Объявляя GPU экземпляров коммерческого класса для Linode клиентов
Linode была основана на идее предоставления разработчикам больше возможностей, инструментов и ресурсов для выполнения своей работы. В 2003 году, это означало, что виртуализация услуги, чтобы сделать их более доступными в том, что теперь облако. Сегодня, это означает, что вождение инноваций сделать облачные вычисления простого, доступным и доступным для всех. www.linode.com/gpus
Наши новые экземпляры Linode GPU являются последним примером нашей приверженности к ускорению инноваций. Каждый экземпляр GPU особенность коммерческого класса графической обработки с NVIDIA Quadro RTX 6000. Эти карты использовать мощь CUDA, тензорные и RT ядер для параллельной обработки, глубокого изучения и трассировки лучей рабочих нагрузок — все со скоростью и последовательностью Linode Dedicated экземпляры CPU.
С экземплярами GPU Linode, вы будете получать:
Одна из лучших карт выполнения GPU, доступных — по требованию
Передовое соотношение цены и производительности
Ясно ценообразование, великодушные политики передачи сети, и не сюрприз излишков
Ваша обратная связь будет определять дальнейшие шаги, как мы надеемся вырастить Linode GPU предложение. Если вы хотите принять участие в этом пилоте, вы можете узнать больше о наших планах GPU здесь, или войти Менеджер Linode Cloud. www.linode.com/pricing
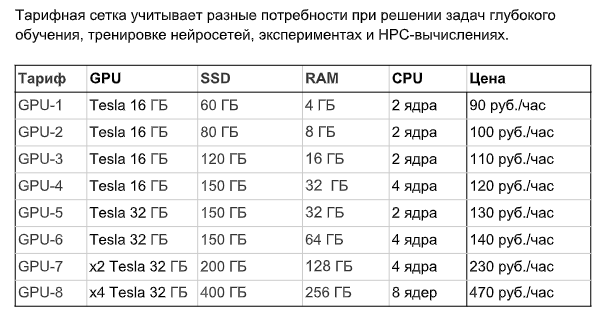
Крупнейший российский хостинг-провайдер и регистратор доменов REG.RU в формате открытого бета-тестирования запускает новые тарифы для услуги «Облачные вычисления на GPU». Инфраструктурный партнёр продукта — производитель графических ускорителей NVIDIA.
Облачные вычисления на GPU — программно-аппаратная платформа на базе мощных графических ускорителей NVIDIA Tesla V100, разработанных специально для машинного обучения, анализа больших массивов данных и высоконагруженных вычислений. В течение последнего года REG.RU тестировал услугу, изучал пользовательский опыт и спрос, идентифицировал потребности клиентов и в результате запускает бета-тест новых тарифов для облачных вычислений.
Ключевые критерии выбора тарифа — объём данных клиента и необходимая мощность GPU. Чем больше память GPU, тем больший объём она способна переработать. GPU-7 и GPU-8 позволяют использовать сразу несколько графических ускорителей для максимально быстрых расчётов. В зависимости от задачи, каждый сможет найти подходящее решение: владельцы стартапов и предприниматели, программисты и разработчики, студенты, научные сотрудники и многие другие.
Через панель управления услугой клиент может самостоятельно разворачивать и удалять серверы, выбирать преднастроенные шаблоны виртуального окружения с Ubuntu или Windows и производить базовые действия с услугой. Благодаря режиму почасовой оплаты можно включать вычисления только на тот период, на который требуется графический ускоритель (GPU). На время бета-тестирования, до 1 июня 2019 года, стоимость составит от 90 рублей за час работы.
Подробнее о тарифных планах можно узнать на странице услуги: www.reg.ru/cloud-services/cloud_gpu Если ни один из них по каким-то причинам не подходит, можно оставить заявку в специальной форме и менеджеры создадут индивидуальную конфигурацию и тариф.
Выбирая облачные вычисления на GPU от REG.RU, пользователи получают доступ к NVIDIA GPU Cloud — каталогу программных инструментов для искусственного интеллекта, машинного обучения, НРС и используют мощность GPU NVIDIA на локальных и облачных системах. Предварительно интегрированные контейнеры включают в себя рекордный программный стек NVIDIA AI, в том числе NVIDIA CUDA Toolkit, библиотеки глубокого обучения NVIDIA и ведущие интеллектуальные программные инструменты.
Облачные вычисления на GPU — это во многом эксперимент, который показал отличные результаты! В течение года мы тестировали продукт, предоставляли его участникам хакатонов, изучали спрос и отклики. Разработка понятной и устойчивой тарифной сетки и выход в открытое бета-тестирование — это ещё один шаг в развитии нашей услуги
комментирует генеральный директор REG.RU Алексей Королюк.
Мощные вычислительные платформы сегодня востребованы не только в сфере исследований, но и в бизнесе. Доступ к вычислениям в облаке и наличие необходимых программных инструментов обеспечивают компании разного масштаба всеми необходимыми ресурсами для реализации самых смелых идей
отмечает Дмитрий Конягин, руководитель направления Enterprise-решений в NVIDIA Россия
Мы только что выпустили GPU Instances, наши первые серверы, оснащенные графическими процессорами (GPU). Оснащенные высокопроизводительными 16-ГБ картами NVIDIA Tesla P100 и высокоэффективными процессорами Intel Xeon Gold 6148, они идеально подходят для обработки данных, искусственного интеллекта, рендеринга и кодирования видео. В дополнение к выделенному графическому процессору и 10 ядрам Intel Xeon Gold каждый экземпляр поставляется с 45 ГБ памяти, 400 ГБ локального хранилища NVMe SSD и оплачивается 1 евро в час или 500 евро в месяц.
Сегодня мы представляем вам конкретный вариант использования для экземпляров графических процессоров, использующих глубокое обучение для получения фронтальной визуализации изображений лица. Не стесняйтесь попробовать это тоже. Для этого посетите консоль Scaleway, чтобы запросить квоты, прежде чем создавать свой первый экземпляр GPU.
Обзор графического процессора
Графический процессор (GPU) стал условным обозначением специализированной электронной схемы, предназначенной для питания графики на машине, в конце 1990-х годов, когда она была популяризирована производителем чипов NVIDIA.
Первоначально графические процессоры создавались главным образом для обеспечения высокого качества игр, создавая реалистичную цифровую графику. Сегодня эти возможности используются более широко для ускорения вычислительных нагрузок в таких областях, как искусственный интеллект, машинное обучение и сложное моделирование.
Экземпляры с графическим процессором в Scaleway были спроектированы так, чтобы их можно было оптимизировать для сбора огромных пакетов данных и очень быстрого выполнения одной и той же операции снова и снова. Сочетание эффективного процессора с мощным графическим процессором обеспечит наилучшее соотношение производительности системы и цены для ваших приложений глубокого обучения.
Написание собственного программного обеспечения Frontalization для лица с нуля
Сценаристы никогда не перестают нас смешить с причудливыми изображениями технологической индустрии, начиная от лукавого до веселого. Однако с учетом современных достижений в области искусственного интеллекта некоторые из самых нереалистичных технологий с экранов телевизоров оживают.
Например, программное обеспечение Enhance от CSI: NY (или Les Experts: Manhattan для наших франкоязычных читателей) уже вышло за пределы современных нейронных сетей Super Resolution. На более экстремальной стороне воображения находится враг государства:
«Поворот [кадры видеонаблюдения] на 75 градусов вокруг вертикали», должно быть, казался совершенно бессмысленным задолго до 1998 года, когда вышел фильм, о чем свидетельствуют комментарии YouTube под этим конкретным отрывком:
Несмотря на явный пессимизм аудитории, сегодня благодаря машинному обучению любой, кто обладает небольшим знанием Python, достаточно большим набором данных и учетной записью Scaleway, может попробовать написать программу, достойную научной фантастики.
Вступление
Забудьте MNIST, забудьте о классификаторах скучных кошек и собак, сегодня мы узнаем, как сделать что-то гораздо более захватывающее! Эта статья вдохновлена впечатляющей работой R. Huang et al. («За гранью вращения лица: глобальное и локальное восприятие GAN для фотореалистичного синтеза идентичности с сохранением идентичности»), в котором авторы синтезируют фронтальные виды лиц людей с учетом их изображений под разными углами. Ниже приведен рисунок 3 из этой статьи, в котором они сравнивают свои результаты [1] с предыдущей работой [2-6]:
Мы не будем пытаться воспроизвести современную модель R. Huang et al. Вместо этого вы сможете построить и обучить модель лобной фронтализации, дающую разумные результаты за один день:
Дополнительно вы узнаете:
Как использовать библиотеку NVIDIA DALI для высоко оптимизированной предварительной обработки изображений на GPU и подачи их в модель глубокого обучения.
Как зашифровать генерирующую состязательную сеть, которую в PyTorch назвал «самой интересной идеей за последние десять лет в машинном обучении» Янн ЛеКун, директор Facebook AI.
У вас также будет своя собственная Генеративная сеть состязаний, настроенная на обучение по выбранному вами набору данных. Без дальнейших церемоний, давайте копаться!
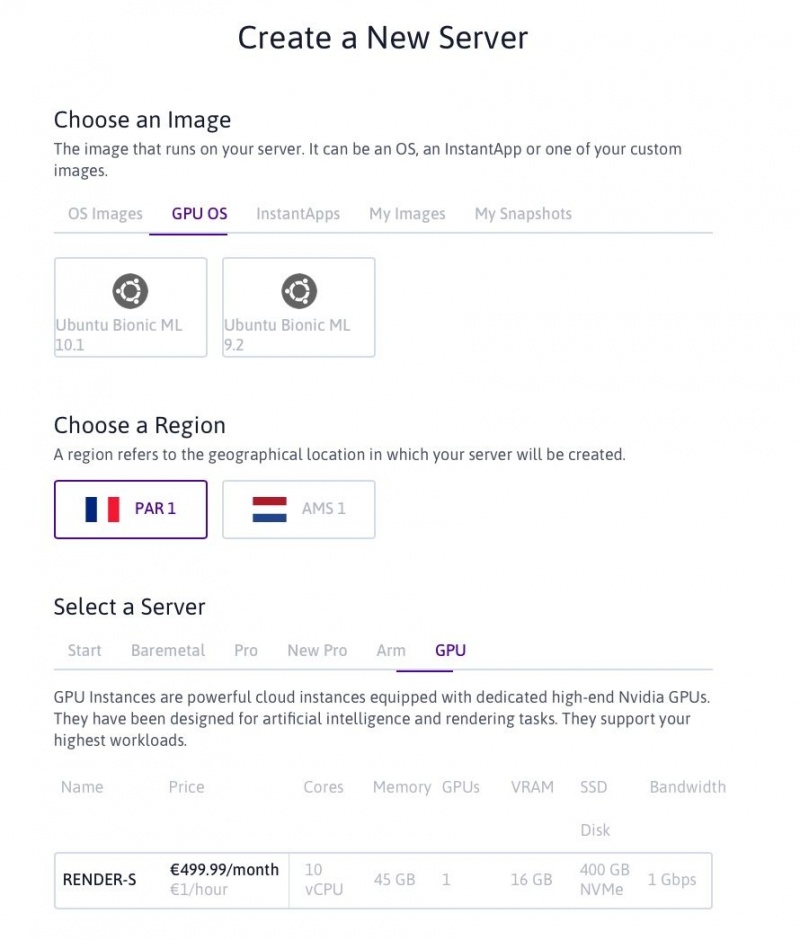
Шаг 1: Запуск и настройка экземпляра Gpu на Scaleway
Если вы еще не получили себе экземпляр GPU, размещенный в Scaleway, вы можете сделать это:
Войдите в консоль Scaleway.
Выберите вкладку Compute на левой боковой панели и нажмите зеленую кнопку + Создать сервер.
Выберите вкладку «GPU OS» в «Выберите образ» и «GPU» в «Выберите сервер».
Для этого проекта вы можете выбрать любой из двух доступных в настоящее время образов ОС GPU (10.1 и 9.2 относятся к соответствующим версиям CUDA) и выбрать RENDER-S в качестве сервера.
Нажмите на зеленую кнопку «Создать новый сервер» внизу страницы, и через несколько секунд ваш собственный экземпляр GPU будет запущен!
Теперь вы можете подключиться к нему по ssh, используя IP-адрес, который вы прочитали в своем списке экземпляров на вкладке Compute:
ssh root@[YOUR GPU INSTANCE IP ADDRESS]
Докерский путь:
Если вы знакомы с Docker, удобной платформой контейнерирования, которая позволяет упаковывать приложения вместе со всеми их зависимостями, продолжайте и извлекайте наш образ Docker, содержащий все пакеты и код, необходимый для проекта Frontalization, а также небольшой примерный набор данных:
nvidia-docker run -it rg.fr-par.scw.cloud/opetrova/frontalization:tutorial
root@b272693df1ca:/Frontalization# ls
Dockerfile data.py main.py network.py test.py training_set
(Обратите внимание, что вам нужно использовать nvidia-docker, а не обычную команду docker из-за наличия графического процессора.) Теперь вы находитесь в каталоге Frontalization, содержащем четыре файла Python, содержимое которых мы рассмотрим ниже, и каталог training_set содержащий образец учебного набора данных. Отличное начало, теперь вы можете перейти к шагу 2!
Родной путь:
Если вы не знакомы с Docker, нет проблем, вы можете легко настроить среду вручную. Экземпляры Scaleway GPU поставляются с уже установленными CUDA, Python и conda, но на момент написания этой статьи вам необходимо понизить версию Python до Python 3.6, чтобы библиотека DALI от Nvidia функционировала:
Вы можете загрузить свой собственный тренировочный набор на свой экземпляр GPU через:
scp -r path/to/local/training_set root@[YOUR GPU INSTANCE IP ADDRESS]:/root/Frontalization
и сохраните код Python, который вы увидите ниже, в каталоге Frontalization, используя выбранный вами текстовый редактор терминала (например, nano или vim, оба из которых уже установлены). В качестве альтернативы вы можете клонировать репозиторий Scaleway GitHub для этого проекта.
Шаг 2: Настройка ваших данных
В основе любого проекта машинного обучения лежат данные. К сожалению, Scaleway не может предоставить базу данных CMU Multi-PIE Face, которую мы использовали для обучения из-за авторских прав, поэтому мы продолжим, если у вас уже есть набор данных, на котором вы хотели бы обучить свою модель. Чтобы использовать библиотеку загрузки данных NVIDIA (DALI), изображения должны быть в формате JPEG. Размеры изображений не имеют значения, поскольку у нас есть DALI для изменения размера всех входов до размера, требуемого нашей сетью (128 × 128 пикселей), но для получения наиболее реалистичных синтезированных изображений желательно соотношение 1: 1.,
Преимущество использования DALI перед, например, стандартным набором данных PyTorch, заключается в том, что любая предварительная обработка (изменение размера, обрезка и т. Д.) Выполняется на графическом процессоре, а не на процессоре, после чего предварительно обрабатываются изображения на графическом процессоре. питаются прямо в нейронную сеть.
Управление нашим набором данных:
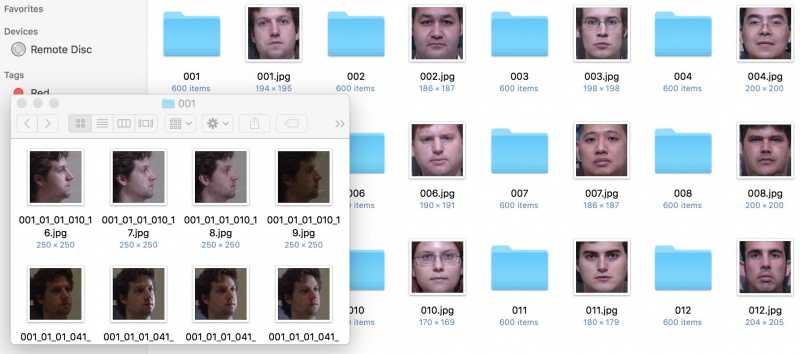
Для проекта фронтализации лица мы настраиваем наш набор данных следующим образом: папка набора данных содержит подпапку и целевое фронтальное изображение для каждого человека (также как субъект). В принципе, имена подпапок и целевых изображений не обязательно должны быть идентичными (как показано на рисунке ниже), но если мы хотим отдельно отсортировать все подпапки и все цели в алфавитно-цифровом порядке, те, которые соответствуют одному и тому же субъект должен появляться в одной и той же позиции в двух списках имен.
Как видите, подпапка 001 /, соответствующая теме 001, содержит изображения человека, изображенные в 001.jpg — это близко обрезанные изображения лица в разных позах, условиях освещения и различных выражениях лица. Для целей фронтализации лица крайне важно, чтобы фронтальные изображения были выровнены как можно ближе друг к другу, тогда как другие (профильные) изображения имеют немного больше свободы.
Например, все наши целевые фронтальные изображения имеют квадратную форму и обрезаются таким образом, что нижняя часть подбородка человека расположена в нижней части изображения, а центрированная точка между внутренними углами глаз расположена на 0,8 ч выше и 0,5 часа справа от нижнего левого угла (h — высота изображения). Таким образом, после изменения размера изображений до 128 × 128 все элементы лица появляются в более или менее одинаковых местах на изображениях в обучающем наборе, и сеть может научиться генерировать упомянутые элементы и объединять их вместе в реалистичный синтез. лица.
Строительство трубопровода DALI:
Теперь мы собираемся построить конвейер для нашего набора данных, который будет наследоваться от nvidia.dali.pipeline.Pipeline. На момент написания DALI не поддерживает непосредственное чтение пар (изображение, изображение) из каталога, поэтому мы будем использовать nvidia.dali.ops.ExternalSource () для передачи входных данных и целей в конвейер. data.py
import collections
from random import shuffle
import os
from os import listdir
from os.path import join
import numpy as np
from nvidia.dali.pipeline import Pipeline
import nvidia.dali.ops as ops
import nvidia.dali.types as types
def is_jpeg(filename):
return any(filename.endswith(extension) for extension in [".jpg", ".jpeg"])
def get_subdirs(directory):
subdirs = sorted([join(directory,name) for name in sorted(os.listdir(directory)) if os.path.isdir(os.path.join(directory, name))])
return subdirs
flatten = lambda l: [item for sublist in l for item in sublist]
class ExternalInputIterator(object):
def __init__(self, imageset_dir, batch_size, random_shuffle=False):
self.images_dir = imageset_dir
self.batch_size = batch_size
# First, figure out what are the inputs and what are the targets in your directory structure:
# Get a list of filenames for the target (frontal) images
self.frontals = np.array([join(imageset_dir, frontal_file) for frontal_file in sorted(os.listdir(imageset_dir)) if is_jpeg(frontal_file)])
# Get a list of lists of filenames for the input (profile) images for each person
profile_files = [[join(person_dir, profile_file) for profile_file in sorted(os.listdir(person_dir)) if is_jpeg(profile_file)] for person_dir in get_subdirs(imageset_dir)]
# Build a flat list of frontal indices, corresponding to the *flattened* profile_files
# The reason we are doing it this way is that we need to keep track of the multiple inputs corresponding to each target
frontal_ind = []
for ind, profiles in enumerate(profile_files):
frontal_ind += [ind]*len(profiles)
self.frontal_indices = np.array(frontal_ind)
# Now that we have built frontal_indices, we can flatten profile_files
self.profiles = np.array(flatten(profile_files))
# Shuffle the (input, target) pairs if necessary: in practice, it is profiles and frontal_indices that get shuffled
if random_shuffle:
ind = np.array(range(len(self.frontal_indices)))
shuffle(ind)
self.profiles = self.profiles[ind]
self.frontal_indices = self.frontal_indices[ind]
def __iter__(self):
self.i = 0
self.n = len(self.frontal_indices)
return self
# Return a batch of (input, target) pairs
def __next__(self):
profiles = []
frontals = []
for _ in range(self.batch_size):
profile_filename = self.profiles[self.i]
frontal_filename = self.frontals[self.frontal_indices[self.i]]
profile = open(profile_filename, 'rb')
frontal = open(frontal_filename, 'rb')
profiles.append(np.frombuffer(profile.read(), dtype = np.uint8))
frontals.append(np.frombuffer(frontal.read(), dtype = np.uint8))
profile.close()
frontal.close()
self.i = (self.i + 1) % self.n
return (profiles, frontals)
next = __next__
class ImagePipeline(Pipeline):
'''
Constructor arguments:
- imageset_dir: directory containing the dataset
- image_size = 128: length of the square that the images will be resized to
- random_shuffle = False
- batch_size = 64
- num_threads = 2
- device_id = 0
'''
def __init__(self, imageset_dir, image_size=128, random_shuffle=False, batch_size=64, num_threads=2, device_id=0):
super(ImagePipeline, self).__init__(batch_size, num_threads, device_id, seed=12)
eii = ExternalInputIterator(imageset_dir, batch_size, random_shuffle)
self.iterator = iter(eii)
self.num_inputs = len(eii.frontal_indices)
# The source for the inputs and targets
self.input = ops.ExternalSource()
self.target = ops.ExternalSource()
# nvJPEGDecoder below accepts CPU inputs, but returns GPU outputs (hence device = "mixed")
self.decode = ops.nvJPEGDecoder(device = "mixed", output_type = types.RGB)
# The rest of pre-processing is done on the GPU
self.res = ops.Resize(device="gpu", resize_x=image_size, resize_y=image_size)
self.norm = ops.NormalizePermute(device="gpu", output_dtype=types.FLOAT,
mean=[128., 128., 128.], std=[128., 128., 128.],
height=image_size, width=image_size)
# epoch_size = number of (profile, frontal) image pairs in the dataset
def epoch_size(self, name = None):
return self.num_inputs
# Define the flow of the data loading and pre-processing
def define_graph(self):
self.profiles = self.input(name="inputs")
self.frontals = self.target(name="targets")
profile_images = self.decode(self.profiles)
profile_images = self.res(profile_images)
profile_output = self.norm(profile_images)
frontal_images = self.decode(self.frontals)
frontal_images = self.res(frontal_images)
frontal_output = self.norm(frontal_images)
return (profile_output, frontal_output)
def iter_setup(self):
(images, targets) = self.iterator.next()
self.feed_input(self.profiles, images)
self.feed_input(self.frontals, targets)
Теперь вы можете использовать класс ImagePipeline, который вы написали выше, для загрузки изображений из вашего каталога наборов данных, по одному пакету за раз.
Если вы используете код из этого учебника в блокноте Jupyter, вот как вы можете использовать ImagePipeline для отображения изображений:
from __future__ import division
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
%matplotlib inline
def show_images(image_batch, batch_size):
columns = 4
rows = (batch_size + 1) // (columns)
fig = plt.figure(figsize = (32,(32 // columns) * rows))
gs = gridspec.GridSpec(rows, columns)
for j in range(rows*columns):
plt.subplot(gs[j])
plt.axis("off")
plt.imshow(np.transpose(image_batch.at(j), (1,2,0)))
batch_size = 8
pipe = ImagePipeline('my_dataset_directory', image_size=128, batch_size=batch_size)
pipe.build()
profiles, frontals = pipe.run()
# The images returned by ImagePipeline are currently on the GPU
# We need to copy them to the CPU via the asCPU() method in order to display them
show_images(profiles.asCPU(), batch_size=batch_size)
show_images(frontals.asCPU(), batch_size=batch_size)
Scaleway makes ArtificialIntelligence more accessible by launching premium, dedicated cloud #GPU instances powered by NVIDIAEU Tesla P100 at an ultra-competitive price.
Уупс. Что-то пошло не так! Не найдена плата за установку для выделенного сервера EX51-SSD-GPU! Наша команда уже работает над исправлением.
Ну а пока, вы можете воспользоваться предоставленной возможностью и заказать выделенный сервер EX51-SSD-GPU на выгодных условиях. Закажи сейчас и не плати 116.82 € за установку.
Будьте осторожны. Эта модель имеет мощнейшую видеокарту GeForce GTX 1080. Ее параллельная архитектура позволяет обрабатывать различные процессы параллельно и эффективно, усиливая общую производительность сервера. Это позволяет быстро работать с большим количество графических данных, независимо от того, состоят ли данные из изображений или видео.
Пока наши техники не нашли плату за установку, вы можете заказать этот сервер от 110.92 €, и теперь он также доступен в Финляндии.
Графические процессоры (graphics processing unit, GPU) — яркий пример того, как технология, спроектированная для задач графической обработки, распространилась на несвязанную область высокопроизводительных вычислений. Современные GPU являются сердцем множества сложнейших проектов в сфере машинного обучения и анализа данных. В нашей обзорной статье мы расскажем, как клиенты Selectel используют оборудование с GPU, и подумаем о будущем науки о данных и вычислительных устройств вместе с преподавателями Школы анализа данных Яндекс.
Графические процессоры за последние десять лет сильно изменились. Помимо колоссального прироста производительности, произошло разделение устройств по типу использования. Так, в отдельное направление выделяются видеокарты для домашних игровых систем и установок виртуальной реальности. Появляются мощные узкоспециализированные устройства: для серверных систем одним из ведущих ускорителей является NVIDIA Tesla P100, разработанный именно для промышленного использования в дата-центрах. Помимо GPU активно ведутся исследования в сфере создания нового типа процессоров, имитирующих работу головного мозга. Примером может служить однокристальная платформа Kirin 970 с собственным нейроморфным процессором для задач, связанных с нейронными сетями и распознаванием образов.
Подобная ситуация заставляет задуматься над следующими вопросами:
Почему сфера анализа данных и машинного обучения стала такой популярной?
Как графические процессоры стали доминировать на рынке оборудования для интенсивной работы с данными?
Какие исследования в области анализа данных будут наиболее перспективными в ближайшем будущем?
Попробуем разобраться с этими вопросами по порядку, начиная с первых простых видеопроцессоров и заканчивая современными высокопроизводительными устройствами.
Эпоха GPU
Для начала вспомним, что же такое GPU. Graphics Processing Unit — это графический процессор широко используемый в настольных и серверных системах. Отличительной особенностью этого устройства является ориентированность на массовые параллельные вычисления. В отличие от графических процессоров архитектура другого вычислительного модуля CPU (Central Processor Unit) предназначена для последовательной обработки данных. Если количество ядер в обычном CPU измеряется десятками, то в GPU их счет идет на тысячи, что накладывает ограничения на типы выполняемых команд, однако обеспечивает высокую вычислительную производительность в задачах, включающих параллелизм.
Первые шаги
Развитие видеопроцессоров на ранних этапах было тесно связано с нарастающей потребностью в отдельном вычислительном устройстве для обработки двух и трехмерной графики. До появления отдельных схем видеоконтроллеров в 70-х годах вывод изображения осуществлялся через использование дискретной логики, что сказывалось на увеличенном энергопотреблении и больших размерах печатных плат. Специализированные микросхемы позволили выделить разработку устройств, предназначенных для работы с графикой, в отдельное направление.
Следующим революционным событием стало появление нового класса более сложных и многофункциональных устройств — видеопроцессоров. В 1996 году компания 3dfx Interactive выпустила чипсет Voodoo Graphics, который быстро занял 85% рынка специализированных видеоустройств и стал лидером в области 3D графики того времени. После серии неудачных решений менеджмента компании, среди которых была покупка производителя видеокарт STB, 3dfx уступила первенство NVIDIA и ATI (позднее AMD), а в 2002 объявила о своем банкротстве.
Общие вычисления на GPU
В 2006 году NVIDIA объявила о выпуске линейки продуктов GeForce 8 series, которая положила начало новому классу устройств, предназначенных для общих вычислений на графических процессорах (GPGPU). В ходе разработки NVIDIA пришла к пониманию, что большее число ядер, работающих на меньшей частоте, более эффективны для параллельных нагрузок, чем малое число более производительных ядер. Видеопроцессоры нового поколения обеспечили поддержку параллельных вычислений не только для обработки видеопотоков, но также для проблем, связанных с машинным обучением, линейной алгеброй, статистикой и другими научными или коммерческими задачами.
Признанный лидер
Различия в изначальной постановке задач перед CPU и GPU привели к значительным расхождениям в архитектуре устройств — высокая частота против многоядерности. Для графических процессоров это заложило вычислительный потенциал, который в полной мере реализуется в настоящее время. Видеопроцессоры с внушительным количеством более слабых вычислительных ядер отлично справляются с параллельными вычислениями. Центральный же процессор, исторически спроектированный для работы с последовательными задачами, остается лучшим в своей области.
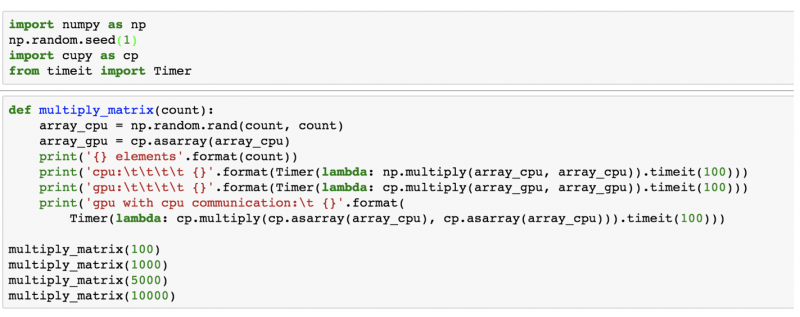
Для примера сравним значения в производительности центрального и графического процессора на выполнении распространенной задачи в нейронных сетях — перемножении матриц высокого порядка. Выберем следующие устройства для тестирования:
Используем пример вычисления перемножения матриц на CPU и GPU в Jupyter Notebook:
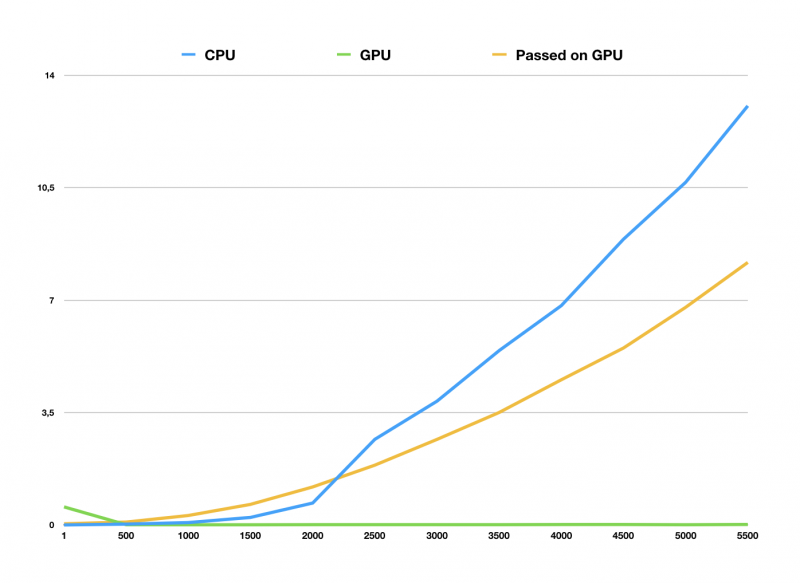
В коде выше мы измеряем время, которое потребовалось на вычисление матриц одинакового порядка на центральном или графическом процессоре («Время выполнения»). Данные можно представить в виде графика, на котором горизонтальная ось отображает порядок перемножаемых матриц, а вертикальная — Время выполнения в секундах:
Линия графика, выделенная оранжевым, показывает время, которое требуется для создания данных в обычном ОЗУ, передачу их в память GPU и последующие вычисления. Зеленая линия показывает время, которое требуется на вычисление данных, которые были сгенерированы уже в памяти видеокарты (без передачи из ОЗУ). Синяя отображает время подсчета на центральном процессоре. Матрицы порядка менее 1000 элементов перемножаются на GPU и CPU почти за одинаковое время. Разница в производительности хорошо проявляется с матрицами размерами более 2000 на 2000, когда время вычислений на CPU подскакивает до 1 секунды, а GPU остается близким к нулю.
Более сложные и практические задачи эффективнее решаются на устройстве с графическими процессорами, чем без них. Поскольку проблемы, которые решают наши клиенты на оборудовании с GPU, очень разнообразны, мы решили выяснить, какие самые популярные сценарии использования существуют.
Кому в Selectel жить хорошо с GPU?
Первый вариант, который сразу приходит на ум и оказывается правильной догадкой — это майнинг, однако любопытно отметить, что некоторые применяют его как вспомогательный способ загрузить оборудование на «максимум». В случае аренды выделенного сервера с видеокартами, время свободное от рабочих нагрузок используется для добычи криптовалют, не требующих специализированных установок (ферм) для своего получения.
Ставшие уже в какой-то степени классическими, задачи, связанные с графической обработкой и рендерингом, неизменно находят свое место на серверах Selectel с графическими ускорителями. Использование высокопроизводительного оборудования для таких задач позволяет получить более эффективное решение, чем организация выделенных рабочих мест с видеокартами.
В ходе разговора с нашими клиентами мы также познакомились с представителями Школы анализа данных Яндекс, которая использует мощности Selectel для организации тестовых учебных сред. Мы решили узнать побольше о том, чем занимаются студенты и преподаватели, какие направления машинного обучения сейчас популярны и какое будущее ожидает индустрию, после того как молодые специалисты пополнят ряды сотрудников ведущих организаций или запустят свои стартапы.
Наука о данных
Пожалуй, среди наших читателей не найдется тех, кто не слышал бы словосочетания «нейронные сети» или «машинное обучение». Отбросив маркетинговые вариации на тему этих слов, получается сухой остаток в виде зарождающейся и перспективной науки о данных.
Современный подход к работе с данными включает в себя несколько основных направлений:
Большие данные (Big Data). Основная проблема в данной сфере — колоссальный объем информации, который не может быть обработан на единственном сервере. С точки зрения инфраструктурного обеспечения, требуется решать задачи создания кластерных систем, масштабируемости, отказоустойчивости, и распределенного хранения данных;
Ресурсоемкие задачи (Машинное обучение, глубокое обучение и другие). В этом случае поднимается вопрос использования высокопроизводительных вычислений, требующих большого количества ОЗУ и процессорных ресурсов. В таких задачах активно используются системы с графическими ускорителями.
Граница между данными направления постепенно стирается: основные инструменты для работы с большими данным (Hadoop, Spark) внедряют поддержку вычислений на GPU, а задачи машинного обучения охватывают новые сферы и требуют бо́льших объемов данных. Разобраться подробнее нам помогут преподаватели и студенты Школы анализа данных.
Трудно переоценить важность грамотной работы с данными и уместного внедрения продвинутых аналитических инструментов. Речь идёт даже не о больших данных, их «озерах» или «реках», а именно об интеллектуальном взаимодействии с информацией. Происходящее сейчас представляет собой уникальную ситуацию: мы можем собирать самую разнообразную информацию и использовать продвинутые инструменты и сервисы для глубокого анализа. Бизнес внедряет подобные технологии не только для получения продвинутой аналитики, но и для создания уникального продукта в любой отрасли. Именно последний пункт во многом формирует и стимулирует рост индустрии анализа данных.
Новое направление
Повсюду нас окружает информация: от логов интернет-компаний и банковских операций до показаний в экспериментах на Большом адронном коллайдере. Умение работать с этими данными может принести миллионные прибыли и дать ответы на фундаментальные вопросы о строении Вселенной. Поэтому анализ данных стал отдельным направлением исследований среди бизнес и научного сообщества.
Школа анализа данных готовит лучших профильных специалистов и ученых, которые в будущем станут основным источником научных и индустриальных разработок в данной сфере. Развитие отрасли сказывается и на нас как на инфраструктурном провайдере — все больше клиентов запрашивают конфигурации серверов для задач анализа данных.
От специфики задач, стоящих перед нашими клиентами, зависит то, какое оборудование мы должны предлагать заказчикам и в каком направлении следует развивать нашу продуктовую линейку. Совместно со Станиславом Федотовым и Олегом Ивченко мы опросили студентов и преподавателей Школы анализа данных и выяснили, какие технологии они используют для решения практических задач.
Технологии анализа данных
За время обучения слушатели от основ (базовой высшей математики, алгоритмов и программирования) доходят до самых передовых областей машинного обучения. Мы собирали информацию по тем, в которых используются серверы с GPU:
Глубинное обучение;
Обучение с подкреплением;
Компьютерное зрение;
Автоматическая обработка текстов.
Студенты используют специализированные инструменты в своих учебных заданиях и исследованиях. Некоторые библиотеки предназначены для приведения данных к необходимому виду, другие предназначены для работы с конкретным типом информации, например, текстом или изображениями. Глубинное обучение — одна из самых сложных областей в анализе данных, которая активно использует нейронные сети. Мы решили узнать, какие именно фреймворки преподаватели и студенты применяют для работы с нейронными сетями.
Представленные инструменты обладают разной поддержкой от создателей, но тем не менее, продолжают активно использоваться в учебных и рабочих целях. Многие из них требуют производительного оборудования для обработки задач в адекватные сроки.
Дальнейшее развитие и проекты
Как и любая наука, направление анализа данных будет изменяться. Опыт, который получают студенты сегодня, несомненно войдет в основу будущих разработок. Поэтому отдельно стоит отметить высокую практическую направленность программы — некоторые студенты во время учебы или после начинают стажироваться в Яндексе и применять свои знания уже на реальных сервисах и службах (поиск, компьютерное зрение, распознавание речи и другие).
О будущем анализа данных мы поговорили с преподавателями Школы анализа данных, которые поделились с нами своим видением развития науки о данных.
По мнению Влада Шахуро, преподавателя курса «Анализ изображений и видео», самые интересные задачи в компьютерном зрении — обеспечение безопасности в местах массового скопления людей, управление беспилотным автомобилем и создание приложение с использованием дополненной реальности. Для решения этих задач необходимо уметь качественно анализировать видеоданные и развивать в первую очередь алгоритмы детектирования и слежения за объектами, распознавания человека по лицу и трехмерной реконструкции наблюдаемой сцены. Преподаватель Виктор Лемпицкий, ведущий курс «Глубинное обучение», отдельно выделяет в своем направлении автокодировщики, а также генеративные и состязательные сети.
Один из наставников Школы анализа данных делится своим мнением касательно распространения и начала массового использования машинного обучения:
Машинное обучение из удела немногих одержимых исследователей превращается в ещё один инструмент рядового разработчика. Раньше (например в 2012) люди писали низкоуровневый код для обучения сверточных сетей на паре видеокарт. Сейчас, кто угодно может за считанные часы
скачать веса уже обученной нейросети (например, в keras);
встроить её в свой веб-сайт или мобильное приложение (tensorflow / caffe 2).
Многие большие компании и стартапы уже выиграли на такой стратегии (например, Prisma), но еще больше задач только предстоит открыть и решить. И, быть может, вся эта история с машинным/глубинным обучением когда-нибудь станет такой же обыденностью, как сейчас python или excel»
Точно предсказать технологию будущего сегодня не сможет никто, но когда есть определенный вектор движения можно понимать, что следует изучать уже сейчас. А возможностей для этого в современном мире — огромное множество.
Возможности для новичков
Изучение анализа данных ограничивается высокими требованиями к обучающимся: обширные познания в области математики и алгоритмики, умение программировать. По-настоящему серьезные задачи машинного обучения требуют уже наличия специализированного оборудования. А для желающих побольше узнать о теоретической составляющей науки о данных Школой анализа данных совместно с Высшей Школой Экономики был запущен онлайн курс «Введение в машинное обучение».
Вместо заключения
Рост рынка графических процессоров обеспечивается возрастающим интересом к возможностям таких устройств. GPU применяется в домашних игровых системах, задачах рендеринга и видеообработки, а также там, где требуются общие высокопроизводительные вычисления. Практическое применение задач интеллектуального анализа данных будет проникать все глубже в нашу повседневную жизнь. И выполнение подобных программ наиболее эффективно осуществляется именно с помощью GPU.
Мы благодарим наших клиентов, а также преподавателей и студентов Школы анализа данных за совместную подготовку материала, и приглашаем наших читателей познакомиться с ними поближе.
А опытным и искушенным в сфере машинного обучения, анализа данных и не только мы предлагаем посмотреть предложения от Selectel по аренде серверного оборудования с графическми ускорителями: от простых GTX 1080 до Tesla P100 и K80 для самых требовательных задач.
Сегодня мы рады объявить об общей доступности графических процессоров в Google Kubernetes Engine, которые стали одной из самых быстрорастущих функций платформы, так как они вступили в бета-версию в начале этого года, а основные часы выросли на 10X с конца 2017 года.
Совместно с GA Kubernetes Engine 1.10 графические процессоры делают Kubernetes Engine отличным для рабочих нагрузок для машинного обучения (ML). Используя GPU в Kubernetes Engine для ваших рабочих нагрузок CUDA, вы получаете максимальную вычислительную мощность графических процессоров, когда вам нужно, без необходимости управлять оборудованием или даже виртуальными машинами. Недавно мы представили новейший и самый быстрый NVIDIA Tesla V100 в портфолио, и P100, как правило, доступен. И последнее, но не менее важное: мы также предлагаем начальный уровень K80, который в значительной степени отвечает за популярность графических процессоров.
Все наши модели графических процессоров доступны в качестве превентивных графических процессоров, что позволяет снизить затраты при использовании графических процессоров в Google Cloud. Ознакомьтесь с последними ценами на графические процессоры здесь.
По мере роста основных часов GPU наши пользователи в восторге от GPU в Kubernetes Engine. Ocado, крупнейший в мире онлайн-магазин продуктов питания, всегда стремится применять современные модели машинного обучения для клиентов Ocado.com и партнеров по розничной торговле Ocado Smart Platform и запускает модели на превентивных экземплярах с ускорением GPU на Двигатель Кубернетеса.
Присоединенные к GPU узлы вместе с Kubernetes обеспечивают мощную, экономичную и гибкую среду для машинного обучения на уровне предприятия. Ocado выбрала Kubernetes за ее масштабируемость, мобильность, сильную экосистему и огромную поддержку сообщества. Он легче, гибче и удобнее в обслуживании по сравнению с кластером традиционных виртуальных машин. Он также имеет большую простоту в использовании и возможность прикреплять аппаратные ускорители, такие как графические процессоры и TPU, обеспечивая огромный прирост по сравнению с традиционными процессорами
— Мартин Николов, инженер-разработчик программного обеспечения, Ocado
Графические процессоры в Kubernetes Engine также имеют ряд уникальных возможностей:
Узел пулов позволяет вашему существующему кластеру использовать графические процессоры, когда вам нужно.
Autoscaler автоматически создает узлы с графическими процессорами, когда планируются графические процессоры, и масштабируются до нуля, когда графические процессоры больше не потребляются никакими активными модулями.
Технология Taint и toleration гарантирует, что на узлах с графическими процессорами будут запланированы только те модули, которые запрашивают графические процессоры, и предотвращают запуск блоков, которые не требуют использования графических процессоров.
Квота ресурсов, которая позволяет администраторам ограничить потребление ресурсов на пространство имен в большом кластере, совместно используемом несколькими пользователями или командами.
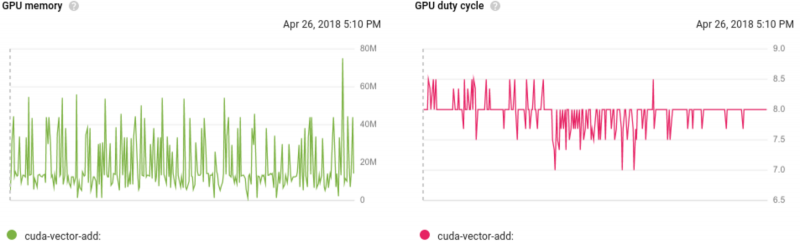
Мы также слышали от вас, что вам нужен простой способ понять, как работают ваши задачи GPU: насколько заняты графические процессоры, сколько памяти доступно и сколько памяти выделено. Мы очень рады сообщить, что теперь вы можете отслеживать эту информацию из консоли GCP. Вы также можете визуализировать эти показатели в Stackdriver.
Рис. 1. Использование памяти GPU и рабочий цикл
Общая доступность графических процессоров в Kubernetes Engine представляет собой тяжелую работу за кулисами, полировку внутренних компонентов для корпоративных нагрузок. Jiaying Zhang, технический лидер в этой общей доступности, возглавил усилия Device Plugins в Kubernetes 1.10, тесно сотрудничая с сообществом OSS, чтобы понять его потребности, определить общие требования и разработать план выполнения для создания готовой к производству системы.
Попробуйте их сегодня
Чтобы начать использовать графические процессоры в Kubernetes Engine с помощью бесплатной пробной версии в размере 300 долларов США, вам необходимо обновить свою учетную запись и подать заявку на получение квоты на использование графического процессора для вступления в силу кредитов. Для более подробного объяснения Kubernetes Engine с графическими процессорами, например, как установить драйверы NVIDIA и как настроить контейнер для использования графических процессоров, ознакомьтесь с документацией.
В дополнение к графическим процессорам в Kubernetes Engine облачные TPU также теперь доступны в Google Cloud. Например, RiseML использует Cloud TPU в Kubernetes Engine для простой в использовании инфраструктуры машинного обучения, которая проста в использовании, обладает высокой масштабируемостью и экономичностью. Если вы хотите быть одним из первых, кто получил доступ к Cloud TPU в Kubernetes Engine, присоединяйтесь к нашей программе раннего доступа сегодня.
Спасибо за ваши отзывы о том, как формировать нашу дорожную карту, чтобы лучше удовлетворить ваши потребности. Продолжайте разговор, соединившись с нами на канале Cubernetes Engine Slack.
Новая услуга REG.RU для ИИ-проектов на базе NVIDIA Tesla V100
Услуга «Облачные вычисления на GPU» позволит вам получить доступ к аппаратной платформе для работы с алгоритмами глубокого обучения и высокопроизводительными вычислениями. Кроме того, платформа NVIDIA отлично подходит для 3D и видеорендеринга. В основе услуги мощный специализированный ускоритель для работы с высокопроизводительными вычислениями — NVIDIA Tesla V100. Воспользуйтесь бесплатным тестовым периодом (до 2 вычислительных ускорителей к одному контейнеру на срок до нескольких дней). www.reg.ru/cloud-services/cloud_gpu/
Облачные аппаратные ускорители, такие как графические процессоры или графические процессоры, являются отличным выбором для вычислительных нагрузок, таких как машинное обучение и высокопроизводительные вычисления (HPC). Мы стремимся предоставить самый широкий выбор популярных ускорителей на Google Cloud, чтобы удовлетворить ваши потребности в гибкости и стоимости. С этой целью, мы рады сообщить, что графические процессоры NVIDIA Tesla и твердотельного накопителя v100, если сейчас публично доступна в бета-версии на Вычислительные машины и двигателя Kubernetes, и что NVIDIA Тесла Р100 графических процессоров стала общедоступна.
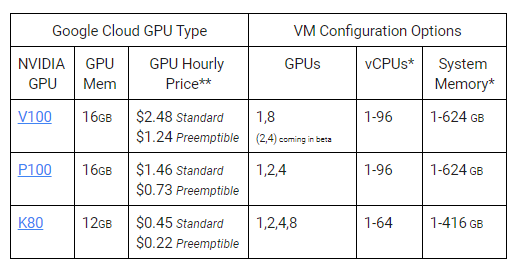
Сегодняшние самые требовательные рабочие нагрузки и индустрии требуют самых быстрых акселераторов оборудования. Теперь вы можете выбрать до восьми графических процессоров NVIDIA Tesla V100, 96 vCPU и 624 ГБ системной памяти в одной виртуальной машине, получая до 1 петафлопа смешанной точности аппаратного ускорения. Следующее поколени соединений NVLINK поставляет до 300GB/s ширины полосы частот GPU-к-GPU, 9X над PCIe, форсируя представление на глубоком учить и рабочих нагрузках HPC до 40%. NVIDIA V100s доступны для следующих регионов: us-west1, us-central1 и Европа-west4. Каждый V100 GPU по цене всего $2.48 в час по требованию ВМ и $1,24 на час для операционных систем виртуальных машин. Как и наши другие графические процессоры, V100 также оплачивается вторым и действуют постоянные скидки.
Наши клиенты часто спрашивают, какой Графический процессор лучше всего подходит для их вычислительной нагрузки с поддержкой CUDA. Если вы ищете баланс между ценой и производительностью, Графический процессор NVIDIA Tesla P100 хорошо подходит. Можно выбрать до четырех графических процессоров P100, 96 vcpu и 624 ГБ памяти на виртуальную машину. Кроме того, Р100, теперь доступна и в Европе-западе4 (Нидерланды) в дополнение к нам-запад1, нам-central1, нам-восток1, Европа-запад1 и Азии-восток1.
Наше портфолио GPU предлагает широкий выбор вариантов производительности и цен, чтобы помочь удовлетворить ваши потребности. Вместо того чтобы выбирать универсальную виртуальную машину одного размера, вы можете подключить наши графические процессоры к пользовательским формам виртуальных машин и воспользоваться широким выбором вариантов хранения, оплачивая только необходимые ресурсы.
Google Cloud упрощает управление рабочими нагрузками GPU как для виртуальных машин, так и для контейнеров. В Google Compute Engine клиенты могут использовать шаблоны экземпляров и управляемые группы экземпляров для простого создания и масштабирования инфраструктуры GPU. Вы также можете использовать NVIDIA V100s и другие наши предложения GPU в Kubernetes Engine, где Кластерный Автоскалер помогает обеспечить гибкость, автоматически создавая узлы с графическими процессорами и масштабируя их до нуля, когда они больше не используются. Вместе с Вытесняемыми графическими процессорами группы управляемых экземпляров Compute Engine и Автосалон Kubernetes Engine позволяют оптимизировать затраты и упростить операции инфраструктуры.
LeadStage, поставщик автоматизации маркетинга, впечатлен стоимостью и масштабом графических процессоров в Google Cloud.
«Графические процессоры NVIDIA отлично подходят для сложных задач оптического распознавания символов на наборах данных низкого качества. Мы используем графические процессоры V100 и P100 в Google Compute Engine для преобразования миллионов рукописных документов, чертежей съемки и инженерных чертежей в машиночитаемые данные. Возможность развертывания тысяч экземпляров GPU в считанные секунды значительно превосходила возможности и стоимость предыдущего поставщика облачных вычислений.»
Адам Сибрук, Главный Исполнительный Директор, LeadStage
Если у вас есть вычислительно требовательные рабочие нагрузки, графические процессоры могут стать настоящим игровым чейнджером. Проверьте нашу страницу GPU, чтобы узнать больше о том, как вы можете извлечь выгоду из P100, V100 и других Google Cloud GPU!