все новости по филиалам
Поиск
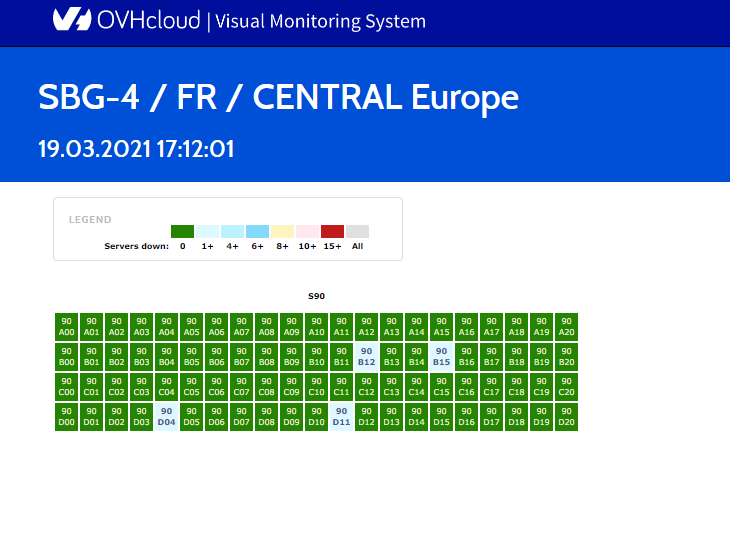
SBG4 all servers are UP [19-03-2021]
SBG1 61E, 62E
Диск, процессор, оперативная память работают хорошо, но нам нужно заменить материнскую плату всех серверов. Чтобы сделать это быстро, мы заменим их все на одну стандартную материнскую плату с Atom и позволим пользователям получать и переносить данные на другой сервер.
18-03-2021 log sbg
- В панели управления OVHcloud каждый затронутый клиент может просмотреть статус своих служб, расположенных в Страсбурге (SBG), как подробно описано в FAQ. => help.ovhcloud.com/en/faq/strasbourg-incident/how-can-get-overview-impact/
- Платформа сообщества OVHcloud теперь доступна для взаимодействия с членами сообщества и поддержки вас. => Https://community.ovh.com/en/
- Следуя протоколу безопасности, определенному для локальных операций: перезапуск будет выполняться комната за комнатой, проход за проходом и стойка за стойкой.
- Процедуры перезапуска сервисов будут сообщены затронутым клиентам по мере того, как подробности станут доступны в ближайшие дни.
- Мониторинг перезапуска SBG по помещениям и запланированным стойкам в реальном времени доступен по адресу: status.ovh.com/vms/sbg/
SBG-1
- — Ситуация: центр обработки данных работает.
- — Электрический перезапуск: выполнен
- — Перезагрузка сети: завершена
- — Перезагрузка сервера: первые стойки успешно протестированы. Передача клиенту сегодня с видимостью статуса в его панели управления клиентами OVHcloud.
SBG-2
- — Ситуация: здание не используется. Проведена структурная экспертиза. Сайт защищен
- — Перезагрузка сервера: замена инфраструктуры в других центрах обработки данных Gravelines (GRA), Roubaix (RBX), Лондон (LON), Варшава (WAW), Франкфурт (FRA)
SBG-3
- — Ситуация: центр обработки данных работает. Серверы не повреждены.
- — Электрический перезапуск: выполнен
- — Перезагрузка сети: завершена
- — Перезапуск сервера: протестируйте сегодня на одной стойке и, если окончательно, предварительную оценку на пятницу, 19 марта, для постепенного перезапуска служб.
SBG-4
- — Ситуация: центр обработки данных работает. Все этажи и серверы в целости и сохранности.
- — Электрический перезапуск: выполнен
- — Перезагрузка сети: завершена
- — Перезапуск сервера: предварительное время прибытия: понедельник, 22 марта, для постепенного перезапуска служб.
- • Сегодня на территории мобилизовано 136 человек.
- o Составлен график ротации команд на предстоящие выходные.
- Очистка сайта:
- o Команды по уборке работают на SBG1 и SBG3 во всех пострадавших районах.
- o Некоторые серверы в SBG3 требуют специальной очистки перед их возвратом в эксплуатацию. Мы начали этот процесс.
Обновленная информация о поставках с 10 марта:
- — Оголенный метал
- + Bare Metal — серверы — Количество: 4519
- + NAS-HA — TB — Количество: 246
- — Публичное облако
- + VPS — VM — Количество: 12353
- — Размещенное частное облако
- + Хост — серверы — Количество: 485
- + Хранилище данных
- + Количество Zpool: 522
- + Объем ТБ: 3067
Сегодня произведено 400 серверов.
Чтобы следить за обновлениями об этой ситуации в режиме реального времени:
Нашим основным средством коммуникации остается «Статус задачи».
Статусные видео доступны здесь:
FR: twitter.com/olesovhcom/status/1370045226929299461
EN: twitter.com/olesovhcom/status/1370045891806175232
Аккаунт Октава Клабы в Twitter: twitter.com/olesovhcom
OVHcloud Twitter: twitter.com/ovhcloud
Наша миссия по-прежнему заключается в том, чтобы предоставлять нашим клиентам услуги высочайшего качества, поддерживать их онлайн-бизнес. и мы знаем, насколько это важно для них. Приносим искренние извинения за возможные неудобства, связанные с данной ситуацией. В настоящее время проводится расследование причин. Какой бы ни была причина инцидента, OVHcloud в настоящее время оценивает возможные технические и эксплуатационные меры, чтобы предложить решения всем затронутым клиентам.
17-03-2021 log sbg
Статус услуги
Коммерческие действия
Обновленная информация о поставках с 10 марта:
Облачная вселенная:
В связи с текущим спросом сроки доставки наших услуг для изделий из чистого металла могут быть дольше, чем обычно. Наши команды полностью мобилизованы, и мы прилагаем все усилия, чтобы доставить их нашим клиентам как можно быстрее, особенно всем пострадавшим клиентам.
С другой стороны, услуги Public Cloud, Web Cloud и VPS предоставляются в обычном режиме во всех центрах обработки данных.
- Октав Клаба, основатель OVHcloud, выпустил новое видео о ситуации в Страсбурге (SBG). => twitter.com/olesovhcom/status/1371934994751500288
- В Панели управления каждый затронутый клиент может просмотреть статус своих услуг, расположенных в Страсбурге (SBG), как подробно описано в FAQ. => help.ovhcloud.com/en/faq/strasbourg-incident/how-can-get-overview-impact/
- Платформа сообщества OVHcloud теперь доступна для взаимодействия с членами сообщества и поддержки вас.
- Следуя протоколу безопасности, определенному для локальных операций: перезапуск будет выполняться комната за комнатой, от прохода к проходу и стойка за стойкой.
- Процедуры перезапуска служб будут сообщены затронутым клиентам по мере того, как подробности станут доступны в ближайшие дни.
- Мониторинг перезапуска SBG в режиме реального времени по помещению и запланированной стойке через: travaux.ovh.net/vms/index_sbg1.html
- Постепенное обновление страницы состояния для служб и резервных копий в Страсбурге (SBG), начиная с сегодняшнего дня, доступно через FAQ.
- Обновление и отслеживание процента перезапущенных сервисов для каждого центра обработки данных, запланированных в интерфейсе «Состояние задачи» в ближайшие дни.
- Создана новая форма заказа (для Bare Metal Cloud), чтобы предлагать заинтересованным клиентам услуги, аналогичные тем, которые они имели на сайте в Страсбурге (SBG).
Коммерческие действия
- Все заинтересованные клиенты получили в начале недели сообщение о коммерческих мерах, которые будут применяться к их ситуации. Для клиентов, которые не получили электронное письмо, процедура была указана в FAQ.
- Для каждого заинтересованного клиента:
- Уведомление о приостановке выставления счетов за март было добавлено в Панель управления клиентов.
- Указаны коммерческие акции, подробности которых будут сообщены на этой неделе.
Обновленная информация о поставках с 10 марта:
Облачная вселенная:
- — Оголенный метал
- + Bare Metal — серверы — Количество: 4200
- + NAS-HA — TB — Количество: 276
- — Публичное облако
- + VPS — VM — Количество: 11998
- — Размещенное частное облако
- + Хост — серверы — Количество: 434
- + Хранилище данных
- + Количество Zpool: 466
- + Объем ТБ: 2950
Сегодня произведено 400 серверов.
В связи с текущим спросом сроки доставки наших услуг для изделий из чистого металла могут быть дольше, чем обычно. Наши команды полностью мобилизованы, и мы прилагаем все усилия, чтобы доставить их нашим клиентам как можно быстрее, особенно всем пострадавшим клиентам.
С другой стороны, услуги Public Cloud, Web Cloud и VPS предоставляются в обычном режиме во всех центрах обработки данных.
VPS теперь доступен в Хиллсборо, штат Орегон

Мы рады сообщить, что наши решения VPS теперь доступны в нашем центре обработки данных в Хиллсборо, ИЛИ! Если вы ищете решение для размещения игр, работы над проектами в песочнице, потоковой передачи видео или поддержки небольших виртуальных машин, наш VPS предлагает пять настраиваемых конфигураций ресурсов, каждая с широким спектром опций программного обеспечения. Это большой шаг в процессе расширения наших предложений в нашем центре обработки данных на западном побережье.
us.ovhcloud.com/vps/
С нашими решениями VPS вы можете ожидать:
- Стабильность — пропускная способность и использование ресурсов других VPS не повлияет на вашу производительность.
- Опции — свобода выбора операционных систем, программного обеспечения и root-доступ к серверу
- Производительность — более высокая пропускная способность для посетителей вашего веб-сайта и возможность размещать игры без проблем с задержкой
- Масштабируемость — обновите свой VPS, когда ваш бизнес набирает обороты, с большим объемом оперативной памяти или дополнительным хранилищем
Не стесняйтесь обращаться, если у вас есть дополнительные вопросы о том, как использовать наши новые предложения VPS в Хиллсборо, штат Орегон! Просто ответьте на это письмо, и специалист по продукту свяжется с вами.
16-03-2021 log sbg
SBG-1
SBG-2
SBG-3
SBG-4
Облачная вселенная:
Связь
Часто задаваемые вопросы доступны по следующей ссылке: help.ovhcloud.com/en-gb/faq/strasbourg-incident/
Чтобы следить за обновлениями об этой ситуации в режиме реального времени:
Нашим основным средством коммуникации остается «Статус задачи».
Статусные видео доступны здесь:
FR: twitter.com/olesovhcom/status/1370045226929299461
EN: twitter.com/olesovhcom/status/1370045891806175232
Аккаунт Октава Клабы в Twitter: twitter.com/olesovhcom
OVHcloud Twitter: twitter.com/ovhcloud
Наша миссия по-прежнему состоит в том, чтобы предоставлять нашим клиентам услуги высочайшего качества, поддерживать их онлайн-бизнес, и мы знаем, насколько это важно для них. Приносим искренние извинения за любые неудобства, связанные с этой ситуацией. В настоящее время проводится расследование причин. Какой бы ни была причина инцидента, OVHcloud в настоящее время оценивает возможные технические и эксплуатационные меры, чтобы предложить решения всем затронутым клиентам.
Доступны все наши каналы связи, включая нашу платформу отслеживания инцидентов, чтобы вы могли быть в курсе событий в режиме реального времени.
- — Ситуация: 4 номера из 12 повреждены
- + Комнаты 61AD / 62AD: серверы не затронуты
- + Помещения 61E / 62D: ведется уборка серверов
- — Электрический перезапуск:
- + Электроэнергия восстановлена
- + Поврежденные ИБП проверены и заменяются
- — Перезагрузка сети:
- + Магистраль: временное подключение к SBG 15 марта
- + Повторное развертывание и настройка локальной сети сегодня
- — Перезапуск сервера: предварительное время прибытия: понедельник, 22 марта, для постепенного перезапуска.
SBG-2
- Ситуация: здание не используется. Проведена структурная экспертиза. Сайт защищен
- Перезагрузка: замена инфраструктуры в других центрах обработки данных Gravelines (GRA), Roubaix (RBX), Лондон (LON), Варшава (WAW), Франкфурт (FRA)
SBG-3
- — Ситуация: серверы не повреждены
- — Электрический перезапуск:
- + Электроэнергия восстановлена сегодня
- + Все инверторы в рабочем состоянии
- — Перезагрузка сети:
- + Сегодня подключена новая сетевая комната
- + Развертывание локальной сети 17 марта
- Перезапуск: предварительное время прибытия: понедельник, 22 марта, для постепенного перезапуска.
SBG-4
- Ситуация: все этажи и серверы спасены.
- Электрический перезапуск: Электропитание восстановлено сегодня
- Перезагрузка сети: повторное развертывание локальной сети сегодня
- Перезапуск сервера: предварительное время прибытия: понедельник, 22 марта, для постепенного перезапуска.
101 человек мобилизован и находится на территорииОбновленная информация о поставках с 10 марта:
Облачная вселенная:
- — Оголенный метал
- + Bare Metal — серверы — Количество: 3939
- + NAS-HA — TB — Количество: 222
- — Публичное облако
- + VPS — VM — Количество: 10731
- — Размещенное частное облако
- + Хост — серверы — Количество: 372
- + Хранилище данных
- + Количество Zpool: 393
- + Объем ТБ: 2704
Сегодня было произведено 350 серверов.
Связь
Часто задаваемые вопросы доступны по следующей ссылке: help.ovhcloud.com/en-gb/faq/strasbourg-incident/
Чтобы следить за обновлениями об этой ситуации в режиме реального времени:
Нашим основным средством коммуникации остается «Статус задачи».
Статусные видео доступны здесь:
FR: twitter.com/olesovhcom/status/1370045226929299461
EN: twitter.com/olesovhcom/status/1370045891806175232
Аккаунт Октава Клабы в Twitter: twitter.com/olesovhcom
OVHcloud Twitter: twitter.com/ovhcloud
Наша миссия по-прежнему состоит в том, чтобы предоставлять нашим клиентам услуги высочайшего качества, поддерживать их онлайн-бизнес, и мы знаем, насколько это важно для них. Приносим искренние извинения за любые неудобства, связанные с этой ситуацией. В настоящее время проводится расследование причин. Какой бы ни была причина инцидента, OVHcloud в настоящее время оценивает возможные технические и эксплуатационные меры, чтобы предложить решения всем затронутым клиентам.
Доступны все наши каналы связи, включая нашу платформу отслеживания инцидентов, чтобы вы могли быть в курсе событий в режиме реального времени.
15-03-2021 log sbg
На объекте выделено 111 человек для подключения сетевых и электрических узлов (по очереди, 24/24), для:
Перераспределение мощности:
Повторное развертывание сети:
Очистка от сажи серверных SBG3 начнется во вторник, 16 марта. Команды по очистке прибыли на место и начинают развертывание.
15-03-2021 произведено 500 серверов.
Обновленная информация о поставках с 10 марта:
Перераспределение мощности:
- Электрические установки, необходимые для перезапуска SBG1 / SBG4, были проверены.
- Высоковольтный источник питания для SBG3 развернут и находится в рабочем состоянии.
- Сегодня выполняется протокол повторного ввода в эксплуатацию инвертора (проверка всех ИБП).
Повторное развертывание сети:
- Сетевая комната SBG1 проходит испытания.
- Новое сетевое помещение завершается и будет обеспечено электричеством, как только инверторы будут проверены.
- Установка сетевого оборудования будет завершена сегодня вечером.
- Подключение магистрали запланировано на завтра.
- Локальная сеть перераспределяется.
Очистка от сажи серверных SBG3 начнется во вторник, 16 марта. Команды по очистке прибыли на место и начинают развертывание.
15-03-2021 произведено 500 серверов.
Обновленная информация о поставках с 10 марта:
- + Baremetal
- + Bare Metal — серверы — Количество: 3658
- + NAS-HA — TB — Количество: 220
- + Публичное облако
- + VPS — VM — Количество: 8903
- + Размещенное частное облако
- + Хост — серверы — Количество: 328
- + Хранилище данных
- + Количество Zpool: 361
- + Объем ТБ: 2598
14-03-2021 log sbg
Информация о клиенте:
Статус сервера
Коммерческие действия
План действий:
Приоритет 1: восстановление услуг для SBG1, SBG3 и SBG4
Сводка состояния для каждого центра обработки данных
SBG-1
SBG-2
SBG-3
SBG-4
На объекте работает бригада из 60 человек для подключения мобильной сети и энергоблоков (работает по очереди, 24 часа в сутки):
Очистка от сажи серверных SBG3 начнется во вторник, 16 марта.
Система охлаждения исправна:
Приоритет 2: предоставление инфраструктуры в других центрах обработки данных для затронутых нами клиентов.
Приоритет 3: Внедрение всех механизмов DRP (плана аварийного восстановления) с нашими клиентами.
Связь
Часто задаваемые вопросы доступны по следующей ссылке: help.ovhcloud.com/en-gb/faq/strasbourg-incident/
Чтобы следить за обновлениями об этой ситуации в режиме реального времени:
Нашим основным средством коммуникации остается «Статус задачи».
Статусные видео доступны здесь:
— FR: twitter.com/olesovhcom/status/1370045226929299461
— EN: twitter.com/olesovhcom/status/1370045891806175232
Аккаунт Октава Клабы в Twitter: twitter.com/olesovhcom
OVHcloud Twitter: twitter.com/ovhcloud_fr
Наша миссия по-прежнему заключается в предоставлении нашим клиентам услуг высочайшего качества для поддержки их онлайн-активности, и мы знаем, насколько это важно для них. Мы искренне приносим свои извинения за проблемы, вызванные этим пожаром. Мы продолжим сообщать с максимальной прозрачностью о причине пожара и его последствиях.
Расследование продолжается. Какой бы ни была причина инцидента, OVHcloud в настоящее время оценивает возможные технические и эксплуатационные меры, чтобы предложить решения всем затронутым клиентам.
Доступны все наши каналы связи, включая нашу платформу отслеживания инцидентов, чтобы вы могли быть в курсе событий в режиме реального времени.
Статус сервера
- Создана страница, на которой перечислены резервные копии служб, размещенных в Страсбурге (SBG), которыми управляет заказчик или OVHcloud, а также их статус, которые будут доступны в разделе часто задаваемых вопросов в течение следующих нескольких часов.
- Для клиентов Public Cloud и VPS вопрос «зона или центр обработки данных (SBG)» был разъяснен в FAQ сегодня.
Коммерческие действия
- Все затронутые клиенты будут уведомлены о приостановленном мартовском счете в своей Панели управления.
- Подробная информация о том, как эти меры будут реализованы, будет отправлена на следующей неделе, а также будет применяться к мартовским счетам за затронутые услуги, которые уже были выпущены до 10 марта.
План действий:
Приоритет 1: восстановление услуг для SBG1, SBG3 и SBG4
Сводка состояния для каждого центра обработки данных
SBG-1
- Ситуация: 4 номера из 12 повреждены
- Электрический перезапуск: временно переведен на 13 марта и будет окончательно восстановлен 17 марта.
- Перезагрузка сети:
- + Магистраль: временное подключение к SBG 15 марта
- + Внутренняя сеть будет развернута 17 марта
- Перезапуск сервера: предварительное время прибытия: понедельник, 22 марта, для постепенного перезапуска.
SBG-2
- Ситуация: здание не используется
- Перезагрузка сервера: замена инфраструктуры в других центрах обработки данных
SBG-3
- Ситуация: серверы не повреждены
- Электрический перезапуск: временно отключен 12 марта и будет полностью восстановлен 16 марта.
- Перезагрузка сети:
- + Новая сетевая комната будет развернута и включена 16/03
- + Внутренняя сеть будет развернута 17 марта
- Перезапуск сервера: предварительное время прибытия: понедельник, 22 марта, для постепенного перезапуска.
SBG-4
- Ситуация: серверы не повреждены
- Электрический перезапуск: питание будет постоянно восстановлено 17 марта.
- Перезагрузка сети: внутренняя сеть будет повторно развернута 17 марта.
- Перезапуск сервера: предварительное время прибытия: понедельник, 22 марта, для постепенного перезапуска.
На объекте работает бригада из 60 человек для подключения мобильной сети и энергоблоков (работает по очереди, 24 часа в сутки):
- Выполняется кабельная разводка.
- Подключение запланировано на сегодня вечером.
Очистка от сажи серверных SBG3 начнется во вторник, 16 марта.
Система охлаждения исправна:
- Водяное охлаждение защищено от холода (местный прогноз — четверг, 18 марта, и пятница, 19 марта).
- Насосы в рабочем состоянии.
Приоритет 2: предоставление инфраструктуры в других центрах обработки данных для затронутых нами клиентов.
- Для клиентов, которых это затронуло, мы предлагаем заменяющие инфраструктуры (Bare Metal, Hosted Private Cloud и Public Cloud) в наших центрах обработки данных Roubaix (RBX) и Gravelines (GRA).
- Мы намерены предоставить около 15 000 новых серверов в ближайшие недели.
- Обновленная информация о поставках с 10 марта:
- Облачная вселенная:
- + Baremetal
- + Bare Metal — серверы — Количество: 3424
- + NAS-HA — TB — Количество: 196
- + Публичное облако
- + VPS — VM — Количество: 7770
- + Размещенное частное облако
- + Хост — серверы — Количество: 207
- + Хранилище данных
- + Количество Zpool: 205
- + Объем ТБ: 1772
Приоритет 3: Внедрение всех механизмов DRP (плана аварийного восстановления) с нашими клиентами.
- Наши группы поддержки и технические менеджеры по работе с клиентами находятся в контакте с нашими клиентами и разработали план поддержки для клиентов, которые еще не активировали свои DRP.
Связь
Часто задаваемые вопросы доступны по следующей ссылке: help.ovhcloud.com/en-gb/faq/strasbourg-incident/
Чтобы следить за обновлениями об этой ситуации в режиме реального времени:
Нашим основным средством коммуникации остается «Статус задачи».
Статусные видео доступны здесь:
— FR: twitter.com/olesovhcom/status/1370045226929299461
— EN: twitter.com/olesovhcom/status/1370045891806175232
Аккаунт Октава Клабы в Twitter: twitter.com/olesovhcom
OVHcloud Twitter: twitter.com/ovhcloud_fr
Наша миссия по-прежнему заключается в предоставлении нашим клиентам услуг высочайшего качества для поддержки их онлайн-активности, и мы знаем, насколько это важно для них. Мы искренне приносим свои извинения за проблемы, вызванные этим пожаром. Мы продолжим сообщать с максимальной прозрачностью о причине пожара и его последствиях.
Расследование продолжается. Какой бы ни была причина инцидента, OVHcloud в настоящее время оценивает возможные технические и эксплуатационные меры, чтобы предложить решения всем затронутым клиентам.
Доступны все наши каналы связи, включая нашу платформу отслеживания инцидентов, чтобы вы могли быть в курсе событий в режиме реального времени.
состояние каждой службы в каждом DC
- состояние каждой службы в каждом DC
- состояние нашей внутренней резервной копии (без договора)
- состояние Резервной копии Сервиса (если cust взял услугу)
www.ovhcloud.com/en/lp/status-services-backup-strasbourg/