База данных Scaleway Elements теперь общедоступна! Команда разработчиков баз данных с гордостью представляет свой сервис управляемых баз данных. В этой статье мы пойдем за кулисы, чтобы узнать, как работает наша служба баз данных.
www.scaleway.com/en/database/
Жизненный цикл базы данных
Что происходит, когда вы нажимаете кнопку «Создать экземпляр»?
Ну так много всего! В этом разделе мы узнаем о полном жизненном цикле экземпляра базы данных Scaleway.
Создание экземпляра
Мы используем много субресурсов для создания вашего экземпляра базы данных. Все эти подресурсы полностью абстрагированы для вас. Они не будут отображаться в вашей консоли, вы увидите только экземпляр вашей базы данных.
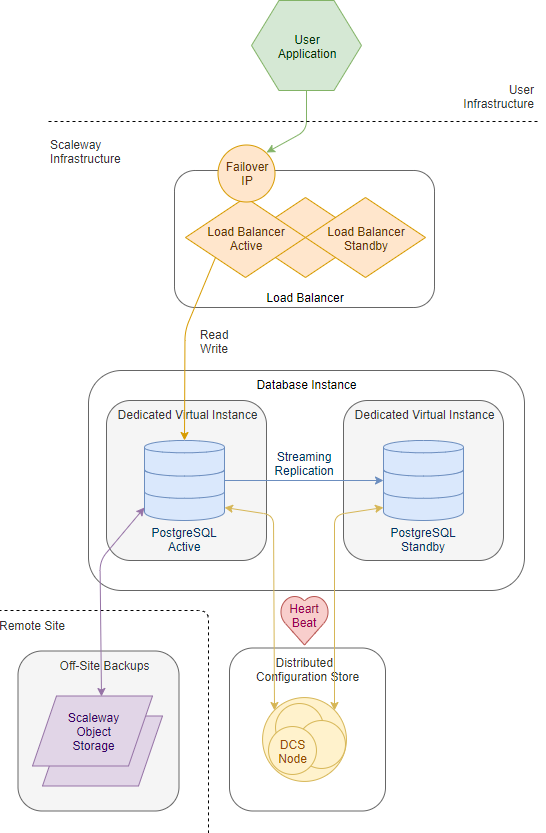
Все базы данных используют экземпляры, созданные из базового образа настраиваемого экземпляра. Этот образ построен внутри, и наша команда может развернуть любую версию PostgreSQL, которую мы поддерживаем. Мы называем их золотыми изображениями, потому что они являются единственной ссылкой на наш продукт. Механизм базы данных работает в среде Debian с использованием официального дистрибутива PostgreSQL вместе со многими другими внутренними утилитами.
Мы также используем балансировщик нагрузки перед экземпляром базы данных. Этот балансировщик нагрузки будет всегда перенаправлять ваш звонок на активный узел и автоматически переключаться на узел горячего резервирования в случае сбоя. Это гарантирует, что вы всегда сможете получить доступ к вашей базе данных с тем же IP-адресом.
www.scaleway.com/en/load-balancer/
Со стороны экземпляра мы предоставляем экземпляр с нашим золотым изображением.
Для PostgreSQL с включенной опцией высокой доступности мы используем механизм антиаффинности, чтобы убедиться, что экземпляры работают на разных гипервизорах. В случае одного сбоя гипервизора экземпляр вашей базы данных все еще работает.
В отношении хранилища мы используем локальный том экземпляра для высокопроизводительного доступа к диску для вашего экземпляра базы данных.
Конфигурация экземпляра
Теперь, когда наш экземпляр подготовлен, нам нужно настроить его для вас.
Это включает в себя создание пользователя с паролями и специальными параметрами, которые вы можете настроить на вкладке «Дополнительные параметры» в консоли.
Чтобы ограничить доступ к вашему экземпляру базы данных, вы можете ограничить доступ с помощью функции «Разрешенные IP-адреса». Когда этот параметр включен, на вашем балансировщике нагрузки настраивается ограничение IP-адресов белого списка.
en.wikipedia.org/wiki/Whitelisting
Готовность
Когда экземпляр создан и настроен, он готов обслуживать запросы SQL! Вам выставляется счет только тогда, когда база данных готова к использованию.
Возможность наблюдения
Теперь, когда ваш экземпляр базы данных работает, наша миссия — обеспечить его правильную работу. Мониторинг и ведение журнала помогают нам увидеть экземпляр, на котором работает ваша база данных.
Мониторинг
Ваши экземпляры базы данных постоянно контролируются, чтобы убедиться, что они работают правильно. Наш стек мониторинга основан на Prometheus, который собирается исследовать экспортеры метрик (включая экспортер узлов), которые живут в вашем экземпляре. Эта настройка позволяет нам иметь метрики об экземпляре, в котором в данный момент работает ваша база данных.
Например, система отвечает за проверку того, что в вашем экземпляре базы данных достаточно свободного места. Если это не так, он переключит режим транзакций по умолчанию в режим «только чтение», чтобы вы заметили проблему, поддерживая службу в ухудшенном режиме. Эта операция выполняется, чтобы дать вам достаточно времени для очистки логических баз данных или обновления экземпляра базы данных до другого плана.
prometheus.io/
prometheus.io/docs/guides/node-exporter/
Логирование
Во время работы PostgreSQL генерирует логи. Эти журналы здесь, чтобы помочь понять, что в данный момент происходит внутри вашей базы данных.
Вы можете получить эти журналы с консоли.
Выберите интервал времени, из которого вы хотите извлечь журналы, и они будут готовы для вас. Когда ваш экземпляр базы данных высокодоступен, мы получаем журналы со всех активных узлов. Когда вы спросите их в консоли, вы получите файл журнала для каждого узла.
Резервное копирование и восстановление
Резервное копирование и восстановление является неотъемлемой частью построения надежной системы.
При создании экземпляра базы данных по умолчанию резервное копирование экземпляра автоматически выполняется с использованием расписания управляемого резервного копирования. Вы также можете выполнять резервное копирование и восстановление по требованию с помощью консоли.
Резервный
Когда вы включаете автоматическое резервное копирование для своего экземпляра базы данных, мы планируем процесс резервного копирования, который будет запускаться с фиксированной частотой.
Задача резервного копирования создаст дамп вашей базы данных в виде сжатого файла дампа.
Этот файл затем сохраняется внутри другого региона с использованием хранилища объектов Scaleway Elements.
Мы используем другой географический регион для обеспечения устойчивости данных в случае аварии в одной из наших зон доступности.
Эта задача также может быть запущена вручную, когда вы считаете нужным. Вы можете запустить резервное копирование вручную на вкладке Резервное копирование вашего интерфейса администрирования.
Восстановить
Операция восстановления извлечет резервную копию из хранилища объектов и восстановит этот дамп в качестве базы данных.
По умолчанию целевая база данных является исходной базой данных резервной копии.
В качестве целевой резервной копии вы можете указать другое имя базы данных, чтобы восстановить резервную копию в другой базе данных, чем ее источник.
www.scaleway.com/en/object-storage/
Восстановление резервной копии не ограничивается одним экземпляром, вы можете выполнить восстановление для всех экземпляров базы данных. Тем не менее, можно указать имя целевой базы данных, где будет восстановлена резервная копия.
console.scaleway.com/rdb/backups
Высокая доступность
База данных Scaleway поддерживает настройку высокой доступности. Это позволяет вашей базе данных оставаться доступной даже в случае сбоя узла. Мы настоятельно рекомендуем активировать резервные копии и высокую доступность для производственного использования.
en.wikipedia.org/wiki/High_availability
Собственная репликация PostgreSQL
PostgreSQL изначально поддерживает множество типов репликации.
Для репликации мы используем стратегию доставки журналов с записью.
Это означает, что когда запрос на запись отправляется в активную базу данных, транзакция подтверждается только тогда, когда активный и резервный экземпляры подтверждают, что запись на запись зафиксирована с обеих сторон.
Этим мы гарантируем, что в случае потери одного из узлов экземпляра система продолжит работу и будет работать согласованно.
PostgreSQL поддерживает встроенные методы репликации.
Однако автоматический переход на другой ресурс по умолчанию не поддерживается.
У нас должен быть механизм для перенаправления вызовов на нужный узел. Вот почему нам нужна другая система для арбитража, куда перенаправлять запросы в зависимости от состояния узла (активный / резервный).
www.postgresql.org/docs/current/different-replication-solutions.html
Отработка отказа в случае высокой доступности
Когда вы запрашиваете параметр высокой доступности для экземпляра вашей базы данных, мы включаем отказоустойчивую систему, которая состоит из нескольких элементов:
Распределенное консенсусное хранилище (DCS) DCS гарантирует, что только одна база данных будет одновременно иметь основную блокировку.
Это также гарантирует, что все логические базы данных получили одинаковые согласованные данные.
Это где замок будет жить.
Блокировка — это концепция параллелизма. Это гарантирует, что одновременно может быть активен только один компонент.
Эта согласованная система также проверяет состояние ядра базы данных перед добавлением узла в пул. С помощью этой системы мы можем убедиться, что ваш экземпляр базы данных остается согласованным.
Демон конфигурации. Этот демон работает на каждом экземпляре базы данных. Он отвечает за генерацию конфигурации двигателя и решает, является ли он активным или резервным узлом, на основе согласованного механизма. Этот демон будет выполнять тяжелую работу по управлению механизмом переключения при отказе в вашем кластере базы данных.
Когда система находится в полностью рабочем состоянии, активный экземпляр базы данных будет периодически выполнять операцию записи в DCS. Эта периодическая операция записи называется heartbeat.
Он сохраняет активную базу данных как владельца активной блокировки.
Резервный также считывает этот DCS и видит, что активный узел существует и, следовательно, находится в режиме ожидания. Если в течение определенного времени активной базе данных не удается выполнить операцию записи в DCS, активная база данных считается неисправной. Когда бэкэнд обнаружен как неисправный, соединения с ним обрываются на уровне балансировки нагрузки. DCS также снимает блокировку, если активная база данных не проявляет себя. Когда это происходит, резервный сервер пытается стать активным путем записи в DCS. Делая это, резервный узел информирует DCS, что он готов стать активным.
После достижения консенсуса с DCS резервный узел повышается в качестве основного, и экземпляр базы данных может продолжать работать.
В случае сбоя экземпляра сработает внутренняя система мониторинга группы базы данных, которая сгенерирует новый резервный узел для замены неисправного.
Заключение
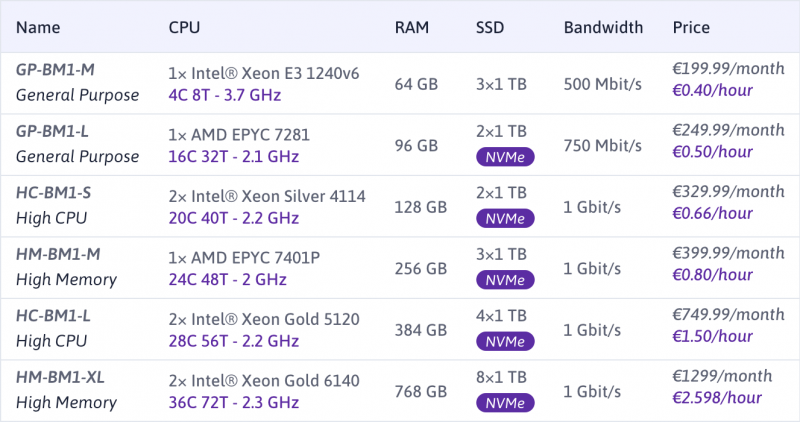
Scaleway Elements предоставляет обширный каталог управляемых сервисов баз данных PostgreSQL. Получите выгоду от управляемой базы данных PostgreSQL, начиная с 8 евро в месяц (или 0,016 евро в час) и разворачивая ее менее чем за 5 минут. Среди наших новых предложений вы можете выбрать базу данных, соответствующую вашему проекту, с 256 ГБ ОЗУ и 585 ГБ SSD NVMe для повышения производительности.
www.scaleway.com/en/database/
Узнайте, как запустить свою первую базу данных, благодаря нашей документации и часто задаваемым вопросам по Scaleway Elements. Или узнайте, как перенести ваш экземпляр PostgreSQL в экземпляр базы данных PostgreSQL Scaleway Elements через нашу документацию по API.
www.scaleway.com/en/docs/database-instance/
developers.scaleway.com/en/products/rdb/api/#migration-to-scaleway-database