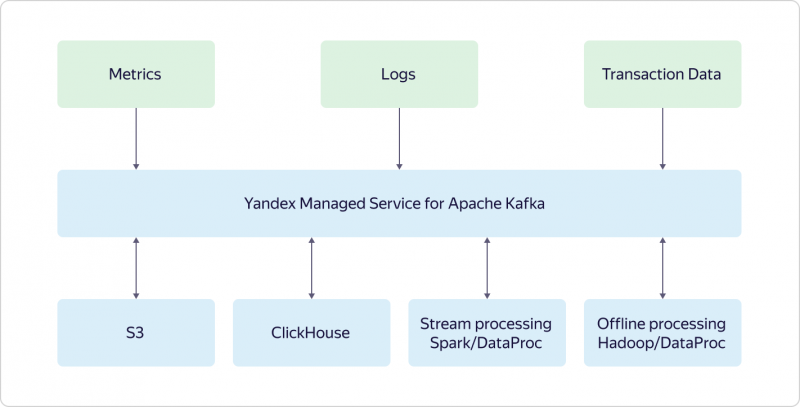
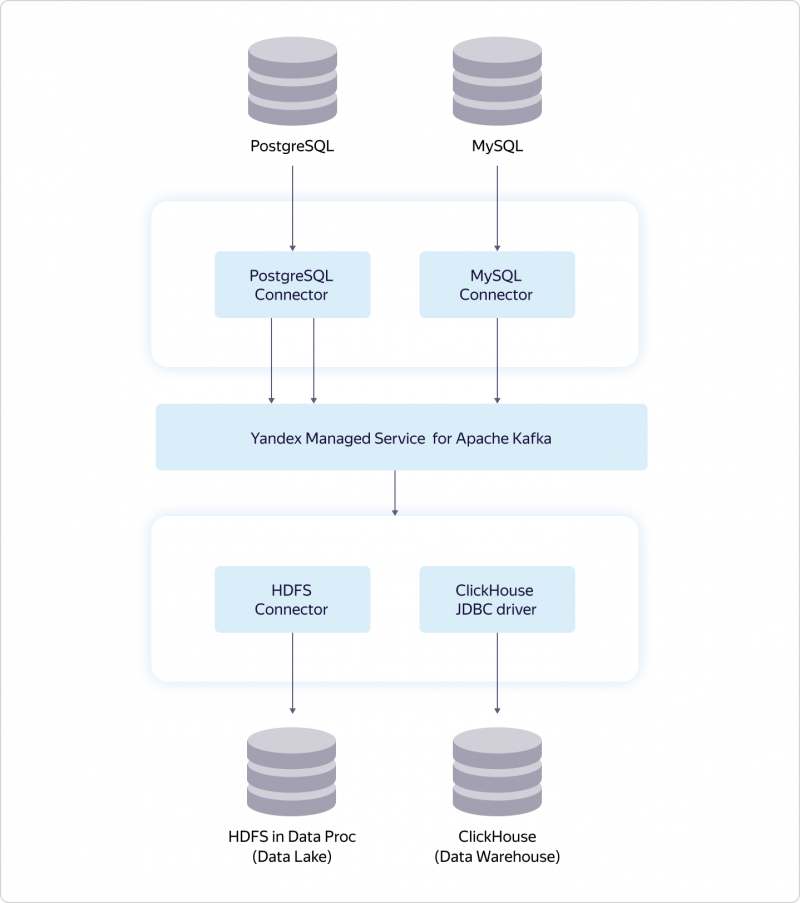
Мы с гордостью сообщаем, что выпустили новую версию SolusIO, SolusIO v1.1.11382. Эта версия предоставляет некоторые приятные улучшения и новые функции.
Вы можете найти примечания к выпуску для каждой версии в разделе документации. Мы рекомендуем вам регулярно посещать заметки о выпуске, чтобы узнать об обновлениях.
Новые особенности
SolusIO анонсировал новую функцию: тип маршрутизируемой сети для блока IP
Тип маршрутизируемой сети для блока IP
Администратор может выбрать тип сети на странице добавления / редактирования IP-блока.
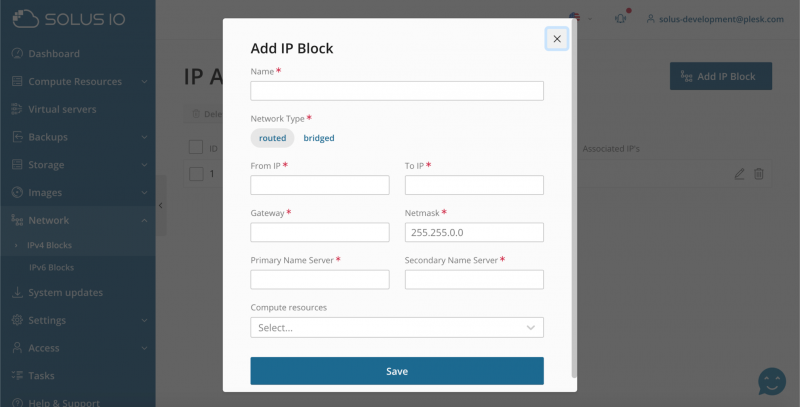 Routed
Routed
Используйте маршрутизируемую сеть, если вам нужно использовать весь диапазон IP-адресов, предоставленных вашим хостинг-провайдером.
Маршрутизируемая сеть означает, что виртуальные серверы не подключаются напрямую к физической сети. Операционная система вычислительного ресурса направляет трафик серверов в физическую сеть (вычислительный ресурс работает как шлюз). Если вы выбираете маршрутизируемую сеть, MAC-адрес сервера не отображается в физической сети.
Мостовой
Мостовая сеть означает, что виртуальные серверы получают прямой доступ к физической сети. В мостовой сети IP-адреса сервера и шлюза должны находиться в одной IP-сети. Например, если IP-адрес шлюза 192.168.1.1 находится в IP-сети 192.168.1.0/24, то IP-адрес сервера также должен находиться в сети 192.168.1.0/24 (например, 192.168.1.2). Если вы выберете мостовую сеть, MAC-адрес сервера будет открыт для физической сети.
Подробности здесь:
docs.solus.io/en-US/latest/quickstart/administration/7-setting-up-sending-out-email-notifications.3/#adding-an-ip-block
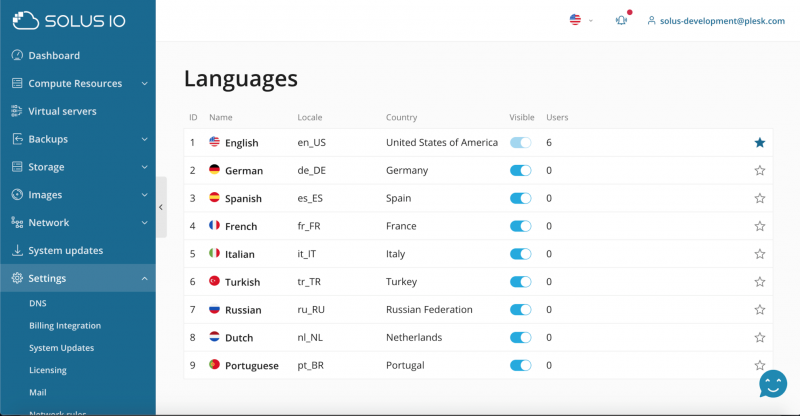
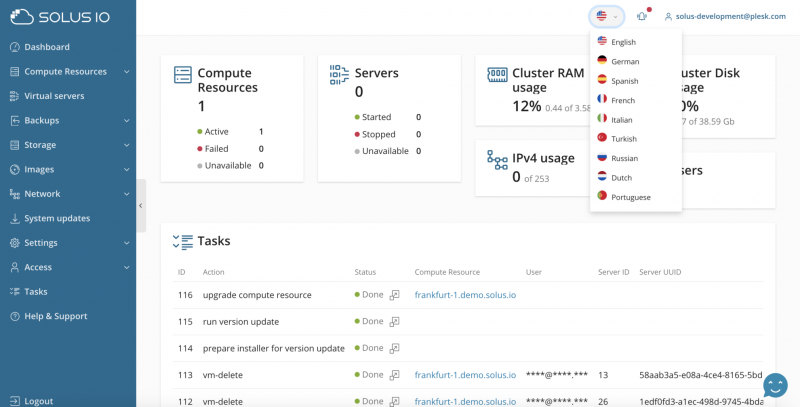
В дополнение к маршрутизируемой сети для блока IP, мы рады объявить о поддержке японского языка.
Поддержка японского языка
Добавлена поддержка японского языка.
 улучшения
улучшения
- Уведомления по электронной почте были переведены: конечные пользователи теперь могут получать уведомления на своем языке.
- Добавлена новая красивая страница для функций в разработке.
 Исправление ошибок
Исправление ошибок
- Исправлена проблема, когда виртуальные серверы зависали при загрузке на хосте с Debian 10 или Ubuntu 20 из-за неправильной модели контроллера SCSI.
- Университет Плеска
Не забудьте: профессиональный курс SolusIO доступен! Узнайте, как предложить масштабируемый интерфейс PublicCloud, основанный на API и самообслуживании, для разработчиков и предприятий, использующих существующую инфраструктуру. Подпишите здесь!
university.plesk.com/catalog/info/id:378
Курс охватывает следующие темы:
- Планирование инфраструктуры SolusIO
- Развертывание главного сервера SolusIO
- Добавление вычислительных ресурсов
- Настройка предоставления
- Предоставление виртуальных серверов
Общее время: 2 часа
Дорожная карта
Дорожная карта SolusIO теперь публично доступна на Trello. Мы будем обновлять его как можно чаще, добавляя новую информацию, чтобы вы всегда знали, что у нас на уме и что будет дальше!
Мы приглашаем вас представить свои идеи для запросов функций нашей команде по продукту. Чтобы отправить запрос функции, поделитесь своими идеями — не стесняйтесь вносить предложения или отправлять запросы функций.
Мы также рады помочь вам в достижении ваших целей, поскольку вы осваиваете новые способы работы и более эффективно конкурируете, наша команда по продажам в вашем распоряжении.
www.solus.io/roadmap/
trello.com/b/bizBnbE9/solusio-roadmap
features.solus.io/
www.plesk.com/contact-us/