Мы «Хостинг технологии» и 5 лет назад запустили
VDSina — первый vds хостинг, созданный специально для разработчиков. Мы стремимся сделать его удобным, как DigitalOcean, но с русской поддержкой, способами оплаты и серверами в России. Но DigitalOcean это не только надежность и цена, это еще и сервис.
Софт от ISPsystem оказался веревкой, которая связывала нам руки на пути к крутому сервису. Три года назад мы использовали биллинг Billmanager и панель управления серверами VMmanager и быстро поняли, что оказывать хороший сервис без своей панели практически нереально.
Как ISPsystem убивал удобство
Баги
Мы не могли сами пофиксить баг — каждый раз приходилось писать в чужую поддержку и ждать. Решение любой проблемы требовало реакции сторонней компании.
Поддержка ISPsystem нормально отвечала, но фиксы приходили только через несколько релизов, и то не всегда и не все. Иногда критические баги правились несколько недель. Нам приходилось успокаивать клиентов, извиняться и ждать, пока ISPsystem починят баг.
Угроза даунтаймов
Обновления могли порождать непрогнозируемые даунтаймы, которые провоцировали новые ошибки.
Каждый апдейт был лотереей: приходилось прикрывать биллинг и приносить жертвы богам обновлений — пару раз апдейт вызывал даунтайм на минут 10-15. Наши админы в это время седели на глазах — мы никогда не знали, сколько продлится даунтайм и не могли спрогнозировать, когда ISPsystem решит выпустить новый апдейт.
На пятом поколении Billmanager стало получше, но чтобы получить доступ к необходимым фичам пришлось ставить бету, которая уже обновлялась каждую неделю. Если что-то ломалось, приходилось давать доступ чужим разработчикам, чтобы они что-то поправили.
Неудобный интерфейс панели
Всё было разделено на разные панели и управлялось из разных мест. Например, клиенты платили через Billmanager, а перезагружать или переустанавливать VDS им приходилось в VMManager. Нашим сотрудникам тоже приходилось переключаться между окнами, чтобы помочь клиенту, проверить нагрузку на его сервере или посмотреть, какую ОС он использует.
Такой интерфейс отнимает время — и наше, и клиентов. Ни о каком удобстве, как у DigitalOcean, в такой ситуации речи не идёт.
Короткие лайфциклы с частым обновлением API
Мы писали собственные плагины — например, плагин с дополнительными способами оплаты, которых нет в VMManager.
В последние годы у VMManager был относительно короткий жизненный цикл, причем в новых версиях могли произвольно меняться названия переменных или функций в API — это ломало наши плагины. Поддержку старых версий быстро сворачивали и приходилось обновляться.
Нельзя дорабатывать
Точнее можно, но крайне неэффективно. Лицензионные ограничения не дают вносить изменения в исходники, можно только писать плагины. Максимум плагинов — какие-то элементы меню, пошаговый мастер. ISPsystem заточены на универсальность, а нам нужны были специализированные решения.
Так созрело решение написать свою панель. Мы поставили цели:
- Быстро реагировать на ошибки, баги и иметь возможность самостоятельно устранять их, не заставляя клиента ждать.
- Свободно модифицировать интерфейс под рабочие процессы и нужды клиента.
- Повысить юзабилити чистым и понятным дизайном.
И начали разработку.
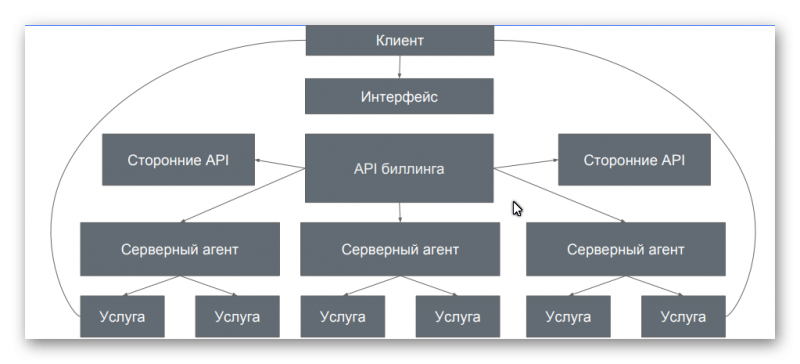
Архитектура новой панели
У нас есть самодостаточная команда разработки, так что панель мы написали сами.
Основную работу проделали три инженера — технический директор Сергей придумал архитектуру и написал серверный агент, Алексей сделал биллинг, а фронтенд собрал наш фронтендер Артыш.
Шаг 1. Серверный агент
Серверный агент — это веб-сервер на питоне, который управляет библиотекой libvirt, которая, в свою очередь, управляет гипервизором Qemu-kvm.
Агент управляет всеми услугами на сервере: создание, остановка, удаление vds, установка операционных систем, изменение параметров и так далее через библиотеку libvirt. На момент выхода статьи это больше сорока разных функций, которые мы дополняем в зависимости от задачи и потребностей клиента.
По идее libvirt можно было управлять прямо из биллинга, но это требовало слишком много дополнительного кода и мы решили разнести эти функции между агентом и биллингом — биллинг просто делает запросы агенту через JSON API.
Агент — первое, что мы сделали, поскольку он не требовал никакого интерфейса и тестировать его можно было прямо из консоли сервера.
Что дал нам серверный агент: появилась прослойка, которая упрощает жизнь всем — биллингу не нужно передавать целую кучу команд, а только сделать запрос. А агент сделает все, что нужно: например, выделит место на диске и оперативную память.
Шаг 2. Биллинг
Для нашего разработчика Алекса это была уже не первая панель управления — Алекс в хостинге давно, поэтому он в целом понимал, что нужно клиенту и что нужно хостеру.
Биллинг мы и называем между собой «панелью управления»: в нем не только деньги и услуги, но и управление ими, поддержка клиентов и многое другое.
Для перехода с софта ISPSystem, необходимо было полностью сохранить клиентам предыдущий функционал, перенести все финансовые действия пользователей из старого биллинга в новый, а также все услуги и связи между ними. Мы изучили что есть в текущем продукте, потом решения конкурентов, в основном DO и Vultr. Посмотрели на недостатки и преимущества, собрали отзывы людей, которые работали со старыми продуктами от ISPsystem.
В новом биллинге использовали два стека: классический PHP, MySQL (а в будущем планируется перейти на PostgreSQL), Yii2 в качестве фреймворка на бекэнде и VueJS на фронте. Стеки работают независимо друг от друга, разрабатываются разными людьми, а общаются с помощью JSON API. Для разработки тогда и сейчас мы используем PHPStorm и WebStorm от JetBrains и нежно их любим (ребята, привет!)
Панель спроектирована по модульному принципу: модули платёжных систем, модуль регистраторов доменов или, например, модуль SSL-сертификатов. Можно легко добавить новую функцию или убрать старую. Задел на расширение заложен архитектурно, в том числе и в обратную сторону, «к железу».
 Что мы получили
Что мы получили: панель управления, над которой у нас полный контроль. Теперь баги правятся за часы, а не недели, а новые функции реализовываются по просьбе клиентов, а не по желанию ISPSystem.
Шаг 3. Интерфейс
Интерфейс — наше командное детище.
Сначала мы посмотрели, что будет, если сделать надстройку над API ISPsystem, ничего кардинально не меняя в интерфейсе. Вышло так себе и мы решили всё сделать с нуля.
Мы верили, что главное — сделать интерфейс логичным, с чистым и минималистичным дизайном и тогда получим красивую панель. Расположение элементов обсуждали в Мегаплане и постепенно родится тот интерфейс, который пользователи видят в панели управления сейчас.
Первой появился дизайн странички биллинга, ведь мы уже делали плагины оплаты для ISPsystem.
Фронтенд
Панель решили сделать SPA приложением — нетребовательной к ресурсам и с быстрой загрузкой данных. Наш фронтендер Артыш решил писать ее на Vue — на тот момент Vue только появился. Мы предположили, что фреймворк будет развиваться динамично, как React, через какое-то время коммьюнити Vue разрастется и появится море библиотек. Мы поставили на Vue и не пожалели — теперь добавить на фронт новые функции, которые уже запрограммировали на бекенде занимает мало времени. Подробнее про фронтенд панели мы расскажем в отдельной статье.
Связь фронтенда с бекендом
Фронтенд связали с бекендом через пуши. Пришлось попотеть и написать собственный обработчик, но теперь обновление информации на странице происходят почти моментально.
Что получилось: интерфейс панели стал проще. Мы сделали ее адаптивной, а быстрая прогрузка позволяет пользоваться ей даже с мобильников в последние минуты перед взлетом, не устанавливая отдельное приложение для работы с панелью.
Шаг 4. Тестирование и схема миграции
Когда все завелось и прошли первые тесты, встал вопрос миграции. Первым делом мы поставили биллинг и начали тестировать его работу с серверным агентом.
Потом написали простой скрипт, который переносит базу данных из старого биллинга в новый.
Приходилось тестировать и перепроверять буквально все, так как данные сливали в одну новую базу из трёх старых: Billmanager, VMmanager и IPmanager менеджера. Пожалуй, тестовые миграции — самое сложное, с чем мы столкнулись в процессе разработки новой панели.
После перепроверок, мы прикрыли старый биллинг. Финальная миграция данных была очень тревожным моментом, но, слава Богу, выполнилась за несколько минут и без заметных проблем. Были мелкие баги, которые мы чинили в течение недели. Основное время заняло тестирование того, что получилось.
Затем мы разослали письма клиентам с адресом новой панели и биллинга и сделали редирект.
В итоге: IT’S ALIVE!
Хэппиэнд
С первых часов работы своего софта мы почувствовали все прелести перехода. Код был полностью наш и с удобной архитектурой, а интерфейс — чистым и логичным.
Первый отзыв после запуска новой панели

Мы запустили процесс перехода в декабре, накануне Нового 2017 года, когда нагрузки было меньше всего, чтобы сделать переход проще для клиентов — почти никто не работает накануне праздников.
Главное, что мы получили при переходе на свою систему (кроме общей надежности и удобства) — возможность быстро добавлять функционал под ключевых клиентов — быть к ним лицом, а не задницей.
Что дальше?
Мы растём, растёт количество данных, клиентов, данных клиентов. На бекенд пришлось добавить Memcached-сервер и два менеджера очередей с разными задачами. На фронтенде есть кэширование и свои очереди.
Конечно, у нас еще были приключения по мере разработки и усложнения продукта, например, когда мы добавляли HighLoad.
В следующей статье расскажем, как запускали Hi-CPU тариф: про железо, ПО, какие задачи мы решали и что у нас получилось.
vdsina.ru