Представление экземпляров GPU: использование глубокого обучения для получения фронтальной визуализации изображений лица
Мы только что выпустили GPU Instances, наши первые серверы, оснащенные графическими процессорами (GPU). Оснащенные высокопроизводительными 16-ГБ картами NVIDIA Tesla P100 и высокоэффективными процессорами Intel Xeon Gold 6148, они идеально подходят для обработки данных, искусственного интеллекта, рендеринга и кодирования видео. В дополнение к выделенному графическому процессору и 10 ядрам Intel Xeon Gold каждый экземпляр поставляется с 45 ГБ памяти, 400 ГБ локального хранилища NVMe SSD и оплачивается 1 евро в час или 500 евро в месяц.
Сегодня мы представляем вам конкретный вариант использования для экземпляров графических процессоров, использующих глубокое обучение для получения фронтальной визуализации изображений лица. Не стесняйтесь попробовать это тоже. Для этого посетите консоль Scaleway, чтобы запросить квоты, прежде чем создавать свой первый экземпляр GPU.
Обзор графического процессора
Графический процессор (GPU) стал условным обозначением специализированной электронной схемы, предназначенной для питания графики на машине, в конце 1990-х годов, когда она была популяризирована производителем чипов NVIDIA.
Первоначально графические процессоры создавались главным образом для обеспечения высокого качества игр, создавая реалистичную цифровую графику. Сегодня эти возможности используются более широко для ускорения вычислительных нагрузок в таких областях, как искусственный интеллект, машинное обучение и сложное моделирование.
Экземпляры с графическим процессором в Scaleway были спроектированы так, чтобы их можно было оптимизировать для сбора огромных пакетов данных и очень быстрого выполнения одной и той же операции снова и снова. Сочетание эффективного процессора с мощным графическим процессором обеспечит наилучшее соотношение производительности системы и цены для ваших приложений глубокого обучения.
Написание собственного программного обеспечения Frontalization для лица с нуля
Сценаристы никогда не перестают нас смешить с причудливыми изображениями технологической индустрии, начиная от лукавого до веселого. Однако с учетом современных достижений в области искусственного интеллекта некоторые из самых нереалистичных технологий с экранов телевизоров оживают.
Например, программное обеспечение Enhance от CSI: NY (или Les Experts: Manhattan для наших франкоязычных читателей) уже вышло за пределы современных нейронных сетей Super Resolution. На более экстремальной стороне воображения находится враг государства:
«Поворот [кадры видеонаблюдения] на 75 градусов вокруг вертикали», должно быть, казался совершенно бессмысленным задолго до 1998 года, когда вышел фильм, о чем свидетельствуют комментарии YouTube под этим конкретным отрывком:

Несмотря на явный пессимизм аудитории, сегодня благодаря машинному обучению любой, кто обладает небольшим знанием Python, достаточно большим набором данных и учетной записью Scaleway, может попробовать написать программу, достойную научной фантастики.
Вступление
Забудьте MNIST, забудьте о классификаторах скучных кошек и собак, сегодня мы узнаем, как сделать что-то гораздо более захватывающее! Эта статья вдохновлена впечатляющей работой R. Huang et al. («За гранью вращения лица: глобальное и локальное восприятие GAN для фотореалистичного синтеза идентичности с сохранением идентичности»), в котором авторы синтезируют фронтальные виды лиц людей с учетом их изображений под разными углами. Ниже приведен рисунок 3 из этой статьи, в котором они сравнивают свои результаты [1] с предыдущей работой [2-6]:

Мы не будем пытаться воспроизвести современную модель R. Huang et al. Вместо этого вы сможете построить и обучить модель лобной фронтализации, дающую разумные результаты за один день:

Дополнительно вы узнаете:
Шаг 1: Запуск и настройка экземпляра Gpu на Scaleway
Если вы еще не получили себе экземпляр GPU, размещенный в Scaleway, вы можете сделать это:
Для этого проекта вы можете выбрать любой из двух доступных в настоящее время образов ОС GPU (10.1 и 9.2 относятся к соответствующим версиям CUDA) и выбрать RENDER-S в качестве сервера.
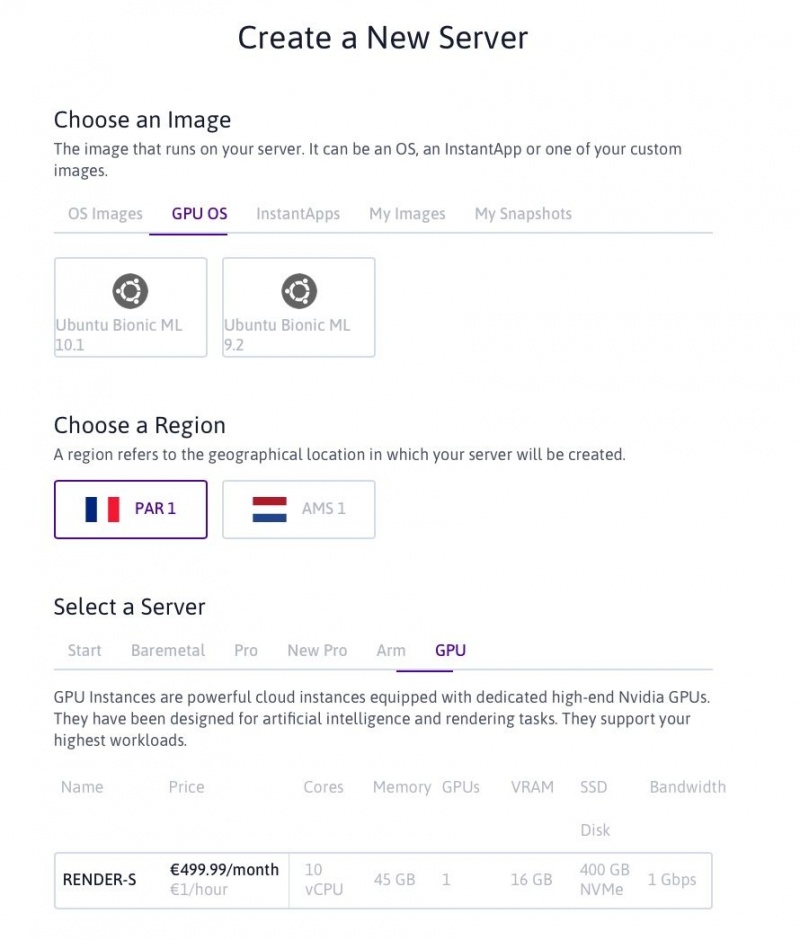
Нажмите на зеленую кнопку «Создать новый сервер» внизу страницы, и через несколько секунд ваш собственный экземпляр GPU будет запущен!
Теперь вы можете подключиться к нему по ssh, используя IP-адрес, который вы прочитали в своем списке экземпляров на вкладке Compute:
Докерский путь:
Если вы знакомы с Docker, удобной платформой контейнерирования, которая позволяет упаковывать приложения вместе со всеми их зависимостями, продолжайте и извлекайте наш образ Docker, содержащий все пакеты и код, необходимый для проекта Frontalization, а также небольшой примерный набор данных:
(Обратите внимание, что вам нужно использовать nvidia-docker, а не обычную команду docker из-за наличия графического процессора.) Теперь вы находитесь в каталоге Frontalization, содержащем четыре файла Python, содержимое которых мы рассмотрим ниже, и каталог training_set содержащий образец учебного набора данных. Отличное начало, теперь вы можете перейти к шагу 2!
Родной путь:
Если вы не знакомы с Docker, нет проблем, вы можете легко настроить среду вручную. Экземпляры Scaleway GPU поставляются с уже установленными CUDA, Python и conda, но на момент написания этой статьи вам необходимо понизить версию Python до Python 3.6, чтобы библиотека DALI от Nvidia функционировала:
Вы можете загрузить свой собственный тренировочный набор на свой экземпляр GPU через:
и сохраните код Python, который вы увидите ниже, в каталоге Frontalization, используя выбранный вами текстовый редактор терминала (например, nano или vim, оба из которых уже установлены). В качестве альтернативы вы можете клонировать репозиторий Scaleway GitHub для этого проекта.
Шаг 2: Настройка ваших данных
В основе любого проекта машинного обучения лежат данные. К сожалению, Scaleway не может предоставить базу данных CMU Multi-PIE Face, которую мы использовали для обучения из-за авторских прав, поэтому мы продолжим, если у вас уже есть набор данных, на котором вы хотели бы обучить свою модель. Чтобы использовать библиотеку загрузки данных NVIDIA (DALI), изображения должны быть в формате JPEG. Размеры изображений не имеют значения, поскольку у нас есть DALI для изменения размера всех входов до размера, требуемого нашей сетью (128 × 128 пикселей), но для получения наиболее реалистичных синтезированных изображений желательно соотношение 1: 1.,
Преимущество использования DALI перед, например, стандартным набором данных PyTorch, заключается в том, что любая предварительная обработка (изменение размера, обрезка и т. Д.) Выполняется на графическом процессоре, а не на процессоре, после чего предварительно обрабатываются изображения на графическом процессоре. питаются прямо в нейронную сеть.
Управление нашим набором данных:
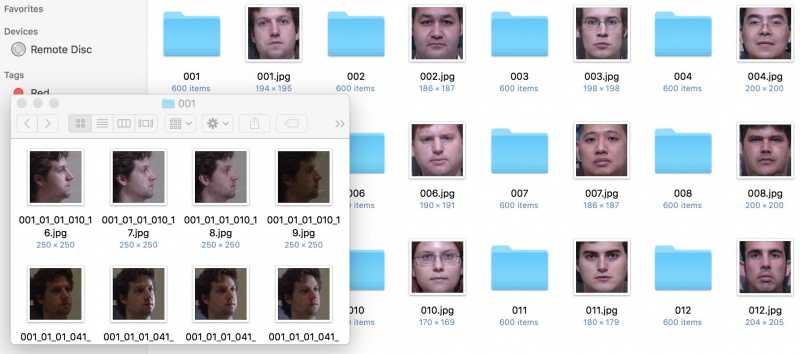
Для проекта фронтализации лица мы настраиваем наш набор данных следующим образом: папка набора данных содержит подпапку и целевое фронтальное изображение для каждого человека (также как субъект). В принципе, имена подпапок и целевых изображений не обязательно должны быть идентичными (как показано на рисунке ниже), но если мы хотим отдельно отсортировать все подпапки и все цели в алфавитно-цифровом порядке, те, которые соответствуют одному и тому же субъект должен появляться в одной и той же позиции в двух списках имен.
Как видите, подпапка 001 /, соответствующая теме 001, содержит изображения человека, изображенные в 001.jpg — это близко обрезанные изображения лица в разных позах, условиях освещения и различных выражениях лица. Для целей фронтализации лица крайне важно, чтобы фронтальные изображения были выровнены как можно ближе друг к другу, тогда как другие (профильные) изображения имеют немного больше свободы.
Например, все наши целевые фронтальные изображения имеют квадратную форму и обрезаются таким образом, что нижняя часть подбородка человека расположена в нижней части изображения, а центрированная точка между внутренними углами глаз расположена на 0,8 ч выше и 0,5 часа справа от нижнего левого угла (h — высота изображения). Таким образом, после изменения размера изображений до 128 × 128 все элементы лица появляются в более или менее одинаковых местах на изображениях в обучающем наборе, и сеть может научиться генерировать упомянутые элементы и объединять их вместе в реалистичный синтез. лица.
Строительство трубопровода DALI:
Теперь мы собираемся построить конвейер для нашего набора данных, который будет наследоваться от nvidia.dali.pipeline.Pipeline. На момент написания DALI не поддерживает непосредственное чтение пар (изображение, изображение) из каталога, поэтому мы будем использовать nvidia.dali.ops.ExternalSource () для передачи входных данных и целей в конвейер.
data.py
Теперь вы можете использовать класс ImagePipeline, который вы написали выше, для загрузки изображений из вашего каталога наборов данных, по одному пакету за раз.
Если вы используете код из этого учебника в блокноте Jupyter, вот как вы можете использовать ImagePipeline для отображения изображений:
blog.scaleway.com/2019/gpu-instances-using-deep-learning-to-obtain-frontal-rendering-of-facial-images/
Сегодня мы представляем вам конкретный вариант использования для экземпляров графических процессоров, использующих глубокое обучение для получения фронтальной визуализации изображений лица. Не стесняйтесь попробовать это тоже. Для этого посетите консоль Scaleway, чтобы запросить квоты, прежде чем создавать свой первый экземпляр GPU.
Обзор графического процессора
Графический процессор (GPU) стал условным обозначением специализированной электронной схемы, предназначенной для питания графики на машине, в конце 1990-х годов, когда она была популяризирована производителем чипов NVIDIA.
Первоначально графические процессоры создавались главным образом для обеспечения высокого качества игр, создавая реалистичную цифровую графику. Сегодня эти возможности используются более широко для ускорения вычислительных нагрузок в таких областях, как искусственный интеллект, машинное обучение и сложное моделирование.
Экземпляры с графическим процессором в Scaleway были спроектированы так, чтобы их можно было оптимизировать для сбора огромных пакетов данных и очень быстрого выполнения одной и той же операции снова и снова. Сочетание эффективного процессора с мощным графическим процессором обеспечит наилучшее соотношение производительности системы и цены для ваших приложений глубокого обучения.
Написание собственного программного обеспечения Frontalization для лица с нуля
Сценаристы никогда не перестают нас смешить с причудливыми изображениями технологической индустрии, начиная от лукавого до веселого. Однако с учетом современных достижений в области искусственного интеллекта некоторые из самых нереалистичных технологий с экранов телевизоров оживают.
Например, программное обеспечение Enhance от CSI: NY (или Les Experts: Manhattan для наших франкоязычных читателей) уже вышло за пределы современных нейронных сетей Super Resolution. На более экстремальной стороне воображения находится враг государства:
«Поворот [кадры видеонаблюдения] на 75 градусов вокруг вертикали», должно быть, казался совершенно бессмысленным задолго до 1998 года, когда вышел фильм, о чем свидетельствуют комментарии YouTube под этим конкретным отрывком:
Несмотря на явный пессимизм аудитории, сегодня благодаря машинному обучению любой, кто обладает небольшим знанием Python, достаточно большим набором данных и учетной записью Scaleway, может попробовать написать программу, достойную научной фантастики.
Вступление
Забудьте MNIST, забудьте о классификаторах скучных кошек и собак, сегодня мы узнаем, как сделать что-то гораздо более захватывающее! Эта статья вдохновлена впечатляющей работой R. Huang et al. («За гранью вращения лица: глобальное и локальное восприятие GAN для фотореалистичного синтеза идентичности с сохранением идентичности»), в котором авторы синтезируют фронтальные виды лиц людей с учетом их изображений под разными углами. Ниже приведен рисунок 3 из этой статьи, в котором они сравнивают свои результаты [1] с предыдущей работой [2-6]:
Мы не будем пытаться воспроизвести современную модель R. Huang et al. Вместо этого вы сможете построить и обучить модель лобной фронтализации, дающую разумные результаты за один день:
Дополнительно вы узнаете:
- Как использовать библиотеку NVIDIA DALI для высоко оптимизированной предварительной обработки изображений на GPU и подачи их в модель глубокого обучения.
- Как зашифровать генерирующую состязательную сеть, которую в PyTorch назвал «самой интересной идеей за последние десять лет в машинном обучении» Янн ЛеКун, директор Facebook AI.
- У вас также будет своя собственная Генеративная сеть состязаний, настроенная на обучение по выбранному вами набору данных. Без дальнейших церемоний, давайте копаться!
Шаг 1: Запуск и настройка экземпляра Gpu на Scaleway
Если вы еще не получили себе экземпляр GPU, размещенный в Scaleway, вы можете сделать это:
- Войдите в консоль Scaleway.
- Выберите вкладку Compute на левой боковой панели и нажмите зеленую кнопку + Создать сервер.
- Выберите вкладку «GPU OS» в «Выберите образ» и «GPU» в «Выберите сервер».
Для этого проекта вы можете выбрать любой из двух доступных в настоящее время образов ОС GPU (10.1 и 9.2 относятся к соответствующим версиям CUDA) и выбрать RENDER-S в качестве сервера.
Нажмите на зеленую кнопку «Создать новый сервер» внизу страницы, и через несколько секунд ваш собственный экземпляр GPU будет запущен!
Теперь вы можете подключиться к нему по ssh, используя IP-адрес, который вы прочитали в своем списке экземпляров на вкладке Compute:
ssh root@[YOUR GPU INSTANCE IP ADDRESS]Докерский путь:
Если вы знакомы с Docker, удобной платформой контейнерирования, которая позволяет упаковывать приложения вместе со всеми их зависимостями, продолжайте и извлекайте наш образ Docker, содержащий все пакеты и код, необходимый для проекта Frontalization, а также небольшой примерный набор данных:
nvidia-docker run -it rg.fr-par.scw.cloud/opetrova/frontalization:tutorial
root@b272693df1ca:/Frontalization# ls
Dockerfile data.py main.py network.py test.py training_set(Обратите внимание, что вам нужно использовать nvidia-docker, а не обычную команду docker из-за наличия графического процессора.) Теперь вы находитесь в каталоге Frontalization, содержащем четыре файла Python, содержимое которых мы рассмотрим ниже, и каталог training_set содержащий образец учебного набора данных. Отличное начало, теперь вы можете перейти к шагу 2!
Родной путь:
Если вы не знакомы с Docker, нет проблем, вы можете легко настроить среду вручную. Экземпляры Scaleway GPU поставляются с уже установленными CUDA, Python и conda, но на момент написания этой статьи вам необходимо понизить версию Python до Python 3.6, чтобы библиотека DALI от Nvidia функционировала:
conda install -y python==3.6.7
conda install -y pytorch torchvision
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist nvidia-dali==0.6.1Вы можете загрузить свой собственный тренировочный набор на свой экземпляр GPU через:
scp -r path/to/local/training_set root@[YOUR GPU INSTANCE IP ADDRESS]:/root/Frontalizationи сохраните код Python, который вы увидите ниже, в каталоге Frontalization, используя выбранный вами текстовый редактор терминала (например, nano или vim, оба из которых уже установлены). В качестве альтернативы вы можете клонировать репозиторий Scaleway GitHub для этого проекта.
Шаг 2: Настройка ваших данных
В основе любого проекта машинного обучения лежат данные. К сожалению, Scaleway не может предоставить базу данных CMU Multi-PIE Face, которую мы использовали для обучения из-за авторских прав, поэтому мы продолжим, если у вас уже есть набор данных, на котором вы хотели бы обучить свою модель. Чтобы использовать библиотеку загрузки данных NVIDIA (DALI), изображения должны быть в формате JPEG. Размеры изображений не имеют значения, поскольку у нас есть DALI для изменения размера всех входов до размера, требуемого нашей сетью (128 × 128 пикселей), но для получения наиболее реалистичных синтезированных изображений желательно соотношение 1: 1.,
Преимущество использования DALI перед, например, стандартным набором данных PyTorch, заключается в том, что любая предварительная обработка (изменение размера, обрезка и т. Д.) Выполняется на графическом процессоре, а не на процессоре, после чего предварительно обрабатываются изображения на графическом процессоре. питаются прямо в нейронную сеть.
Управление нашим набором данных:
Для проекта фронтализации лица мы настраиваем наш набор данных следующим образом: папка набора данных содержит подпапку и целевое фронтальное изображение для каждого человека (также как субъект). В принципе, имена подпапок и целевых изображений не обязательно должны быть идентичными (как показано на рисунке ниже), но если мы хотим отдельно отсортировать все подпапки и все цели в алфавитно-цифровом порядке, те, которые соответствуют одному и тому же субъект должен появляться в одной и той же позиции в двух списках имен.
Как видите, подпапка 001 /, соответствующая теме 001, содержит изображения человека, изображенные в 001.jpg — это близко обрезанные изображения лица в разных позах, условиях освещения и различных выражениях лица. Для целей фронтализации лица крайне важно, чтобы фронтальные изображения были выровнены как можно ближе друг к другу, тогда как другие (профильные) изображения имеют немного больше свободы.
Например, все наши целевые фронтальные изображения имеют квадратную форму и обрезаются таким образом, что нижняя часть подбородка человека расположена в нижней части изображения, а центрированная точка между внутренними углами глаз расположена на 0,8 ч выше и 0,5 часа справа от нижнего левого угла (h — высота изображения). Таким образом, после изменения размера изображений до 128 × 128 все элементы лица появляются в более или менее одинаковых местах на изображениях в обучающем наборе, и сеть может научиться генерировать упомянутые элементы и объединять их вместе в реалистичный синтез. лица.
Строительство трубопровода DALI:
Теперь мы собираемся построить конвейер для нашего набора данных, который будет наследоваться от nvidia.dali.pipeline.Pipeline. На момент написания DALI не поддерживает непосредственное чтение пар (изображение, изображение) из каталога, поэтому мы будем использовать nvidia.dali.ops.ExternalSource () для передачи входных данных и целей в конвейер.
data.py
import collections
from random import shuffle
import os
from os import listdir
from os.path import join
import numpy as np
from nvidia.dali.pipeline import Pipeline
import nvidia.dali.ops as ops
import nvidia.dali.types as types
def is_jpeg(filename):
return any(filename.endswith(extension) for extension in [".jpg", ".jpeg"])
def get_subdirs(directory):
subdirs = sorted([join(directory,name) for name in sorted(os.listdir(directory)) if os.path.isdir(os.path.join(directory, name))])
return subdirs
flatten = lambda l: [item for sublist in l for item in sublist]
class ExternalInputIterator(object):
def __init__(self, imageset_dir, batch_size, random_shuffle=False):
self.images_dir = imageset_dir
self.batch_size = batch_size
# First, figure out what are the inputs and what are the targets in your directory structure:
# Get a list of filenames for the target (frontal) images
self.frontals = np.array([join(imageset_dir, frontal_file) for frontal_file in sorted(os.listdir(imageset_dir)) if is_jpeg(frontal_file)])
# Get a list of lists of filenames for the input (profile) images for each person
profile_files = [[join(person_dir, profile_file) for profile_file in sorted(os.listdir(person_dir)) if is_jpeg(profile_file)] for person_dir in get_subdirs(imageset_dir)]
# Build a flat list of frontal indices, corresponding to the *flattened* profile_files
# The reason we are doing it this way is that we need to keep track of the multiple inputs corresponding to each target
frontal_ind = []
for ind, profiles in enumerate(profile_files):
frontal_ind += [ind]*len(profiles)
self.frontal_indices = np.array(frontal_ind)
# Now that we have built frontal_indices, we can flatten profile_files
self.profiles = np.array(flatten(profile_files))
# Shuffle the (input, target) pairs if necessary: in practice, it is profiles and frontal_indices that get shuffled
if random_shuffle:
ind = np.array(range(len(self.frontal_indices)))
shuffle(ind)
self.profiles = self.profiles[ind]
self.frontal_indices = self.frontal_indices[ind]
def __iter__(self):
self.i = 0
self.n = len(self.frontal_indices)
return self
# Return a batch of (input, target) pairs
def __next__(self):
profiles = []
frontals = []
for _ in range(self.batch_size):
profile_filename = self.profiles[self.i]
frontal_filename = self.frontals[self.frontal_indices[self.i]]
profile = open(profile_filename, 'rb')
frontal = open(frontal_filename, 'rb')
profiles.append(np.frombuffer(profile.read(), dtype = np.uint8))
frontals.append(np.frombuffer(frontal.read(), dtype = np.uint8))
profile.close()
frontal.close()
self.i = (self.i + 1) % self.n
return (profiles, frontals)
next = __next__
class ImagePipeline(Pipeline):
'''
Constructor arguments:
- imageset_dir: directory containing the dataset
- image_size = 128: length of the square that the images will be resized to
- random_shuffle = False
- batch_size = 64
- num_threads = 2
- device_id = 0
'''
def __init__(self, imageset_dir, image_size=128, random_shuffle=False, batch_size=64, num_threads=2, device_id=0):
super(ImagePipeline, self).__init__(batch_size, num_threads, device_id, seed=12)
eii = ExternalInputIterator(imageset_dir, batch_size, random_shuffle)
self.iterator = iter(eii)
self.num_inputs = len(eii.frontal_indices)
# The source for the inputs and targets
self.input = ops.ExternalSource()
self.target = ops.ExternalSource()
# nvJPEGDecoder below accepts CPU inputs, but returns GPU outputs (hence device = "mixed")
self.decode = ops.nvJPEGDecoder(device = "mixed", output_type = types.RGB)
# The rest of pre-processing is done on the GPU
self.res = ops.Resize(device="gpu", resize_x=image_size, resize_y=image_size)
self.norm = ops.NormalizePermute(device="gpu", output_dtype=types.FLOAT,
mean=[128., 128., 128.], std=[128., 128., 128.],
height=image_size, width=image_size)
# epoch_size = number of (profile, frontal) image pairs in the dataset
def epoch_size(self, name = None):
return self.num_inputs
# Define the flow of the data loading and pre-processing
def define_graph(self):
self.profiles = self.input(name="inputs")
self.frontals = self.target(name="targets")
profile_images = self.decode(self.profiles)
profile_images = self.res(profile_images)
profile_output = self.norm(profile_images)
frontal_images = self.decode(self.frontals)
frontal_images = self.res(frontal_images)
frontal_output = self.norm(frontal_images)
return (profile_output, frontal_output)
def iter_setup(self):
(images, targets) = self.iterator.next()
self.feed_input(self.profiles, images)
self.feed_input(self.frontals, targets)Теперь вы можете использовать класс ImagePipeline, который вы написали выше, для загрузки изображений из вашего каталога наборов данных, по одному пакету за раз.
Если вы используете код из этого учебника в блокноте Jupyter, вот как вы можете использовать ImagePipeline для отображения изображений:
from __future__ import division
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
%matplotlib inline
def show_images(image_batch, batch_size):
columns = 4
rows = (batch_size + 1) // (columns)
fig = plt.figure(figsize = (32,(32 // columns) * rows))
gs = gridspec.GridSpec(rows, columns)
for j in range(rows*columns):
plt.subplot(gs[j])
plt.axis("off")
plt.imshow(np.transpose(image_batch.at(j), (1,2,0)))
batch_size = 8
pipe = ImagePipeline('my_dataset_directory', image_size=128, batch_size=batch_size)
pipe.build()
profiles, frontals = pipe.run()
# The images returned by ImagePipeline are currently on the GPU
# We need to copy them to the CPU via the asCPU() method in order to display them
show_images(profiles.asCPU(), batch_size=batch_size)
show_images(frontals.asCPU(), batch_size=batch_size)blog.scaleway.com/2019/gpu-instances-using-deep-learning-to-obtain-frontal-rendering-of-facial-images/
0 комментариев
Вставка изображения
Оставить комментарий