До Нового года осталось всего три дня. Мы с коллегами уже поделились на два лагеря — одна половина пытается успеть неуспеваемое, а другая поймала предпраздничный дзен и поглощает мандаринки с новогодней колой.

Если вы ещё в работе — держитесь, мы с вами! В перерыве между задачами предлагаем полистать последний в этом году дайджест и узнать новости декабря. В честь Нового года мы кое-что для вас приготовили, но давайте по порядку :)
Статьи и инструкции
Как подключить HTTP/2 на сервере
Протокол HTTP/2 позволяет ускорить загрузку сайта и увеличить производительность за счёт одновременного выполнения множества запросов в рамках одного соединения. В новой статье мы рассмотрим порядок подключения HTTP/2 на вашем виртуальном сервере.
Как подключить HTTP/2 на сервер
 Разбираемся в новой архитектуре и тестируем Intel Core i9-12900K
Разбираемся в новой архитектуре и тестируем Intel Core i9-12900K
Недавно Intel выпустила долгожданную новинку — Core i9-12900K на новой архитектуре Alder Lake. Предполагалось, что выход этого процессора может стать наиболее значимым шагом для Intel со времён появления Core в 2006 году. Мы внимательно изучили характеристики Core i9-12900K, протестировали его и сравнили с другими процессорами из линейки Core i9, чтобы узнать, удалось ли Intel совершить прорыв.
«Препариуем» Intel Core i9-12900k: 10 нанометров, гибридная архитектура и новая память
Habr: самое интересное за декабрь
А вот и новая подборка статей из нашего блога на Хабре. Не забывайте подписываться — готовим для вас интересные статьи каждую неделю. В новогодние каникулы тоже будем, чтобы вы не заскучали :)
Новости
А теперь к новостям декабря.
 Отметили день рождения FirstVDS
Отметили день рождения FirstVDS
Праздновать мы привыкли с размахом, вот и в этот раз отмечали целую неделю. Делились фактами о себе и о вас, дарили сертификаты за решение загадок на стриме, а самое главное — подготовили и провели масштабный розыгрыш. К концу акции в призовом фонде накопилось почти 600 000 рублей, мы купили классные подарки на всю сумму и разыграли между участниками.
firstvds.ru/blog/itogi-akcii-v-chest-19-letiya-firstvds
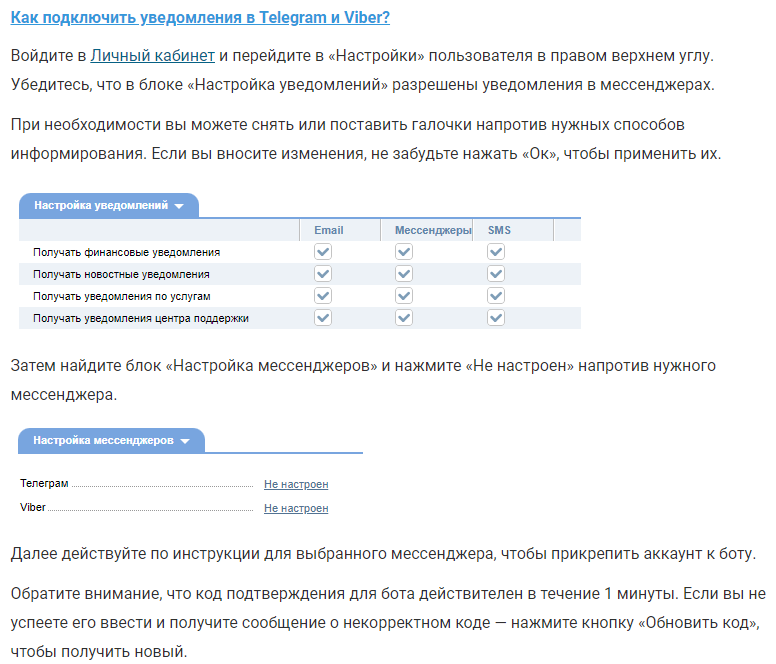
 Добавили уведомления об услугах в Telegram и Viber
Добавили уведомления об услугах в Telegram и Viber
Теперь вы можете получать уведомления об услугах не только по SMS или почте, но и в мессенджерах Telegram и Viber — отправлять их будет специальный бот. При необходимости можно подключить к одному аккаунту сразу оба мессенджера или использовать одного бота для уведомлений на нескольких аккаунтах.
firstvds.ru/blog/poluchayte-uvedomleniya-ob-uslugah-v-telegram-i-viber
Не забудьте продлить услуги перед праздниками
Напоминаем, что в праздники банковские переводы могут «зависнуть» на несколько дней, поэтому услуги лучше продлить заранее.
Акции
Пора открывать подарки!
 С Новым годом, новым счастьем и новыми VDS
С Новым годом, новым счастьем и новыми VDS
В преддверии главного праздника в году приготовили для вас кое-что приятное: -15% на заказ новых VDS до конца января. Недавно мы обновили тарифную линейку, поэтому сейчас идеальный момент, чтобы заказать более мощный и выгодный сервер с новогодней скидкой.
firstvds.ru/blog/novogodnyaya-akciya-15-na-zakaz-vds-i-sertifikaty-na-popolnenie-balansa
CLO: бесплатный тест или +500 рублей к первому платежу
Акция на проекте CLO подходит к концу, успейте воспользоваться предложением до 31 декабря. Оставьте заявку на бесплатный трехдневный период или пополните баланс минимум на 500 рублей и получите ещё 500 рублей в подарок по сертификату CASH.
clo.ru/welcome-bonus
Выгодные предложения от FirstDEDIC
Для тех, кто ищет помощнее — скидки на выделенные серверы на сайте FirstDEDIC.
Скидка 20% на серверы с Intel Core и AMD Ryzen
Чтобы в Новом году переехать на более мощный и дешевый сервер — успейте принять участие в акции от FirstDEDIC. Соберите гибкую конфигурацию на базе процессора Intel Core или AMD Ryzen и получите скидку 20% на весь период оплаты — 1, 3, 6 или 12 месяцев. Серверов осталось не так много, долго не раздумывайте!
1dedic.ru/content/prodlevaem-akciyu-20-na-servery-s-intel-core-i-amd-ryzen
Уязвимости
Уязвимость в Apache Log4j
В Apache Log4j 2 выявлена уязвимость, позволяющая выполнить произвольный код при записи в лог специально оформленного значения. Злоумышленник может атаковать Java-приложения, записывающие в лог значения из внешних источников. Чтобы закрыть уязвимость, было выпущено обновление 2.15, но нашелся способ его обойти, поэтому разработчики выпустили версии 2.16 и 2.12.2.
www.opennet.ru/opennews/art.shtml?num=56347
Уязвимости в Grafana
В Grafana нашли уязвимость, которая позволяет злоумышленнику выйти за пределы базового каталога и получить доступ к произвольным файлам в локальной файловой системе. Уязвимость закрыли в обновлениях 8.3.1, 8.2.7, 8.1.8 и 8.0.7, но затем были обнаружены ещё две похожие уязвимости. Проблема была решена в версиях 8.3.2 и 7.5.12.
www.opennet.ru/opennews/art.shtml?num=56329
Уязвимости в каталоге PyPI
В каталоге PyPI обнаружены три библиотеки, содержащие вредоносный код. Пакеты dpp-client и dpp-client1234 включали код для отправки содержимого переменных окружения, а в aws-login0tool выявлен код для запуска троянского приложения. Сейчас проблемные пакеты уже удалены, однако их успели скачать около 15 тысяч раз.
www.opennet.ru/opennews/art.shtml?num=56337
Уязвимость в USB Gadget, подсистеме ядра Linux
В USB Gadget, подсистеме ядра Linux, выявлена уязвимость, позволяющая злоумышленнику получить информацию из ядра, выполнить произвольный код или инициировать крах ядра. Проблема решена в обновлениях ядра Linux 5.15.8, 5.10.85, 5.4.165, 4.19.221, 4.14.258, 4.9.293 и 4.4.295. В дистрибутивах уязвимость пока не закрыта.
www.opennet.ru/opennews/art.shtml?num=56357