друг от друга дверями.
Сверху на плане выглядело так: в центре складские помещения и офис, а в стороны расходятся четыре помещения для строительства кластеров. Было похоже на насекомое, поэтому мы прозвали этот проект «жук».
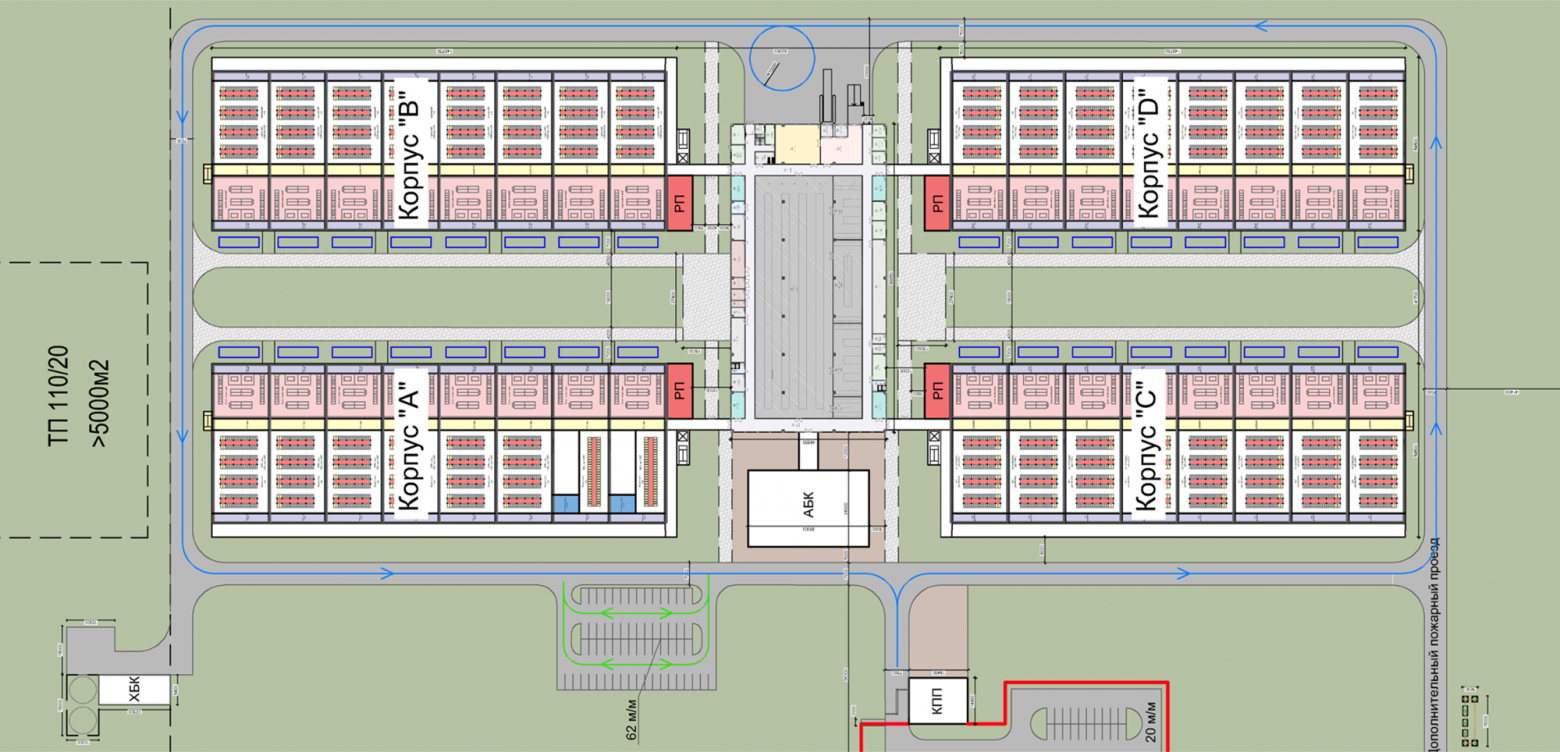
В таком едином помещении нет пыли, корпуса по‑прежнему можно вводить в эксплуатацию по мере заполнения, но поскольку они расположены близко, то перемещение в любую погоду комфортное, а переезд IT‑оборудования между модулями проходит беспрепятственно.
В недавно прошедший день работников дата‑центров мы даже заказали торт, вдохновлённый этим проектом:
 2025: жизнь первых дата-центров
2025: жизнь первых дата-центров
Ввод новых площадок в эксплуатацию не означает, что мы забываем про прежние дата‑центры.
К настоящему моменту в серверных стойках мы перешли уже к четвёртому поколению серверов, и для них требуется совсем другая инфраструктура, чем было 10–12 лет назад:
Сервер 4.0 предусматривает:
- более эффективное охлаждение на 10–15%;
- питание 48 В на сервер (ноду);
- вместо четырёх NVMe‑дисков теперь шесть, и есть возможность установки двух дисков M2;
- возможность установки GPU.
Само стоечное решение выглядит уже так:

С 2023 года мы ведём работы по модернизации старой части нашей первой площадки.
Это позволяет полностью отказаться от доохлаждения и демонтировать оставшееся холодильное оборудование, которое не позволяло установить в старые модули современные устройства.
2026: что будет дальше?

Дата‑центры будущего уже рядом с нами, и вот как они выглядят для нас сейчас:
- современное помещение, которое сочетает удобство и надёжность;
- возможность запускать площадку даже с одним модулем и достраивать остальные по мере необходимости;
- экономичное расходование энергии с PUE не более 1,1;
- стойки приезжают в дата‑центр в сборе и отправляются в тестирование через 30–40 минут с момента разгрузки фуры.
Уже можно представить, как это будет развиваться дальше:
- Виден рост потребностей в мощностях для ML‑задач, которые потребляют много электроэнергии. Поэтому площадки будут заполняться очень быстро.
- Если первые кластеры потребляли киловатты, а существующие якорные дата‑центры — 40–60 МВт, то площадки ближайшего будущего проектируется уже с мощностью 120 и более МВт.
- Масштабироваться мы и дальше будем площадками, и это будет несколько обособленных сооружений в непосредственной близости, например, как наш «жук».
- Постоянно увеличивающийся TDP чипов обязывает постепенно переходить к системам жидкостного охлаждения, как в инженерных системах дата‑центров, так и внутри серверов.

Иногда я спрашиваю коллег, работающих в дата‑центре, как они видят будущее нашей площадки. Многие отвечают, что чинить серверы будут роботы (а сотрудники IT‑поддержки, по‑видимому, будут чинить роботов). Но с точки зрения эксплуатации это не так уж далеко от истины. В идеале хочется, чтобы это выглядело так:
- прихожу в дата‑центр, иду в офис;
- умная колонка меня приветствует и рассказывает про запланированные на день задачи в формате саммари, докладывает об уровне SLA и каких‑либо изменениях;
- по цеху ходят сотрудники службы контроля качества в очках дополненной реальности, на которых видны необходимые операции с оборудованием;
- роботы‑доставщики вокруг развозят компоненты на склад и со склада до места проведения работ;
- в офисе сидят IT‑специалисты, которые выполняют сложную диагностику, давая задачи AI‑ассистентам.
Пока часть из этого ещё не сбылось, но многие из технологий мы уже тестируем. Так что поживём‑увидим!
yandex.cloud/ru