Мы поздравляем всех наших клиентов и посетителей сайта с наступающим Новым Годом и дарим новогоднюю акцию на выделенные серверы. Заказать выделенный сервер за 2000 рублей можно перейдя по баннеру в левом нижнем краю экрана, либо по ссылке.
Эта новость понравится всем без исключения. Первые родительские узлы на процессорах E5 уже заполнены, но желающих так много, что мы решили продолжить наращивать количество узлов в новом кластере! Эта неделя началась с добавлением двух новых родительских узлов в кластер с серверами на процессорах Intel E5-2680v2 www.ihor.ru
Мы продолжаем стандартизировать работу службы технической поддержки. И сегодня готовы предоставить небольшой прайс-лист того, что мы готовы сделать для вас. Этот список в течением времени, несомненно, будет расширяться. Он поможет вам полностью контролировать ценообразование платных работ с вашими услугами.
Так же мы вводим скидку в 10% на платные работы по волшебной фразе: «У меня лапки». www.ihor.ru/documents/2017/additional-services-27.11.2017.pdf
9 ноября прошла презентация нашего нового дата-центра под кодовым названием «МАРОСНЕТ 2». Присутствовали, как сотрудники компании, так и приглашённые гости.
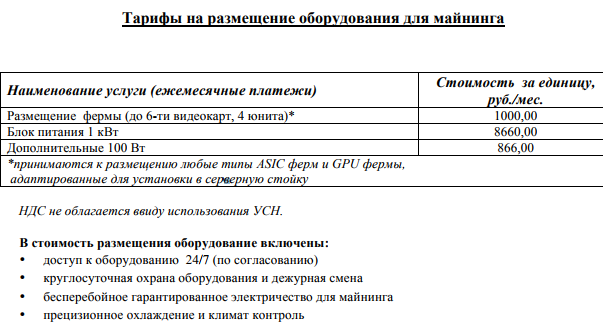
Мы продолжаем работать над увеличением количества предоставляемых услуг. И сегодня мы готовы представить вам новую услугу — Размещение майнинг-ферм.
Она отлично подойдёт как для тех, кому уже не хватает пространства в домашней обстановке, так и тем, кто только подумывает заняться этим интересным и прибыльным делом, но не знает где это можно разместить.
Наши специалисты примут и аккуратно разместят аппаратное обеспечение с максимальным удобством. Избавят Вас от больших счетов за электричество и возможный шум от работы ферм.
Вся информация об условиях представлена на отдельной странице нашего сайта по майнингу.
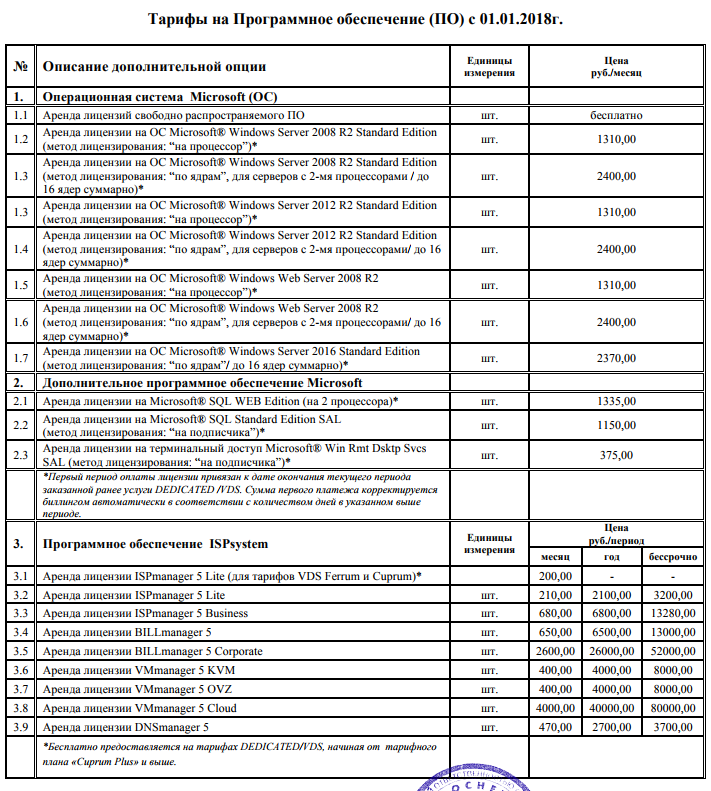
Стоимость лицензии ISPmanager 5 Lite на тарифных планах Ferrum составит 200 рублей в месяц.
Стоимость лицензии ISPmanager 5 Lite на тарифных планах Cuprum составит 200 рублей в месяц.
Лицензии ISPmanager 5 Lite предоставляется бесплатно начиная с тарифного плана Cuprum Plus для виртуальных серверов и для всех выделенных серверов. Сотрудники технической поддержки готовы оказать помощь в переносе ваших сайтов на бесплатные панели управления (например, VestaCP).
С полным перечнем тарифов на ПО можно ознакомиться на сайте компании в разделе программное обеспечение www.ihor.ru/agreements