Google Cloud Platform
Поиск

Visualize 2030: Google Cloud hosts data storytelling contest with the United Nations Foundation
Visualize 2030: Google Cloud hosts data storytelling contest with the United Nations Foundation, the World Bank, and the Global Partnership for Sustainable Development Data
Примечание редактора: настройте завтра, вторник, 25 сентября 2018 года, в 12 часов вечера PST / 3 вечера EST, чтобы Cloud OnAir услышать от Шейна Гласса, премьер-министра для публичных наборов данных в Google Cloud, и Эндрю Уитби, научного сотрудника по данным Всемирного банка, приложений публичных наборов данных и визуализации данных в государственном секторе, а также о том, как учащиеся более высокого уровня могут участвовать в конкурсе Visualize 2030.
Узнайте больше о том, как Visualize 2030 поощряет рассказы, связанные с данными, о целях развития.
«Визуализация 2030» — это конкурс рассказов о событиях для студентов университетов, организованный в партнерстве со Всемирным банком, Фондом Организации Объединенных Наций и данными Глобального партнерства в интересах устойчивого развития. Мы приглашаем студентов на уровне колледжа и выпускников использовать Google Data Studio для анализа наборов данных из Всемирного банка и Организации Объединенных Наций и рассказать историю данных о Целях устойчивого развития ООН. Если вы активно участвуете в учебе, узнайте больше и применитесь здесь.
НПО, МПО и некоммерческие организации все чаще обращаются к аналитике данных и компьютерному обучению для достижения своих миссий в масштабе, изучают партнерские отношения и возможности для сотрудничества с частным сектором. В основе этого растущего «данных для хорошего» движения относятся междисциплинарные и международные партнерские отношения, приносящие частные и общественные организации, чтобы применять современные технологии к самым серьезным проблемам в мире.
Одной из таких возможностей для сотрудничества являются публичные наборы данных. Google Cloud запустила свою программу Public Datasets в 2016 году с целью облегчения доступа к данным и развития знаний, путем миграции более 100 наборов данных, которые анализируются во всем мире. Для каждого набора данных Google Cloud покрывает расходы на миграцию и хранение бесплатно, позволяя любому пользователю с действительной учетной записью GCP запрашивать до 1 ТБ в месяц — снова бесплатно. По сравнению с нашими наборами данных BigQuery, начиная с GSOD NOAA и заканчивая историей качества воздуха EPA, общий объем запросов данных превышает 100 петабайт. Стоит также отметить, что вертикали, такие как климат, здоровье и экономика, в частности, могут помочь некоммерческим организациям ускорить реализацию своих проектов по аналитике данных и продвинуть социальные причины.
Эти точки данных очень похожи на словарный запас: чтобы понять их, вы должны объединить их вместе в убедительное предложение. В противном случае, как и сами слова, метрики существуют только сами по себе, в строго ограниченных определениях и этимологиях. Такие предложения могут быть объединены в таблицы, группы и объединения, развиваясь в гладкие абзацы, которые сразу начинают рассказывать историю. Эта история может быть проиллюстрирована, то есть визуализирована. Визуализация данных — еще один полезный ресурс для миссионерских организаций, которые хотят внедрить аналитику данных, способствуя синтезированной и убедительной передаче информации. С помощью Google Data Studio любой пользователь может создавать интерактивные информационные панели или отчеты из BigQuery и более 500 других источников данных через экосистему сообщества сообщества Data Studio бесплатно. В то время как одна некоммерческая организация, например, Фонд Прецизионной Медицины, может использовать Data Studio для визуализации чувствительной медицинской информации, не покидая безопасную облачную среду, другая организация, такая как Harambee Youth Employment Accelerator, может использовать ее, чтобы лучше синтезировать свои данные и соответствовать безработной молодежи с заданиями в Южной Африке. Любая организация может рассказать историю, которая будет служить их цели, поддерживать их сообщество или даже изменить мир.
datastudio.google.com/reporting/1jxiA_D8CXWu_rH0jQ2dXOGcfUJD9JrhV/page/2WOV
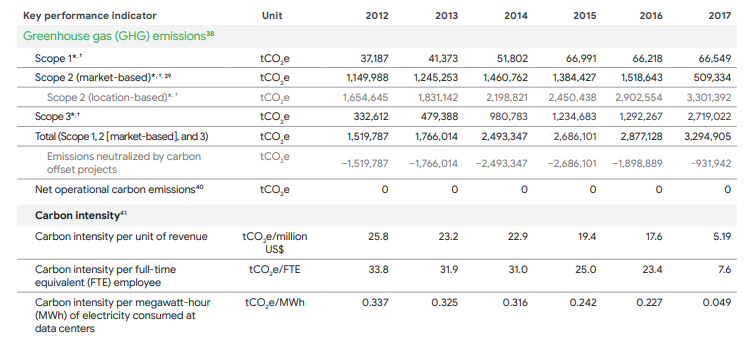
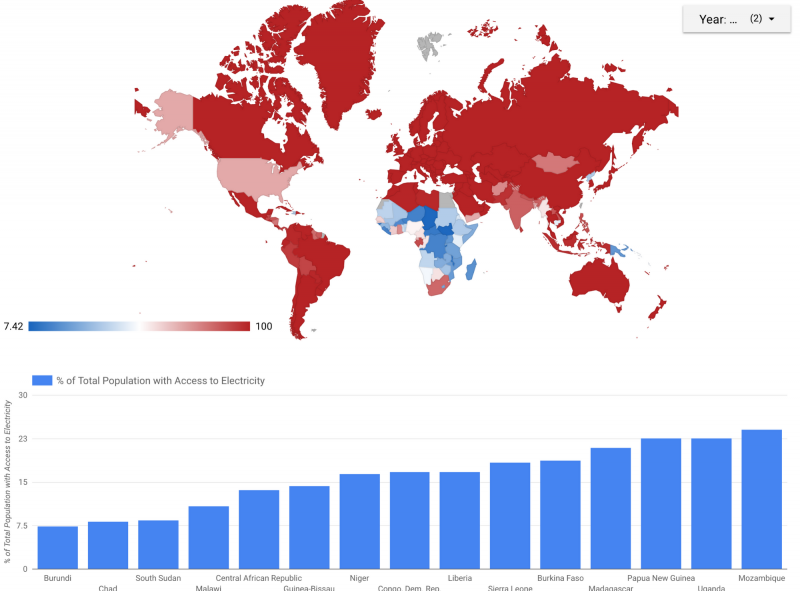
Эта визуализация предоставляет демонстрацию, которая может служить отправной точкой для пользователей, желающих визуализировать данные WDI. Глобальная тепловая карта показывает среднюю долю всего населения, имеющего доступ к электричеству по странам. На гистограмме внизу показаны 15 стран с самой низкой общей долей населения с доступом к электричеству за тот же период времени.
Именно с этим оптимизмом мы запустили еще одну инициативу в июле 2018 года: визуализировать 2030 | Истории данных для SDG (Цели устойчивого развития). В партнерстве с Фондом Организации Объединенных Наций, Всемирным банком и Глобальным партнерством по данным в области устойчивого развития мы поощряем учащихся на более высоком уровне анализировать наборы данных и рассказывать историю о повестке дня 2030 года, состоящую из 17 Устойчивого развития Цели (SDG). Эти СГД были определены Организацией Объединенных Наций и варьируются от сохранения биоразнообразия до прекращения бедности. В частности, мы просим учащихся проанализировать недавно перенесенные общедоступные наборы данных из Статистического отдела Организации Объединенных Наций и Всемирного банка и использовать Data Studio, чтобы рассказать историю данных о том, как по крайней мере две SDG влияют друг на друга и как мы можем их достичь 2030. Мы надеемся, что, работая вместе, мы можем вдохновить ученых нового поколения на то, чтобы принять меры и присоединиться к данным для хорошего движения. Если вы участвуете в университетском университете, который хочет узнать больше о Visualize 2030, посетите сайт cloud.google.com/visualize-2030
В этом духе междисциплинарного сотрудничества мы будем участвовать в Неделе глобальных целей, которая состоится на этой неделе вокруг Генеральной Ассамблеи ООН в Нью-Йорке. Ребекка Мур, директор Google Earth Engine, будет представлять Google Earth и Google Cloud на сессии под названием «Большие данные для лучшей жизни: мобильная связь, статистика и анализ» 25 сентября вместе с представителями таких организаций, как ЮНИСЕФ и Мировая продовольственная программа (МПП), а также в Зоне СМИ SDG 27 сентября, чтобы поговорить об устойчивости и SDG.
https://cloud.google.com/blog/
Примечание редактора: настройте завтра, вторник, 25 сентября 2018 года, в 12 часов вечера PST / 3 вечера EST, чтобы Cloud OnAir услышать от Шейна Гласса, премьер-министра для публичных наборов данных в Google Cloud, и Эндрю Уитби, научного сотрудника по данным Всемирного банка, приложений публичных наборов данных и визуализации данных в государственном секторе, а также о том, как учащиеся более высокого уровня могут участвовать в конкурсе Visualize 2030.
Узнайте больше о том, как Visualize 2030 поощряет рассказы, связанные с данными, о целях развития.
«Визуализация 2030» — это конкурс рассказов о событиях для студентов университетов, организованный в партнерстве со Всемирным банком, Фондом Организации Объединенных Наций и данными Глобального партнерства в интересах устойчивого развития. Мы приглашаем студентов на уровне колледжа и выпускников использовать Google Data Studio для анализа наборов данных из Всемирного банка и Организации Объединенных Наций и рассказать историю данных о Целях устойчивого развития ООН. Если вы активно участвуете в учебе, узнайте больше и применитесь здесь.
НПО, МПО и некоммерческие организации все чаще обращаются к аналитике данных и компьютерному обучению для достижения своих миссий в масштабе, изучают партнерские отношения и возможности для сотрудничества с частным сектором. В основе этого растущего «данных для хорошего» движения относятся междисциплинарные и международные партнерские отношения, приносящие частные и общественные организации, чтобы применять современные технологии к самым серьезным проблемам в мире.
Одной из таких возможностей для сотрудничества являются публичные наборы данных. Google Cloud запустила свою программу Public Datasets в 2016 году с целью облегчения доступа к данным и развития знаний, путем миграции более 100 наборов данных, которые анализируются во всем мире. Для каждого набора данных Google Cloud покрывает расходы на миграцию и хранение бесплатно, позволяя любому пользователю с действительной учетной записью GCP запрашивать до 1 ТБ в месяц — снова бесплатно. По сравнению с нашими наборами данных BigQuery, начиная с GSOD NOAA и заканчивая историей качества воздуха EPA, общий объем запросов данных превышает 100 петабайт. Стоит также отметить, что вертикали, такие как климат, здоровье и экономика, в частности, могут помочь некоммерческим организациям ускорить реализацию своих проектов по аналитике данных и продвинуть социальные причины.
Эти точки данных очень похожи на словарный запас: чтобы понять их, вы должны объединить их вместе в убедительное предложение. В противном случае, как и сами слова, метрики существуют только сами по себе, в строго ограниченных определениях и этимологиях. Такие предложения могут быть объединены в таблицы, группы и объединения, развиваясь в гладкие абзацы, которые сразу начинают рассказывать историю. Эта история может быть проиллюстрирована, то есть визуализирована. Визуализация данных — еще один полезный ресурс для миссионерских организаций, которые хотят внедрить аналитику данных, способствуя синтезированной и убедительной передаче информации. С помощью Google Data Studio любой пользователь может создавать интерактивные информационные панели или отчеты из BigQuery и более 500 других источников данных через экосистему сообщества сообщества Data Studio бесплатно. В то время как одна некоммерческая организация, например, Фонд Прецизионной Медицины, может использовать Data Studio для визуализации чувствительной медицинской информации, не покидая безопасную облачную среду, другая организация, такая как Harambee Youth Employment Accelerator, может использовать ее, чтобы лучше синтезировать свои данные и соответствовать безработной молодежи с заданиями в Южной Африке. Любая организация может рассказать историю, которая будет служить их цели, поддерживать их сообщество или даже изменить мир.
datastudio.google.com/reporting/1jxiA_D8CXWu_rH0jQ2dXOGcfUJD9JrhV/page/2WOV
Эта визуализация предоставляет демонстрацию, которая может служить отправной точкой для пользователей, желающих визуализировать данные WDI. Глобальная тепловая карта показывает среднюю долю всего населения, имеющего доступ к электричеству по странам. На гистограмме внизу показаны 15 стран с самой низкой общей долей населения с доступом к электричеству за тот же период времени.
Именно с этим оптимизмом мы запустили еще одну инициативу в июле 2018 года: визуализировать 2030 | Истории данных для SDG (Цели устойчивого развития). В партнерстве с Фондом Организации Объединенных Наций, Всемирным банком и Глобальным партнерством по данным в области устойчивого развития мы поощряем учащихся на более высоком уровне анализировать наборы данных и рассказывать историю о повестке дня 2030 года, состоящую из 17 Устойчивого развития Цели (SDG). Эти СГД были определены Организацией Объединенных Наций и варьируются от сохранения биоразнообразия до прекращения бедности. В частности, мы просим учащихся проанализировать недавно перенесенные общедоступные наборы данных из Статистического отдела Организации Объединенных Наций и Всемирного банка и использовать Data Studio, чтобы рассказать историю данных о том, как по крайней мере две SDG влияют друг на друга и как мы можем их достичь 2030. Мы надеемся, что, работая вместе, мы можем вдохновить ученых нового поколения на то, чтобы принять меры и присоединиться к данным для хорошего движения. Если вы участвуете в университетском университете, который хочет узнать больше о Visualize 2030, посетите сайт cloud.google.com/visualize-2030
В этом духе междисциплинарного сотрудничества мы будем участвовать в Неделе глобальных целей, которая состоится на этой неделе вокруг Генеральной Ассамблеи ООН в Нью-Йорке. Ребекка Мур, директор Google Earth Engine, будет представлять Google Earth и Google Cloud на сессии под названием «Большие данные для лучшей жизни: мобильная связь, статистика и анализ» 25 сентября вместе с представителями таких организаций, как ЮНИСЕФ и Мировая продовольственная программа (МПП), а также в Зоне СМИ SDG 27 сентября, чтобы поговорить об устойчивости и SDG.
https://cloud.google.com/blog/
Open Match: Flexible and extensible matchmaking for games

Сегодняшние игры все больше связаны, объединяя игроков в общей среде, где они могут проверить свое мастерство и изобретательность в отношении геймеров по всему миру.
Но создание сватовства — искусство согласования множества игроков вместе, чтобы максимизировать их удовольствие от игры — с технической точки зрения нелегко и может потребовать много ресурсов, чтобы получить право. Каждая игра уникальна, из-за чего трудно создать готовое решение для совместной работы, чтобы быть достаточно гибким, чтобы поддерживать их. Следовательно, разработчики игр часто проводят значительное время и ресурсы, разрабатывая индивидуальное масштабируемое решение для каждой новой версии, когда они могут тратить время на то, что они делают лучше всего, создавая отличные игры.
Что делать, если разработчики игр могли бы сосредоточиться только на логике Matchmaking — входы и логика для выбора игроков — вместо того, чтобы строить целую сваху с нуля для каждой игры? Google Cloud and Unity совместно объявляют о доступности проекта по созданию знакомств с открытым исходным кодом под названием Open Match, чтобы сделать именно это. Open Match предназначен для того, чтобы создатели игр могли повторно использовать общую структуру сватов. Он включает в себя три основных компонента: интерфейсный API для игровых клиентов, бэкэнд-интерфейс для игровых серверов и оркестр, который управляет индивидуальной логикой знакомств. Он основан на OpenCensus (opencensus.io) для сбора метрик, а Prometheus (prometheus.io) настроен по умолчанию.
С Open Match разработчики получают следующие преимущества:
- Расширяемость. Примеры пользовательской логики соответствия доступны для простого сопоставления игроков на основе латентности, времени ожидания и произвольного рейтинга навыков.
- Гибкость. Поскольку Open Match работает на Kubernetes, вы можете развернуть его в любом общедоступном облаке, локальном центре обработки данных или даже на локальной рабочей станции.
- Масштабируемость. Open Match разработан с использованием проверенных шаблонов веб-микросервисов, а с Kubernetes в качестве базовой платформы, добавляя дополнительную емкость для ваших API, когда у вас больше клиентов, так же просто, как и одна команда. Автомасштабирование Кубернеса также может быть использовано для автоматизации.
Хотя Open Match является соучредителем Google Cloud и Unity, это не зависит от игрового движка. Он может быть интегрирован в любую игру, независимо от того, как построена игра или какая инфраструктура работает. Unity будет основывать будущую технологию Matchmaking на Open Match, поэтому клиенты Unity смогут более легко использовать свои функции, например, путем интеграции с серверами Unity. Репо Open Open GitHub теперь открыто для вкладов, и вы можете следовать примеру, приведенному в руководстве по настройке разработки, чтобы начать экспериментировать сегодня.
github.com/GoogleCloudPlatform/open-match/blob/master/docs/development.md
Cisco Hybrid Cloud Platform for Google Cloud: Now generally available
Независимо от того, являются ли они облачными или модернизируют свою инфраструктуру на месте, многие предприятия могут воспользоваться хорошо поддерживаемым путем, позволяющим им перемещаться в облако на своих условиях. Чтобы решить эту проблему, мы объявили о своем партнерстве с Cisco в октябре прошлого года на новой открытой гибридной облачной платформе, которая объединяет локальные и облачные среды. Сегодня мы рады объявить о том, что платформа гибридных облачных вычислений Cisco для Google Cloud теперь доступна в целом, предоставляя нашим клиентам больше возможностей при рассмотрении гибридных решений.
Cisco является идеальным партнером для нас в этой области благодаря многолетнему сосредоточению бизнеса и опыту в области сетей, безопасности, аналитики и гиперконверсированной инфраструктуры. Cisco Hybrid Cloud Platform для Google Cloud предлагает еще один способ беспрепятственно работать на месте и в облаке, обеспечивая скорость и масштаб, где клиенты больше всего этого нуждаются. Приложения в облаке могут использовать возможности на местах, в том числе существующие ИТ-системы, а приложения на местах могут использовать новые облачные возможности — без необходимости полного перехода в общедоступное облако.
Это полностью интегрированное решение позволяет разработчикам использовать возможности корпоративного уровня от Google Cloud, такие как управляемые Kubernetes, каталог сервисов GCP, сеть Cisco и безопасность, а также проверку подлинности Istio и мониторинг сервисов. Центр технической поддержки Cisco (TAC) предоставит клиентам единый источник поддержки. Он расширяет сетевые политики и конфигурации Cisco, а также контролирует поведение приложений в гибридных облачных средах.
Более подробно о том, что могут сделать компании:
Telindus, интегратор, телекоммуникатор и поставщик облачных услуг, приняли участие в нашей Программе раннего доступа и использовали Cisco Hybrid Cloud Platform для Google Cloud для развертывания решений на основе контейнеров в средах, поскольку безопасность является ключевой. Гибридная облачная платформа позволила интегрированному управлению развертыванием и загрузкой контейнеров через государственные и частные облака по-настоящему гибридно, что является ключевым требованием для высоко регулируемых и чувствительных к безопасности отраслей.
Говорит д-р Томас Шерер, главный архитектор Telindus SA: «Виртуальная гибридная облачная платформа Cisco для Google Cloud обеспечивает готовое решение для облачного локального опыта и может быть легко масштабирована до общего облака, используя такие сервисы, как Google Kubernetes Engine и BigQuery ». Вы можете узнать больше от Cisco о развертывании Telindus в своем блоге.
blogs.cisco.com/cloud/promise-of-hybrid-cloud-delivered
Мы надеемся, что гибридная облачная платформа Cisco для Google Cloud позволит большему числу предприятий перейти в облако темпами, которые работают на них, при этом максимизируя инвестиции на предварительном этапе и избегая блокировки. Мы также сотрудничаем с Cisco по решению Cisco и Google Cloud, предлагая призы организациям, которые пересматривают взаимодействие своих локальных и облачных приложений.
developer.cisco.com/googlechallenge/
Чтобы узнать больше о Cisco Hybrid Cloud Platform для Google Cloud, посетите наш веб-сайт.
cloud.google.com/cisco/
Cisco является идеальным партнером для нас в этой области благодаря многолетнему сосредоточению бизнеса и опыту в области сетей, безопасности, аналитики и гиперконверсированной инфраструктуры. Cisco Hybrid Cloud Platform для Google Cloud предлагает еще один способ беспрепятственно работать на месте и в облаке, обеспечивая скорость и масштаб, где клиенты больше всего этого нуждаются. Приложения в облаке могут использовать возможности на местах, в том числе существующие ИТ-системы, а приложения на местах могут использовать новые облачные возможности — без необходимости полного перехода в общедоступное облако.
Это полностью интегрированное решение позволяет разработчикам использовать возможности корпоративного уровня от Google Cloud, такие как управляемые Kubernetes, каталог сервисов GCP, сеть Cisco и безопасность, а также проверку подлинности Istio и мониторинг сервисов. Центр технической поддержки Cisco (TAC) предоставит клиентам единый источник поддержки. Он расширяет сетевые политики и конфигурации Cisco, а также контролирует поведение приложений в гибридных облачных средах.
Более подробно о том, что могут сделать компании:
- Ускорьте модернизацию приложений, используя стратегию контейнеров на основе Kubernetes, которая совместима с облачными технологиями, включая GKE. Cisco предоставит готовое решение для кубернетов и контейнеров под ключ, а также инструменты управления для обеспечения соблюдения политик безопасности и потребления.
- Простота управления услугами. Технология Istio с открытым исходным кодом, с использованием контейнеров и микросервисов предлагает разработчикам единый способ подключения, защиты, управления и мониторинга микросервисов через облака с помощью контроля доступа к сервису уровня сервиса mTLS. В результате они могут легко внедрять новые портативные сервисы и централизованно настраивать и управлять этими услугами.
- Быстро и надежно подключайте рабочие нагрузки к облакам. Управление API через Apigee позволяет использовать устаревшие рабочие нагрузки на предварительном уровне для подключения к облаку через API. С Apigee предприятия могут предоставлять устаревшие услуги, предоставляя им безопасные API для разработчиков, которые затем могут легко включить эти службы в свое современное приложение.
- Воспользуйтесь интегрированной системой безопасности и поддержки. Клиенты могут расширить свои существующие политики безопасности Cisco и мониторинг в облаке и быть уверенными в совместной координации технической поддержки от Cisco и Google Cloud.
Telindus, интегратор, телекоммуникатор и поставщик облачных услуг, приняли участие в нашей Программе раннего доступа и использовали Cisco Hybrid Cloud Platform для Google Cloud для развертывания решений на основе контейнеров в средах, поскольку безопасность является ключевой. Гибридная облачная платформа позволила интегрированному управлению развертыванием и загрузкой контейнеров через государственные и частные облака по-настоящему гибридно, что является ключевым требованием для высоко регулируемых и чувствительных к безопасности отраслей.
Говорит д-р Томас Шерер, главный архитектор Telindus SA: «Виртуальная гибридная облачная платформа Cisco для Google Cloud обеспечивает готовое решение для облачного локального опыта и может быть легко масштабирована до общего облака, используя такие сервисы, как Google Kubernetes Engine и BigQuery ». Вы можете узнать больше от Cisco о развертывании Telindus в своем блоге.
blogs.cisco.com/cloud/promise-of-hybrid-cloud-delivered
Мы надеемся, что гибридная облачная платформа Cisco для Google Cloud позволит большему числу предприятий перейти в облако темпами, которые работают на них, при этом максимизируя инвестиции на предварительном этапе и избегая блокировки. Мы также сотрудничаем с Cisco по решению Cisco и Google Cloud, предлагая призы организациям, которые пересматривают взаимодействие своих локальных и облачных приложений.
developer.cisco.com/googlechallenge/
Чтобы узнать больше о Cisco Hybrid Cloud Platform для Google Cloud, посетите наш веб-сайт.
cloud.google.com/cisco/
Product updates | September 4, 2018

NVIDIA Tesla P4 GPUs for Compute Engine: beta
Compute Engine now offers NVIDIA Tesla P4 GPUs for 3D visualization, deep learning, video transcoding, and high-performance computing. NVIDIA Tesla P4 GPUs offer up to 5.5 teraflops of single-precision performance and 22 tera operations per second of INT8 performance.
cloud.google.com/blog/products/gcp/introducing-nvidia-tesla-p4-gpus-accelerating-virtual-workstations-and-ml-inference-compute-engine
Cloud Firestore: beta
Cloud Firestore, our serverless, NoSQL document database, is in the process of adding new hosting locations and is now available in the Google Cloud Platform Console. Current Cloud Firestore beta users will see their projects in consoles for both Firebase and GCP.
cloud.google.com/blog/products/gcp/expanding-the-cloud-firestore-beta-to-more-users
Compute Engine единственного арендатора узлы: GA
Подошва-арендатор узлы физических серверов Compute Engine, которые предлагают вам те же типы машин и варианты, как обычные экземпляры вычислительными — в том числе нестандартных форм машин и прозрачного технического обслуживания — но на серверах, посвященный одному пользователю.
cloud.google.com/compute/docs/nodes/
Стандартная среда App Engine — Python 3.7: бета
Python 3.7 выполнения на App Engine стандартной среды дает вам последние версии популярных библиотек, неограниченной среды выполнения, снижение латентности затрат, и код, который более компактен, и проще в обслуживании.
cloud.google.com/blog/products/gcp/introducing-app-engine-second-generation-runtimes-and-python-3-7
Binary Авторизация: бета
Binary авторизации является контроль безопасности развертывания времени, что позволяет определять политику, обеспечивая только доверенные контейнеры развернуты в вашей среде на Kubernetes Engine. Binary авторизации поддерживает имидж подписания, а также белый список изображений.
cloud.google.com/blog/products/identity-security/deploy-only-what-you-trust-introducing-binary-authorization-for-google-kubernetes-engine
Предотвращение потери данных Cloud API хранится пользовательский словарь детектор: GA
Большой словарь детекторы позволяют заказчикам создавать пользовательский детектор, который может искать десятки миллионов слов или фраз. Общие области применения включают обнаружение и классификацию, или редакцию конфиденциальных данных.
cloud.google.com/dlp/docs/creating-stored-infotypes
Облако Firestore удалось экспорта и импорта услуги: бета
Используйте облако Firestore управляемого экспорта и импорта услуг, чтобы оправиться от случайного удаления данных, а также экспортировать данные для автономной обработки. Импорт и экспорт всех документов сразу, или только определенные коллекции.
cloud.google.com/firestore/docs/manage-data/export-import
Облако Datastore — только для чтения индекса API: GA
REST и КПГРЫ API, теперь доступно в облаке Datastore API, чтобы читать список сводных индексов для данного проекта, а также информации, связанных в процессе сборки в пределах этих показателей.
cloud.google.com/datastore/docs/reference/admin/rest/
Apigee Пограничного клиент самообслуживание управления удостоверениями для порталов разработчиков: бета
API потребительских разработчики теперь могут самостоятельно управлять своими счетами для интегрированных порталов разработчиков Apigee, и поставщики API могут просматривать и управлять этими пользователями, настроить автоматическое или ручное одобрение, а также добавлять пользовательские счета регистрационных полей.
docs-new.apigee.com/whats-new#identity-service
Apigee Край интегрированный разработчик портала — SmartDocs API: бета
SmartDocs ссылки API документация теперь является частью интегрированного портала разработчиков. Благодаря три панельного подходом, левая панель позволяет перемещаться между областями API, центр предоставляет подробную документацию для данной операции, а правая панель позволяет выполнять запросы API непосредственно из документации.
apigee.com/about/blog/api-technology/announcing-enhancements-apigee-integrated-developer-portal
Облако аудита Logging — Журналы событий системы: GA
Облако аудит Logging поддерживает три журнал аудита для каждого проекта и организаций: Администратор Активность, доступ к данным, и теперь системные события. Этот новый тип журнала аудит отслеживает события Compute технического обслуживания системы двигателя, такие как живая миграция.
cloud.google.com/logging/docs/audit/
Облако консоль вне коробки опыта потока и Cloud Shell для мобильных устройств: GA
Теперь вы можете получить доступ к функции Cloud Shell из мобильного приложения Google Cloud Console. Облако Shell является интерактивной средой оболочки для Google Cloud Platform, которая делает его легким для вас, чтобы управлять своими проектами и ресурсами без необходимости установки Cloud SDK.
cloud.google.com/shell/docs/features
Облако Идентичность-Aware Proxy Per-ресурсная политика: бета
Теперь вы можете установить политику Облако ИПД на основе каждого ресурса. Это позволяет иметь несколько приложений с различными политиками доступа в рамках проекта, в том числе Compute Engine, Kubernetes Engine и App Engine приложений.
cloud.google.com/iap/docs/managing-access
GCP основе ролей поддержки: Г.А.
Модель ценообразования на сиденье ролевой поддержки позволяет платить фиксированную плату за пользователь в месяц вместо переменного процента на основе использования платформы. Она также позволяет взаимодействовать с поддержкой непосредственно из вашего Cloud Console вместо центра поддержки Cloud.
cloud.google.com/support/
Google Cloud grants $9M in credits for the operation of the Kubernetes project
Ubernetes, создатель контейнера и созданный здесь в Google, имеет невероятную разработку и принятие с момента его появления в 2014 году. Сегодня 54% компаний из списка Fortune 100 используют Kubernetes в некотором качестве, а разработчики сделали почти миллион комментариев сделанный по проекту в GitHub.
С момента создания Kubernetes мы предоставили облачные ресурсы, которые поддерживают разработку проекта, а именно инфраструктуру тестирования CI / CD, загрузку контейнеров и другие сервисы, такие как DNS, все из которых выполняются на Google Cloud Platform (GCP). И в то время Кубернетес стал одним из самых популярных в мире проектов с открытым исходным кодом. Чтобы представить это в перспективе, только в прошлом месяце, в реестре контейнеров Kubernetes, который мы размещали, было загружено 129 537 369 изображений контейнеров с основными компонентами Kubernetes. Это более 4 миллионов в день — и большая пропускная способность!
В 2015 году мы внесли свой вклад в создание недавно созданного Cloud Native Computing Foundation (CNCF), чтобы помочь в управлении проектами и создать открытое, яркое сообщество участников. CNCF под руководством Linux Foundation помогает воспитывать рост проекта, например, создание сертифицированной программы Kubernetes, которая помогает поддерживать последовательный опыт в распределении Kubernetes и руководить Kubernetes посредством процесса инкубации.
9 миллионов причин, которые мы посвятили Кубернету
В качестве свидетельства зрелости Кубернеса мы рады принять следующий шаг и открываем облачные ресурсы проекта Кубернеса до участников. Мы финансируем этот шаг с помощью гранта GCP на сумму 9 млн. Долл. США для CNCF, разделенного на три года, для покрытия расходов на инфраструктуру. В дополнение к всемирной сети и емкости хранилища, необходимой для обслуживания всех этих загрузок контейнеров, значительная часть этого гранта будет направлена на финансирование тестирования масштабируемости, которое регулярно запускает 150 000 контейнеров по 5000 виртуальных машин. Наша цель — убедиться, что Kubernetes готов к масштабированию, когда это необходимо вашему предприятию.
Мы считаем, что все аспекты зрелого проекта с открытым исходным кодом, включая его инфраструктуру тестирования и выпуска, должны поддерживаться людьми, которые его разрабатывают. В ближайшие месяцы все проектные операции будут переданы на управление членами проекта Kubernetes (включая многих гуглеров), которые будут владеть повседневными оперативными задачами, такими как тестирование и сборка, а также поддержание и эксплуатация хранилище изображений и инфраструктуру загрузки. Мы рады услышать от руководителей проектов на этом фронте:
Развитие Kubernetes на открытом воздухе с сообществом вкладчиков привело к значительно более мощному и многофункциональному проекту. Разделяя оперативные обязанности Кубернеса с участниками проекта, мы с нетерпением ожидаем новых идей и эффективности, которые все вкладчики Кубернетес привносят в деятельность проекта.
Чтобы узнать больше о сегодняшних больших новостях, ознакомьтесь с сообщением CNCF.
Если вы хотите попробовать GCP бесплатно, мы предлагаем различные программы, которые помогут вам начать работу. Для обучения и академических исследований см. Нашу Программу образовательных грантов. Если вы работаете на ранней стадии, ознакомьтесь с нашими пакетами программ для запуска (теперь они открыты для более широкого круга стартапов). И для всех GCP предлагает бесплатный кредит в размере 300 долларов за любой продукт, включая запуск последней версии Kubernetes, выпускаемой по заказу, в версии 1.10 в Google Kubernetes Engine.
cloud.google.com/edu/
cloud.google.com/developers/startups/
cloud.google.com/free/
cloud.google.com/kubernetes-engine
С момента создания Kubernetes мы предоставили облачные ресурсы, которые поддерживают разработку проекта, а именно инфраструктуру тестирования CI / CD, загрузку контейнеров и другие сервисы, такие как DNS, все из которых выполняются на Google Cloud Platform (GCP). И в то время Кубернетес стал одним из самых популярных в мире проектов с открытым исходным кодом. Чтобы представить это в перспективе, только в прошлом месяце, в реестре контейнеров Kubernetes, который мы размещали, было загружено 129 537 369 изображений контейнеров с основными компонентами Kubernetes. Это более 4 миллионов в день — и большая пропускная способность!
В 2015 году мы внесли свой вклад в создание недавно созданного Cloud Native Computing Foundation (CNCF), чтобы помочь в управлении проектами и создать открытое, яркое сообщество участников. CNCF под руководством Linux Foundation помогает воспитывать рост проекта, например, создание сертифицированной программы Kubernetes, которая помогает поддерживать последовательный опыт в распределении Kubernetes и руководить Kubernetes посредством процесса инкубации.
9 миллионов причин, которые мы посвятили Кубернету
В качестве свидетельства зрелости Кубернеса мы рады принять следующий шаг и открываем облачные ресурсы проекта Кубернеса до участников. Мы финансируем этот шаг с помощью гранта GCP на сумму 9 млн. Долл. США для CNCF, разделенного на три года, для покрытия расходов на инфраструктуру. В дополнение к всемирной сети и емкости хранилища, необходимой для обслуживания всех этих загрузок контейнеров, значительная часть этого гранта будет направлена на финансирование тестирования масштабируемости, которое регулярно запускает 150 000 контейнеров по 5000 виртуальных машин. Наша цель — убедиться, что Kubernetes готов к масштабированию, когда это необходимо вашему предприятию.
Мы считаем, что все аспекты зрелого проекта с открытым исходным кодом, включая его инфраструктуру тестирования и выпуска, должны поддерживаться людьми, которые его разрабатывают. В ближайшие месяцы все проектные операции будут переданы на управление членами проекта Kubernetes (включая многих гуглеров), которые будут владеть повседневными оперативными задачами, такими как тестирование и сборка, а также поддержание и эксплуатация хранилище изображений и инфраструктуру загрузки. Мы рады услышать от руководителей проектов на этом фронте:
Значительное финансовое пожертвование Google сообществу Кубернетес поможет обеспечить постоянное развитие инновационных проектов и широкое внедрение проекта. Мы очень рады видеть, что Google Cloud передает управление проектами тестирования и инфраструктуры Kubernetes в руки разработчиков, создавая проект не только с открытым исходным кодом, но и с открытым доступом, открытым сообществом.Дэн Кон, исполнительный директор областного научного вычислительного фонда
Я очень рад видеть, что Google включает ведущих участников проекта в текущее управление тестированием и обслуживанием инфраструктуры Kubernetes, поэтому мы все можем помочь поддержать эту важную важную часть проекта вместе.Тим Хокин, главный инженер-программист, Google Cloud и совместное руководство проектом Kubernetes
Развитие Kubernetes на открытом воздухе с сообществом вкладчиков привело к значительно более мощному и многофункциональному проекту. Разделяя оперативные обязанности Кубернеса с участниками проекта, мы с нетерпением ожидаем новых идей и эффективности, которые все вкладчики Кубернетес привносят в деятельность проекта.
Чтобы узнать больше о сегодняшних больших новостях, ознакомьтесь с сообщением CNCF.
Если вы хотите попробовать GCP бесплатно, мы предлагаем различные программы, которые помогут вам начать работу. Для обучения и академических исследований см. Нашу Программу образовательных грантов. Если вы работаете на ранней стадии, ознакомьтесь с нашими пакетами программ для запуска (теперь они открыты для более широкого круга стартапов). И для всех GCP предлагает бесплатный кредит в размере 300 долларов за любой продукт, включая запуск последней версии Kubernetes, выпускаемой по заказу, в версии 1.10 в Google Kubernetes Engine.
cloud.google.com/edu/
cloud.google.com/developers/startups/
cloud.google.com/free/
cloud.google.com/kubernetes-engine
Ethereum in BigQuery: a Public Dataset for smart contract analytics
Эфириум и другие криптотермии захватили воображение технологов, финансистов и экономистов. Цифровые валюты — это всего лишь одно применение базовой технологии blockchain. Ранее в этом году мы сделали базу данных биткойнов общедоступной для анализа в Google BigQuery. Сегодня мы создаем набор данных Ethereum.
Как и его предшественник Биткойн, вы можете подумать о блочной цепочке Ethereum как непреложный распределенный регистр. Тем не менее, создатель Виталий Бутерин расширил свой набор возможностей, включив в него виртуальную машину, которая может выполнять произвольный код, хранящийся в блочной цепочке, в виде смарт-контрактов.
Что касается архитектуры системы, Ethereum напоминает Bitcoin тем, что он в первую очередь служит для записи неизменяемых транзакций. Оба они по существу являются базами данных OLTP и мало способствуют функциональности OLAP (аналитики). Однако набор данных Ethereum заметно отличается от набора данных биткойнов:
Первичной криптоэкономической единицей Ethereum blockchain является Ether, в то время как единица биткойнов-блокчейнов — биткойн. Однако большая часть переноса стоимости на блок-цепочку Ethereum состоит из так называемых токенов. Токены создаются и управляются интеллектуальными контрактами.
Передача переносов эфира является точной и прямой, напоминающей дебетовые счета и кредиты. Это контрастирует с механизмом передачи значений биткойнов, для которого может быть сложно определить баланс заданного адреса кошелька.
Адресами могут быть не только кошельки, которые содержат балансы, но также могут содержать смарт-контрактный байт-код, который позволяет создавать программные соглашения и автоматически запускать их выполнение. Для создания децентрализованной автономной организации можно использовать совокупность согласованных интеллектуальных контрактов.
Данные Blockchain Ethereum теперь доступны для исследования с помощью BigQuery. Все исторические данные находятся в наборе данных ethereum_blockchain, который обновляется ежедневно. Проект Ethereum ETL на GitHub содержит весь исходный код, используемый для извлечения данных из блок-цепи Ethereum и загрузки его в BigQuery — мы приветствуем больше участников и больше блоков!
Зачем собирать данные о блок-цепочке Ethereum в Google Cloud?
В то время как одноранговое программное обеспечение Ethereum для блокноев имеет API для подмножества часто используемых функций произвольного доступа (например, проверка состояния транзакций, поиск связей между транзакциями транзакций и проверкой балансов кошельков, например), конечные точки API существует для легкого доступа ко всем данным, хранящимся в сети.
Возможно, что более важно, конечные точки API также не существуют для просмотра данных блок-цепи в совокупности. Вот примерная диаграмма, показывающая общую передачу Ether и среднюю транзакционную стоимость, агрегированную по дням:
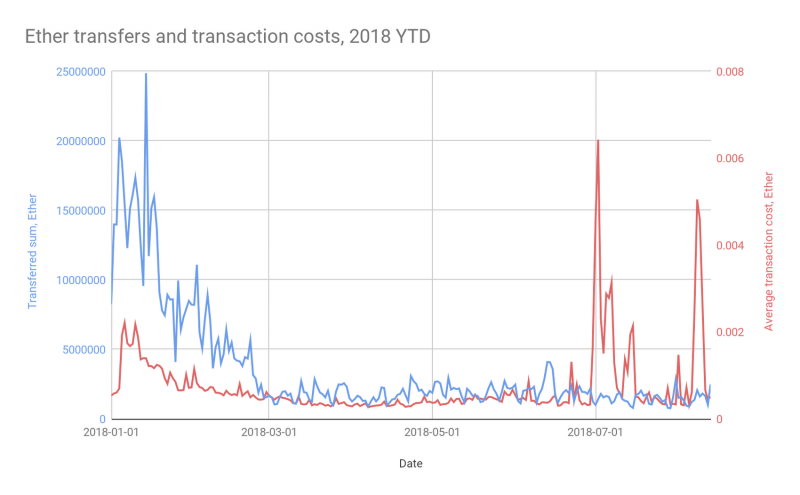
Такая визуализация (и базовый запрос базы данных) полезна для принятия бизнес-решений, таких как определение приоритетов для самой архитектуры Ethereum (является ли система, работающая рядом с пропускной способностью и из-за обновления?), Для корректировки баланса (как быстро кошелек можно перебалансировать?).
BigQuery имеет сильные OLAP-возможности для поддержки такого типа анализа, ad-hoc и вообще, без необходимости дополнительной реализации API.
Соответственно, мы создали программную систему в Google Cloud, которая:
Набор данных блок-схемы Ethereum также доступен в Kaggle. Вы можете запрашивать текущие данные в ядрах, без ограничений в кодировке браузера Kaggle, используя клиентскую библиотеку BigQuery Python. Попробуйте это ядро примера, чтобы поэкспериментировать с вашей собственной копией кода Python.
Анализ 1: популярные журналы событий Smart Contracts
Основным вариантом использования блок-цепи Ethereum до сих пор был обмен цифровыми токенами. Ниже мы показываем запрос таблиц транзакций и контрактов набора данных для поиска наиболее популярных смарт-контрактов, измеряемых по количеству транзакций:
Каковы 10 самых популярных коллекций Ethereum (контракты ERC-721) по количеству транзакций? Посмотреть мой запрос здесь.
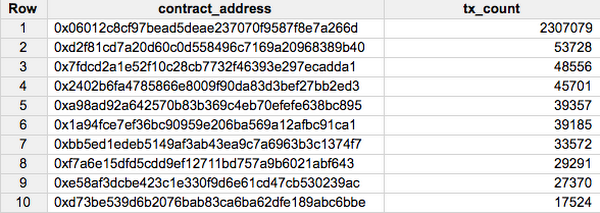
Самый популярный смарт-контракт ERC-721 по количеству транзакций — 0x06012c8cf97bead5deae237070f9587f8e7a266d, главный смарт-контракт для игры CryptoKitties. Мы рассмотрим некоторые атрибуты игры позже в этом документе.
Более внимательно изучив исходный код этого контракта, он регистрирует событие рождения CryptoKitty в блок-цепочке. Вы можете запросить таблицу журналов для экземпляров этого события здесь.
Мы можем визуализировать родословную CryptoKitty, как показано здесь для учетных записей, которые владеют не менее 10 CryptoKitties. Цвет указывает владельца, а размер указывает PageRank (репродуктивная пригодность) каждого CryptoKitty:
Анализ 2: Объемы транзакций и транзакционные сети
Существует много типов токенов, распределенных по блок-цепочке Ethereum, и их модели распределения различаются по типу, а также по времени. Рассматривая транзакционную активность каждого токена, мы можем измерить, которые более популярны в совокупности или в течение определенного периода времени.
Вот запрос для измерения статистической статистики токенов: 10 самых популярных токенов Ethereum (контракты ERC20) по количеству транзакций? Найдите ответ здесь.
В позиции №5 одним из самых популярных токенов является OmiseGO ($ OMG) по адресу 0xd26114cd6ee289accf82350c8d8487fedb8a0c07.
В качестве продолжения, вот запрос для измерения статистики токенов (количество транзакций) по времени, в частности, ежедневное количество переносов токенов OMG и визуализация данных Data Studio этих данных в виде временного ряда с момента создания до 2 августа, 2018 из этого листка Google:
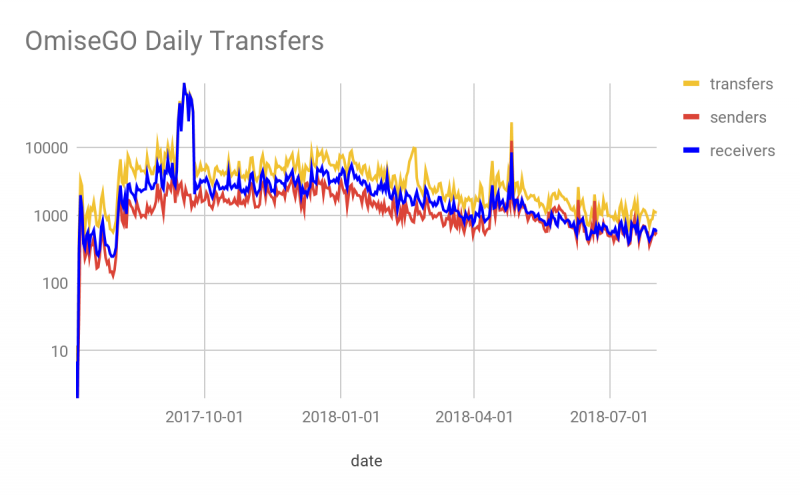
Обратите внимание, что 13 сентября 2017 года произошло значительное увеличение количества приемников $ OMG, но не увеличилось количество отправителей. Это соответствует началу OmiseGO Token Airdrop.
Поскольку данные на очень узком уровне состоят из набора передач между адресами кошельков, мы можем также рассуждать о данных, используя структуру данных ориентированного графа.
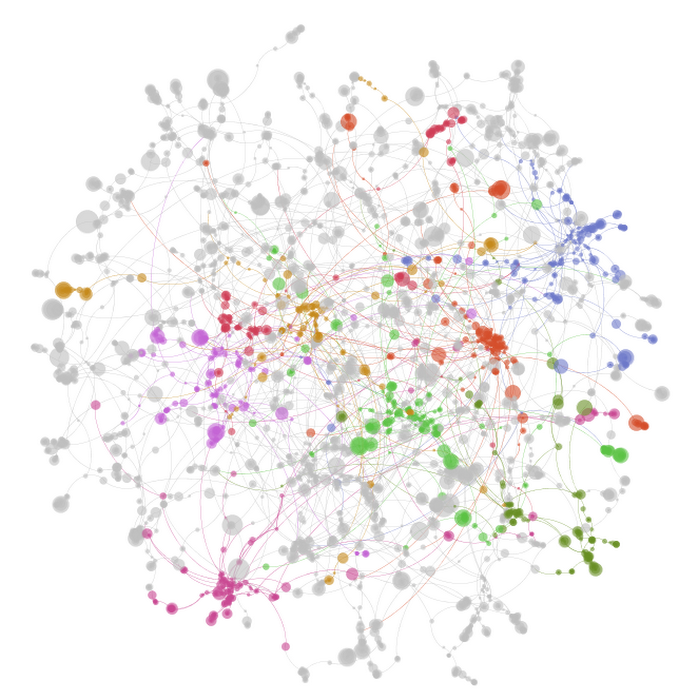
Вот визуализация подмножества одних и тех же данных: это первые 50 000 транзакций, в которых было по крайней мере два торговых партнера. На этом графике узлы (точки) представляют адреса кошельков в блочной цепочке Ethereum, а ребра (линии) представляют собой совокупную передачу токенов между двумя адресами. Длина края приблизительно пропорциональна количеству переносимых токенов, то есть кошельки, которые переносят более суммарные жетоны между ними, находятся ближе друг к другу на диаграмме. Дальнейшие группы адресов, которые передаются часто друг с другом — за исключением членов других групп — объединяются вместе, и мы четко определяем цвета этих групп для ясности. Эта графика была сделана с помощью Gephi, а узлы отмечены цветом по группам, рассчитанным с использованием алгоритма модульности.

Анализ 3: Анализ функциональности Smart Contract
Ранее мы упоминали, что многие из разумных контрактов на блок-цепочку Ethereum заключаются в контрактах ERC-20. Что это значит? ERC-20 просто определяет программный интерфейс, который могут реализовать интеллектуальные контракты. В частности, он состоит из нескольких функций, связанных с переносом токенов, полностью описанных в документе спецификации стандарта Token Standard ERC20.
Существует множество других функций, которые могут быть реализованы с помощью умного контракта. К счастью, исходный код многих смарт-контрактов свободно доступен для использования (с открытым исходным кодом). Мы можем использовать это, чтобы получить некоторые знания о том, что другие контракты делают от имени функции, даже для тех, у которых у нас нет исходного кода, потому что общие имена функций будут иметь общую подпись.
Возвращаясь к CryptoKitties, обсужденному в анализе 3 выше, основным элементом игрового процесса является животноводство, а смешение генов в событии размножения реализовано в смарт-контракте CryptoKitties GeneScience, 0xf97e0a5b616dffc913e72455fde9ea8bbe946a2b. Предположим, мы хотели найти другие игры, которые также реализуют аналогичную механику игры в контракт CryptoKitties GeneScience? Мы можем измерить это, используя JavaScript UDF-реализацию коэффициента подобия Jaccard в этом запросе.
Эти результаты показывают, что несколько более ранних версий контракта GeneScience наиболее похожи на текущую версию смарт-контракта по адресу 0xf97e0a5b616dffc913e72455fde9ea8bbe946a2b. Но есть и некоторые другие (например, CryptoPuppies на 0xb64e6bef349a0d3e8571ac80b5ec522b417faeb6), которые выглядят очень схожими контрактами, измеренными сигнатурами методов.
cloud.google.com/blog/products/data-analytics/ethereum-bigquery-public-dataset-smart-contract-analytics
Как и его предшественник Биткойн, вы можете подумать о блочной цепочке Ethereum как непреложный распределенный регистр. Тем не менее, создатель Виталий Бутерин расширил свой набор возможностей, включив в него виртуальную машину, которая может выполнять произвольный код, хранящийся в блочной цепочке, в виде смарт-контрактов.
Что касается архитектуры системы, Ethereum напоминает Bitcoin тем, что он в первую очередь служит для записи неизменяемых транзакций. Оба они по существу являются базами данных OLTP и мало способствуют функциональности OLAP (аналитики). Однако набор данных Ethereum заметно отличается от набора данных биткойнов:
Первичной криптоэкономической единицей Ethereum blockchain является Ether, в то время как единица биткойнов-блокчейнов — биткойн. Однако большая часть переноса стоимости на блок-цепочку Ethereum состоит из так называемых токенов. Токены создаются и управляются интеллектуальными контрактами.
Передача переносов эфира является точной и прямой, напоминающей дебетовые счета и кредиты. Это контрастирует с механизмом передачи значений биткойнов, для которого может быть сложно определить баланс заданного адреса кошелька.
Адресами могут быть не только кошельки, которые содержат балансы, но также могут содержать смарт-контрактный байт-код, который позволяет создавать программные соглашения и автоматически запускать их выполнение. Для создания децентрализованной автономной организации можно использовать совокупность согласованных интеллектуальных контрактов.
Данные Blockchain Ethereum теперь доступны для исследования с помощью BigQuery. Все исторические данные находятся в наборе данных ethereum_blockchain, который обновляется ежедневно. Проект Ethereum ETL на GitHub содержит весь исходный код, используемый для извлечения данных из блок-цепи Ethereum и загрузки его в BigQuery — мы приветствуем больше участников и больше блоков!
Зачем собирать данные о блок-цепочке Ethereum в Google Cloud?
В то время как одноранговое программное обеспечение Ethereum для блокноев имеет API для подмножества часто используемых функций произвольного доступа (например, проверка состояния транзакций, поиск связей между транзакциями транзакций и проверкой балансов кошельков, например), конечные точки API существует для легкого доступа ко всем данным, хранящимся в сети.
Возможно, что более важно, конечные точки API также не существуют для просмотра данных блок-цепи в совокупности. Вот примерная диаграмма, показывающая общую передачу Ether и среднюю транзакционную стоимость, агрегированную по дням:
Такая визуализация (и базовый запрос базы данных) полезна для принятия бизнес-решений, таких как определение приоритетов для самой архитектуры Ethereum (является ли система, работающая рядом с пропускной способностью и из-за обновления?), Для корректировки баланса (как быстро кошелек можно перебалансировать?).
BigQuery имеет сильные OLAP-возможности для поддержки такого типа анализа, ad-hoc и вообще, без необходимости дополнительной реализации API.
Соответственно, мы создали программную систему в Google Cloud, которая:
- Синхронизирует блок-цепочку Ethereum с компьютерами, использующими Parity в облаке Google.
- Выполняет ежедневное извлечение данных из блокберической таблицы Ethereum, включая результаты транзакций смарт-контрактов, таких как передача токенов.
- Де-нормализует и сохраняет данные с разбивкой по дате в BigQuery для легкого и экономичного исследования.
Набор данных блок-схемы Ethereum также доступен в Kaggle. Вы можете запрашивать текущие данные в ядрах, без ограничений в кодировке браузера Kaggle, используя клиентскую библиотеку BigQuery Python. Попробуйте это ядро примера, чтобы поэкспериментировать с вашей собственной копией кода Python.
Анализ 1: популярные журналы событий Smart Contracts
Основным вариантом использования блок-цепи Ethereum до сих пор был обмен цифровыми токенами. Ниже мы показываем запрос таблиц транзакций и контрактов набора данных для поиска наиболее популярных смарт-контрактов, измеряемых по количеству транзакций:
Каковы 10 самых популярных коллекций Ethereum (контракты ERC-721) по количеству транзакций? Посмотреть мой запрос здесь.
Самый популярный смарт-контракт ERC-721 по количеству транзакций — 0x06012c8cf97bead5deae237070f9587f8e7a266d, главный смарт-контракт для игры CryptoKitties. Мы рассмотрим некоторые атрибуты игры позже в этом документе.
Более внимательно изучив исходный код этого контракта, он регистрирует событие рождения CryptoKitty в блок-цепочке. Вы можете запросить таблицу журналов для экземпляров этого события здесь.
Мы можем визуализировать родословную CryptoKitty, как показано здесь для учетных записей, которые владеют не менее 10 CryptoKitties. Цвет указывает владельца, а размер указывает PageRank (репродуктивная пригодность) каждого CryptoKitty:
Анализ 2: Объемы транзакций и транзакционные сети
Существует много типов токенов, распределенных по блок-цепочке Ethereum, и их модели распределения различаются по типу, а также по времени. Рассматривая транзакционную активность каждого токена, мы можем измерить, которые более популярны в совокупности или в течение определенного периода времени.
Вот запрос для измерения статистической статистики токенов: 10 самых популярных токенов Ethereum (контракты ERC20) по количеству транзакций? Найдите ответ здесь.
В позиции №5 одним из самых популярных токенов является OmiseGO ($ OMG) по адресу 0xd26114cd6ee289accf82350c8d8487fedb8a0c07.
В качестве продолжения, вот запрос для измерения статистики токенов (количество транзакций) по времени, в частности, ежедневное количество переносов токенов OMG и визуализация данных Data Studio этих данных в виде временного ряда с момента создания до 2 августа, 2018 из этого листка Google:
Обратите внимание, что 13 сентября 2017 года произошло значительное увеличение количества приемников $ OMG, но не увеличилось количество отправителей. Это соответствует началу OmiseGO Token Airdrop.
Поскольку данные на очень узком уровне состоят из набора передач между адресами кошельков, мы можем также рассуждать о данных, используя структуру данных ориентированного графа.
Вот визуализация подмножества одних и тех же данных: это первые 50 000 транзакций, в которых было по крайней мере два торговых партнера. На этом графике узлы (точки) представляют адреса кошельков в блочной цепочке Ethereum, а ребра (линии) представляют собой совокупную передачу токенов между двумя адресами. Длина края приблизительно пропорциональна количеству переносимых токенов, то есть кошельки, которые переносят более суммарные жетоны между ними, находятся ближе друг к другу на диаграмме. Дальнейшие группы адресов, которые передаются часто друг с другом — за исключением членов других групп — объединяются вместе, и мы четко определяем цвета этих групп для ясности. Эта графика была сделана с помощью Gephi, а узлы отмечены цветом по группам, рассчитанным с использованием алгоритма модульности.
Анализ 3: Анализ функциональности Smart Contract
Ранее мы упоминали, что многие из разумных контрактов на блок-цепочку Ethereum заключаются в контрактах ERC-20. Что это значит? ERC-20 просто определяет программный интерфейс, который могут реализовать интеллектуальные контракты. В частности, он состоит из нескольких функций, связанных с переносом токенов, полностью описанных в документе спецификации стандарта Token Standard ERC20.
Существует множество других функций, которые могут быть реализованы с помощью умного контракта. К счастью, исходный код многих смарт-контрактов свободно доступен для использования (с открытым исходным кодом). Мы можем использовать это, чтобы получить некоторые знания о том, что другие контракты делают от имени функции, даже для тех, у которых у нас нет исходного кода, потому что общие имена функций будут иметь общую подпись.
Возвращаясь к CryptoKitties, обсужденному в анализе 3 выше, основным элементом игрового процесса является животноводство, а смешение генов в событии размножения реализовано в смарт-контракте CryptoKitties GeneScience, 0xf97e0a5b616dffc913e72455fde9ea8bbe946a2b. Предположим, мы хотели найти другие игры, которые также реализуют аналогичную механику игры в контракт CryptoKitties GeneScience? Мы можем измерить это, используя JavaScript UDF-реализацию коэффициента подобия Jaccard в этом запросе.
Эти результаты показывают, что несколько более ранних версий контракта GeneScience наиболее похожи на текущую версию смарт-контракта по адресу 0xf97e0a5b616dffc913e72455fde9ea8bbe946a2b. Но есть и некоторые другие (например, CryptoPuppies на 0xb64e6bef349a0d3e8571ac80b5ec522b417faeb6), которые выглядят очень схожими контрактами, измеренными сигнатурами методов.
cloud.google.com/blog/products/data-analytics/ethereum-bigquery-public-dataset-smart-contract-analytics
Google Cloud Newsletter, August 2018 | Watch all of Google Cloud Next ’18
cloud.withgoogle.com/next18/sf/nextonair
cloudplatform.googleblog.com/2018/07/cloud-services-platform-bringing-the-best-of-the-cloud-to-you.html

cloudplatform.googleblog.com/2018/07/istio-reaches-1-0-ready-for-prod.html

cloudplatform.googleblog.com/2018/05/Google-named-a-Leader-in-2018-Gartner-Infrastructure-as-a-Service-Magic-Quadrant.html
НОВОСТИ ПЛАТФОРМЫ
G Suite и Chrome для преобразования работы.
Клиенты обсуждают, как Chrome Enterprise и G Suite вместе помогли преобразовать свою технологическую инфраструктуру и реализовать более умное и безопасное сотрудничество в облачном мире.
www.youtube.com/watch?v=0H0Hej6zUgI
Принесите вам лучшее от сервера без сервера.
Получите более быструю сборку и большую гибкость при использовании одноэтапного развертывания безбумажных приложений Kubernetes Engine, новых версий приложений App Engine и рутинной версии с открытым исходным кодом.
cloudplatform.googleblog.com/2018/07/bringing-the-best-of-serverless-to-you.html
Cloud AutoML предоставляет разработчикам расширенный ИИ.
Благодаря новым облачным приложениям AutoML Vision, Natural Language и Translation теперь стало еще проще обучать высококачественные модели пользовательских моделей машин с минимальной экспертизой ML.
cloud.google.com/blog/products/ai-machine-learning/closer-look-our-newest-google-cloud-ai-capabilities-developers
BigQuery становится умнее с BigQuery ML.
Клиенты BigQuery, такие как 20th Century Fox, создают модели за считанные секунды, не перемещая данные, используя простой SQL. С запуском BigQuery ML — и новыми функциями, типами данных и интеграцией G Suite — BigQuery переходит на следующий уровень.
cloud.google.com/blog/products/gcp/bridging-the-gap-between-data-and-insights
Cloud Firestore — это эволюция Cloud Datastore.
Облачные приложения Cloud Firestore обеспечивают гибкие структуры данных, мощные запросы для упрощенного кода приложения, автомасштабирования и онлайн-синхронизации. Благодаря новым функциям и регионам он теперь доступен на консоли Google Cloud Platform.
cloud.google.com/blog/products/gcp/expanding-the-cloud-firestore-beta-to-more-users
cloudplatform.googleblog.com/2018/07/cloud-services-platform-bringing-the-best-of-the-cloud-to-you.html
cloudplatform.googleblog.com/2018/07/istio-reaches-1-0-ready-for-prod.html
cloudplatform.googleblog.com/2018/05/Google-named-a-Leader-in-2018-Gartner-Infrastructure-as-a-Service-Magic-Quadrant.html
НОВОСТИ ПЛАТФОРМЫ
G Suite и Chrome для преобразования работы.
Клиенты обсуждают, как Chrome Enterprise и G Suite вместе помогли преобразовать свою технологическую инфраструктуру и реализовать более умное и безопасное сотрудничество в облачном мире.
www.youtube.com/watch?v=0H0Hej6zUgI
Принесите вам лучшее от сервера без сервера.
Получите более быструю сборку и большую гибкость при использовании одноэтапного развертывания безбумажных приложений Kubernetes Engine, новых версий приложений App Engine и рутинной версии с открытым исходным кодом.
cloudplatform.googleblog.com/2018/07/bringing-the-best-of-serverless-to-you.html
Cloud AutoML предоставляет разработчикам расширенный ИИ.
Благодаря новым облачным приложениям AutoML Vision, Natural Language и Translation теперь стало еще проще обучать высококачественные модели пользовательских моделей машин с минимальной экспертизой ML.
cloud.google.com/blog/products/ai-machine-learning/closer-look-our-newest-google-cloud-ai-capabilities-developers
BigQuery становится умнее с BigQuery ML.
Клиенты BigQuery, такие как 20th Century Fox, создают модели за считанные секунды, не перемещая данные, используя простой SQL. С запуском BigQuery ML — и новыми функциями, типами данных и интеграцией G Suite — BigQuery переходит на следующий уровень.
cloud.google.com/blog/products/gcp/bridging-the-gap-between-data-and-insights
Cloud Firestore — это эволюция Cloud Datastore.
Облачные приложения Cloud Firestore обеспечивают гибкие структуры данных, мощные запросы для упрощенного кода приложения, автомасштабирования и онлайн-синхронизации. Благодаря новым функциям и регионам он теперь доступен на консоли Google Cloud Platform.
cloud.google.com/blog/products/gcp/expanding-the-cloud-firestore-beta-to-more-users
Introducing Cloud HSM beta for hardware crypto key security
Защита данных — это главное соображение при запуске корпоративных рабочих нагрузок в облаке. В Google Cloud Platform (GCP) мы предлагаем множество вариантов шифрования ваших данных, включая наше шифрование по умолчанию для данных (мы гордимся тем, что являемся единственным облачным провайдером, который шифрует все данные клиента в состоянии покоя), а также наше облако Служба управления ключами (KMS), которая позволяет явно шифровать блоки данных с помощью ключа под вашим контролем. Но мы слышали от многих из вас, что вы хотели бы еще больше вариантов, которые помогут вам защитить ваши наиболее чувствительные информационные ресурсы и выполнить требования соответствия.
Вот почему мы рады объявить о доступности бета-версии Cloud HSM, управляемой облачной службы безопасности (HSM). Cloud HSM позволяет вам размещать ключи шифрования и выполнять криптографические операции в сертифицированных FIPS 140-2 HSM (см. Ниже). Благодаря этому полностью управляемому сервису вы можете защитить свои наиболее чувствительные рабочие нагрузки, не беспокоясь об операционных издержках управления кластером HSM.

Cloud HSM предоставляет бесплатную аппаратную криптографию и управление ключами для развертывания GCP
Из-за эксплуатационных издержек мы подразумеваем такие задачи, как управление кластерами, масштабирование и обновление. Вы контролируете использование службы Cloud HSM с помощью обычных API облачных KMS, а служба Cloud HSM автоматически позаботится об исправлении, масштабировании и кластеризации без простоя. Вы можете увидеть интерфейс здесь:
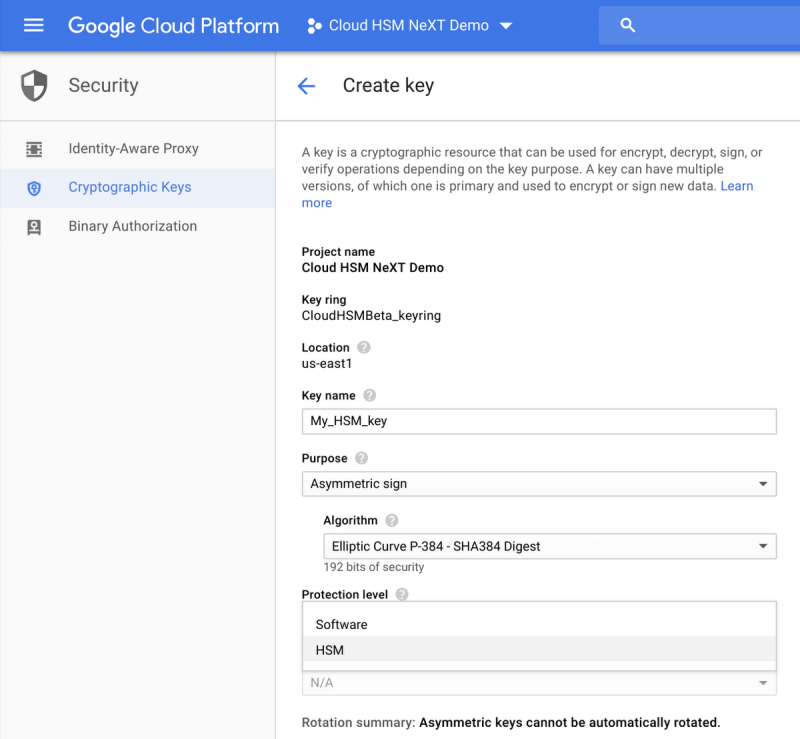
И поскольку служба Cloud HSM тесно интегрирована с Cloud KMS, теперь вы можете защитить свои данные в службах с поддержкой шифрования с поддержкой клиентов, таких как BigQuery, Google Compute Engine, Google Cloud Storage и DataProc, с защищенным аппаратным ключом.
Для тех из вас, кто соблюдает требования соответствия, Cloud HSM может помочь вам выполнить регулирующие мандаты, требующие выполнения ключей и криптографических операций в рамках аппаратной среды. В дополнение к использованию сертифицированных FIPS 140-2 устройств Cloud HSM позволит вам достоверно подтвердить, что ваши криптографические ключи были созданы на границе аппаратного обеспечения, как показано ниже:
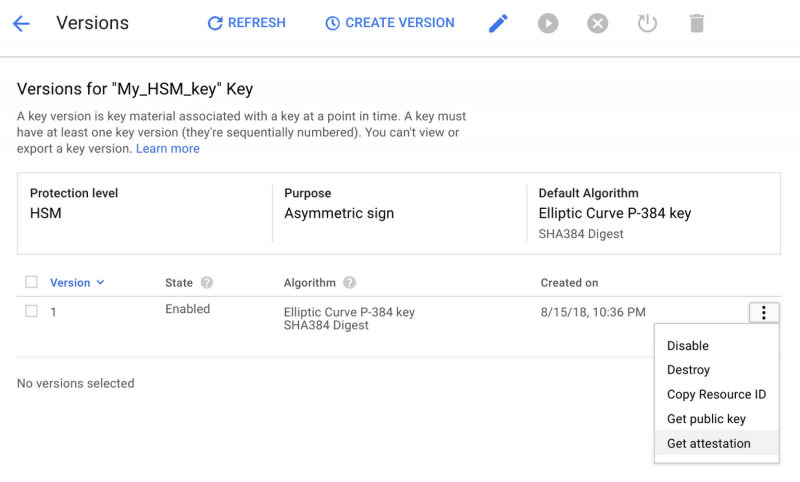
С помощью Cloud HSM можно легко начать работу с консоли Google Cloud Platform. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.
Внедрение асимметричной поддержки ключей
В дополнение к Cloud HSM мы рады объявить о выпуске бета-версии поддержки асимметричного ключа для Cloud KMS и Cloud HSM. В дополнение к симметричному шифрованию ключей с использованием ключей AES-256 теперь вы можете создавать различные типы асимметричных ключей для операций дешифрования или подписания, а это означает, что теперь вы можете хранить свои ключи, используемые для PKI или подписи кода в управляемом хранилище ключей Google Cloud. В частности, для операций подписи будут доступны ключи RSA 2048, RSA 3072, RSA 4096, EC P256 и EC P384, в то время как ключи RSA 2048, RSA 3072 и RSA 4096 также смогут расшифровывать блоки данных. Ознакомьтесь с документацией для получения дополнительной информации и ознакомьтесь с интерфейсом здесь:
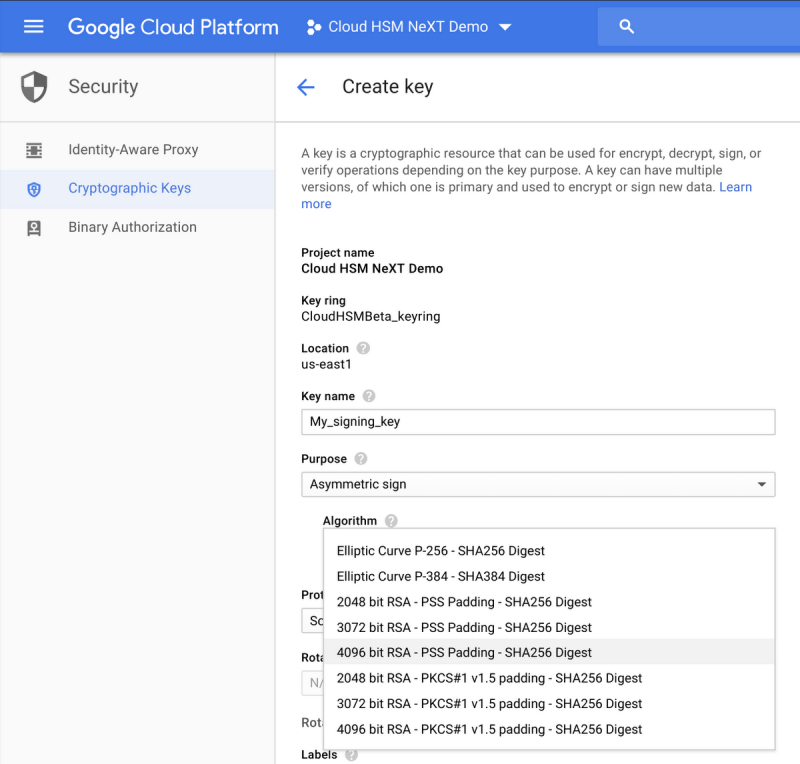
Дальнейшая интеграция Hashicorp Vault с Cloud KMS
Наконец, мы рады поделиться замечательными новостями о поддержке Hashicorp Vault Cloud KMS. Теперь вы можете использовать Google Cloud KMS или Cloud HSM для шифрования токенов HashiCorp Vault в покое с помощью GK Cloud KMS Vault Token Helper. Помощник маркера хранилища по умолчанию хранит токены в виде открытого текста на диске. С помощью этой новой функции помощник токена GCP шифрует эти маркеры с помощью клавиш Cloud KMS или Cloud HSM и сохраняет зашифрованные значения на диске. Помощник токена Vault автоматически выполняет все необходимые вызовы API для шифрования / дешифрования данных, поэтому пользовательский интерфейс не изменяется.
Сегодня вы можете начать с Cloud HSM. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.
Вот почему мы рады объявить о доступности бета-версии Cloud HSM, управляемой облачной службы безопасности (HSM). Cloud HSM позволяет вам размещать ключи шифрования и выполнять криптографические операции в сертифицированных FIPS 140-2 HSM (см. Ниже). Благодаря этому полностью управляемому сервису вы можете защитить свои наиболее чувствительные рабочие нагрузки, не беспокоясь об операционных издержках управления кластером HSM.
Cloud HSM предоставляет бесплатную аппаратную криптографию и управление ключами для развертывания GCP
Из-за эксплуатационных издержек мы подразумеваем такие задачи, как управление кластерами, масштабирование и обновление. Вы контролируете использование службы Cloud HSM с помощью обычных API облачных KMS, а служба Cloud HSM автоматически позаботится об исправлении, масштабировании и кластеризации без простоя. Вы можете увидеть интерфейс здесь:
И поскольку служба Cloud HSM тесно интегрирована с Cloud KMS, теперь вы можете защитить свои данные в службах с поддержкой шифрования с поддержкой клиентов, таких как BigQuery, Google Compute Engine, Google Cloud Storage и DataProc, с защищенным аппаратным ключом.
Для тех из вас, кто соблюдает требования соответствия, Cloud HSM может помочь вам выполнить регулирующие мандаты, требующие выполнения ключей и криптографических операций в рамках аппаратной среды. В дополнение к использованию сертифицированных FIPS 140-2 устройств Cloud HSM позволит вам достоверно подтвердить, что ваши криптографические ключи были созданы на границе аппаратного обеспечения, как показано ниже:
С помощью Cloud HSM можно легко начать работу с консоли Google Cloud Platform. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.
Внедрение асимметричной поддержки ключей
В дополнение к Cloud HSM мы рады объявить о выпуске бета-версии поддержки асимметричного ключа для Cloud KMS и Cloud HSM. В дополнение к симметричному шифрованию ключей с использованием ключей AES-256 теперь вы можете создавать различные типы асимметричных ключей для операций дешифрования или подписания, а это означает, что теперь вы можете хранить свои ключи, используемые для PKI или подписи кода в управляемом хранилище ключей Google Cloud. В частности, для операций подписи будут доступны ключи RSA 2048, RSA 3072, RSA 4096, EC P256 и EC P384, в то время как ключи RSA 2048, RSA 3072 и RSA 4096 также смогут расшифровывать блоки данных. Ознакомьтесь с документацией для получения дополнительной информации и ознакомьтесь с интерфейсом здесь:
Дальнейшая интеграция Hashicorp Vault с Cloud KMS
Наконец, мы рады поделиться замечательными новостями о поддержке Hashicorp Vault Cloud KMS. Теперь вы можете использовать Google Cloud KMS или Cloud HSM для шифрования токенов HashiCorp Vault в покое с помощью GK Cloud KMS Vault Token Helper. Помощник маркера хранилища по умолчанию хранит токены в виде открытого текста на диске. С помощью этой новой функции помощник токена GCP шифрует эти маркеры с помощью клавиш Cloud KMS или Cloud HSM и сохраняет зашифрованные значения на диске. Помощник токена Vault автоматически выполняет все необходимые вызовы API для шифрования / дешифрования данных, поэтому пользовательский интерфейс не изменяется.
Сегодня вы можете начать с Cloud HSM. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.
Product updates | August 20, 2018

COMPUTE
Knative: GA
Knative является Kubernetes на основе платформы для создания, развертывания и управления рабочими нагрузками бессерверную. Он предлагает набор компонентов промежуточного программного обеспечения для построения источника ориентированных и контейнеров на основе приложений, которые могут работать в любом месте.
cloud.google.com/knative/
AI & MACHINE LEARNING
AutoML Vision: beta
AutoML Зрение позволяет тренировать модели машинного обучения для классификации изображений в соответствии с вашими определенными метками. Железнодорожные модели из помеченных изображений, оценить их эффективность, а затем зарегистрировать их для обслуживания через API AutoML
cloud.google.com/vision/automl/docs/
DATA ANALYTICS
BigQuery ML: beta
BigQuery ML позволяет пользователям без глубокого знания машинного обучения, чтобы быстро создавать и выполнять модели ML с помощью стандартных запросов SQL и без перемещения данных.
cloud.google.com/bigquery/docs/bigqueryml-intro
DEVELOPER TOOLS
Cloud Build: GA
Облако сборки (ранее Container Builder) позволяет быстро создавать программное обеспечение с помощью любого языка. Пользователи могут определять собственные рабочие процессы для создания, тестирования и развертывания в нескольких средах, в том числе экземпляров виртуальных машин, бессерверную, Kubernetes и Firebase.
cloud.google.com/cloud-build/
Compute Engine n1-megamem-96 Тип машины: GA
N1-megamem-96, память оптимизированным, предопределенный тип машины с 96 виртуальных ЦП и 1,4 ТБ оперативной памяти, теперь доступна для баз данных в оперативной памяти и в памяти аналитических задач, как SAP HANA рабочих нагрузок, анализ геномики и SQL услуги анализа.
cloud.google.com/compute/docs/machine-types
Экранированный VM: бета
Благодаря использовании безопасной загрузки, Измеренная загрузки и контроля целостности, экранированная VM предлагает проверяемую целостность ваших экземпляров Compute Engine VM, чтобы гарантировать, что они не были скомпрометированы или загрузочными уровне ядра вредоносных программ или руткитами.
cloud.google.com/security/shielded-cloud/shielded-vm
Поддержка Cloud ТПУ в Kubernetes Двигатель: бета
TPUs аппаратные ускорители для машинного обучения, которые повышают скорость и снизить стоимость обучения и работы передовых моделей машинного обучения. Эта версия обеспечивает поддержку облачных TPU узлов в Kubernetes Engine.
cloud.google.com/kubernetes-engine/docs/concepts/tpus
Node.js поддержки 8 и Python 3 на облачные функции: бета
Облако функции была добавлена поддержка для Node.js 8 и Python 3 автономной работы. Node.js 8 | Python 3
cloud.google.com/functions/docs/concepts/nodejs-8-runtime
cloud.google.com/functions/docs/concepts/python-runtime
Региональный управляемый экземпляр выбор группы зоны: GA
Выбор зоны позволяет выбрать определенные зоны вместо конфигурации три-зоны по умолчанию. Это может быть полезно, если вам нужны продукты, которые доступны только в определенных зонах — например, графических процессоров и упорных дисков — или вы хотите, чтобы выбрать зоны для экземпляров виртуальных машин.
cloud.google.com/compute/docs/instance-groups/distributing-instances-with-regional-instance-groups
Организация адаптационный: бета
Мастер установки Организация предоставляет простые инструменты, которые помогут вам взять под контроль и управление ресурсами централизованно. Вы можете делегировать административные и критические роли Облако идентификации и управления доступом, а также импортировать существующие проекты и платежные счета в вашей организации.
cloud.google.com/resource-manager/docs/organization-setup
Репликация Cloud Bigtable: GA
Региональная репликация Cloud Bigtable повышает доступность и долговечность ваших данных путем непрерывной репликации его между двумя кластерами в том же регионе. Она также позволяет изолировать рабочие нагрузки за счет маршрутизации различных типов запросов к различным кластерам.
cloud.google.com/bigtable/docs/replication-overview
Листинг доступных подсетей в общей VPC: GA
Этот запуск позволяет Service Admins Project в списке подсетей, на которых они имеют разрешения на создание экземпляров виртуальных машин в общей VPC.
cloud.google.com/vpc/docs/provisioning-shared-vpc
BigQuery языка определения данных: GA
Операторы определения данных языка в BigQuery позволяют создавать, изменять и удалять таблицы и представление, используя стандартный синтаксис SQL запросов.
cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language
Расширения Apigee Пограничной поддержка: бета
Apigee Край теперь поддерживает расширения, которые позволяют API прокси для безопасного соединения с облачными сервисами, включая услуги Google Cloud Platform, как Cloud Storage, предотвращение потери данных Cloud API, и так далее.
docs.apigee.com/api-platform/extensions/extensions-overview
Управление Apigee API для Istio: GA
Теперь вы можете выставить microservices, как API, и легко делиться ими с разработчиками внутри и за пределами организации, благодаря интеграции управления API Apigee для Istio.
apigee.com/about/blog/api-technology/introducing-apigee-api-management-istio
Облако ML Опора двигателя для scikit учиться и XGBoost: бета
Облачный Machine Learning Engine добавлена поддержка для подготовки и обслуживания scikit учиться и модель XGBoost. Теперь вы можете нажать, чтобы развернуть модель, которую вы обученного на местах, в помещениях или на других облачных сервисов, а также генерировать предсказания, используя управляемые ресурсы на GCP.
cloud.google.com/ml-engine/docs/scikit/getting-started-training
AutoML Перевод: бета
AutoML Translation позволяет создавать пользовательские модели перевода, возвращающие результаты запроса перевода специфичные для вашего домена. Особенности включают в себя поддержку 18 языков, в API для обучения онлайн пользовательских моделей, а также новый пользовательский интерфейс.
cloud.google.com/translate/automl/docs/
Облако Talent Решение: GA
Облако Talent Решение позволяет хранить, искать и управлять данными работы, компании, и кандидат в профиле. Он использует машинное обучение и стандартные методы на основе ключевых слов, чтобы обнаружить и вывести совпадения из данных — такие, как навыки, старшинство и промышленность — для получения лучших результатов.
cloud.google.com/solutions/talent-solution/
Облако Billing добавляет гонконгских долларов: GA
гонконгские доллары, которые были добавлены в наш список местных валют, доступных для выставления счетов и платежей. Google преобразует цены в применимой местной валюте по ставкам конверсии, опубликованных ведущими финансовыми институтами.
cloud.google.com/billing/docs/resources/currency
Проект Go Cloud
С Go Cloud вы можете писать простые, надежные и эффективные мульти-облако и гибридные облачные приложения и библиотеки, а также выбрать между облаком, локальными или пользовательскими поставщиками. AWS и G поддерживаются из коробки и другие платформы будут добавлены.
github.com/google/go-cloud
Новый пользовательский интерфейс для облачных репозиториев: бета
Облако Источник Хранилища, полнофункциональный, частные Git репозиториев, размещенные на GCP, теперь есть новый интерфейс, который включает в себя персональную целевую страницу и надежный поиск кода. страница продукта
source.cloud.google.com/onboarding/welcome