Миграция 23 ТБ из Amazon S3 в Backblaze B2 всего за семь часов
Как и многие клиенты Backblaze, Nodecraft поняла, что может сэкономить целое состояние, переместив свое облачное хранилище на Backblaze и инвестировав его в другое место для развития своего бизнеса. В этом посте, который первоначально появился в блоге Nodecraft, Грегори Р. Суддерт, старший инженер по разработке приложений для Nodecraft, рассказывает о шагах, которые они предприняли, чтобы сначала проанализировать, протестировать, а затем переместить это хранилище.Левенс
Nodecraft.com — это многопользовательская облачная платформа, где геймеры могут арендовать и использовать наши серверы для создания и обмена уникальными многопользовательскими онлайн-серверами со своими друзьями и / или публикой. Владельцы серверов, использующие свои игровые серверы, создают резервные копии, включая файлы серверов, игровые резервные копии и другие файлы. Само собой разумеется, что надежность резервного копирования важна для владельцев серверов.
В ноябре 2018 года нам в Nodecraft стало ясно, что мы можем улучшить наши расходы, если пересмотрим нашу стратегию облачного резервного копирования. Изучив текущие предложения, мы решили перенести наши резервные копии с Amazon S3 на сервис Backblaze B2. В этой статье описывается, как наша команда подошла к этому, почему и что произошло, в частности, чтобы мы могли поделиться своим опытом.
Выгоды
Из-за того, что S3 и B2, по крайней мере, в равной степени * доступны, надежны, доступны, а также многих других провайдеров, нашей основной причиной для переноса наших резервных копий стала цена. Когда мы начали работу, начали появляться другие факторы, такие как разнообразие API, качество API, реальная работоспособность и обслуживание клиентов.
Изучив самые разные соображения, мы остановились на услуге Backblaze B2. Большую часть затрат на эту операцию составляет их пропускная способность, которая удивительно доступна.
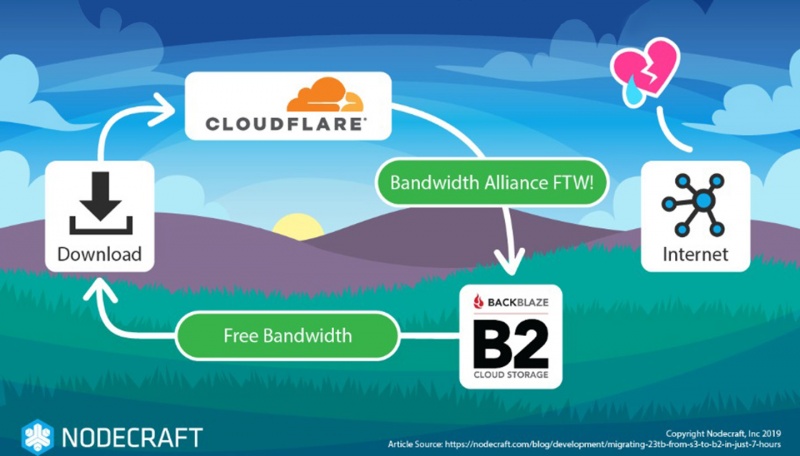
Ценовой разрыв между двумя системами хранения объектов обусловлен альянсом Bandwidth между Backblaze и Cloudflare, группой провайдеров, которые согласились не взимать (или сильно снижать) плату за данные, оставленные в альянсе сетей («выходные» сборы). Мы в Nodecraft интенсивно используем Cloudflare, и поэтому оставалось беспокоиться только об исходящих затратах от Amazon до Cloudflare.
В обычных условиях наши клиенты постоянно создают резервные копии, а также получают к ним доступ для различных целей, и их возможности по выполнению этих операций не изменились по сравнению с предыдущим поставщиком.
Соображения
Как и в случае любых изменений в поставщиках, переход должен быть продуман с большим вниманием к деталям. Когда ранее не было проблем с качеством, и обстоятельства таковы, что можно рассмотреть широкое поле новых поставщиков, окончательный выбор должен быть тщательно оценен. Наш список проблем включал эти:
- Безопасность: нам нужно было переместить наши файлы и обеспечить их сохранность, избыточным способом
- Доступность: служба должна быть надежной, но и широко доступной ** (что означает, что нам нужно было «указать» на нужный файл после его перемещения в течение всего процесса перемещения всех файлов: у разных компаний разные стратегии, одна корзина, много ведер, областей, зон и т. д.)
- API: у нас есть опыт, поэтому мы не помешаны на проприетарных инструментах передачи файлов
- Скорость: нам нужно было перемещать файлы навалом, а не тормозить ограничения скорости, и
- Неправильная настройка может превратить операцию в нашу собственную DDoS.
Все эти факторы в отдельности хороши и важны, но при их совместном создании может произойти значительный сбой в обслуживании. Если все может двигаться легко, быстро и, ненадежно, неправильная настройка может превратить эту операцию в нашу собственную DDoS. Мы предприняли тщательные шаги, чтобы этого не произошло, поэтому было добавлено дополнительное требование:
Настройка: не отказывайтесь от собственных услуг и не вредите соседям
Что это означает для непрофессионала:
У нас много устройств в нашей сети, мы можем сделать это параллельно. Если мы сделаем это на полной скорости, мы сможем сделать так, чтобы наши поставщики услуг не очень-то нравились нам… может быть, мы должны сделать это не на полной скорости
Важные части
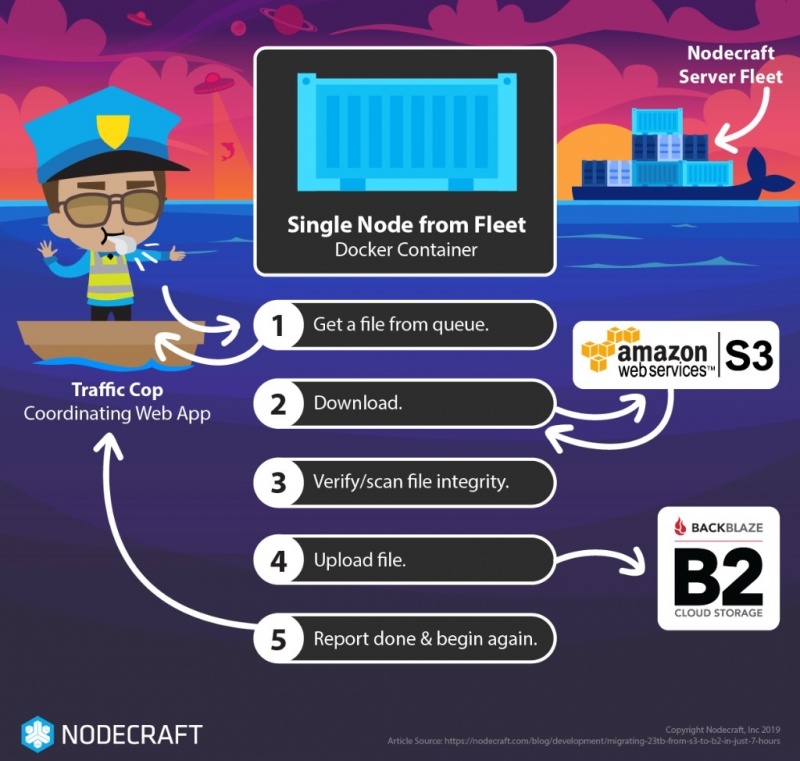
Чтобы использовать наши собственные возможности облачной обработки, мы знали, что нам придется использовать двухуровневый подход как на уровне Tactical (переместить файл), так и на уровне Strategic (указать многим узлам, чтобы переместить все файлы).
Cстратегическое
Наши цели здесь просты: мы хотим переместить все файлы, переместить их правильно и только один раз, но также убедиться, что операции могут продолжаться, пока происходит это перемещение. Это важно, потому что если бы мы использовали один компьютер для перемещения файлов, это заняло бы месяцы.
Первым шагом к выполнению этой работы параллельно было создание небольшого веб-сервиса, который позволил бы нам ставить в очередь один целевой файл, который будет одновременно перемещаться на каждый рабочий узел. Эта служба обеспечивала механизм блокировки, чтобы один и тот же файл не мог перемещаться дважды, одновременно или одновременно. Таймер истечения блокировки (с сообщением об ошибке) был установлен на пару часов. Этот сервис был предназначен для доступа с помощью простых инструментов, таких как curl.
Мы развернули каждый рабочий узел в виде контейнера Docker, распределенного по всему нашему Docker Swarm. Используя параметры в файле стека докеров, мы смогли определить, сколько рабочих на узел присоединилось к задаче. Это также гарантировало, что более дорогие регионы пропускной способности, такие как Азиатско-Тихоокеанский регион, не присоединились к рабочему пулу.
Тактический
У Nodecraft есть несколько парков серверов, охватывающих несколько центров обработки данных, и мы планировали использовать запасные ресурсы на большинстве из них для перемещения файлов резервных копий. Мы испытывали постоянный порядок доступа к нашим серверам со стороны наших пользователей в различных дата-центрах по всему миру, и мы знали, что будет доступность для наших целей перемещения файлов.
Наши цели в этой части операции также просты, но имеют больше шагов:
- Получить имя / идентификатор / URL-адрес файла для перемещения, который блокирует файл и запускает таймер сбоя
- Получить информацию о файле, включая размер
- СКАЧАТЬ: Скопировать файл на локальный узел (без ограничения доступности узла сети)
- Проверьте файл (размер, целостность ZIP, хэш)
- ЗАГРУЗИТЬ: скопировать файл в новый сервис (опять же, не влияя на узел)
- Сообщите «готово» с новой информацией о местоположении ID / URL на стратегическом уровне, который
- Снимает блокировку в веб-сервисе, отменяет таймер и помечает файл как DONE
Переключатель убийства
В случае потенциального побега, когда даже внутриполосный Docker Swarm командует сами, мы решили убедиться, что у нас есть удобный переключатель. В нашем случае это был наш маленький бесстрашный веб-сервис — мы позаботились о том, чтобы приостановить его. Оглядываясь назад, было бы лучше, если бы он использовал расходуемый ресурс, такой как счетчик, или значение в ячейке базы данных. Если бы мы не обновили счетчик, он остановился бы сам по себе. Подробнее о «побегах» позже.
Тюнинг Реальной Жизни
Наш бизнес имеет ежедневные, еженедельные и другие циклы деятельности, которые предсказуемы. Наиболее важным является наш ежедневный цикл, который тянется после Солнца. Мы решили использовать наши узлы, которые находились в областях с низкой активностью, для выполнения работы, и после тестирования мы обнаружили, что, если мы настроимся правильно, это не повлияет на относительно небольшие нагрузки на серверы в этой области с низкой активностью. Это было подтверждено проверкой отсутствия изменений в нагрузке обслуживания клиентов с использованием наших показателей и инструментов CRM. Вернуться к настройке.
Первоначально мы настроили скорость передачи файла DOWN, эквивалентную 3/4 от того, что мог сделать wget (1). Мы подумали: «Ох, сетевой трафик к узлу будет соответствовать этому, так что все в порядке». Это в основном верно, но только в основном. Это проблема в двух отношениях. Причиной проблем является то, что тесты изолированного узла являются просто изолированными. Когда большое количество узлов в центре обработки данных выполняет фактическую передачу рабочих файлов, возникает пропорциональное воздействие, поскольку трафик концентрируется в направлении выходных точек.
Проблема 1: вы плохой сосед на пути к выходным пунктам. Хорошо, вы говорите «хорошо, мы платим за доступ к сети, давайте использовать его», но, конечно, есть только так много всего, но также очевидно, что «все порты коммутатора имеют большую пропускную способность, чем порты восходящей линии связи», поэтому, конечно, будет быть ограниченным, чтобы быть пораженным.
Проблема 2: ты сам себе плохой сосед. Опять же, если в конечном итоге ваши машины будут находиться рядом друг с другом в сети с помощью сетевых координат, ваши попытки «использовать всю пропускную способность, за которую мы заплатили», будут подавлены ближайшей точкой подавления, воздействуя только на почти только ты. Если вы собираетесь использовать большую часть полосы пропускания, которую МОЖЕТЕ использовать, вы должны также помнить об этом и выбирать, куда вы поместите точку засорения, которую создаст вся операция. Если кто-то не знает об этой проблеме, он может снять целые стойки вашего собственного оборудования, подавив коммутатор в верхней части стойки, или другие сетевые устройства.
Уменьшая нашу настройку 3 / 4ths-wget (1) до 50% от того, что wget могла сделать для передачи одного файла, мы увидели, что наши узлы по-прежнему функционируют должным образом. Ваш пробег будет совершенно разным, и есть скрытые проблемы в деталях того, как ваши узлы могут или не могут быть рядом друг с другом, и их влияние на оборудование между ними и Интернетом.
Старые привычки
Возможно, это досадная деталь: основываясь на предыдущем жизненном опыте, я привел некоторые задержки. Мы написали эти инструменты на Python, с помощью оболочки оболочки Bourne для обнаружения сбоев (были), а также потому, что на нашем этапе загрузки мы пошли вразрез с нашей ДНК и использовали утилиту загрузки Backblaze. Кстати, он многопоточный и действительно быстрый. Но в сценарии оболочки оболочки, как само собой разумеющемся, в главном цикле, который впервые говорил с нашим API, я поместил оператор sleep 2. Это создает небольшую паузу «вверху» между файлами.
Это оказалось ключевым, как мы увидим через мгновение.
Как это (служба, почти) все пошли вниз
То, что в прошлом, иногда не является прологом. Независимое тестирование в одном узле или даже в нескольких узлах не было полностью поучительным для того, что действительно должно было произойти, когда мы удушили тест. Теперь, когда я говорю «тест», я действительно имею в виду «операция».
Наше первоначальное тестирование было завершено «Тактически», как и выше, для которого мы использовали тестовые файлы, и были очень осторожны при их проверке. В общем, мы были уверены, что сможем справиться с копированием файла (цикл Python) и проверкой (unzip -T) и работать с утилитой Backblaze b2 без особых проблем… но это стратегический уровень, который научил нас нескольким вещам.
Вспоминая туманное прошлое, когда «6% коллизий в сети 10-BASE-T и ее игра окончена»… да, 6%. Мы сократили количество реплик в Docker Swarm, и у нас не было никаких проблем. Хорошо. “Хорошо.” Тогда мы переместили дроссель, так сказать, к последней задержке.
Мы почти достигли самообороны DDoS.
Это было не так уж и плохо, но мы внезапно были очень, очень довольны нашей настройкой 50% -го-wget (1) и нашими 2-секундными задержками между передачами, и, самое главное, нашим переключателем уничтожения.
Анализ
TL; DR — Все прошло отлично.
Было несколько файлов, которые просто не хотелось передавать (их не было на S3, хм). Были некоторые DDoS-тревоги, которые на мгновение сработали. Было много трафика… и, затем, счет за пропускную способность.
Ваш пробег может отличаться, но есть некоторые вещи, которые нужно учитывать в отношении вашего счета за пропускную способность. Когда я говорю «счет», на самом деле это несколько счетов.
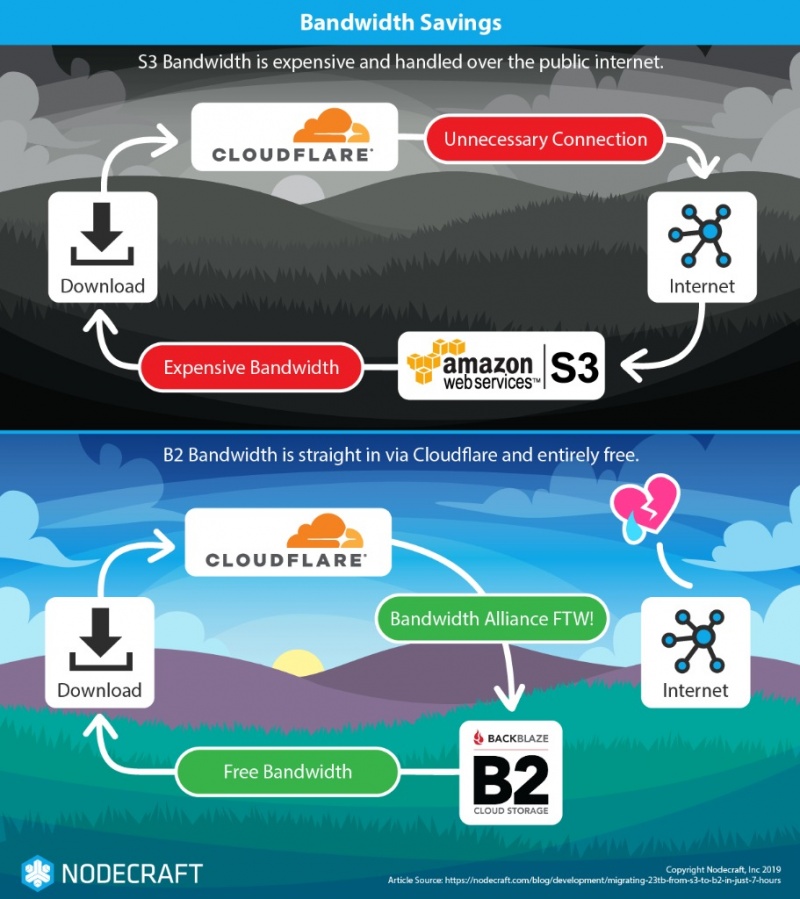
Как показано на диаграмме выше, перемещение файла может привести к многократной загрузке полосы пропускания, особенно когда наши клиенты начали загружать файлы из B2 для развертывания экземпляров и т. Д. В нашем случае у нас теперь был только счет за выход S3. Вот почему это работает:
У нас есть групповые (узловые) дисконтные соглашения о пропускной способности с нашими провайдерами.
B2 является членом Bandwidth Alliance и Cloudflare тоже
Мы обращались к нашему контенту S3 через наши (не бесплатные!) Публичные URL-адреса учетной записи Cloudflare, а не через (частные) S3 URL.
Не говоря уже о наших конфиденциальных договоренностях с нашими партнерами по обслуживанию, в целом верно и следующее: вы можете поговорить с поставщиками, а иногда и договориться о сокращениях. Кроме того, им особенно нравится, когда вы звоните им (заранее) и обсуждаете свои планы по усиленному управлению своей экипировкой. Например, при другом перемещении данных один из провайдеров дал нам способ «пометить» наш трафик определенным образом, и он будет проходить через тихую, но не часто посещаемую часть своей сети; победа победа!
Хочу больше?
Прочитайте пример использования Nodecraft в блоге Cloudflare.
Мы также выпустили наш собственный модуль JavaScript NPM B2-Cloud-Storage, который мы сейчас используем в производстве, чтобы упростить процесс загрузки.
Спасибо за ваше внимание, и удачи с вашим собственным байтовым стропом.
Грегори Р. Sudderth
Nodecraft Старший инженер DevOps
Наука сложна, синие клавиши на калькуляторах хитры, и у нас нет лет, чтобы изучать вещи, прежде чем делать их
0 комментариев
Вставка изображения
Оставить комментарий