Публичная сеть Scaling Droplet

Эволюция масштабируемых, но простых сетевых решений
В DigitalOcean мы гордимся простотой решений, которые мы предлагаем нашим клиентам. И это относится и к нашим сетевым предложениям. На момент написания этой части каждая капля создавалась с общедоступным интерфейсом, который имеет адрес v4 (или необязательный адрес v6), который доступен для общего доступа в Интернете. Между ними нет слоя, подобного тем, что есть в шлюзе NAT. Это приводит к простому взаимодействию с пользователем, которое дает клиентам доступ к их собственным каплям.
Простота предлагаемой сети также влияет на дизайн базового центра обработки данных. Как только пакеты, предназначенные для открытых адресов Droplet, достигают центров обработки данных DigitalOcean, они переключаются непосредственно на гипервизоры и отправляются в сетевой стек Droplet через виртуальный коммутатор, работающий на гипервизоре (Open vSwitch). Обратный путь работает аналогично, когда виртуальный коммутатор гипервизора принимает пакеты от дроплета и перемещает их из сети уровня 2 в базовую инфраструктуру.
Однако по мере масштабирования в течение многих лет эта простая модель стала создавать проблемы производительности и надежности при развертывании и управлении сетевой инфраструктурой — от нехватки адресов IPv4 до ограничений масштабируемости сетей уровня 2.
После почти двух лет итераций мы рады поделиться своим решением этих проблем, а также этапами развертывания новой сетевой модели. В этом выпуске мы рассмотрим наши проблемы с ростом, то, как мы справились с ними, и достижения, достигнутые в этом путешествии.
Первые дни: проблемы масштабирования
Если вы посмотрите на сетевой дизайн одного из наших самых популярных глобальных регионов (например, TOR1), вы увидите простую фабрику CLOS, в которой шлюз по умолчанию Droplet находится на основных коммутаторах, тогда как уровни позвоночника / листа (включая гипервизор) работают как слой простого доступа. Этот дизайн относительно прост в развертывании, настройке и интеграции — что имело смысл в масштабах, в которых DigitalOcean работала с самого начала.

Но у этого дизайна есть ряд недостатков:
Производительность: когда гипервизор или ядро не знают адресата для пакета, он будет делать то, что любая конечная точка будет делать в домене уровня 2, когда ему нужно будет обнаружить адресат для пакета. Он будет передавать запрос на разрешение адреса (используя ARP для IPv4). Это означает, что в больших масштабах сеть начнет перегружаться большим количеством широковещательного трафика или неизвестной одноадресной передачей.
- Устранение неполадок: широковещательный трафик значительно затрудняет устранение неполадок из-за огромного количества конечных точек, участвующих в широковещательной области, что делает нас жертвами пресловутого нахождения иголки в стоге сена.
- Аппаратные ограничения: каждый аппаратный коммутатор имеет ограниченный объем памяти, выделенный для хранения записей MAC для широковещательного домена. В наших самых популярных регионах мы работаем очень близко к физическим ограничениям нашего сетевого оборудования.
- Обширные области сбоев. Несмотря на то, что мы используем избыточную инфраструктуру, отказ одноядерного коммутатора может привести к значительным сбоям из-за того, что протоколы аварийного переключения уровня 2 работают, когда радиус взрыва охватывает весь центр обработки данных.
- Неэффективное использование инфраструктуры: характер уровня 2 «подключи и работай» означает, что сетевое оборудование должно реализовывать эквивалент протокола связующего дерева, чтобы избежать сетевых петель. Предотвращение петель в сети означает, что не все звенья и инфраструктурное оборудование могут или будут использоваться одновременно.
- Ошибки конфигурации. По мере увеличения числа настраиваемых сетей VLAN вероятность неправильной конфигурации многих тысяч коммутаторов, устанавливаемых в верхней части стойки, увеличивается.
Путешествие к нашему решению
Общепринятой отраслевой практикой для решения задач масштабируемости при сохранении мобильности и гибкости для виртуальных машин является виртуализация сети. Это делается путем отделения логического трафика (капли) от физического трафика (гипервизора) в том, что обычно называется разделением наложения и подложки. Наложенный трафик проходит через маршрутизируемую IP-фабрику (чьи пакеты пересылаются по любому протоколу маршрутизации, обычно BGP), в то время как оверлейный трафик проходит по так называемой SDN-структуре, которая может использовать различные протоколы для распределения пакетов и с виртуальных машин. Протоколы в решениях SDN сильно различаются в зависимости от различных факторов, например, от того, используется ли инкапсуляция.
Мы рассмотрели множество факторов в DigitalOcean, чтобы выбрать решение SDN и стратегии интеграции для нашей физической основы. В ходе оценки мы поняли, что никакое решение «под ключ» — ни с открытым исходным кодом, ни с коммерческой — не позволит нам поддерживать низкую совокупную стоимость владения (TCO) при минимальном воздействии на наших клиентов во время подъема и переноса старого оборудования на новое один. Например, инкапсуляция VXLAN (и решения на основе EVPN) была невозможна, потому что значительная часть нашего парка гипервизоров была неспособна к разгрузке оборудования VXLAN — а эксплуатационные расходы, связанные с заменой этих сетевых адаптеров, были непомерно высокими. Нарушение, вызванное туннелированием, было разрушительным с точки зрения сгорания ядер vCPU из-за инкапсуляции / декапсуляции в программном обеспечении и потери скорости линейной скорости. Запуск чистой маршрутизации L3 к хосту был невозможен без суммирования маршрутов, чтобы обойти аппаратные ограничения в таблицах маршрутизации в листах / спинах. Суммирование маршрутов также не могло быть рассмотрено без перестройки нашего уровня планирования вычислений и / или реорганизации существующей рабочей нагрузки клиента.
После значительного анализа ага! Наступил момент: использование коммутации по меткам (а именно MPLS) в сочетании с протоколом уровня 3, таким как BGP, позволило нам обойти аппаратные ограничения в нашей структуре, в то же время получив маршрутизируемое решение для нашей общедоступной сети Droplet. Остальная часть истории была в основном гладкой оттуда. Каждый Droplet v4 (и адреса v6) объявляется как маршрут (ы) BGP в основу подложки от заказного распределенного контроллера SDN, когда они приходят и уходят от гипервизоров. Для этого уровня оркестровки мы полностью использовали возможности открытого источника: BIRD, GoBGP и OVS.
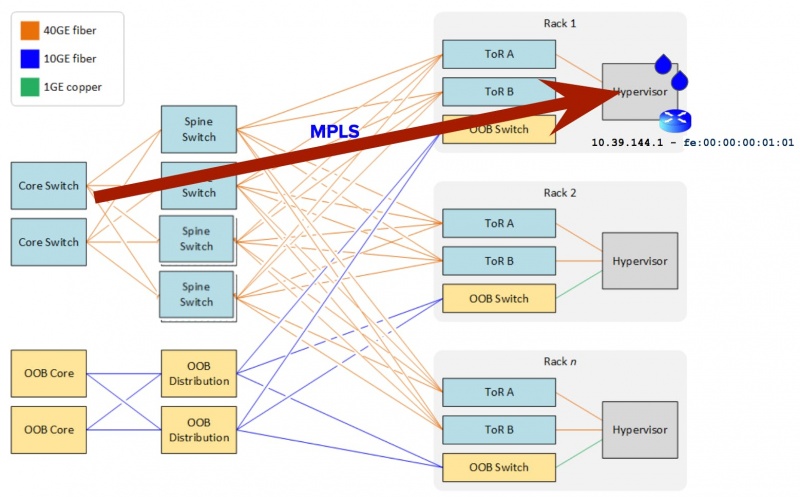
Благодаря усилиям, в которых участвуют несколько команд и которые занимают несколько лет, мы сейчас находимся на последних этапах нашего пути по расширению нашей общедоступной сети Droplet до новых пределов. Проще говоря, мы превратили дизайн слоя 2 в дизайн слоя 3. Каждый гипервизор во флоте теперь действует как шлюз по умолчанию для дроплета. Затем пакеты шаг за шагом пересылаются из ядра через уровни позвоночника и листьев до гипервизора (вместо переключения через уровень 2).
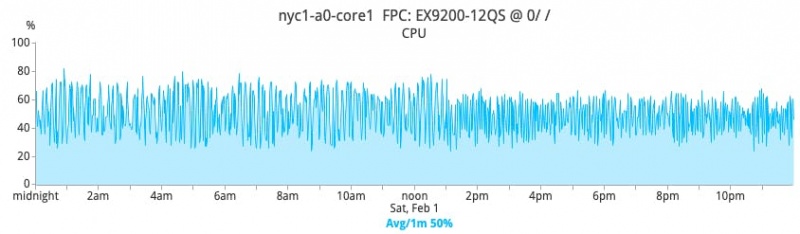
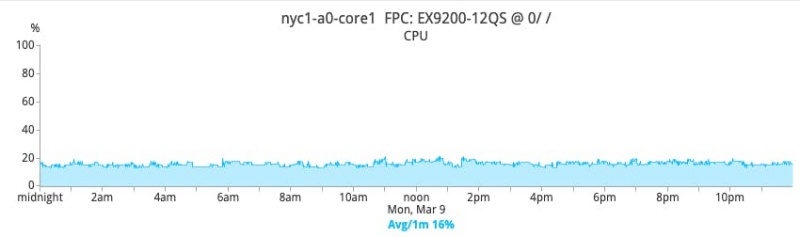
Положительное влияние на сетевое оборудование является глубоким. Например, учитывая резкое сокращение широковещательного и неизвестного одноадресного трафика, который должен обрабатывать сетевой механизм, общее потребление ресурсов ЦП становится значительно более стабильным и значительно снижается. На рисунках ниже показан процент загрузки процессора одним основным коммутатором в NYC1 до и после перехода на уровень 3.
ДО
ПОСЛЕ
Если вы заинтересованы в получении дополнительной информации о сложных деталях решения, эта презентация OVSCon 2019 содержит более подробную информацию о шагах, предпринятых для достижения этого перехода.
Заключительные соображения
В течение последних полутора лет развертывание уровня 3 на нашем флоте было постоянным усилием. Эта часть исследует только верхушку очень большого айсберга. Сегодня следующие регионы поддерживают уровень 3: TOR1, BLR1, NYC1. В течение 2020 года будет развиваться больше регионов. Самой сложной задачей, с которой мы столкнулись как инженерной командой, было изменение архитектуры с минимальными помехами для наших клиентов. Но общий успех этого опыта (хотя и не без икоты) стал исключительной вехой, доказав, что у нас есть ресурсы и опыт для развертывания весьма сложных и инновационных решений! Что еще этот сдвиг означает для наших клиентов? Вы продолжите получать лучшие в своем классе сетевые возможности для своих капель и приложений
0 комментариев
Вставка изображения
Оставить комментарий