Теперь вы можете запускать свои виртуальные экземпляры в двух изолированных зонах доступности
Теперь вы можете запускать свои виртуальные экземпляры в двух изолированных зонах доступности (PAR1 и PAR2) для большей устойчивости.

Распространяйте свои приложения на fr-par1 и fr-par2, чтобы гарантировать их высокую доступность! И запускайте их в инновационной, безуглеродной и энергоэффективной среде: DC5
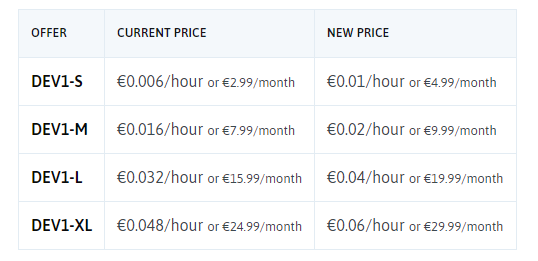
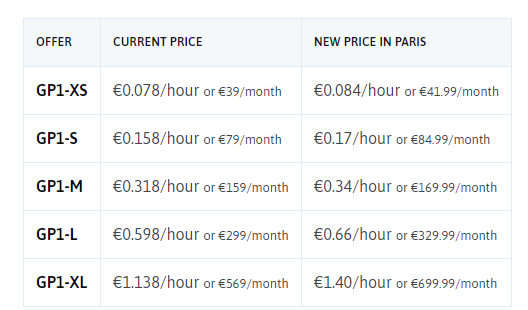
fr-par2 теперь доступен для ваших экземпляров DEV и GP и томов блочного хранилища!
Несколько дней назад мы объявили о нашем новом регионе Варшавы для виртуальных экземпляров (DEV & GP) и сегментов объектного хранилища стандартного класса. И поскольку хорошие новости приходят парами… теперь вы можете развернуть свои экземпляры DEV и GP и тома блочного хранилища в нашей зоне доступности fr-par2 (AZ)!
Разработан, чтобы гарантировать повышенную доступность и соответствовать требованиям устойчивости
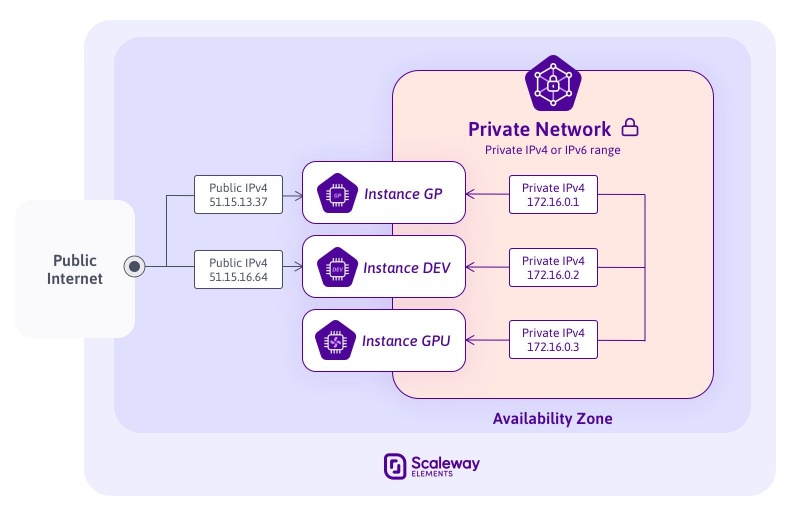
Оба запуска преследуют общую цель: предоставить вам еще более стабильные и эффективные услуги для создания отказоустойчивой инфраструктуры. Поскольку экземпляры DEV и GP теперь могут работать в двух разных зонах доступности (fr-par1 и fr-par2), вы можете распределить свои приложения по нескольким центрам обработки данных в регионе Парижа, чтобы обеспечить более высокую доступность и оптимальную отказоустойчивость. Эти зоны доступности полностью изолированы и разделены расстоянием более 10 км, что позволяет создать устойчивую инфраструктуру.
Разработан для очень высоких экологических показателей
Кроме того, fr-par2 AZ находится в нашем офисе DC5. DC5 — это экологически чистый и инновационный центр обработки данных с нулевым выбросом углерода, в котором одновременно используются прямое воздушное охлаждение и адиабатическая система. Это означает, что ваши облачные ресурсы работают в инновационной и чистой среде.
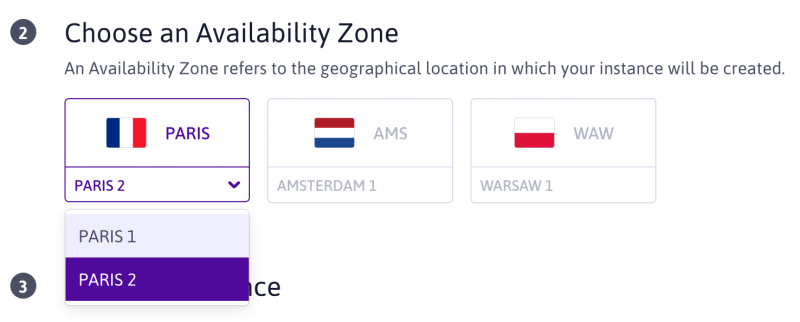
Вы уже можете запускать свои экземпляры DEV и GP и тома блочного хранилища в fr-par2 через консоль Scaleway или API.
Распространяйте свои приложения на fr-par1 и fr-par2, чтобы гарантировать их высокую доступность! И запускайте их в инновационной, безуглеродной и энергоэффективной среде: DC5
fr-par2 теперь доступен для ваших экземпляров DEV и GP и томов блочного хранилища!
Несколько дней назад мы объявили о нашем новом регионе Варшавы для виртуальных экземпляров (DEV & GP) и сегментов объектного хранилища стандартного класса. И поскольку хорошие новости приходят парами… теперь вы можете развернуть свои экземпляры DEV и GP и тома блочного хранилища в нашей зоне доступности fr-par2 (AZ)!
Разработан, чтобы гарантировать повышенную доступность и соответствовать требованиям устойчивости
Оба запуска преследуют общую цель: предоставить вам еще более стабильные и эффективные услуги для создания отказоустойчивой инфраструктуры. Поскольку экземпляры DEV и GP теперь могут работать в двух разных зонах доступности (fr-par1 и fr-par2), вы можете распределить свои приложения по нескольким центрам обработки данных в регионе Парижа, чтобы обеспечить более высокую доступность и оптимальную отказоустойчивость. Эти зоны доступности полностью изолированы и разделены расстоянием более 10 км, что позволяет создать устойчивую инфраструктуру.
Разработан для очень высоких экологических показателей
Кроме того, fr-par2 AZ находится в нашем офисе DC5. DC5 — это экологически чистый и инновационный центр обработки данных с нулевым выбросом углерода, в котором одновременно используются прямое воздушное охлаждение и адиабатическая система. Это означает, что ваши облачные ресурсы работают в инновационной и чистой среде.
Наши системы обработки естественным воздухом и адиабатического охлаждения являются первыми в своем роде во Франции. Серверы охлаждаются простым воздушным потоком, связанным с испарением воды. Этот адиабатический процесс обеспечивает чрезвычайно низкий PUE 1, равный 1,15. DC5 потребляет до 40% меньше энергии, чем большинство центров обработки данных, и питается исключительно от возобновляемых источников энергии. Таким образом, это инфраструктура с нулевым выбросом углерода, которая сильно отличается от стратегии с нулевым выбросом углерода, которая может быть достигнута посредством политики компенсации. Наш новаторский подход позволяет нам сочетать технологические и энергетические показатели для удовлетворения потребностей компаний, которые все больше обеспокоены своим воздействием на окружающую среду.объясняет Арно де Бермигам, президент Scaleway.
Вы уже можете запускать свои экземпляры DEV и GP и тома блочного хранилища в fr-par2 через консоль Scaleway или API.