29 мая 2026 Крупный апдейт в App Platform
29 мая 2026 Крупный апдейт в App Platform
Теперь развернуть приложение можно не только из своего репозитория, но и сразу из Docker Hub.
Выбираете образ → App Platform сам настраивает обратный прокси и выдает бесплатный технический домен. Через пару минут — рабочее приложение с HTTPS и логами.
Удобно, когда нужен готовый сервис здесь и сейчас — в Docker Hub есть множество образов под любые задачи: веб-серверы, CMS, базы, мониторинг и не только.
Подробнее о деплое приложений → в доке.
timeweb.cloud/docs/apps/deploying-with-docker-hub
Планируем добавить деплой из приватных и кастомных реестров контейнеров, а также упростить работу с доменами.
28 мая 2026 Ускорили сборку и доставку образов для облачных серверов
Раз в минуту у нас разворачивается минимум два новых сервера — это 3000+ установок в день. Каждый из них должен запускаться быстро, быть готовым к работе из коробки и иметь актуальные обновления безопасности.
Чтобы держать эту планку, мы пересобрали qcow_builder — наш внутренний конвейер сборки и тестирования образов.
Вот как мы это сделали:
1. Перешли на cloud-образы вместо установки с ISO
Для большинства Linux-дистрибутивов берем готовые .qcow2 с зеркал вендоров и дорабатываем до своих стандартов. Сборка одного образа теперь занимает 5–15 минут вместо полутора часов. Образы унифицированы с другими облаками: плейбуки, раннеры и привычная автоматизация переносятся к нам без существенных доработок.
2. Ввели модульный конвейер вместо гигантского скрипта
Теперь сборка устроена из двух частей. Конвейер приводит все диски к единым стандартам, чтобы любая ОС работала у нас одинаково предсказуемо. А роутер отвечает за точечную настройку под конкретное семейство ОС — туда подключаются модули с плейбуками. Так мы быстрее раскатываем новые ОС по вашим запросам.
3. Добавили единую настройку через Ansible
После сборки диска временный сервер прогоняется через плейбуки. В каждый образ закладываем необходимые для мониторинга юниты и корректные сетевые конфигурации — чтобы потом вам не пришлось доставлять их вручную.
4. Расширили автотесты до публикации в продакшн
Каждый образ проверяется на реальной виртуальной машине — такой же, как и у вас. Прогоняем сеть, SSH, cloud-init, QEMU Guest Agent, Zabbix-агент и базовые сценарии запуска. Если что-то пошло не так — образ возвращается на доработку и дальше не идет.
В итоге вы получаете сервер, готовый к работе сразу после выбора образа в панели. Под капотом — 58 наших образов на весь стек, от Linux для облачных серверов до сборок под Kubernetes и managed-сервисы.
Платформа нативно работает с cloud-образами и cloud-init — проще переносить существующие проекты, автоматизацию и CI/CD-процессы без лишней адаптации.
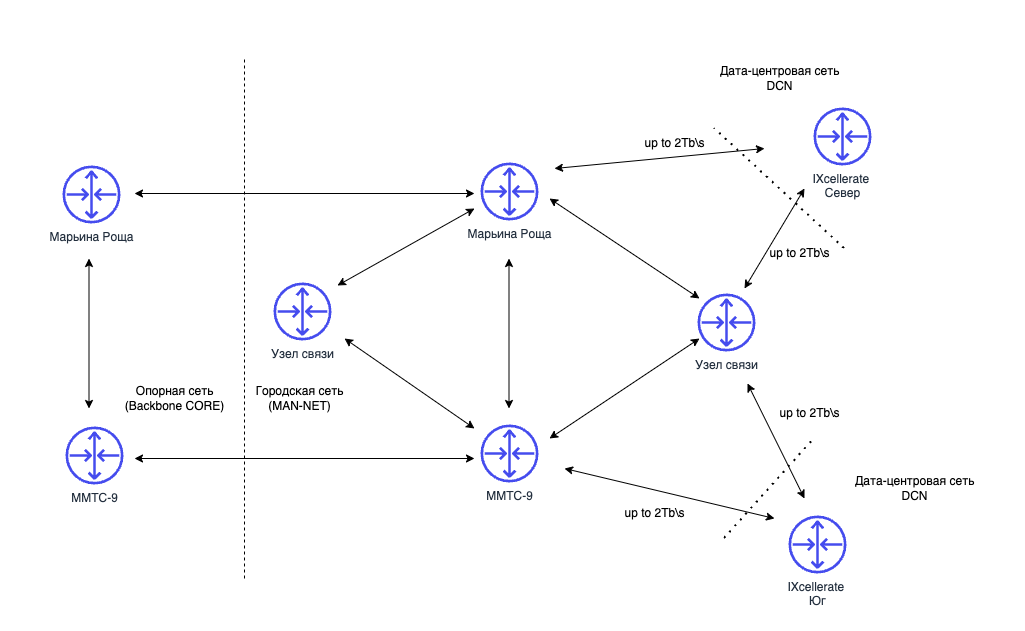
22 мая 2026 Запускаем городскую сеть в Москве — и расширяем пиринг с одной точки до четырех
В прошлых постах рассказывали про опорную сеть — поставили Juniper PTX 10003-80C в Петербурге и перешли на 400 Гбит/с по магистрали.
Следующим этапом запускаем городские сети там, где у нас несколько площадок, и делим всю сеть на три уровня — опорный, городской и внутри каждого дата-центра.
Суть проекта: в городах с несколькими точками присутствия или дата-центрами мы развернем городские MAN-сети. Они объединят площадки в единое кольцо и помогут эффективнее передавать трафик внутри города.
Преимущества таких сетей:
1. Больше точек присутствия для пиринга
Расширим количество узлов связи для стыковки с операторами и партнерами: с 1 узла в ММТС-9 до 4 узлов на разных площадках. Маршруты до клиентских проектов и операторов-партнеров станут короче, а сеть устойчивее. Если одна точка будет недоступна, трафик автоматически перераспределится через остальные.
2. Двойное подключение каждого ЦОД к городской сети
Каждый дата-центр планируем подключить минимум к двум городским узлам на скорости до 4 Тбит/с. Связность сохранится даже при аварии на одном из узлов городской сети.
3. Меньше задержек между площадками
Сможем гибче развивать новые площадки и добавлять емкость до дата-центров. А еще проводить работы на узлах связи без снижения производительности.
Первый город на очереди — Москва. Соберем кольцо на сетевых интерфейсах 100 и 400 Гбит/с — хватит, чтобы спокойно прокачивать трафик и оставить большой запас.
21 мая 2026 Веб-поиск и генерация изображений
Развивается не только наша инфраструктура, но и сервисы. Сегодня — про AI-агентов.
За последние три месяца количество активных агентов выросло в 4 раза, а пользователи тратят больше миллиарда токенов в день.
Теперь можно закрывать больше сценариев в одном диалоге: поиск актуальных данных и создание визуалов под запрос.
— Веб-поиск
Агент ищет информацию в интернете перед ответом, а вы получаете актуальные цены, тарифы, новости, данные с сайтов. Под капотом — интеграция с Яндексом.
Функция включается в настройках агента. Стоимость — 0,49 руб. за запрос.
— Генерация изображений
Агент генерирует иллюстрации, иконки, баннеры прямо в диалоге, без лишних переключений. В будущем добавим и генерацию аудио.
Доступные модели: Gemini 3.1 Flash Image Preview и Gemini 3 Pro Image Preview, они же Nano Banana. Список будет пополняться.
Оплата — по токенам выбранной модели. Включить можно где удобно: при создании агента, в настройках уже готового или прямо в чате.
Бонусом поменяли способ тарификации для новых агентов на поресурсный. Так можно дешевле тестировать новые фичи, платить только за фактическое использование и настраивать агента под свои задачи.
19 мая 2026 Переехали в новый ЦОД в Нидерландах и забрали сеть под свой контроль
С апреля мы вели масштабный проект по переносу европейской локации на новую площадку. Старый дата-центр euNetworks закрывается в июле, поэтому задачу требовалось решить в сжатые сроки и полностью бесшовно для клиентов.
За 2 месяца плотной работы мы провели онлайн-миграцию около 35 000 виртуальных серверов в новый дата-центр Qupra DC2. Процесс шел поэтапно: сначала перераспределяли нагрузку внутри инфраструктуры, а затем запускали миграцию виртуалок. Благодаря этому все клиентские проекты продолжали работать в штатном режиме без даунтайма.
В новом ЦОДе мы заняли 15 стоек, где на текущий момент суммарно работает уже около 60 000 виртуальных серверов и есть большой запас для масштабирования.
Миграция стала поводом для полноценного апгрейда всей локации:
1. Усилили сетевую инфраструктуру
Мы внедрили DWDM-систему для спектрального уплотнения каналов, что увеличило пропускную способность сети. Для объединения трафика с серверных стоек и его ускорения внутри площадки установили модульный коммутатор агрегации Arista 7508.
2. Перевели стойки и сети под свой контроль
Теперь серверы размещаются в наших собственных стойках, а сетевое оборудование внутри ЦОДа находится под полным контролем нашей команды. Это позволяет быстрее мониторить состояние площадки и оперативно реагировать на инциденты.
3. Обновили системное ПО
Параллельно с переносом данных мы актуализировали ПО на хостах. Часть старых нод перевели на свежие версии операционных систем и обновили ядро Linux, чтобы минимизировать риски сбоев на уровне хост-машин.
Итого снизили риски инфраструктурных сбоев в локации до минимума, ускорили связность внутри ЦОДа и заложили большой запас по мощности.
18 мая 2026 Седьмая локация для облачных серверов
Теперь вы можете развернуть сервер в Нью-Йорке. Хороший вариант, если важна низкая задержка для пользователей в Северной Америке или вы хотите распределить инфраструктуру между США и Европой.
Физически дата-центр находится в Буффало, штат Нью-Йорк. Мы подключили локацию к опорно-магистральной сети, чтобы обеспечить стабильное управление и качественное соединение с инфраструктурой в других локациях.
Есть фиксированные и произвольные конфиги. Минималка 1 CPU, 1 ГБ RAM и 15 ГБ диска.
14 мая 2026 Укрепляем защиту ваших проектов
За последнее время в публичном поле появилось несколько заметных уязвимостей: Copy Fail, Dirty Frag, Fragnesia, а также уязвимости в Exim и nginx.
В некоторых конфигурациях они могли нарушить работу сервисов, обойти защиту или повысить риски доступа к данным.
Что мы сделали со своей стороны
Проверили, касаются ли эти угрозы нашей инфраструктуры. Установили обновления и добавили меры доп защиты.
Тем самым снизили риск повышения привилегий и ограничили возможные варианты несанкционированного доступа.
В нашей зоне ответственности все необходимые меры защиты уже применены.
Как можно усилить безопасность у себя
В первую очередь советуем проверить актуальные версии ОС и системных пакетов. Copy Fail, Dirty Frag и Fragnesia связаны с Linux-ядром и повышением привилегий.
Если внутри сервера вы ставили Exim или nginx, то также проверьте их на обновления:
Exim: 4.99.2 или актуальная версия из репозитория вашего дистрибутива
nginx: версия 1.30.1 stable или 1.31.0 mainline
Еще немного базовых рекомендаций:
— Пересмотрите доступы: права пользователей, SSH-ключи и sudo
— Убедитесь, что пароли, токены и ключи не хранятся в открытом виде
Подробнее о мерах безопасности → в
туториале
13 мая 2026 Juniper PTX 10003-80C в Петербурге
В петербургский ЦОД поставили
Juniper PTX 10003-80C, маршрутизатор операторского класса с нативной поддержкой 400G.
— Расширяем магистральный канал до Амстердама. PTX добавляет емкость на одном из транзитных маршрутов в европейском направлении.
— Разгружаем MX480. Часть трафика, которая шла через текущее ядро петербургской сети, переходит на PTX. MX480 получает запас по производительности.
— Фундамент под Nх400G-кольцо по Петербургу. PTX нативно поддерживает 400G, а наша конфигурация MX480 нет. Переход кольца на 400G сейчас в работе.
12 мая 2026 Про Telegram API, СХД, сети и многое другое
За последние 3 месяца мы экстерном прошли курс выживания в экстремальном ИТ. Событий было столько, что хватило бы на сериал.
Просто доросли до нагрузок, где вылезают проблемы совсем другого уровня — те самые, с которыми воюют гиперскейлеры. На этом этапе любые неочевидные зависимости или ограничения масштабирования бьют в разы больнее.
Решили разобрать эти кейсы открыто. Это хроника того, как мы адаптируем инфраструктуру под новые нагрузки.
— Инцидент в ЦОД (Германия). В феврале из-за возгорания на площадке во Франкфурте полностью отключили питание, доступ к стойкам был закрыт на 2 часа. Часть компонентов вышла из строя.
Обновили протоколы «холодного старта» и резервирования для зарубежных сегментов. Дополнительно пересмотрели подходы для более быстрого взаимодействия с поставщиками и партнерами.
— Сетевые атаки в марте. Мы столкнулись с DDoS-атаками новых масштабов и паттернов (пики 1, 2, 14 и 16 числа).
Обновили профили фильтрации, правила классификации и пороги реакции на аномалии. Это позволяет эффективнее отсекать всплески, не задевая легитимный трафик.
— Сбой на уровне гипервизоров. 24 марта из-за флапа сети в московских стойках «зависли» RDMA-сессии на стороне СХД. Это привело к потере связности на 15 нодах, часть ВМ пришлось эвакуировать.
Изменили параметры взаимодействия сетевого стека и гипервизоров, чтобы локальные колебания сети не приводили к каскадному влиянию на виртуальные машины.
— Сбой на уровне СХД. 9–10 апреля кластер СХД столкнулся со сбоем. Причина — софтовый баг, не заявленный ранее вендором, проявился под нашей продакшен-нагрузкой.
Обновили ПО, пересмотрели процедуры обслуживания и ввели дополнительные лимиты на контроллерах для защиты системы в пиковых сценариях.
— Доступность Telegram API. Масштабные сбои в работе ботов по всей РФ затронули и наши сервисы.
Отладили систему мониторинга внешних сервисов, чтобы информировать пользователей о глобальных сбоях, на которые не можем влиять напрямую.
— Ошибка в БД. 4 мая во время плановых работ возник технический сбой, который привел к некорректным балансам и блокировкам.
Ошибку устранили, доступ восстановили. Внесли изменения в регламенты техработ и добавили дополнительные уровни проверки данных (валидацию), чтобы минимизировать риски, связанные с человеческим фактором.
Понимаем, что чем больше становится проект, тем важнее быть открытыми с теми, кто им пользуется. Поэтому решили немного изменить формат новостей.
Теперь наравне с продуктовыми обновлениями будем регулярно рассказывать про архитектуру сетей и работу с железом. Для нас это новый вызов, а для вас — возможность увидеть, с чем сталкивается большая инфраструктура изнутри.
5 мая 2026 Все дороги ведут к CDN
Замечали, что сайт в разных локациях грузится по-разному?
Так происходит потому, что контент идет с одного источника. Чем дальше пользователь, тем дольше загрузка. Особенно это заметно на сайтах с изображениями и видео, а также при раздаче файлов.
И тут в игру вступает CDN. Выкатили решение, которое ускорит загрузку: пользователь открывает сайт → контент прилетает с ближайшего узла → все загружается быстрее.
Если файл уже есть в кэше — он отдается мгновенно. Если нет, то CDN загружает его с источника, сохраняет и ускоряет последующие запросы. Подробнее → в доке.
С CDN посетители сайтов и приложений получают:
1. Быструю загрузку страниц и медиа
2. Стабильную работу сервиса
3. Меньше ошибок при загрузке контента
Как подключить: Перейти в раздел CDN → «Создать ресурс» → указать источник (сервер или S3) → сохранить настройки
timeweb.cloud/my/cdn
4 мая 2026 Ваш кластер больше не черный ящик
Не нужно разбираться в каждой ноде и гадать, что случилось с кластером. Все видно прямо в панели управления — с новыми логами системных компонентов в Kubernetes:
— Healing
— Автоскейлинг
— CCM
— kube-apiserver
Что можно узнать по логам:
Не создается LoadBalancer → открыть логи CCM и сразу увидеть причину
Кластер странно скейлится → посмотреть, какие поды триггернули добавление ноды и почему она потом удалилась
Нода внезапно исчезла → проверить, почему ее пересоздал хиллер и почему это произошло
Искать логи не нужно — они уже в отдельной вкладке кластера.