TL;DR В статье описывается самый простой способ настроить VPN-сервер, у которого IP-адрес для подключения VPN-клиентов отличается от IP-адреса, с которого клиенты выходят в интернет.
Используете VPN для защиты приватности в интернете и арендуете для этого свой личный сервер? При этом вы единственный клиент, который подключается к этому серверу во всем мире? Так ли сложно найти ваш реальный IP-адрес, как вам кажется? С вступлением в силу пакета Яровой, это становится намного проще.
Double VPN — популярная тема, вокруг которой много спекуляций. Часто этим термином называют совершенно разные технологии, но почти всегда это означает разнесенные на уровне IP-адресов точки подключения и выхода в интернет. Мы рассмотрим самый простой способ настройки VPN-сервера в таком режиме, который не требует дополнительной настройки на серверной стороне и позволяет получить максимальную скорость и самые низкие задержки.
Модель угроз
Для того, чтобы от чего-то защищаться, нужно четко понимать модель угроз. Мы не будем рассуждать о новых законах, требующих от провайдеров хранить весь трафик клиентов, но совершенно точно можно сказать, что данные о подключениях, т.н. Netflow, хранить достаточно просто, и это давно и успешно делается. То есть факт подключения условного IP-адреса 1.1.1.1 к адресу 2.2.2.2 в определенное время суток записывается.
Имея доступ к такой информации в масштабах провайдера, города или страны, достаточно просто установить, кто именно скрывается за VPN.
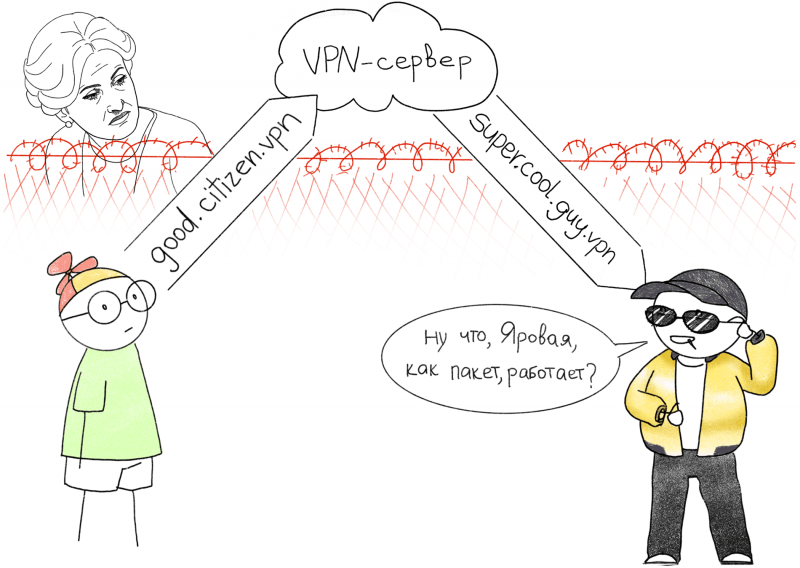
Чтобы повысить уровень приватности при использовании VPN, необходимо разделить точку подключения и точку выхода в интернет на уровне IP. На картинке выше наш пользователь находится за забором под пристальным вниманием Ирины Яровой. Все подключения, проходящие через забор, Ирина строго запоминает. Пользователь, как порядочный гражданин, подключается к адресу good.citizen.vpn, при этом назад он возвращается уже с адреса super.cool.guy.vpn. В итоге для Ирины эти два подключения выглядят не связанными между собой.
Какие бывают двойные VPN
Под названием «двойной» VPN часто понимают разные вещи, но почти всегда это значит разнесенные территориально или на сетевом уровне узлы подключения и выхода в интернет. Иногда это просто маркетинговый трюк VPN-провайдеров, который не значит абсолютно ничего, такие услуги могут называться «тройным» и «четверным» VPN.
Мы разберём самые типовые схемы, которые применяют на практике.
VPN между серверами
Самый распространенный способ. В таком режиме клиент устанавливает VPN-подключение к только первому серверу. На первом сервере настроен тоннель ко второму, и весь трафик от клиента уходит ко второму серверу, и так далее. Промежуточных серверов может быть несколько. При этом тоннель между серверами может быть установлен по любому другому протоколу, отличному от протокола, по которому подключен клиент, например IPsec, или вообще без шифрования, вроде GRE или IPIP. В таком режиме все промежуточные сервера может быть видно в трассировке маршрута. Проверить, как именно подключены между собой промежуточные сервера на стороне клиента нет возможности, поэтому можно только доверять провайдеру.
На всём пути следования трафика минимальный MTU (Maximum transmission unit) остаётся равным значению самого первого тоннеля, и каждый промежуточный сервер имеет доступ к расшифрованному трафику клиента.

VPN через прокси
Тоже достаточно распространённый способ. Часто используется для маскирования VPN-трафика под другой протокол, например в Китае. Такой способ удобнее цепочки из проксей, потому что с помощью VPN легко маршрутизировать весь системный трафик в тоннель. Существуют также инструменты для перехватывания системных вызовов программ и перенаправления их в прокси: ProxyCap, Proxifier, но они менее стабильны, так как иногда пропускают запросы и они уходят мимо прокси или работают некорректно с некоторыми программами.
В этом режиме прокси-сервер не видно в трассировке маршрута.
 VPN внутри VPN
VPN внутри VPN
Самый параноидальный и медленный способ: все тоннели поднимаются на стороне клиента, при этом каждый внутри другого. Такой способ требует хитрой настройки маршрутов на стороне клиента и запуска всех VPN-клиентов в нужном порядке. Это плохо сказывается на задержках и производительности, зато промежуточные сервера не имеют доступа к открытому трафику клиента. Все накладные расходы по инкапсуляции суммируются, и максимальный размер пакета (MTU), доступный в итоге клиенту, уменьшается в зависимости от числа тоннелей. Промежуточные сервера не видны в трассировке маршрутов.
 Настройка VDS
Настройка VDS
Самый лёгкий способ настроить VPN с разделёнными точками входа и выхода — подключить несколько IP-адресов на один виртуальный сервер. Этот способ позволяет получить максимальную скорость и минимальные задержки, так как по сути трафик терминируется на одном сервере. У нас, в Vdsina.ru вы можете это сделать самостоятельно из панели управления. В то время как IPv4 везде кончаются, мы выдаем дополнительные IP-адреса даже на серверах за 60 рублей!
Разберем поэтапно настройку сервера.
Выбираем сервер
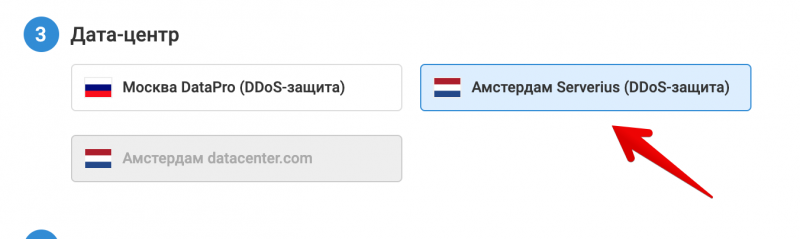
Заказываем VDS с подходящим тарифом, в нужном датацентре. Учитывая нашу задачу, выберем датацентр подальше, в Нидерландах ;)
 Подключаем дополнительный IP-адрес
Подключаем дополнительный IP-адрес
После покупки дополнительного IP-адреса его нужно настроить по
инструкции.
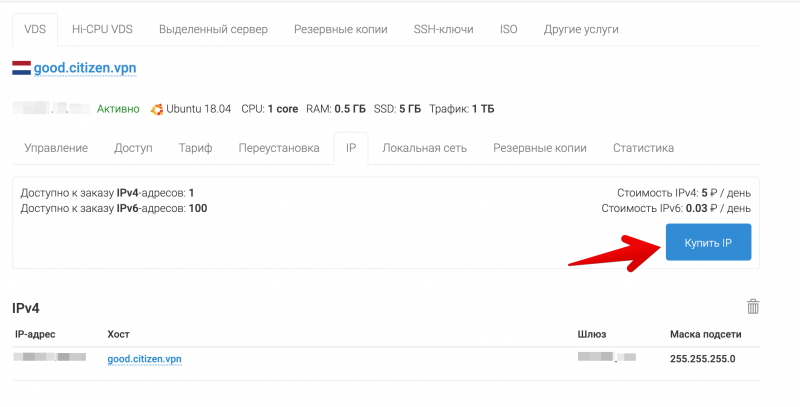
Для наглядности назначим PTR-запись на IP. Это доменное имя, которое будет видно при обратном преобразовании IP-адреса в домен. Это может быть любое значение, в том числе несуществующий домен.
Для примеров будем использовать такие значения:
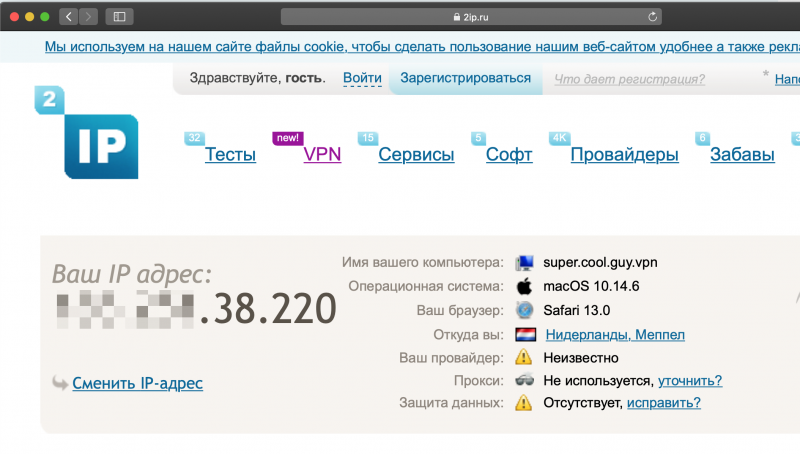
xxx.xxx.38.220 — super.cool.guy.vpn # внешний адрес (точка выхода)
xxx.xxx.39.154 — good.citizen.vpn # адрес подключения (точка входа)
 Проверка двух IP
Проверка двух IP
Важно помнить, что тот IP-адрес, который был установлен на сервере изначально, будет точкой выхода, соответственно новый адрес будет точкой входа. Подключимся по SSH к серверу и проверим, какой адрес используется в качестве внешнего.
Для этого проще всего из консоли использовать сервис ifconfig.co. При запросе через curl он возвращает IP-адрес, с которого был сделан запрос.
$ curl ifconfig.co
xxx.xxx.38.220
По последним цифрам видно, наш внешний адрес действительно соответствует точке выхода. Попробуем проверить корректность работы второго IP в качестве точки входа. Для этого просто используем встроенную в SSH функцию SOCKS-прокси.
Команды выполняются на клиенте:
ssh -D 9999 root@good.citizen.vpn
# в новом окне
curl -x socks5h://127.0.0.1:9999 ifconfig.co
super.cool.guy.vpn
Первая команда устанавливает SSH-сессию с адресом good.citizen.vpn и одновременно активирует SOCKS-прокси внутри этой сессии, который доступен на локальном порту. Вторая делает обычный HTTP-запрос через этот прокси.
Важно помнить, что в наших примерах для запросов используются выдуманные доменные имена. Они будут отображаться только при PTR-резолве, и полноценный запрос к ним сделать не получится. Поэтому на данном этапе обращаться к серверу нужно через IP-адрес.
Настройка сервера IKEv2

IPsec IKEv2 — современный протокол VPN, поддерживаемый почти всеми операционными системами из коробки. Он используется как протокол по-умолчанию в Windows, macOS и iOS. При этом не требует установки стороннего ПО и работает в большинстве случаев быстрее OpenVPN. На хабре уже были статьи по настройке сервера IKEv2, но все они описывают использование самоподписанных сертификатов, и неудобны тем, что требуют установить корневой сертификат на стороне VPN-клиента.
Мы же разберем пример настройки сервера с использованием доверенного сертификата от Let's Encrypt. Это позволяет не устанавливать клиенту посторонние корневые сертификаты, а выдать только логин и пароль.
Подготовка сервера
Мы будем использовать сервер на базе Ubuntu 18.04, но инструкция также подходит для большинства современных дистрибутивов.
Обновляем систему и устанавливаем нужные пакеты
apt update && apt upgrade
apt install certbot strongswan libstrongswan-extra-plugins
Выпуск сертификата
Для выпуска доверенного сертификата вам потребуется направить реальный домен на IP-адрес точки входа. Мы не будем рассматривать этот пункт подробно, так как он выходит за рамки статьи. В качестве примера мы будем использовать вымышленный домен good.citizen.vpn
Если у вас на сервере уже есть есть веб-сервер, используйте подходящий способ выпуска сертификата через certbot или другой клиент для Let's Encrypt. В данном примере предполагается, что порт HTTP (80) ничем не занят.
certbot certonly --standalone --agree-tos -d good.citizen.vpn
Ответив на вопросы мастера? мы получим подписанный сертификат и ключ
# find /etc/letsencrypt/live/good.citizen.vpn/
/etc/letsencrypt/live/good.citizen.vpn/
/etc/letsencrypt/live/good.citizen.vpn/fullchain.pem
/etc/letsencrypt/live/good.citizen.vpn/README
/etc/letsencrypt/live/good.citizen.vpn/cert.pem
/etc/letsencrypt/live/good.citizen.vpn/privkey.pem
/etc/letsencrypt/live/good.citizen.vpn/chain.pem
Для проверки подлинности IKEv2 сервера используются те же X.509-сертификаты, что и для
HTTPS. Чтобы Strongswan смог использовать эти сертификаты, их нужно скопировать в папку /etc/ipsec.d.
Вот как должны быть расположены сертификаты:
cp /etc/letsencrypt/live/good.citizen.vpn/cert.pem /etc/ipsec.d/certs/
cp /etc/letsencrypt/live/good.citizen.vpn/privkey.pem /etc/ipsec.d/private/
cp /etc/letsencrypt/live/good.citizen.vpn/chain.pem /etc/ipsec.d/cacerts/
Так как сертификаты letsencrypt перевыпускаются часто, делать это вручную неудобно. Поэтому автоматизируем этот процесс с помощью хука для certbot.
Задача скрипта скопировать три файла в нужную папку каждый раз, когда сертификат обновился, и после этого послать команду strongswan перечитать сертификаты.
Создадим файл /etc/letsencrypt/renewal-hooks/deploy/renew-copy.sh и сделаем его исполняемым.
#!/bin/sh
set -e
for domain in $RENEWED_DOMAINS; do
case $domain in
good.citizen.vpn)
daemon_cert_root=/etc/ipsec.d/
# Make sure the certificate and private key files are
# never world readable, even just for an instant while
# we're copying them into daemon_cert_root.
umask 077
cp "$RENEWED_LINEAGE/cert.pem" "$daemon_cert_root/certs/"
cp "$RENEWED_LINEAGE/chain.pem" "$daemon_cert_root/cacerts/"
cp "$RENEWED_LINEAGE/privkey.pem" "$daemon_cert_root/private/"
# Reread certificates
/usr/sbin/ipsec reload
/usr/sbin/ipsec purgecerts
/usr/sbin/ipsec rereadall
;;
esac
done
Теперь после каждого перевыпуска сертификата скрипт будет копировать новые файлы в папки strongswan-а и посылать команду демону перечитать сертификаты.
Настройка Strongswan
Добавим конфиг strongswan /etc/ipsec.conf
config setup
# Разрешить несколько подключений с одного аккаунта
uniqueids=no
# Increase debug level
# charondebug = ike 3, cfg 3
conn %default
# Универсальный набор шифров для большинства платформ
ike=aes256-sha256-modp1024,aes256-sha256-modp2048
# Таймауты "мёртвых" подключений
dpdaction=clear
dpddelay=35s
dpdtimeout=2000s
keyexchange=ikev2
auto=add
rekey=no
reauth=no
fragmentation=yes
#compress=yes
# left - local (server) side
leftcert=cert.pem # Имя файла сертификата в папке /etc/ipsec.d/certs/
leftsendcert=always
# Маршруты отправляемые клиенту
leftsubnet=0.0.0.0/0
# right - remote (client) side
eap_identity=%identity
# Диапазон внутренних IP-адресов назначаемых VPN-клиентам
rightsourceip=10.0.1.0/24
rightdns=8.8.8.8,1.1.1.1
# Windows and BlackBerry clients usually goes here
conn ikev2-mschapv2
rightauth=eap-mschapv2
# Apple clients usually goes here
conn ikev2-mschapv2-apple
rightauth=eap-mschapv2
leftid=good.citizen.vpn
Логины и пароли VPN-клиентов задаются в файле /etc/ipsec.secrets
В этом файле также нужно указать имя приватного ключа, который мы ранее копировали из папки letsencrypt:
# Имя файла приватного ключа в папке /etc/ipsec.d/private/
: RSA privkey.pem
# Пользователи VPN
# имя : EAP "Пароль"
IrinaYarovaya : EAP "PleaseLoveMe123"
Mizooleena : EAP "IwannaLoveToo3332"
На данном этапе можно перезапустить сервер strongswan и проверить, активировался ли новый конфиг:
$ systemctl restart strongswan
$ ipsec statusall
Virtual IP pools (size/online/offline):
10.0.1.0/24: 254/0/0
Listening IP addresses:
xxx.xxx.38.220
Connections:
ikev2-mschapv2: %any...%any IKEv2, dpddelay=35s
ikev2-mschapv2: local: [CN=good.citizen.vpn] uses public key authentication
ikev2-mschapv2: cert: "CN=good.citizen.vpn"
ikev2-mschapv2: remote: uses EAP_MSCHAPV2 authentication with EAP identity '%any'
ikev2-mschapv2: child: 0.0.0.0/0 === dynamic TUNNEL, dpdaction=clear
ikev2-mschapv2-apple: %any...%any IKEv2, dpddelay=35s
ikev2-mschapv2-apple: local: [good.citizen.vpn] uses public key authentication
ikev2-mschapv2-apple: cert: "CN=good.citizen.vpn"
ikev2-mschapv2-apple: remote: uses EAP_MSCHAPV2 authentication with EAP identity '%any'
ikev2-mschapv2-apple: child: 0.0.0.0/0 === dynamic TUNNEL, dpdaction=clear
Можно видеть, что конфиг успешно активирован и сертификат подключен. На данном этапе уже можно подключаться к VPN-серверу, но он будет без доступа к интернету. Чтобы выпустить клиентов в интернет, нужно включить форвардинг и настроить NAT.
Настройка NAT
Активируем форвардинг пакетов:
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
sysctl -p
Включаем NAT. Важно иметь в виду, что это просто пример минимальной конфигурации iptables. Настройте остальные правила в зависимости от ваших потребностей.
ethName0 — замените на свое имя интерфейса
10.0.1.0/24 — диапазон IP-адресов который будет выдаваться VPN-клиентам. Мы задавали его в /etc/ipsec.conf
111.111.111.111 — IP-адрес точки выхода, в нашем примере это адрес super.cool.guy.vpn
iptables -t nat -A POSTROUTING -s 10.0.1.0/24 -o ethName0 -j SNAT --to-source 111.111.111.111
Отладка
На данном этапе настройки мы должны получить полностью работающий сервер, к которому уже могут подключаться клиенты. Перед продолжением лучше убедиться в этом, проверив подключение.
В случае проблем с подключением можно смотреть лог в реальном времени:
journalctl -f -u strongswan
Автозапуск при загрузке
Если всё успешно, можно добавить strongswan в автозапуск при загрузке:
systemctl enable strongswan
Сохранение правил iptables
Чтобы сохранить правила iptables после перезагрузки, существует специальный пакет iptables-persistent. Важно помнить, что он сохранит текущий набор правил и добавит его в автозагрузку.
apt install iptables-persistent
Итог
Мы показали самый простой вариант настройки сервера с разнесенными точками входа и выхода. Такая конфигурация позволяет получить максимальную скорость VPN, так как не использует дополнительные тоннели между серверами, при том, что IP-адреса точек входа и выхода находятся в разных подсетях. Такой подход позволяет экспериментировать и дальше, подключив к серверу более двух IP-адресов.
Протокол IKEv2 прекрасно подходит для использования его на десктопных ОС для каждодневной работы, так как максимально нативно интегрирован в систему и при прочих равных, позволяет получить бОльшую скорость, чем через сторонние программы VPN.