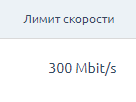
Ryzen 9 3900 - 24vCore 1000р по модели 2020 года

ПУ VM-6 (за 300р подключу ваш сервер в наши бомж кластеры)
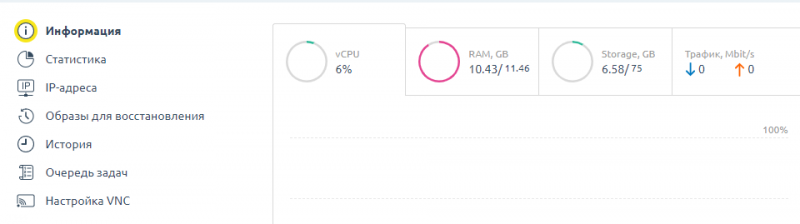
Пока что доступна только HEL1 FI

Как обычно шаг доли — 1000р

Заказывать в панели
asuka.onl
NEW AX61-NVME

Испытайте впечатляющую производительность AMD Ryzen 9 3900 на нашем новом выделенном корневом сервере AX61-NVMe. Его 12 ядер и 24 потока обеспечат быструю работу любых ваших проектов с высокопараллелизуемыми или требовательными вычислительными процессами. Мы установили базовую модель с двумя твердотельными накопителями NVMe для ЦОД объемом 1,92 ТБ, что повысит скорость чтения / записи.128 ГБ ОЗУ ECC AX61-NVMe позволяет обнаруживать и исправлять ошибки, а также обеспечивает повышенную надежность и целостность данных. В целом, эта модель идеально подходит для виртуализации, редактирования видео, кодирования и других случаев использования с высокими требованиями к оперативной памяти.
Мощная производительность AX61-NVMe в вашем распоряжении всего за 84 евро в месяц и единовременная плата за установку в размере 89 евро.
Нужно больше памяти? Нет проблем! С помощью нашего Конфигуратора легко добавить до двух SATA / NVMe SSD или HDD за небольшую ежемесячную плату.
Взять в свои руки один сейчас!
www.hetzner.com/dedicated-rootserver/ax61-nvme/konfigurator
Все цены указаны без учета НДС.
Проблемы с DNS-сервисом 6 и 7 апреля 2020 года

Резюме по инцидентам
6 апреля с 16:51 до 17:40 (в зоне доступности ru-central1-c), 7 апреля с 13:41 до 14:32 (в зоне доступности ru-central1-b) и с 21:03 до 21:29 (в зоне доступности ru-central1-a) по Москве некоторые пользователи Яндекс.Облака сталкивались с недоступностью работы сети на своих ВМ. Во время сбоя резолвинг доменных имён из виртуальных машин, расположенных в соответствующих зонах, работал с перебоями, в ответ на часть запросов DNS-сервера Облака возвращали ответ SERVFAIL или REFUSED. Мы приносим свои извинения всем пользователям, кого затронул данный инцидент, и хотим рассказать подробнее о случившемся и мерах предотвращения повторения подобной ситуации в будущем.
status.cloud.yandex.ru/dashboard
Что произошло?
DNS-сервис Облака состоит из двух частей. Мы называем их Data plane и Control plane. Data plane отвечает непосредственно за резолвинг доменных имён — он получает DNS-запросы от пользователей и возвращает им ответы. Control plane следит за информацией об облаках пользователей (например, о создаваемых и удаляемых виртуальных машинах) и соответствующим образом меняет конфигурацию сервиса Data plane. Сервис Data plane самостоятельно резолвит внутренние адреса облака (например, адреса виртуальных машин и баз данных), остальные запросы рекурсивно отправляет на вышестоящие DNS-сервера Яндекса. Произошедший сбой в зоне ru-central1-c был вызван выходом из строя Control plane.
Причины
На каждой машине в кластере DNS-серверов подняты оба сервиса — и Control plane, и Data plane. Работа серверов практически никак не связана друг с другом, выход строя одного или даже нескольких из них не влияет на работу DNS-резолвинга в Облаке. Сервис Control plane независимо от «соседей» генерирует конфигурацию для своего, локального, сервиса Data plane.
6 апреля в 16:47:05 сервис Control plane на одном из серверов аварийно завершился и перезапустился. В момент запуска сервис Control plane очищает конфигурацию для Data plane, после чего генерирует её с нуля. Это занимает от 5 до 10 минут. После перезапуска он загрузил всю необходимую информацию в себя и приступил к генерации конфигурационных файлов для сервиса Data plane.
В 16:51:05 и 16:51:15 аналогично упали и перезапустились сервисы Control plane ещё на двух серверах. В этот момент дежурные начали разбираться с тем, почему падают сервисы Control plane. К сожалению, падения продолжались — сервисы упали и перезапустились на всех DNS-серверах в зоне ru-central1-c, и продолжали перезапускаться примерно раз в минуту.
Падение одного сервиса вызвало массовое переподключение виртуальных роутеров к копии сервиса на другом сервере, что также приводило к его падению. Таким образом образовалась цепочка циклических падений и рестартов сервисов Control plane на всех серверах. Сервисы Data plane при этом продолжали работать, но так как Control plane очистили при своих рестартах конфигурацию, то в реальности Data plane не выполнял свою работу и отвечал на запросы пользователей кодом REFUSED. К 17:04 дежурным удалось остановить каскад падений сервисов и запустить сервис сначала на одном из них, а к 17:07 — на всех остальных.
Следующие десять минут вновь поднятые сервисы Control plane собирали нужную информацию о сетях и виртуальных машинах и готовили конфигурационные файлы для Data plane. В 17:16 сервисы Data plane начали корректно отвечать на часть DNS-запросов. Постепенно всё большее количество запросов обрабатывались корректно, однако полная работоспособность DNS в ru-central1-c восстановилась только в 17:40. Мы разбираемся, почему этот процесс занял ещё 24 минуты.
О проблеме в сервисе Control plane, которая приводит в падениям, нам было известно уже некоторое время до этого, мы подготовили релиз для его исправления. Релиз, содержащий увеличение этого лимита в 10 раз, выехал в зону ru-central1-a 6 апреля — всё прошло гладко. Через несколько часов мы заметили очередное приближение к лимиту, но только на одном из серверов в этой зоне, остальные показывали запас минимум в 100 раз. Мы решили не блокировать выкладку релиза в другие зоны доступности, а разобраться с этой аномалией позже. Нагрузка на все сервера в кластере идёт одинаковая, и тот факт, что на одном из них вдруг стало использоваться в сто раз больше обработчиков запросов, скорее указывало на проблемы в сервере, чем на проблему в релизе.
7 апреля этот релиз выехал в зону ru-central1-b. Через несколько часов работы, в 13:09, проблема воспроизвелась на одном из серверов и в этой зоне — дежурные начали внимательно изучать, что именно отличает сервера с проблемой от аналогичных серверов без них. Через полчаса, в 13:41, наши мониторинги сообщили, что теперь на всех серверах лимит (увеличенный с релизом в 10 раз) исчерпался. Это было странно, первым делом мы заподозрили, что появилась аномальная нагрузка на наши DNS-серверы. Дежурные начали искать подтверждения этой гипотезе, но ничего не нашли — аномальной нагрузки не было, и тем не менее DNS-сервера рапортовали об исчерпании лимита на обработчики запросов.
В 13:55 дежурные запустили откат релиза на одном сервере в зоне ru-central1-b. Это помогло, и откат запустили на остальных серверах. После стабилизации ситуации в ru-central1-b мы откатили релиз и в ru-central1-a, однако не рестартовали сервисы Data plane — предположили, что из-за меньшей нагрузки в этой зоне и работы в этой зоне в течение суток проблем быть не должно. К сожалению, это предположение было ошибкой.
В 21:03 мониторинги в зоне ru-central1-a аналогично отрапортовали о превышении лимита на всех серверах в этой зоне, что приводило к отбрасыванию части запросов и возвращению кода SERVFAIL. Дежурные постепенно рестартовали сервисы на всех серверах, и ситуация нормализовалась к 21:29. Примерно столько времени занимает плановый рестарт всех DNS-серверов в кластере одной зоны доступности. Как выяснилось позже, причиной проблемы с лимитами стала несогласованность параметров Data plane. Увеличив количество обработчиков рекурсивных запросов, мы оставили прежним количество потоков, в которых они запущены, что и привело к проблемам.
Меры для предотвращения повторения подобной ситуации в будущем:
- Мы предотвратили возможное повторение сбоя — ограничили подключения от виртуальных роутеров до сервисов Control plane и откатили проблемный релиз для Data plane.
- Мы обновили версию Data plane, которая не очищает конфигурацию в случае падения и перезапуска Control plane. Это позволит сохранять работоспособность Data plane даже при полном отказе Control plane.
- В ближайшее время мы обновим версию Data plane, которая при перезапуске попытается сразу начинать работать с конфигурацией, оставшейся до падения. Уже после запуска Control plane поправит конфигурацию в тех местах, где во время недоступности Data plane что-то поменялось. Будем работать над уменьшением времени возвращения связки Control plane + Data plane к полностью рабочему состоянию после падения любого из сервисов.
Новые возможности Битрикс24, которые нельзя пропустить

Две недели назад мы представили вам новый Битрикс24.
Если вы пропустили презентацию Битрикс24.Лондон, то обязательно посмотрите запись. Новые полезные инструменты, смелые прорывные решения и всё, что нужно для бизнеса и его команды сегодня и завтра.
www.youtube.com/watch?v=sCKnWUglWCU
В тот же день мы выпустили улучшенные видеозвонки на 12 человек. Этого ждали многие. Мир на удалённой работе диктует свои требования.
1. Битрикс24 для Windows и Mac
Буквально вчера у вас, наших клиентов, появился обновлённый Битрикс24 для Windows и Mac. Стабильность подключения и качество видеозвонков стали значительно лучше. Проверьте!
helpdesk.bitrix24.ru/open/5562133
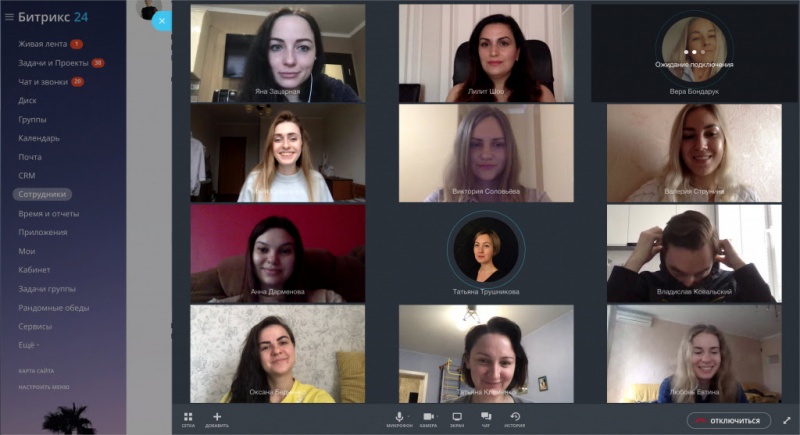
К тому же в Битрикс24 для Windows и Mac (версия 8.2.69.48) появилась уже любимая многими тёмная тема. Не отказывайте в удовольствии: включайте её и работайте комфортно.
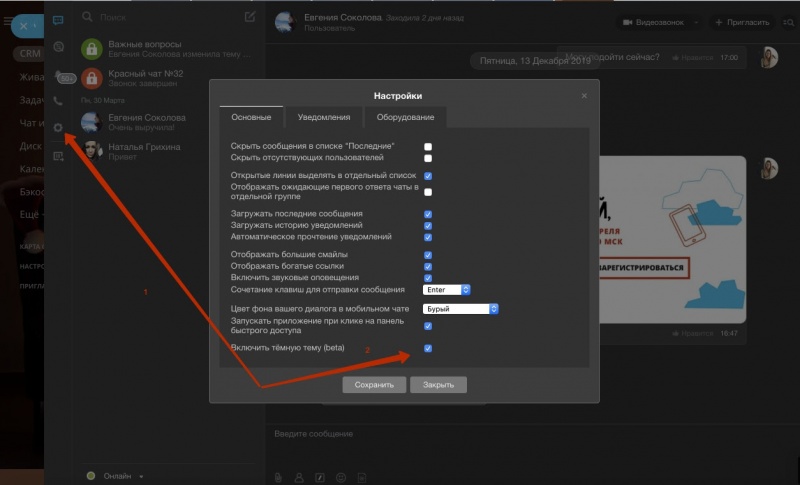
Появился анимированный счётчик сообщений, авторизация внутри Битрикс24 для Windows и Mac, новый API интеграции с 1С и множество других полезных доработок.
Проверьте обновление, если вы уже работает в Битрикс24 для Windows и Mac. И установите себе этого замечательного помощника, если у вас его ещё нет.
www.bitrix24.ru/features/desktop.php
2. Look-alike аудитории.
Попадание в свою целевую аудиторию становится более точечным и надёжным. Битрикс24 передает отобранный вами по каким-либо критериям список контактов из CRM, а рекламные сервисы Facebook и ВКонтакте формируют аудиторию пользователей, похожих на этих ваших клиентов.
Ваша рекламная кампания обещает быть куда более эффективной, чем раньше.
helpdesk.bitrix24.ru/open/10992192
Мы работаем и спешим выпустить ожидаемые вами новинки, как можно быстрее. Следите за информацией. Мы обо всём вам расскажем незамедлительно.
Спасибо, что вы с нами! ❤️
С любовью и уважением
ваша команда Битрикс24
New Infra-3: 1x AMD Epyc 7402, 24c/48t/2.8GHz-3.35GHz


Подарки и скидки до 50% в честь 11-летия компании

Подарки и скидки до 50% в честь 11-летия компании
Сегодня компании Friendhosting LTD исполняется 11 лет. По современным меркам интернета 11 лет это не просто длительный период времени, это целая жизнь. Мы испытываем одновременно радость и гордость, идя по этой жизни вместе с вами.
Нам очень приятно видеть какую популярность за это время получили наши услуги в IT сообществе, как вы цените стабильную работу серверов и нашу круглосуточную дружелюбную техническую поддержку. Разумеется, это не было бы возможным без вас, наши дорогие друзья – клиенты, коллеги и партнеры. Большое вам спасибо!
В честь дня рождения компании мы приготовили для вас следующие скидки и бонусы, которые будут действовать с 20.04.2020 до 20.05.2020.
friendhosting.net/promo/11year.php
1. «Скидка 50%». Экономьте до 50% при заказе нового vds или виртуального хостинга на срок от одного до шести месяцев. Для получения скидки во время заказа используйте промо-код 11year
friendhosting.net/virtual-hosting.php
friendhosting.net/vps.php
2. «Плюс 100%». Мы увеличим оплаченный период любого нового заказа vds или виртуального хостинга, сделанного во время акции, в два раза (максимальное количество бонусных месяцев — 6). Для получения бонуса необходимо создать запрос в финансовый отдел после оплаты заказа.
3. «Старый друг лучше новых двух». Что может быть лучше, чем увидеть старого друга в свой день рождения? Для вас, старые друзья, мы приготовили следующие подарки:
- увеличение оплаченного периода vds или виртуального хостинга в два раза (максимальное количество бонусных месяцев — 6);
- восстановление скидки по программе лояльности 15% для каждого сделанного заказа в период проведения акции.
Условия акции «Старый друг лучше новых двух»:
- ранее вы уже были нашим клиентом, но по каким-то причинам отказались от дальнейшего использования наших услуг;
- заказ необходимо сделать с того аккаунта, где ранее был заказ;
- для получения бонуса «старый друг лучше новых двух» необходимо создать запрос в финансовый отдел после оплаты заказа.
4. Бонус за продление VDS. Уже есть заказ VDS? Продлите его на длительный период и получите бонус. Если во время проведения акции Вы продлите vds на:
- 6 месяцев, то получите в подарок 1 месяц оплаченного периода. Скидка в 5% за продление на 6 месяцев и скидка по программе лояльности до 25% будут учтены автоматически;
- 12 месяцев, то получите в подарок 2 месяца оплаченного периода. Скидка в 10% за продление на 6 месяцев и скидка по программе лояльности до 25% будут учтены автоматически;
Не упустите шанс сделать новый заказ или продлить уже существующий с большой скидкой.
- Акция проходит с 20.04.2020 по 20.05.2020 года включительно.
- Внимание! Скидки и бонусы НЕ могут суммироваться.
https://my.friendhosting.net
Яндекс.Облако и NVIDIA совместно поддержат ИИ-стартапы
Акселерационные программы Yandex Cloud Boost и NVIDIA Inception договорились о взаимной поддержке для своих участников. С апреля 2020 года компании-разработчики в области искусственного интеллекта из NVIDIA Inception могут присоединиться к Cloud Boost по упрощенной процедуре. В свою очередь, ИИ-стартапы Cloud Boost получают доступ к ресурсам NVIDIA Inception на приоритетных условиях.
Что получает компания-участник NVIDIA Inception, присоединившись к программе Yandex Cloud Boost
- Грант от 200 000 руб. (с НДС) на тестирование и использование инфраструктурных сервисов и сервисов Data Storage & Analytics, Cloud-Native, ML & AI: при этом половину гранта, а не четверть, как это предусмотрено стандартными условиями программы, можно потратить на ресурсы с GPU;
- помощь архитекторов в развертывании инфраструктуры на платформе Яндекс.Облако;
- скидку 20% на год на сервисы Data Storage & Analytics и Cloud-Native;
- бесплатную техническую поддержку;
- доступ к закрытому тестированию новых сервисов;
- содействие в продвижении продукта.
Что получает стартап в Yandex Cloud Boost, присоединившись к NVIDIA Inception
- доступ к технологиям: программным инструментам, отдельным графическим процессорам NVIDIA и вычислительным системам линейки NVIDIA DGX;
- бесплатный доступ ко всем онлайн-курсам в Институте глубокого обучения NVIDIA;
- рекомендации по выбору приложений и оборудования на GPU;
- специальные цены на оборудование;
- маркетинговую поддержку.
Специальное предложение от Yandex Cloud Boost и NVIDIA Inception ориентировано на компании, которые ведут работы в области изучения и применения искусственного интеллекта. Теперь сотни стартапов-участников акселерационных программ получат доступ к ресурсам и сервисам для полноценного тестирования AI-проекта.
Как стартапу воспользоваться специальным предложением от Yandex Cloud Boost и NVIDIA Inception
Компании-участнику NVIDIA Inception необходимо заполнить заявку на сайте Yandex Cloud Boost, указав в комментариях кодовое слово «NVIDIA».
Компании-участнику Yandex Cloud Boost нужно оставить заявку на странице NVIDIA Inception, в разделе «Which accelerators/incubators are you currently part or have you been part of?» указав программу Yandex Cloud Boost.
Запросы автоматически получат менеджеры соответствующих программ лояльности и откроют доступ к привилегиям.
По всем вопросам, связанным с данным предложением, просьба обращаться к Марине Поликарповой: marinapolik@yandex-team.ru
Новый сайт и вкусное предложение VPS с поддержкой!

2020 год стал для всех нас годом перемен. Решили обновиться и мы!
Встречайте наш новый сайт, а также вкусное предложение для всех тех, кто уже пользуется виртуальными серверами, либо хочет на них перейти.
Новый, свежий и лёгкий!
Всё это про наш обновлённый веб-сайт. Мы постарались совместить максимум полезной информации о наших услугах с простотой во внешнем виде, так, чтобы Вы смогли легко и просто выбрать подходящее Вам решение.
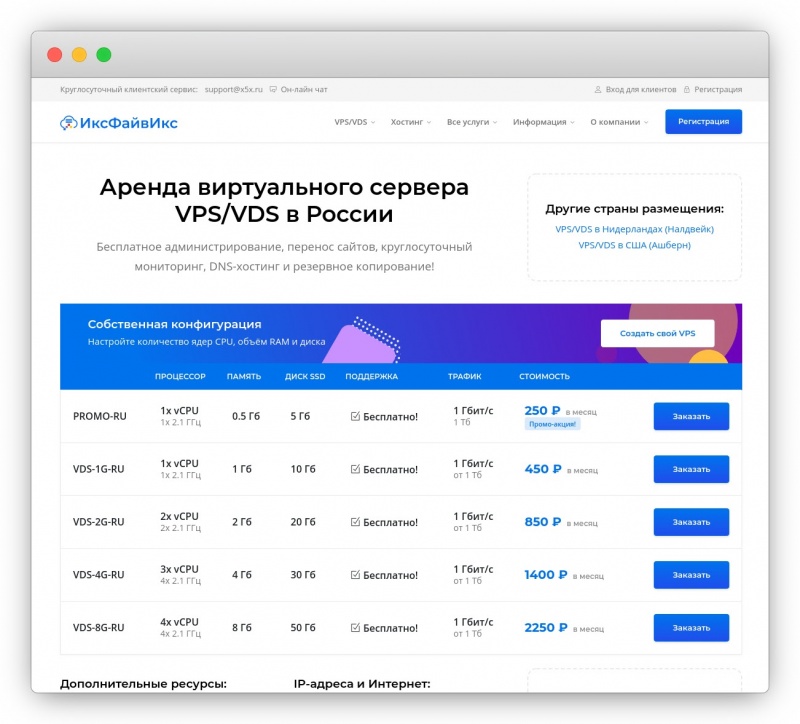

x5x.ru/vps.html
Яндекс.Облако открывает доступ к анализу данных по самоизоляции и распространению коронавируса
Платформа Яндекс.Облако открывает доступ к инструменту для работы с данными по распространению коронавируса в России и мире.
С помощью технологии Yandex DataLens мы собрали в единую информационно-аналитическую панель (дашборд) информацию из трёх источников:
- Роспотребнадзор: статистика о количестве заражений, выздоровлений и летальных исходов в России;
- Университет Джонса Хопкинса: аналогичные данные по всему миру;
- данные сервисов Яндекса: индекс самоизоляции.
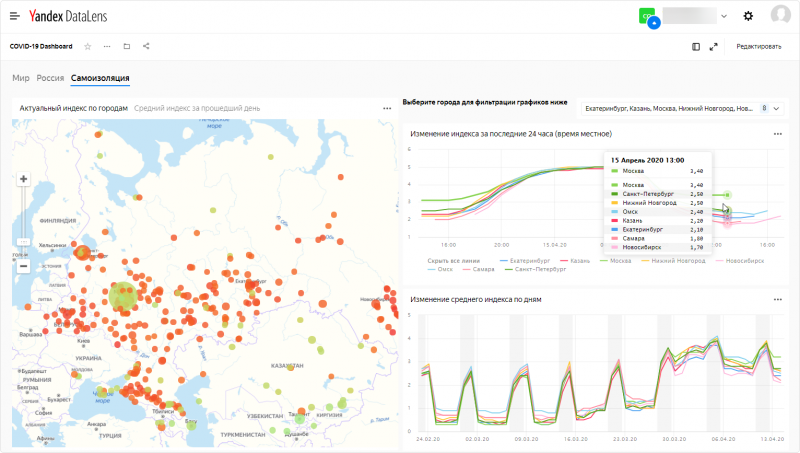
Yandex DataLens позволяет гибко работать с данными: загружать, объединять, мгновенно делать наглядные визуализации — графики, диаграммы, таблицы, а также накладывать показатели на карту. В дополнение к данным, которые предоставляет Яндекс.Облако, пользователи могут подключать собственные источники. Полученными результатами можно делиться с коллегами и публиковать их в открытом доступе на любых внешних ресурсах. Все данные обновляются в режиме реального времени: как только новая информация появляется в источниках, она становится доступна в Yandex DataLens.
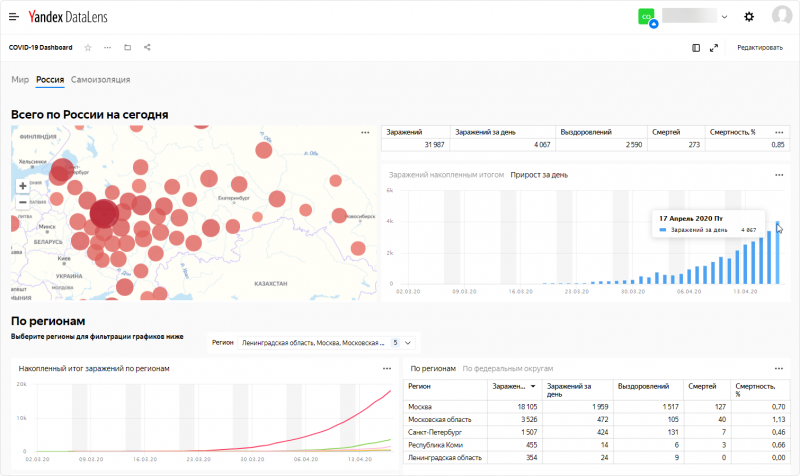
Данные по распространению коронавируса в России доступны с детализацией по регионам. Для индекса самоизоляции представлен исторический срез средних дневных значений по городам с 23 февраля 2020, а также актуальные данные по часам за последние сутки.
Изучить публичный дашборд можно по ссылке datalens.yandex/covid19
Если вы хотите сохранить себе копию дашборда, изменить её, создать собственные визуализации или дополнить своими данными — нужно завести учётную запись в Yandex DataLens и импортировать пресет из маркетплейса.
Для работы с этим пресетом достаточно бесплатного тарифа Yandex DataLens.