Как можно использовать прерываемые виртуальные машины Яндекс.Облака и экономить на решении масштабных задач

Сегодня мы хотим рассказать о такой полезной функции Яндекс.Облака как прерываемые виртуальные машины. Это специальная опция, которую вы можете выбрать при создании виртуальной машины, чтобы использовать вычислительные ресурсы по сниженной цене. Что же такого особенного в прерываемых виртуальных машинах, почему они стоят дешевле обычных и в каких случаях разумно их применять?
Мощности Яндекс.Облака, а точнее, инфраструктурного сервиса Yandex Compute Cloud, заметно больше тех, что задействуются пользователями. По умолчанию предполагается, что у пользователей должна быть возможность условно неограниченного масштабирования. Как минимум из этих соображений, без учета других аспектов, доступные ресурсы облачной платформы существенно превышают текущий спрос. Именно на этих свободных мощностях и создаются прерываемые виртуальные машины.
Основные ограничения
Коротко сущность прерываемых виртуальных машин можно описать так: сервис предлагает использовать свои свободные вычислительные ресурсы по меньшей цене при условии, что эти ресурсы могут быть отозваны в любой момент.
В целом прерываемые виртуальные машины работают как обычные виртуальные машины, но для них установлен ряд ограничений:
- На них не распространяется соглашение об уровне обслуживания (SLA).
- Не гарантируется возможность создания и запуска.
- Они могут быть принудительно остановлены в любой момент. Вероятность остановки невелика, однако не равна нулю, может меняться со временем и различаться в разных зонах доступности Яндекс.Облака.
- Прерываемую виртуальную машину нельзя сделать обычной, а обычную прерываемой. Соответствующий флаг устанавливается один раз и не меняется.
- Машина обязательно будет остановлена в срок, не превышающий 24 часа.
При этом остановленную виртуальную машину можно запустить снова: все данные на дисках сохраняются и при автоматическом и при ручном выключении.
Сценарии использования
Ограничения для прерываемых виртуальных машин вызывают логичный вопрос: как их применять, если ресурсы могут быть отозваны в любой момент? В качестве пояснения приведём несколько возможных сценариев использования.
Пакетная обработка данных
Пакетная обработка подразумевает параллельное исполнение большого количества ресурсоёмких заданий. Это может быть преобразование форматов файлов, обработка и распознавание изображений, ETL-операции. Суть в том, что при пакетной обработке существует очередь заданий и целый набор рабочих процессов (исполнителей), получающих задания из очереди. Если отдельный исполнитель, запущенный на прерываемой машине, остановится, задание будет просто передано следующему исполнителю. Другими словами, остановка одной или даже нескольких виртуальных машин не окажет существенного негативного влияния на процесс и результат обработки.

При пакетной обработке данных речь идет об использовании десятков виртуальных машин. Применение прерываемых машин даёт очень заметную экономию. Сейчас один из главных потребителей производительных прерываемых виртуальных машин с 32 ядрами — давний клиент Яндекс.Облака, компания «Сейсмотек». «Сейсмотек» занимается обработкой сейсмических данных, которые необходимы для разведки газовых и нефтяных месторождений. Сейсморазведка предполагает работу с большими объемами информации. Данные обрабатываются пакетным методом. Компания одновременно использует до 60 с лишним прерываемых машин: суммарно до 2000 vCPU и 4000 ГБ RAM.
Проекты на Hadoop
Hadoop используется для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч недорогих узлов. Предусмотренные в Hadoop механизмы репликации файлов и автоматического перезапуска задач, выполнявшихся на вышедших из строя узлах, обеспечивают устойчивость распределённой системы к отказам отдельных машин. Именно поэтому там, где применяется Hadoop, как минимум часть узлов спокойно может быть развёрнута на прерываемых виртуальных машинах. В случае их досрочной остановки задачи будут отправлены на другие узлы.
Отказоустойчивость веб-сервисов
Постоянную доступность веб-сервиса можно обеспечить с помощью кластера. Кластер состоит из двух и более серверов. Одна из его задач в приложении к веб-сервисам — обеспечить стабильную работу в момент пиковых нагрузок. Характерные примеры: сайты интернет-магазинов или спортивные сайты, где рост трафика привязан к определенным датам. Для магазинов это могут быть традиционные праздники или периоды скидок, а для сайтов спортивной тематики — дни событий, когда идут трансляции, публикуются обзоры и фотоотчёты. В такие моменты объем трафика может увеличиваться в разы.
Кластер должен справляться с наплывом посетителей, распределяя трафик по разным узлам. На период резкого, но непродолжительно роста нагрузки отказоустойчивость можно обеспечивать, добавляя серверы на прерываемых виртуальных машинах. Такой вариант обходится недорого и хорошо справляется со своей задачей. Важно соблюдать одно условие: подобный кластер обязательно должен быть гибридным, то есть включать в себя обычные виртуальные машины. В этом случае даже маловероятная остановка прерываемых машин не приведёт к отказу сервиса.
Проекты на Kubernetes
Kubernetes позволяет автоматизировать развёртывание, масштабирование и управление контейнеризированными приложениями на большом количестве узлов. Одна из основных сущностей, которую можно назвать строительным блоком Kubernetes, — под (pod). Под обеспечивает запуск одного или нескольких контейнеров на одном узле. Узел для каждого пода подбирается и назначается планировщиком Kubernetes. Если отдельный узел с запущенным подом выйдет из строя, планировщик автоматически перенесёт под на узел, работающий в штатном режиме. Такая схема поддержания работоспособности предполагает, что часть узлов можно размещать на прерываемых виртуальных машинах.
Тестирование в практике непрерывной интеграции
Практика непрерывной интеграции строится на частой сборке и тестировании проекта. При этом применяется в основном автоматизированное тестирование. Схематически это выглядит так: создаётся тестовое окружение на виртуальной машине, в него выгружается последний билд приложения, проводится автоматизированное тестирование, результаты тестирования выгружаются, виртуальная машина удаляется. Как правило, тестирование занимает несколько десятков минут, реже — несколько часов.
Традиционно слабыми местами непрерывной интеграции считаются значительные затраты на поддержку самого процесса интеграции и высокая потребность в вычислительных ресурсах. С этой точки зрения и с учетом временных рамок автоматизированных тестов прерываемые виртуальные машины выглядят более чем подходящим вариантом для непрерывной интеграции. Они намного дешевле, а вероятность остановки машины непосредственно в момент проведения тестирования исчезающе мала. Больше того, даже если машина всё-таки будет остановлена, ущерб с точки зрения бизнеса будет минимальным.
Использование совместно с другими сервисами Яндекс.Облака
Сервис Yandex Instance Groups позволяет в автоматическом режиме отслеживать состояние целой группы прерываемых виртуальных машин. Он может самостоятельно создавать виртуальные машины с заданными характеристиками, поддерживать нужное количество машин в группе и перезапускать прерываемые инстансы в случае их остановки. Неважно, произошла ли принудительная остановка или прошло 24 часа с момента запуска. Важно только одно: перезапуск произойдет, если есть доступные ресурсы. Yandex Instance Groups делает работу с прерываемыми виртуальными машинами удобнее, но не может гарантировать, что в конкретной зоне доступности обязательно будут свободные мощности.
Экономические показатели
Как мы упоминали, прерываемые виртуальные машины позволяют сокращать затраты на использование вычислительных ресурсов. Внутри Яндекса мы начали работать над реализацией подобной функции ещё несколько лет назад. Чтобы разделить вычислительные задачи на гарантированно исполняемые и прерываемые, потребовались немалые инвестиции. Но всё было не зря: в итоге мы повысили уровень полезной утилизации серверной инфраструктуры с 30-40% до 70-80%.

Теперь аналогичные возможности доступны всем пользователям Яндекс.Облака по нажатию одной кнопки. Простой пример: если вы переведёте половину используемых виртуальных машин со стопроцентной загрузкой ядра в формат прерываемых, то сможете сэкономить до 35-40% бюджета.
По сниженной стоимости доступны ресурсы CPU и RAM. Дисковое пространство и IP-адреса оплачиваются по обычным тарифам. Вот что показывает простой расчёт для платформы Cascade Lake.
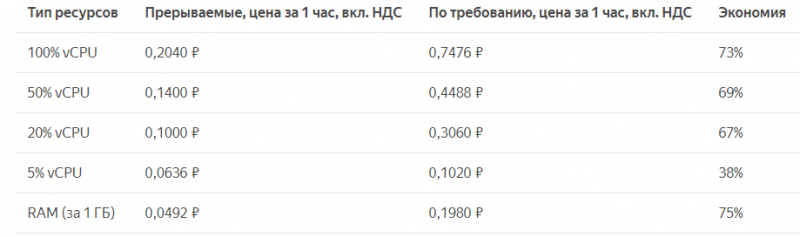
При желании вы можете сами сравнить стоимость использования виртуальных машин в разных режимах с помощью калькулятора. cloud.yandex.ru/prices
Надеемся, мы смогли внести немного ясности и дать несколько полезных примеров, в каких случаях можно применять прерываемые виртуальные машины, чтобы сократить расходы на вычислительные ресурсы, не теряя в качестве выполнения задач.
Инструкции по созданию прерываемых виртуальных машин и информация о тарифах здесь:
0 комментариев
Вставка изображения
Оставить комментарий