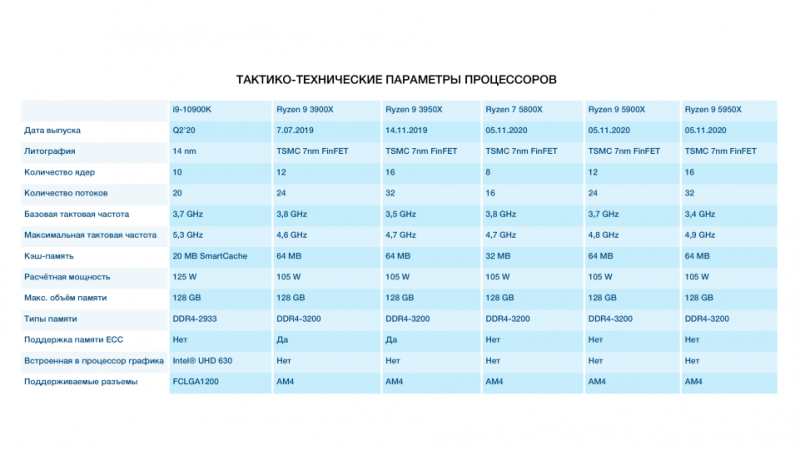
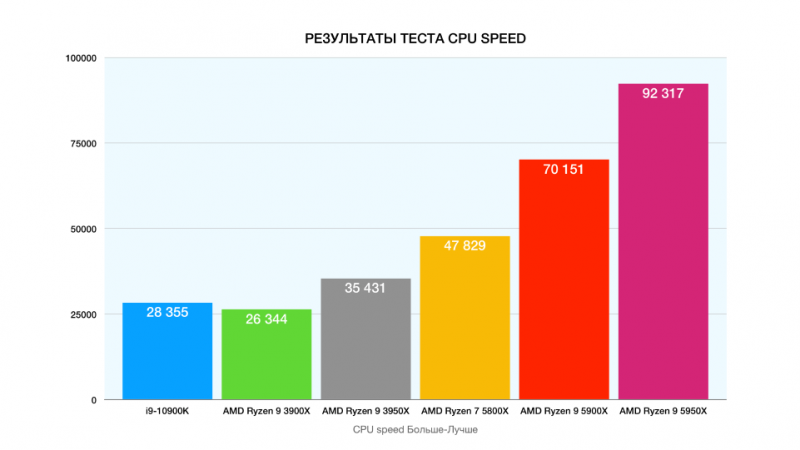
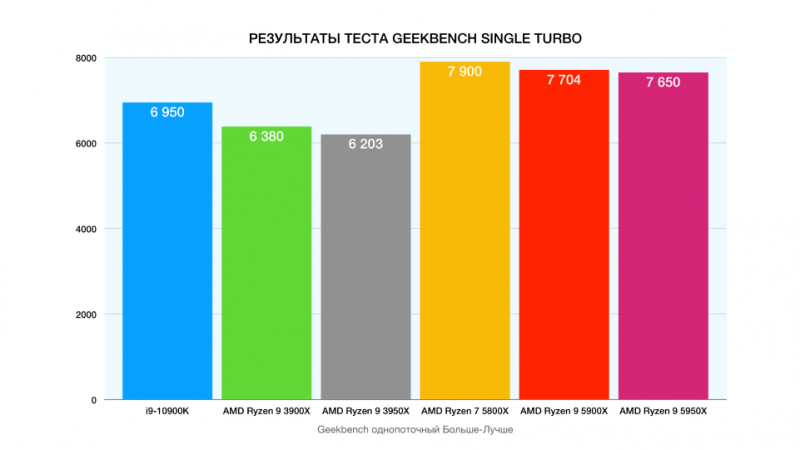
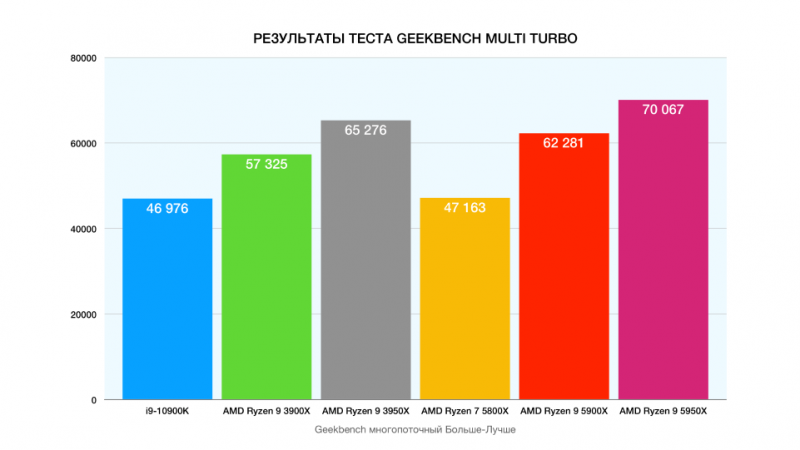
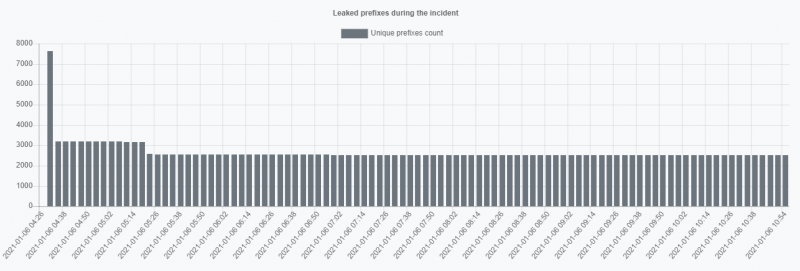
AS9304 утечка префиксов 8764 через AS15412
Можно было бы ожидать, что 2021 год начнется несколько иначе, чем хаос прошлого года. В Qrator.Radar мы тоже надеялись на лучшее. К сожалению, уже 6 января — сегодня мы ошиблись.
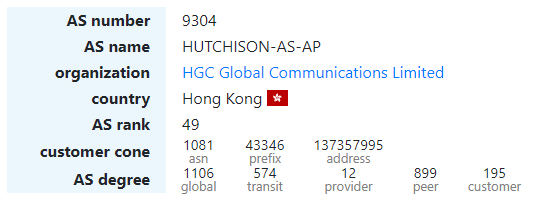
Начиная с 4:21 UTC, из AS9304 — провайдера HGC Global Communications Limited из Гонконга — произошло огромное количество префиксов по сравнению со средней утечкой — 8764. Они содержали IP-адреса 907 ASN из 66 стран, что привело к 9140 конфликтам. в целом.
Активная фаза инцидента длилась около 2,5 часов, после чего сократилась.
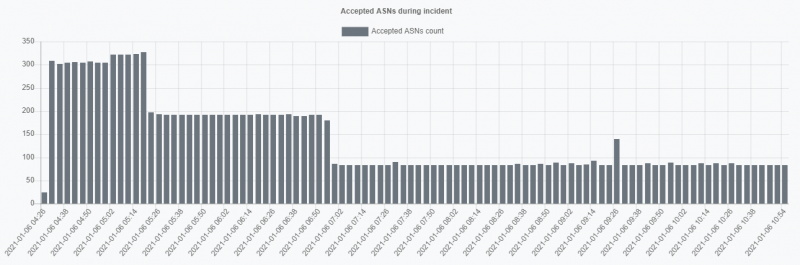
Если такая утечка распространится по всему миру, это будет катастрофическим инцидентом, связанным с маршрутизацией для всех участников. По совпадению, на этот раз этого не произошло. По данным наших наблюдений, только ⅓ автономных систем в утечке принимали эти префиксы.
Среди наиболее пострадавших от этой утечки маршрута оказались известные участники Интернет-транзита из ЕС и США, такие как Akamai и Cloudflare. Однако объем утечки префиксов был настолько широк, что для компании с обширной компьютерной сетью почти невозможно не пострадать от такого инцидента.
Наконец, только для 1% префиксов в утечке распространение было действительно глобальным. По большей части эта утечка имела ограниченную известность и охват во всем мире. Что по-прежнему может быть довольно опасным и привести к потере трафика и доступности в определенных регионах.
Базирующаяся в Великобритании AS15412, принадлежащая Flag Telecom Global Internet, сегодня извлекла ценный урок. Теперь у сетевых инженеров этой компании больше не должно возникать вопросов о необходимости как входящей, так и исходящей фильтрации по префиксу.
Начиная с 4:21 UTC, из AS9304 — провайдера HGC Global Communications Limited из Гонконга — произошло огромное количество префиксов по сравнению со средней утечкой — 8764. Они содержали IP-адреса 907 ASN из 66 стран, что привело к 9140 конфликтам. в целом.
Активная фаза инцидента длилась около 2,5 часов, после чего сократилась.
Если такая утечка распространится по всему миру, это будет катастрофическим инцидентом, связанным с маршрутизацией для всех участников. По совпадению, на этот раз этого не произошло. По данным наших наблюдений, только ⅓ автономных систем в утечке принимали эти префиксы.
Среди наиболее пострадавших от этой утечки маршрута оказались известные участники Интернет-транзита из ЕС и США, такие как Akamai и Cloudflare. Однако объем утечки префиксов был настолько широк, что для компании с обширной компьютерной сетью почти невозможно не пострадать от такого инцидента.
Наконец, только для 1% префиксов в утечке распространение было действительно глобальным. По большей части эта утечка имела ограниченную известность и охват во всем мире. Что по-прежнему может быть довольно опасным и привести к потере трафика и доступности в определенных регионах.
Базирующаяся в Великобритании AS15412, принадлежащая Flag Telecom Global Internet, сегодня извлекла ценный урок. Теперь у сетевых инженеров этой компании больше не должно возникать вопросов о необходимости как входящей, так и исходящей фильтрации по префиксу.