Январь — новогодние обещания, Атлант 3.0 и базы данных на CLO
Сколько лет прошло, всё о том же гудят провода — как мы с нового года начинаем новую жизнь. Но кто ж нам запретит пытаться? Как и обещали, в 2023-м вас ждёт много интересных обновлений. Начинаем уже сейчас!

В январском дайджесте рассказываем, какое обновление получил наш самый надёжный тариф «Атлант», показываем первый в этом году релиз от CLO и традиционно делимся полезными инструкциями и статьями.
Статьи и инструкции
Как настроить почтовый клиент для работы с email?
Чтобы работать с электронной почтой, вам нужен почтовый клиент. Для каждой операционной системы существуют различные клиенты, при этом не важно, на какой ОС работает сам почтовый сервер. В статье пошагово объясняем, как настроить почтовый клиент, на примере Mozilla Thunderbird.
firstvds.ru/technology/kak-nastroit-pochtovyy-klient-dlya-raboty-s-email
Как настроить серверы имён на VDS без ISPmanager
Если вам необходимо обеспечить работу серверов имён на своём VDS, используйте нашу инструкцию — расписали порядок действий как для серверов с ОС Linux, так и с Windows. Там же рассказываем, как проверить работоспособность DNS-сервера.
firstvds.ru/technology/nastroyka-servera-imen-dns-server-na-vds-bez-ispmanager
Habr: самое интересное за январь
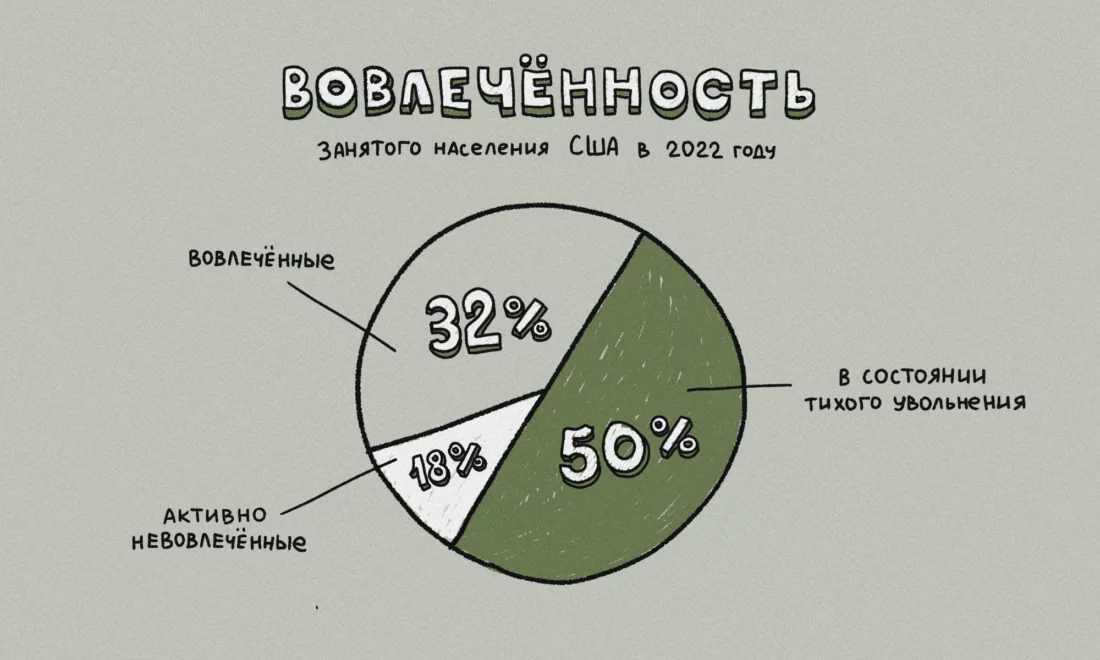
Что такое тихое увольнение и почему его боятся американские корпорации
Не менее половины работающих американцев практикуют «тихое увольнение» — обычно это признак того, что менеджменту пора пересмотреть свои отношения с коллективом. Разбираем новый тренд с точки зрения науки, выясняем, почему так происходит и чем это вредит компаниям, а также ищем эффективный выход из ситуации.
Новости
А теперь к новостям января.

Прокачали VDS Атлант до версии 3.0
Обновили наш самый надёжный тариф «Атлант» до версии 3.0 — вот уж по-настоящему мощное начало года! Теперь вы можете собрать VDS с характеристиками:

Релиз облачных баз данных на CLO
Клиентам CLO теперь доступен сервис облачных баз данных. Чтобы задеплоить MySQL и PostgreSQL, достаточно просто заполнить форму в Личном кабинете — базы данных развернутся автоматически, а наши специалисты возьмут на себя мониторинг доступности и восстановление работы сервиса в случае непредвиденных ситуаций.
clo.ru/help/dbaas
Уязвимости и релизы
Уязвимость в nftables позволяет выполнить код на уровне ядра
Исследователи обнаружили уязвимость в Netfilter, подсистеме ядра Linux. Злоумышленник может использовать её, чтобы поднять привилегии локального пользователя и выполнить код на уровне ядра. Проблема проявляется с выпуска ядра 5.5 и вызвана ошибкой в арифметической операции для определения размера данных, извлекаемых из заголовка VLAN. Исправление пока доступно в форме патча.
www.opennet.ru/opennews/art.shtml?num=58480
В процессорах AMD Ryzen и EPYC исправлено более 30 уязвимостей
Компания AMD сообщила о 31 уязвимости в своих процессорах, 28 из них проявляются в серии EPYC, ещё 3 — в Ryzen. Для закрытия обнаруженных уязвимостей разработчики внесли правки в несколько версий библиотеки AGESA и отправили их производителям материнских плат для обновления BIOS.
3dnews.ru/1080343/amd-obnarugila-31-uyazvimost-v-raznih-protsessorah-vklyuchaya-ryzen-i-epyc
В Git исправлены две уязвимости, позволяющие выполнить код удалённо
Разработчики опубликовали корректирующие выпуски для системы Git, где исправили две уязвимости, которые потенциально позволяют злоумышленнику выполнить свой код на системе пользователя при использовании команды «git archive» и работе с не заслуживающими доверия внешними репозиториями.
www.opennet.ru/opennews/art.shtml?num=58498
Linux-бэкдор атакует сайты на WordPress
Специалисты обнаружили вредоносную программу для Linux, которая взламывает сайты на WordPress, используя 30 уязвимостей в плагинах и темах оформления. На уязвимые сайты внедряются вредоносные JavaScript-скрипты, из-за чего при клике мышью в любом месте скомпрометированной страницы посетителей перенаправляют на другие ресурсы.
xakep.ru/2023/01/09/wordpress-malware/
В январском дайджесте рассказываем, какое обновление получил наш самый надёжный тариф «Атлант», показываем первый в этом году релиз от CLO и традиционно делимся полезными инструкциями и статьями.
Статьи и инструкции
Как настроить почтовый клиент для работы с email?
Чтобы работать с электронной почтой, вам нужен почтовый клиент. Для каждой операционной системы существуют различные клиенты, при этом не важно, на какой ОС работает сам почтовый сервер. В статье пошагово объясняем, как настроить почтовый клиент, на примере Mozilla Thunderbird.
firstvds.ru/technology/kak-nastroit-pochtovyy-klient-dlya-raboty-s-email
Как настроить серверы имён на VDS без ISPmanager
Если вам необходимо обеспечить работу серверов имён на своём VDS, используйте нашу инструкцию — расписали порядок действий как для серверов с ОС Linux, так и с Windows. Там же рассказываем, как проверить работоспособность DNS-сервера.
firstvds.ru/technology/nastroyka-servera-imen-dns-server-na-vds-bez-ispmanager
Habr: самое интересное за январь
- Вот и первый месяц нового года за плечами, успели втянуться в рабочий ритм? Наши авторы уже трудятся в поте лица — всё самое-самое в нашей подборке.
- 7 шагов по организации пространства в серверной стойке
- Технология ABENICS: революция в области механики?
- История развития паролей и средств их хранения
- Исследование сна от MIT: как высыпаться и повысить свою продуктивность
- Обзор OWASP ZAP. Сканер для поиска уязвимостей в веб-приложениях
Что такое тихое увольнение и почему его боятся американские корпорации
Не менее половины работающих американцев практикуют «тихое увольнение» — обычно это признак того, что менеджменту пора пересмотреть свои отношения с коллективом. Разбираем новый тренд с точки зрения науки, выясняем, почему так происходит и чем это вредит компаниям, а также ищем эффективный выход из ситуации.
Новости
А теперь к новостям января.
Прокачали VDS Атлант до версии 3.0
Обновили наш самый надёжный тариф «Атлант» до версии 3.0 — вот уж по-настоящему мощное начало года! Теперь вы можете собрать VDS с характеристиками:
- до 192 ядер,
- до 768 Гб оперативной памяти,
- до 8 Тб независимого хранилища Ceph на базе NVMe.
Релиз облачных баз данных на CLO
Клиентам CLO теперь доступен сервис облачных баз данных. Чтобы задеплоить MySQL и PostgreSQL, достаточно просто заполнить форму в Личном кабинете — базы данных развернутся автоматически, а наши специалисты возьмут на себя мониторинг доступности и восстановление работы сервиса в случае непредвиденных ситуаций.
clo.ru/help/dbaas
Уязвимости и релизы
Уязвимость в nftables позволяет выполнить код на уровне ядра
Исследователи обнаружили уязвимость в Netfilter, подсистеме ядра Linux. Злоумышленник может использовать её, чтобы поднять привилегии локального пользователя и выполнить код на уровне ядра. Проблема проявляется с выпуска ядра 5.5 и вызвана ошибкой в арифметической операции для определения размера данных, извлекаемых из заголовка VLAN. Исправление пока доступно в форме патча.
www.opennet.ru/opennews/art.shtml?num=58480
В процессорах AMD Ryzen и EPYC исправлено более 30 уязвимостей
Компания AMD сообщила о 31 уязвимости в своих процессорах, 28 из них проявляются в серии EPYC, ещё 3 — в Ryzen. Для закрытия обнаруженных уязвимостей разработчики внесли правки в несколько версий библиотеки AGESA и отправили их производителям материнских плат для обновления BIOS.
3dnews.ru/1080343/amd-obnarugila-31-uyazvimost-v-raznih-protsessorah-vklyuchaya-ryzen-i-epyc
В Git исправлены две уязвимости, позволяющие выполнить код удалённо
Разработчики опубликовали корректирующие выпуски для системы Git, где исправили две уязвимости, которые потенциально позволяют злоумышленнику выполнить свой код на системе пользователя при использовании команды «git archive» и работе с не заслуживающими доверия внешними репозиториями.
www.opennet.ru/opennews/art.shtml?num=58498
Linux-бэкдор атакует сайты на WordPress
Специалисты обнаружили вредоносную программу для Linux, которая взламывает сайты на WordPress, используя 30 уязвимостей в плагинах и темах оформления. На уязвимые сайты внедряются вредоносные JavaScript-скрипты, из-за чего при клике мышью в любом месте скомпрометированной страницы посетителей перенаправляют на другие ресурсы.
xakep.ru/2023/01/09/wordpress-malware/













