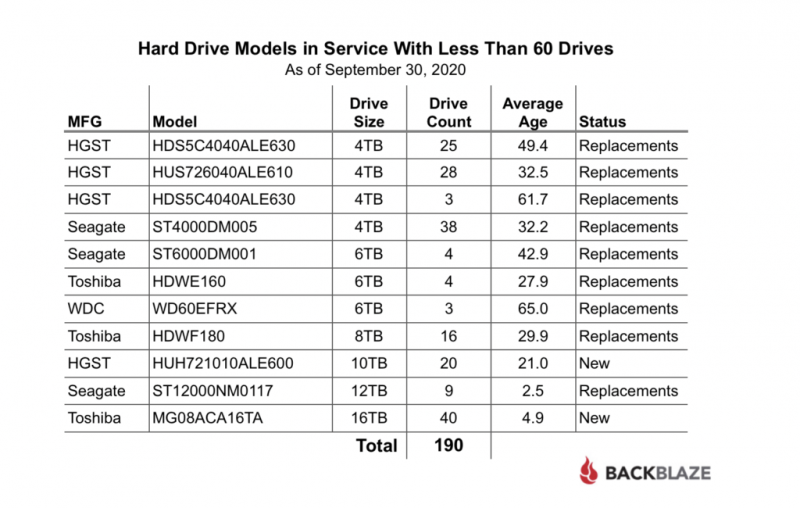
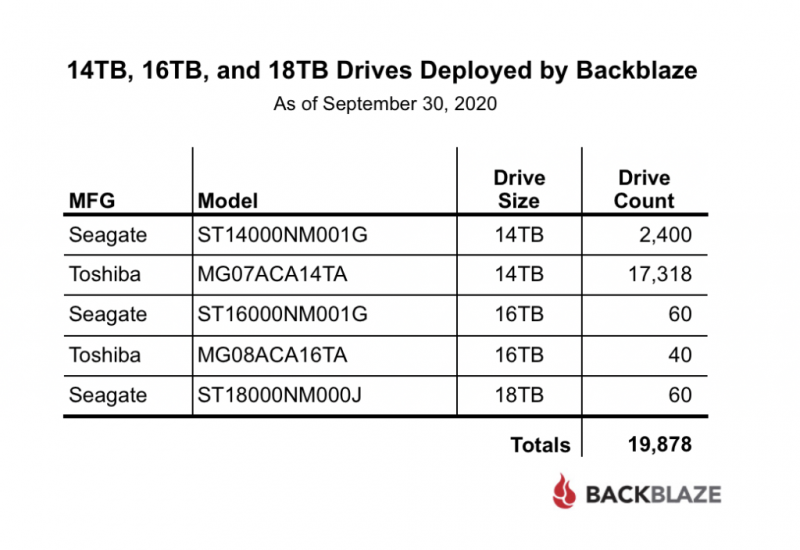
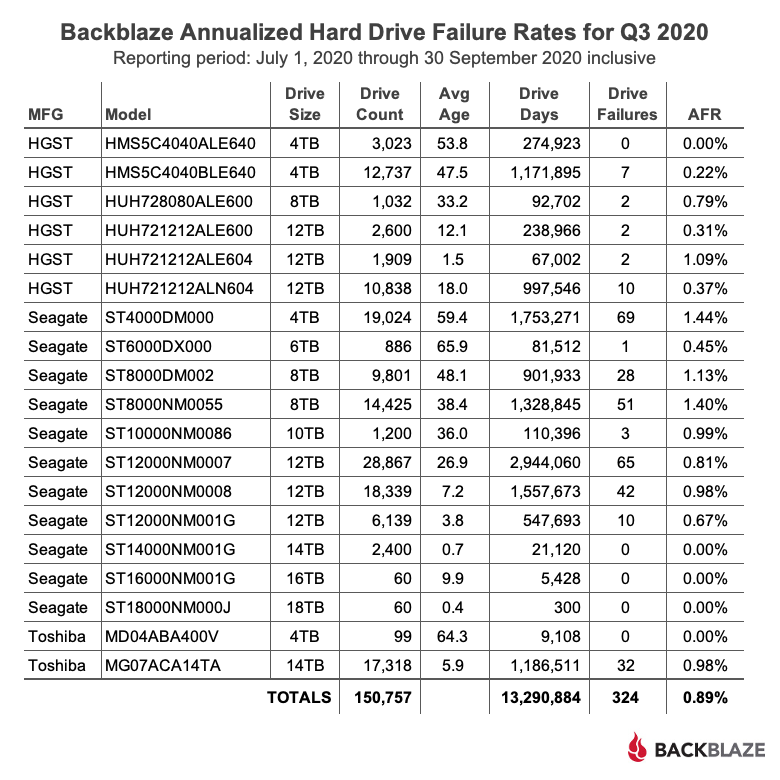
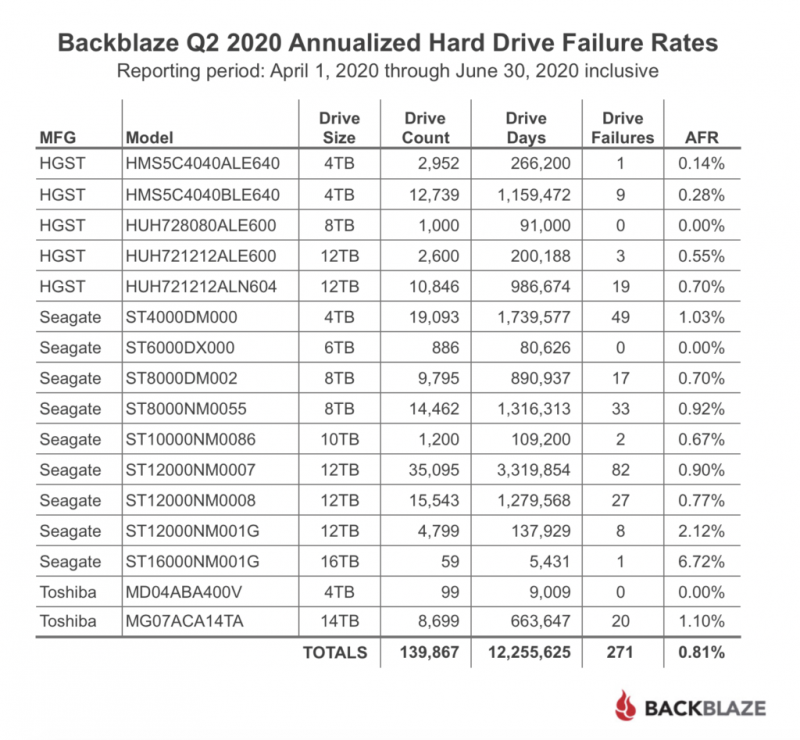
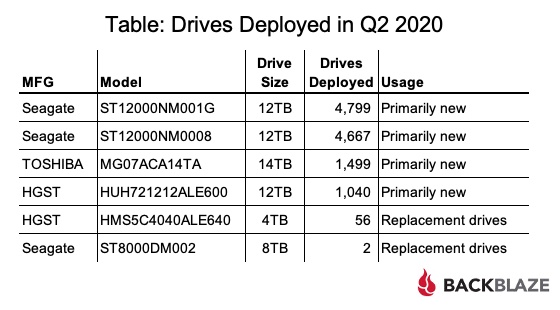
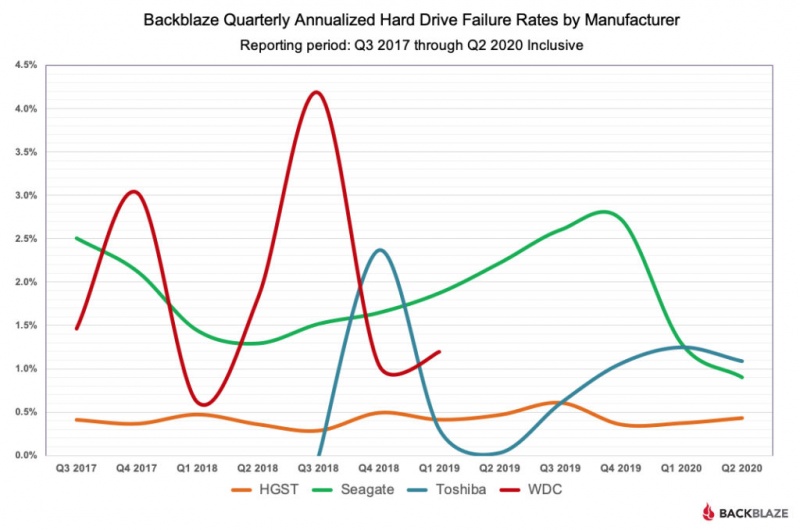
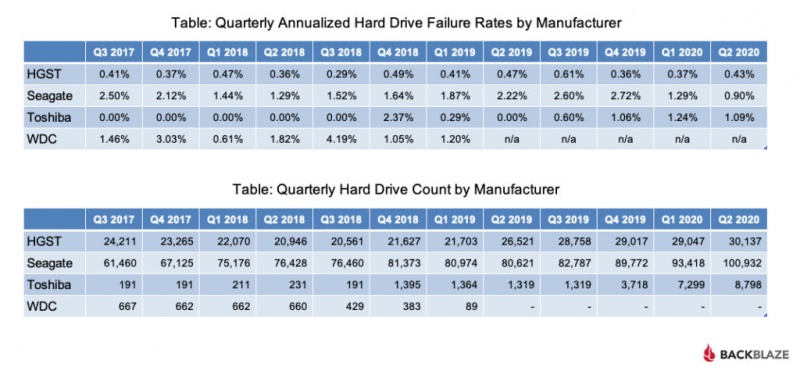
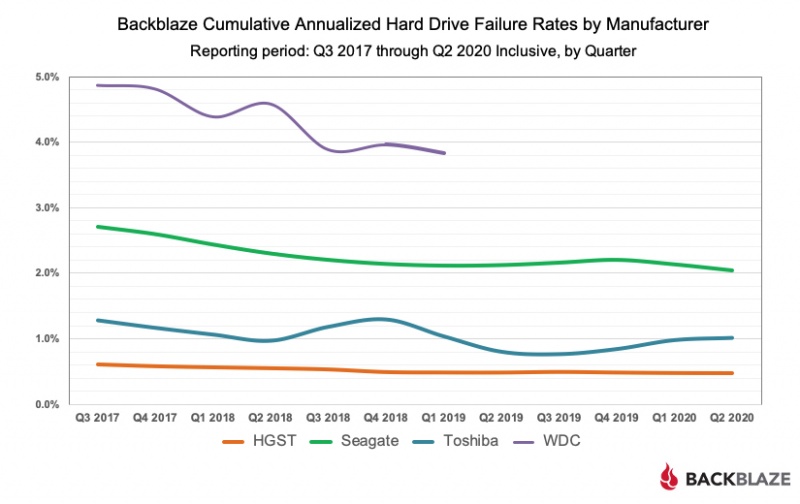
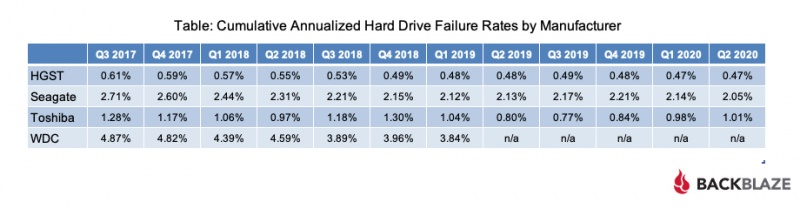
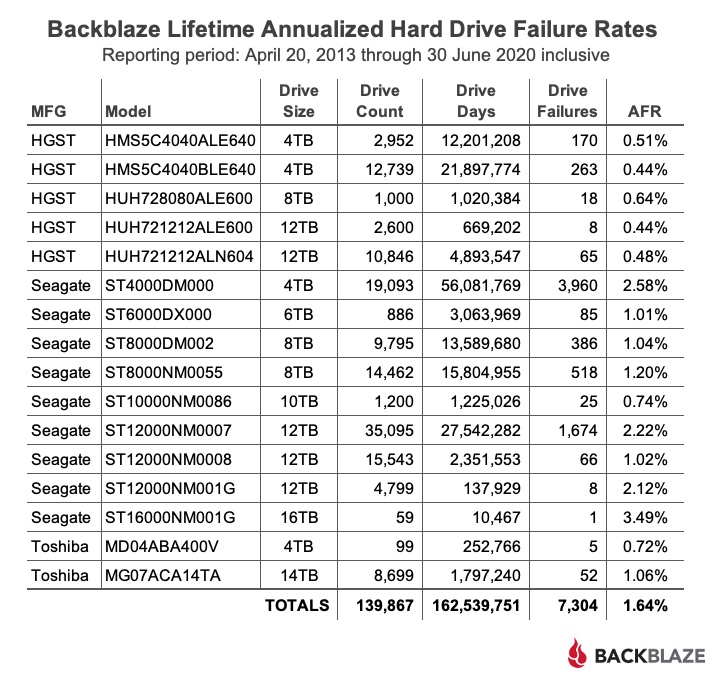
По мере роста вашего бизнеса растет и количество данных, которые ему необходимо хранить и которыми нужно управлять. Хранение этих данных на незакрепленных жестких дисках и отдельных рабочих станциях больше не приведет к их сокращению: вашей команде нужен постоянный доступ к данным, защита от потери и емкость для будущего роста. Самый простой способ быстро и легко предоставить все три — это сетевое хранилище (NAS).
Возможно, вы уже рассматривали возможность покупки NAS-устройства, или вы приобрели то, из которого вы уже выросли, или это может быть ваш первый раз, когда вы рассматриваете свои варианты. Независимо от того, с чего вы начинаете, количество вариантов и функций, предлагаемых сегодня системами NAS, огромно, особенно когда вы пытаетесь купить что-то, что будет работать сейчас и в будущем.
Этот пост призван облегчить вам процесс. Следующий контент поможет вам:
- Ознакомьтесь с преимуществами системы NAS.
- Перейдите к нужным параметрам.
- Понять причину, по которой ваш NAS подключается к облачному хранилищу.
Как NAS может принести пользу вашему бизнесу?
Система NAS может предоставить пользователям в вашей сети множество преимуществ, но здесь мы кратко перечислим некоторые из основных преимуществ.
- Больше места для хранения. Это немного очевидно, но основное преимущество системы NAS заключается в том, что она значительно увеличивает емкость вашего хранилища, если вы полагаетесь на рабочие станции и жесткие диски. Системы NAS создают единый том хранения из нескольких дисков (часто организованных по схеме RAID).
- Защита от потери данных. Менее очевидная, но не менее важная конфигурация RAID в системе NAS гарантирует, что данные, которые вы храните, смогут пережить отказ одного или нескольких жестких дисков. Жесткие диски выходят из строя! NAS помогает сделать это утверждение менее пугающим.
- Безопасность и скорость. Помимо защиты от сбоя диска, NAS также обеспечивает безопасность ваших данных от внешних субъектов, поскольку они доступны только в локальной офисной сети и для учетных записей пользователей, которые вы можете контролировать. Более того, он обычно работает так же быстро, как и ваша локальная офисная сеть.
- Лучшие инструменты управления данными. Полностью автоматизированное резервное копирование, дедупликация, сжатие и шифрование — это лишь некоторые из функций, которые вы можете задействовать в системе NAS. Все они делают ваше хранилище данных более эффективным и безопасным. Вы также можете настроить рабочие процессы синхронизации, чтобы упростить совместную работу вашей команды, включить службы для управления пользователями и группами с помощью служб каталогов и даже добавить такие службы, как управление фотографиями или мультимедиа.
Если все это кажется полезным для вашего бизнеса, читайте дальше, чтобы узнать больше о том, как воспользоваться этими преимуществами внутри компании.
 Руководство покупателя к сетевому хранилищу (NAS)
Руководство покупателя к сетевому хранилищу (NAS)
Как вы оцениваете различия между разными поставщиками NAS? Или даже в рамках продуктовой линейки одной компании? Мы здесь, чтобы помочь. Этот тур по основным компонентам системы NAS поможет вам составить список для определения размеров и функций системы, которые будут соответствовать вашим потребностям.
Выбор NAS: компоненты
Работа вашего NAS определяется компонентами, составляющими систему, и возможностями будущих обновлений. Давайте рассмотрим различные варианты.
Емкость хранилища NAS: сколько отсеков вам нужно?
Один из первых способов отличить разные системы NAS — это количество отсеков для дисков, предлагаемых данной системой, поскольку от этого зависит, сколько дисков может вместить система. Вообще говоря, чем больше количество отсеков для дисков, тем больше места для хранения вы можете предоставить своим пользователям и тем больше у вас будет гибкости для защиты данных от сбоя диска.
В системе NAS хранилище определяется количеством дисков, общим томом, который они создают, и их схемой чередования (например, RAID 0, 1, 5, 6 и т. Д.). Например, один диск не дает дополнительной производительности или защиты. Два диска позволяют выполнить простое зеркальное отображение. Зеркальное отображение также называется RAID 1, когда один том состоит из двух дисков, что допускает отказ одного из этих дисков без потери данных. Два диска также допускают чередование — называемое RAID 0 — когда один том «растягивается» на два диска, образуя один диск большего размера, что также дает некоторое улучшение производительности, но увеличивает риск, поскольку потеря одного диска означает, что весь том будет недоступен.
Напоминание: как снова работает RAID?
Резервный массив независимых дисков или RAID объединяет несколько жестких дисков в один или несколько томов хранения. RAID распределяет данные и четность (информацию о восстановлении дисков) по дискам по-разному, и каждая схема обеспечивает разную степень защиты данных.
Три диска — это минимум для RAID 5, который может выдержать потерю одного диска, хотя четыре диска являются более распространенной конфигурацией системы NAS. Пять дисков позволяют использовать RAID 6, который может выдержать потерю двух дисков. От шести до восьми дисков являются очень распространенными конфигурациями NAS, которые позволяют увеличить объем хранилища, пространства, производительности и даже сэкономить диск — возможность назначить резервный диск для немедленного восстановления отказавшего диска.
Многие считают, что если вы ищете систему NAS с несколькими отсеками, вам следует выбрать емкость, которая позволяет использовать RAID 6, если это возможно. RAID 6 может выдержать потерю двух дисков и обеспечивает производительность, почти равную RAID 5, с лучшей защитой.
Понятно подумать: зачем мне готовиться на случай, если два диска выйдут из строя? Что ж, когда диск выходит из строя и вы заменяете его новым, процесс восстановления данных и информации о четности на этом диске может занять много времени. Хотя это случается редко, во время восстановления может выйти из строя другой диск. В этом случае, если у вас RAID 6, все будет в порядке. Если у вас RAID 5, возможно, вы только что потеряли данные.
Примечание покупателя. Некоторые системы продаются без дисков. Стоит ли покупать NAS с дисками или без них? Это решение обычно сводится к размеру и типу дисков, которые вы хотели бы иметь.
При покупке системы NAS с дисками в комплекте:
- На диски обычно распространяется гарантия производителя как на часть полной системы.
- Накопители обычно покупаются непосредственно в цепочке поставок производителя и отправляются напрямую от производителя жестких дисков.
Если вы решите покупать диски отдельно от NAS:
- Приводы могут представлять собой смесь производственных циклов приводов и дольше присутствовать в цепочке поставок. Подбирайте емкости и модели дисков для наиболее предсказуемой производительности всего тома RAID.
- Выберите диски, рассчитанные на работу с системами NAS — поставщики NAS публикуют списки поддерживаемых типов дисков. Вот, например, список от QNAP.
- Проверьте гарантии и процедуры возврата, и если вы перемещаете коллекцию старых дисков в свой NAS, вы также можете определить, какая часть гарантии уже истекла.
Вывод для покупателя: выберите систему, которая может поддерживать RAID 5 или RAID 6, чтобы обеспечить сочетание большего объема памяти, производительности и защиты диска от сбоев. Но обязательно проверьте, продается ли система NAS с накопителями или без них.
Выбор емкости диска для NAS: диски какого размера следует покупать?
Вы можете быстро оценить, какой объем хранилища вам понадобится, добавив жесткие диски и внешние диски всех систем, для которых вы будете выполнять резервное копирование в своем офисе, добавив объем общего хранилища, который вы хотите предоставить своим пользователям, и учитывайте любой прогнозируемый рост спроса на совместно используемое хранилище.
Если у вас есть какие-либо исторические данные за предыдущие годы, вы можете рассчитать простой темп роста. Но добавляйте буфер, так как с каждым годом рост данных ускоряется. Вообще говоря, цены на системы в два или четыре раза превышают размер вашей существующей емкости данных. Допустим, ваши жесткие и внешние диски для резервного копирования, а также любое дополнительное общее хранилище, которое вы хотите предоставить своим пользователям, увеличивают до 20 ТБ. Удвойте этот размер, чтобы получить 40 ТБ с учетом роста, затем разделите на общий размер жесткого диска, например 10 ТБ. Имея это в виду, вы можете начать покупать системы с четырьмя отсеками и более.
Формула 1: ((количество пользователей NAS x размер жесткого диска) + общее хранилище) * фактор роста = необходимое хранилище NAS
Пример. В офисе шесть пользователей, каждый из которых будет выполнять резервное копирование своих рабочих станций и ноутбуков емкостью 2 ТБ. Команда захочет использовать еще 6 ТБ общего хранилища для документов, изображений и видео для всех. Умноженный на коэффициент роста в два раза, вы начнете покупать системы NAS, которые предлагают не менее 36 ТБ хранилища.
((Шесть пользователей * 2 ТБ каждый) + 6 ТБ общего хранилища) * коэффициент роста два = 36 ТБ
Формула 2: ((требуется хранилище NAS / размер жесткого диска) + два диска с контролем четности) = требуются отсеки для дисков
Пример. Продолжая приведенный выше пример, при поиске новой системы NAS с дисками емкостью 12 ТБ, учитывая два дополнительных диска для RAID 6, вы должны искать системы NAS, которые могут поддерживать пять или более отсеков для жестких дисков по 12 ТБ.
((36 ТБ / 12 ТБ) + два дополнительных диска) = пять отсеков для дисков и более
Если ваш бюджет позволяет, выбор дисков большего размера и большего количества отсеков для дисков приведет к увеличению накладных расходов на хранилище, которые со временем наверняка вырастут. Учтите, однако, что если вы станете слишком большим, вы будете платить за неиспользуемое пространство для хранения в течение более длительного периода времени. А если вы используете бухгалтерский учет по GAAP, вам нужно будет окупить эти вложения за то же время, что и меньшая система NAS, что принесет прибыль на ежегодной основе. Это классическая дилемма CapEx и Opex, о которой вы можете узнать больше здесь.
Если у вас ограниченный денежный бюджет, вы всегда можете приобрести систему NAS с большим количеством отсеков, но меньшими дисками, что значительно снизит ваши первоначальные цены. Затем вы можете заменить эти диски в будущем на более крупные, когда они вам понадобятся. Цены на жесткие диски обычно снижаются со временем, поэтому в будущем они, вероятно, будут дешевле. Со временем вы купите два комплекта приводов, что вначале будет менее затратным, но, вероятно, более дорогим в долгосрочной перспективе.
Точно так же можно частично заполнить отсеки для дисков. Если вы хотите получить систему с восемью отсеками, но у вас есть бюджет только на шесть дисков, просто добавьте остальные диски позже. Одна из лучших составляющих систем NAS — это гибкость, которую они позволяют вам правильно определять подход к общему хранилищу.
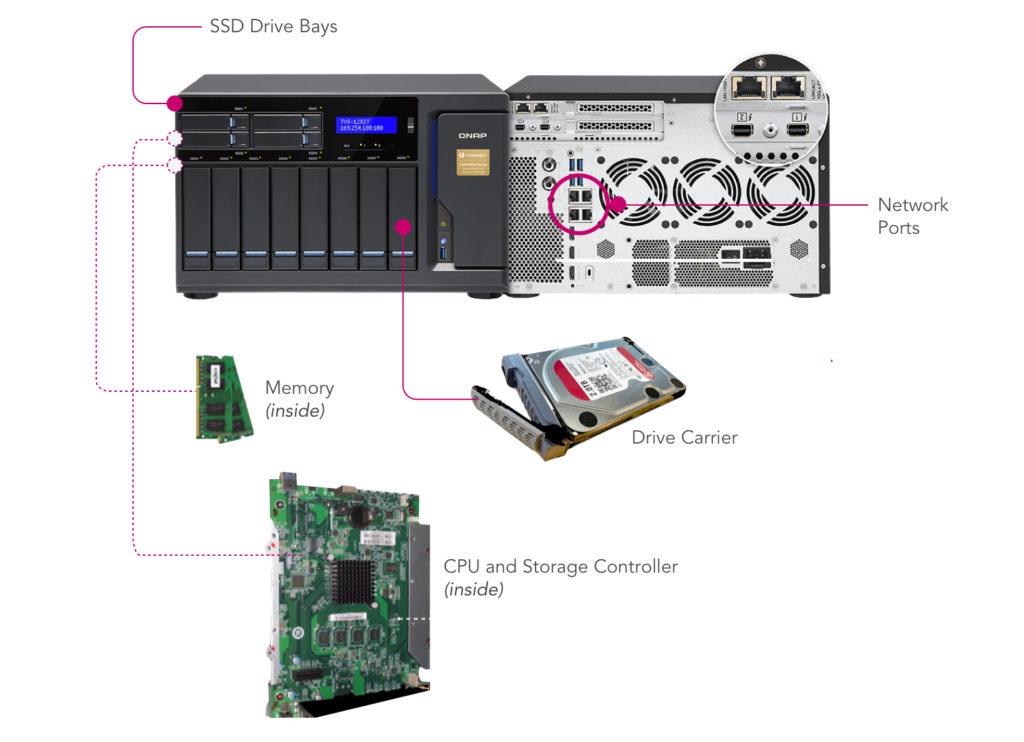
Вывод для покупателя: оцените, какой объем хранилища вам понадобится, добавьте объем общего хранилища, который вы хотите предоставить своим пользователям, и учесть растущий спрос на общее хранилище, а затем сбалансируйте долгосрочный потенциал роста с потоком денежных средств.
Процессор, контроллеры и память: какой уровень производительности вам нужен?
Что лучше: большие встроенные процессоры или контроллеры? Меньшие встроенные микросхемы, обычно используемые в небольших NAS-системах, обеспечивают базовую функциональность, но могут зависнуть при обслуживании большого количества пользователей или при выполнении задач дедупликации и шифрования, которые являются вариантами со многими решениями для резервного копирования. Более крупные системы NAS, которые обычно хранятся в стойках ИТ-центров обработки данных, обычно предлагают несколько контроллеров хранения, которые могут обеспечить максимальную производительность и даже возможность переключения при отказе.
- Процессор: обеспечивает вычислительную мощность для работы системы, служб и приложений.
- Контроллер: управляет представлением и состоянием объема хранилища.
- Память: Повышает скорость работы приложений и производительность обслуживания файлов.
Чипы ARM и Intel Atom хороши для базовых систем, в то время как более крупные и более мощные процессоры, такие как Intel Corei3 и Corei5, быстрее справляются с задачами NAS, такими как шифрование, дедупликация и обслуживание любых встроенных приложений. Микросхемы серверного класса Xeon также можно найти во многих стоечных системах.
Так что, если вы просто ищете базовое расширение хранилища, системы начального уровня с более скромными базовыми микросхемами, скорее всего, вам подойдут. Если дедупликация, шифрование, синхронизация и другие функции, предлагаемые многими системами NAS в качестве дополнительных инструментов, являются частью вашего будущего рабочего процесса, это одна из областей, где вам не следует срезать углы.

Если у вас есть возможность расширить системную память, это может быть простым обновлением производительности. Как правило, чем выше соотношение памяти и дисков, тем выше производительность чтения и записи на диск, а также скорость работы встроенных приложений.
Вывод для покупателя: системы NAS начального уровня обеспечивают хорошую базовую функциональность, но вы должны убедиться, что ваши компоненты соответствуют требованиям, если вы планируете интенсивно использовать дедупликацию, шифрование, сжатие и другие функции.
Сеть и подключения: какая скорость вам нужна?
Базовый NAS будет иметь соединение Gigabit Ethernet, которое часто обозначается как 1GigE. Пропускная способность сети в 1 Гбит / с эквивалентна 125 МБ / с, поступающей из вашей системы хранения. Это означает, что система NAS должна предоставлять услуги хранения для всех пользователей в рамках этого ограничения, что обычно не является проблемой при обслуживании только нескольких пользователей. Многие системы имеют внутренние порты расширения, что позволяет позже приобрести сетевую карту 10GigE для обновления вашего NAS.

Некоторые поставщики NAS предлагают в своих системах соединения со скоростью 2,5 Гбит / с или 5 Гбит / с — это даст вам больше производительности, чем подключения 1GigE, но обычно требуется, чтобы вы получили совместимый сетевой коммутатор и, возможно, USB-адаптеры или карты расширения для каждого система, которая будет подключаться к этому NAS через коммутатор. Если ваш офис уже подключен к 10GigE, убедитесь, что ваш NAS также 10GigE. В противном случае, чем больше сетевых портов на задней панели системы, тем лучше. Если вы не готовы получить систему с поддержкой 10GigE сейчас, но думаете, что, возможно, получите ее в будущем, выберите систему с возможностью расширения.

Некоторые системы предоставляют еще один вариант соединений Thunderbolt в дополнение к соединениям Ethernet. Они позволяют ноутбукам и рабочим станциям с портами Thunderbolt напрямую подключаться к NAS и предлагают гораздо более высокую пропускную способность — до 40GigE (5 ГБ / с) — и подходят для систем, которым необходимо редактировать большие файлы непосредственно на NAS, как это часто бывает случай в редактировании видео. Если вы будете напрямую подключать системы, которым требуется максимально высокая скорость, выберите систему с портами Thunderbolt, по одному на каждого пользователя, подключенного к Thunderbolt.
Вывод для покупателя: лучше иметь больше сетевых портов в задней части системы. Или выберите систему с возможностью карты расширения сети.
Функции кэширования и гибридного диска: насколько быстро нужно обслуживать файлы?
Многие из высокопроизводительных NAS-систем могут дополнять стандартные 5,25-дюймовые жесткие диски более производительными SSD или дисками M.2 меньшего форм-фактора. Эти более компактные и быстрые диски могут значительно повысить производительность обслуживания файлов NAS за счет кэширования файлов в самых последних или наиболее часто запрашиваемых файлах. Комбинируя эти разные типы дисков, NAS может обеспечить как улучшенную производительность обслуживания файлов, так и большую емкость.
По мере роста числа пользователей, которых вы поддерживаете в каждом офисе, эти возможности станут более важными как относительно простой способ повышения производительности. Как мы упоминали ранее, вы можете приобрести систему с незанятыми слотами и добавить их позже.
Вывод для покупателя: комбинируйте различные типы дисков, например SSD меньшего форм-фактора или хранилище M.2 с жесткими дисками 5,25 дюйма, чтобы повысить производительность обслуживания файлов.
Операционная система: какие функции управления вам требуются?
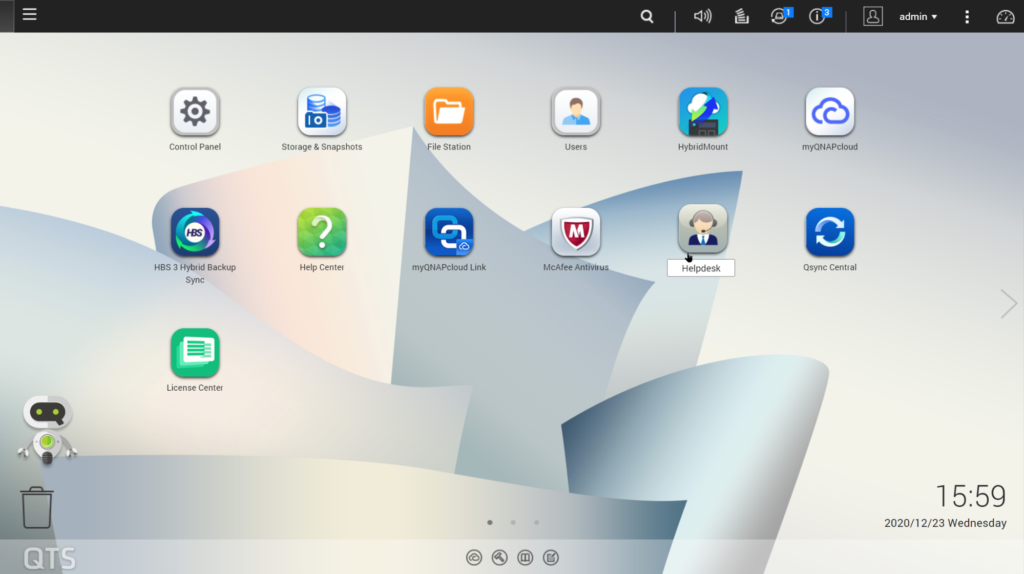
Операционные системы NAS основных производителей обычно предоставляют те же услуги в интерфейсе, подобном ОС, через встроенный веб-сервер. Просто введя IP-адрес своего NAS, вы можете войти в систему и управлять настройками своей системы, создавать тома хранения и управлять ими, настраивать группы пользователей в вашей сети, которые имеют доступ, настраивать и отслеживать задачи резервного копирования и синхронизации, и многое другое.
Если в вашей ИТ-среде есть определенные функции управления пользователями, которые вам нужны или вы хотите протестировать, как работает ОС NAS, вы можете протестировать их, запустив демонстрационную виртуальную машину, предлагаемую некоторыми поставщиками NAS. Вы можете протестировать конфигурацию сервиса и почувствовать интерфейс и инструменты, но очевидно, что в виртуальной среде вы не сможете напрямую управлять оборудованием. Вот несколько вариантов:
Вывод для покупателя: встроенная ОС NAS OS похожа на операционную систему Mac или ПК, что упрощает навигацию по настройке и обслуживанию системы, а также позволяет управлять настройками, хранилищем и задачами.
Решения: какие дополнительные услуги вам требуются?
Хотя встроенный процессор и память на вашем NAS в основном предназначены для файлового сервиса, резервного копирования и синхронизации, вы также можете установить другие решения прямо на него. Например, QNAP и Synology — два популярных поставщика NAS — имеют магазины приложений, доступные из их управляющего программного обеспечения, где вы можете выбрать приложения для загрузки и установки на NAS. Возможно, вас заинтересует решение для резервного копирования и синхронизации, такое как Archiware, или решения CMS, такие как Joomla или WordPress.

Однако, помимо решений для резервного копирования, вы получите выгоду от установки критически важных приложений на выделенную систему, а не на NAS. Для небольшого числа пользователей запуск приложений непосредственно на NAS может быть хорошим временным использованием или способом что-то проверить. Но если приложение становится очень загруженным, это может повлиять на другие службы NAS. В целом, собственные приложения на вашем NAS могут быть полезны, но не переусердствуйте.
Вывод для покупателя: основные приложения для резервного копирования и синхронизации от основных поставщиков NAS превосходны — дайте им хороший тест, но знайте, что существует множество отличных решений для резервного копирования и синхронизации.
Почему добавление облачного хранилища в NAS дает дополнительные преимущества
Когда вы соединяете облачное хранилище с вашим NAS, вы получаете доступ к функциям, которые дополняют безопасность ваших данных и вашу возможность обмениваться файлами как локально, так и удаленно.
Во-первых, облачное хранилище обеспечивает защиту резервного копирования за пределами площадки. Это приводит настройку вашего NAS в соответствие с отраслевым стандартом защиты данных: стратегией резервного копирования 3-2-1, которая гарантирует, что у вас будет три копии ваших данных, исходные данные и две резервные копии, одна из которых находится на вашем NAS, а вторая копия ваших данных защищена за пределами сайта. А в случае потери данных вы можете восстановить свои системы прямо из облака, даже если все системы в вашем офисе выйдут из строя или разрушены.
Хотя данные, отправляемые в облако, шифруются на лету с помощью SSL, вы также можете зашифровать свои резервные копии, чтобы их можно было открыть только с помощью ключа шифрования вашей команды. Облако также может предоставить вам расширенные возможности хранения файлов резервных копий, такие как однократная запись, многократное чтение (WORM) или неизменяемость, что делает ваши данные неизменными в течение определенного периода времени, или устанавливать пользовательские правила жизненного цикла данных на уровне корзины, чтобы соответствовать вашим идеальный рабочий процесс резервного копирования.
Кроме того, облачное хранилище обеспечивает ценный доступ к вашим данным и документам с вашего NAS за счет возможностей синхронизации. В случае, если кому-то из вашей команды потребуется доступ к файлу, когда он находится вне офиса, или, что более распространено сейчас, если вся ваша команда работает из дома, они смогут получить доступ к файлам, которые были синхронизированы с облако через программу безопасной синхронизации вашего NAS. Вы даже можете выполнять синхронизацию в нескольких местах, используя облако в качестве двусторонней синхронизации для быстрой репликации данных в разных местах. Сотрудникам, работающим на большом расстоянии, это помогает избежать ожидания доставки важных файлов в Интернете: они уже находятся на месте.
Напоминание: в чем разница между облачной синхронизацией, облачным резервным копированием и облачным хранилищем? Службы синхронизации позволяют нескольким пользователям на нескольких устройствах получать доступ к одному и тому же файлу. Резервное копирование хранит копию этих файлов где-то вдали от вашей рабочей среды, часто на удаленном сервере, например в облачном хранилище. Важно знать, что «синхронизация» не является резервной копией, но они могут хорошо работать вместе при правильной координации. Вы можете узнать больше о различиях в этом сообщении в блоге.
Готовы к настройке вашего NAS с облачным хранилищем
Подводя итог, вот несколько вещей, которые следует помнить при покупке системы NAS:
- Подумайте, сколько места вам понадобится как для локального резервного копирования, так и для общего пользовательского хранилища.
- Ищите систему как минимум с тремя-пятью отсеками для дисков.
- Убедитесь, что система NAS продается с дисками — в противном случае вам придется приобрести достаточное количество дисков одинакового размера.
- Выбирайте систему, которая позволяет вам модернизировать память и сетевые опции.
- Выберите систему, которая соответствует вашим потребностям сегодня; вы всегда можете обновить его в будущем.
В сочетании с облачным хранилищем, таким как Backblaze B2 Cloud Storage, которое уже интегрировано с системами NAS от Synology и QNAP, вы получаете необходимую защиту резервного копирования и восстановление из облака, а также возможность синхронизации между местоположениями.
www.backblaze.com/b2/cloud-storage.html