Это дайджест Selectel — рассказываем, как меняются наши услуги, что нового происходит в компании и какие статьи мы подготовили для вас за прошедший месяц. В этом выпуске вы узнаете о запуске портала документации API и апдейте «Облачных баз данных». Обязательно дочитайте письмо до конца — там вас ждет приглашение на онлайн‑прогулку по нашему дата‑центру.
Как мы проводим лето
Выкатили портал документации API
Главный релиз месяца: мы запустили портал документации API наших продуктов и услуг. Раньше мы выдавали такую информацию по запросу и частично в панели управления, но параллельно работали над отдельным публичным сервисом. По итогу создали портал для разработчиков, на котором собираем необходимые знания по автоматизации IT‑инфраструктуры и взаимодействию с бэкендом, — часть документации уже добавили, но будем дополнять еще.

Портал документации, вместе с базой знаний, составляют единое пространство — удобный справочный центр. В базе знаний вы познакомитесь с основными концепциями продукта и инструкциями по началу работы с сервисом. На портале для разработчиков вы найдете документацию API к нашим продуктам — она поможет автоматизировать управление вашей IT‑инфраструктурой и интегрировать продукты Selectel в сторонние сервисы. Например, если у вас есть приложение, с помощью API вы можете ресейлить «Облачную платформу Selectel» или настраивать системы мониторинга.
developers.selectel.ru
Завезли новые комплектующие для серверов
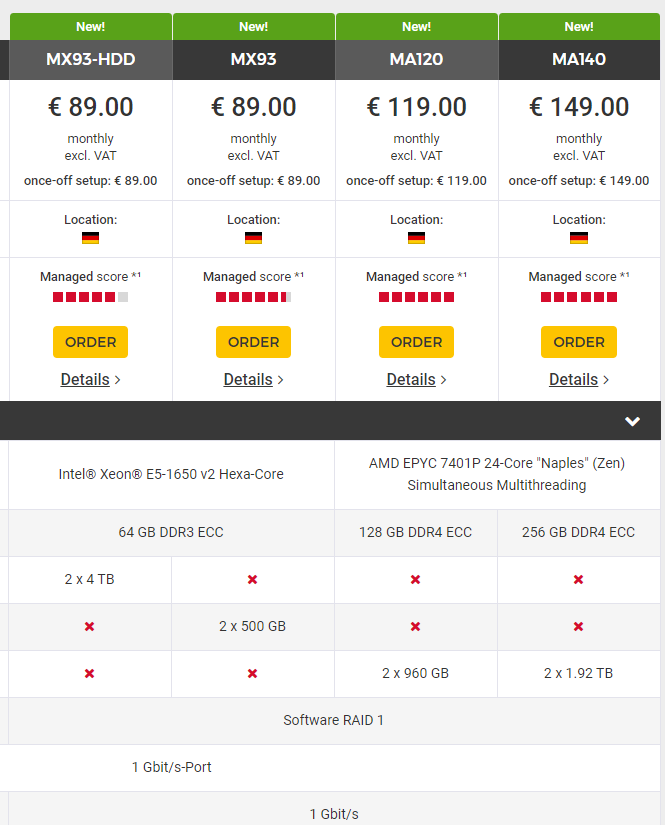
В июле появилось новое «железо» для выделенных серверов произвольных конфигураций — например, к нам пришли планки памяти 32 ГБ DDR4 ECC. Это значит, что теперь конфигурации на процессорах Intel Xeon E могут комплектоваться до 128 ГБ памяти, что отлично подойдет для обработки больших объемов данных.
Еще из нового — процессор Intel Xeon Gold 5218R (2,1 ГГц, 20 ядер) и диск 7 680 ГБ SSD NVMe. Процессор подойдет для задач, в которых количество потоков важнее производительности каждого потока, — как в тестовых средах и VDI. А с новым SSD вы получите пространство для хранения и быстрой обработки больших массивов данных — подойдет для хранения и раздачи медиаконтента.
my.selectel.ru/servers/home/
Добавили расширения PostgreSQL в «Облачных базах данных»
Теперь вы можете самостоятельно включить необходимые расширения баз данных PostgreSQL в панели my.selectel.ru. В личном кабинете доступно более 30 модулей, которые позволяют работать с разными типами данных: хранить JSON и геоинформационные данные, работать с математическими вычислениями и другими важными для вас запросами. Так что если вы используете on‑premise‑инстансы СУБД и разные расширения PostgreSQL, можете смело мигрировать на наши Managed Databases.
selectel.ru/services/cloud/managed-databases/
Подняли оперативку в «Облачных функциях»

«Облачные функции» стали еще более гибкими. Добавили возможность менять количество зарезервированной оперативной памяти, чтобы вы могли быстрее обрабатывать больше данных — это часто требуется при работе с фото и видео. Вы можете выбрать любое необходимое вам количество памяти: 256, 512 или 1 024 МБ. В ближайшем будущем в продукте появится возможность вызова функции: по событию в GitHub‑репозитории (например, при создании нового пул-реквеста) и по расписанию (для актуализации данных в БД, организации простых ETL‑процессов и отправки рассылок).
selectel.ru/services/cloud/serverless/
Расширили настройки CDN
Как и обещали, добавили новые механизмы ограничения доступа в CDN:
- Geo ACL позволяет ограничить доступ к контенту любым странам на выбор. Опция полезна в ситуациях, когда в конкретной стране нет вашей целевой аудитории, а контент туда раздается. Ограничивая доступ этой стране, вы сможете сократить расходы на CDN‑трафик и сфокусироваться на пользователях, которым действительно интересен ваш проект.
- Tokenized URL — хеш‑ключ, который защищает контент от нежелательных загрузок. Например, с его помощью можно раздавать контент только тем пользователям, которые за него заплатили. Это позволит вам фильтровать аудиторию и прогнозировать собственную прибыль.
А чтобы вы больше не путались в HTTP‑заголовках, мы настроили возможность задавать собственные заголовки в панели управления — CDN‑сервер добавит их в запрос при обращении к источнику.
Настройте CDN так, как удобно вам
my.selectel.ru/cdn/home
Selectel — Principal Partner VMware
Облако на базе VMware
Дальше уже некуда — мы получили статус Principal Partner Cloud Provider от VMware. Это значит, что мы найдем для вашего бизнеса идеальный мэтч с решениями от VMware и поделимся лучшими в своем классе возможностями для развертывания инфраструктуры.
Познакомьтесь с нашим «Облаком на базе VMware»
selectel.ru/services/cloud/vmware/
Все на Слёрм
19 и 21 августа уже в привычном и почти любимом онлайне наши друзья‑партнеры Southbridge проводят «Слёрм DevOps: Tools&Cheats». Это интенсив, где 20% времени будут говорить про философию и культуру DevOps, а 80% — про инструменты и их применение. Курс будет полезен администратору Linux или разработчику, который хочет изменить свою работу к лучшему. Selectel предоставляет серверы для практики. И, что еще приятнее, дает скидку 10% по промокоду «Selectel».
Регистрируйтесь на Слёрм
slurm.io/devops/