Даунтайм 7 января: что произошло
7 января система мониторинга сообщила о проблемах с производительностью на 28-ми родительских серверах. Основным симптомом был медленно работающий процессор.
Поиск причин и решение
Проблема проявилась только на платформе Intel S2600BPB с новыми процессорами Intel Silver и Gold. Другие общие характеристики не обнаружились: разные дата-центры, разные версии Linux, разные виртуализации.
Решить проблему в лоб не удалось. Сняли с сервера всю нагрузку (выключили клиентские VDS) — родительский сервер продолжал тормозить. Медленно работал даже интерфейс UEFI. Перезагрузка также не помогала.
Примерно 8 часов ушло на то, чтобы докопаться до сути проблемы. Искали, что связывает все эти случаи. В итоге решить проблему удалось только полным отключением питания. При запуске серверов после 10-минутного простоя проблема исчезает и не повторяется.
Причина сбоя
Чтобы объяснить, в чем дело, придется немного рассказать о физическом устройстве питания серверов.
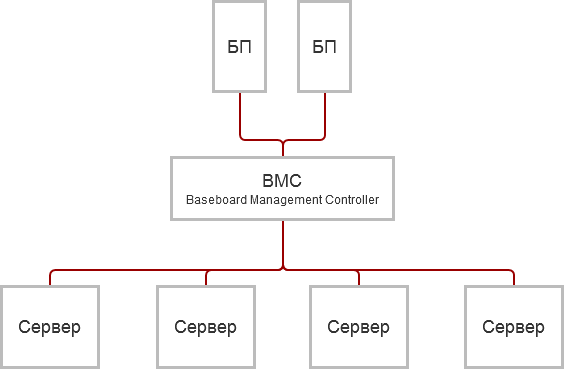
Сервер получает питание не напрямую. Для группы серверов действует пара блоков питания, работающих параллельно. Управляет подачей питания на все элементы сервера специальное устройство — контроллер BMC, Intel Baseboard Management Controller.
В консоли одного BMC нашли логи:
То есть контроллер определил перегрев блоков питания, после чего дал команду всем подчиненным ему серверам работать на минимальной мощности.
Проверили логи остальных контроллеров для пострадавших серверов. Все они с точностью до минуты определили такой же перегрев блоков питания:
Датчики температуры показывали, что температура на блоках питания не поднималась выше 39°C. Получается, что с десяток разных контроллеров одновременно решили, что происходит перегрев блоков питания, хотя на самом деле его не было. Наше предположение — это проблема аппаратной платформы, баг в логике работы.
Одной из версий было, что кто-то взломал IPMI и одновременно дал команду на снижение энергопотребления всем процессорам. Однако, пострадали и новые простаивающие сервера, еще не подключенные в сеть.
Написали запрос в Intel с описанием проблемы, приложив все логи BMC. Интел обещал помочь. Спустя 18 часов, позвонил инженер Intel и сообщил, что зарегистрированы еще аналогичные случаи. Обещали держать нас в курсе новостей. Мы ожидаем одного из двух ответов: либо сообщения о том, что проблема была разовая и больше не повторится, либо обновления BMC для закрытия проблемы.
Решили провести свой эксперимент. На пустой платформе без клиентских серверов перевели время назад, на 6 января, и на следующие сутки, как только часы показали 5:30 проблема повторилась. Поставили на этой платформе дату +3 дня относительно текущего времени. Это поможет заранее узнать о повторении проблемы.
Поиск причин и решение
Проблема проявилась только на платформе Intel S2600BPB с новыми процессорами Intel Silver и Gold. Другие общие характеристики не обнаружились: разные дата-центры, разные версии Linux, разные виртуализации.
Решить проблему в лоб не удалось. Сняли с сервера всю нагрузку (выключили клиентские VDS) — родительский сервер продолжал тормозить. Медленно работал даже интерфейс UEFI. Перезагрузка также не помогала.
Примерно 8 часов ушло на то, чтобы докопаться до сути проблемы. Искали, что связывает все эти случаи. В итоге решить проблему удалось только полным отключением питания. При запуске серверов после 10-минутного простоя проблема исчезает и не повторяется.
Причина сбоя
Чтобы объяснить, в чем дело, придется немного рассказать о физическом устройстве питания серверов.
Сервер получает питание не напрямую. Для группы серверов действует пара блоков питания, работающих параллельно. Управляет подачей питания на все элементы сервера специальное устройство — контроллер BMC, Intel Baseboard Management Controller.
В консоли одного BMC нашли логи:
308 Sun Jan 7 05:31:29 2018 PS1 Status BMC Warning Power Supply Predictive Failure - Over-temperature warning, Status Byte: 0x40 - Asserted
312 Sun Jan 7 05:40:04 2018 PS2 Status BMC Warning Power Supply Predictive Failure - Over-temperature warning, Status Byte: 0x40 - AssertedТо есть контроллер определил перегрев блоков питания, после чего дал команду всем подчиненным ему серверам работать на минимальной мощности.
Проверили логи остальных контроллеров для пострадавших серверов. Все они с точностью до минуты определили такой же перегрев блоков питания:
d0 | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | Asserted
b2 | 01/07/2018 | 05:31:29 | Power Supply #0x50 | Predictive failure | Asserted
a6 | 01/07/2018 | 05:31:29 | Power Supply #0x50 | Predictive failure | Asserted
79 | 01/07/2018 | 05:31:29 | Power Supply #0x50 | Predictive failure | Asserted
62 | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | Asserted
7e | 01/07/2018 | 05:31:29 | Power Supply #0x50 | Predictive failure | Asserted
3d | 01/07/2018 | 05:31:29 | Power Supply #0x50 | Predictive failure | Asserted
3e | 01/07/2018 | 05:31:29 | Power Supply #0x50 | Predictive failure | Asserted
185 | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | Asserted
4d | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | Asserted
53 | 01/07/2018 | 05:31:29 | Power Supply #0x50 | Predictive failure | Asserted
a4 | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | Asserted
ee | 01/07/2018 | 05:31:31 | Power Supply #0x50 | Predictive failure | Asserted
28 | 01/07/2018 | 05:31:31 | Power Supply #0x50 | Predictive failure | Asserted
38 | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | Asserted
91 | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | Asserted
3a | 01/07/2018 | 05:31:31 | Power Supply #0x50 | Predictive failure | Asserted
2c | 01/07/2018 | 05:31:30 | Power Supply #0x50 | Predictive failure | AssertedДатчики температуры показывали, что температура на блоках питания не поднималась выше 39°C. Получается, что с десяток разных контроллеров одновременно решили, что происходит перегрев блоков питания, хотя на самом деле его не было. Наше предположение — это проблема аппаратной платформы, баг в логике работы.
Одной из версий было, что кто-то взломал IPMI и одновременно дал команду на снижение энергопотребления всем процессорам. Однако, пострадали и новые простаивающие сервера, еще не подключенные в сеть.
Написали запрос в Intel с описанием проблемы, приложив все логи BMC. Интел обещал помочь. Спустя 18 часов, позвонил инженер Intel и сообщил, что зарегистрированы еще аналогичные случаи. Обещали держать нас в курсе новостей. Мы ожидаем одного из двух ответов: либо сообщения о том, что проблема была разовая и больше не повторится, либо обновления BMC для закрытия проблемы.
Решили провести свой эксперимент. На пустой платформе без клиентских серверов перевели время назад, на 6 января, и на следующие сутки, как только часы показали 5:30 проблема повторилась. Поставили на этой платформе дату +3 дня относительно текущего времени. Это поможет заранее узнать о повторении проблемы.
0 комментариев
Вставка изображения
Оставить комментарий