BareMetal 2.0: разбираемся, какие GPU выбрать

Недавно мы обновили BareMetal 2.0 в составе нашего «Публичного облака». Теперь в инфраструктуре есть выделенные физические серверы с высокопроизводительными GPU-картами. Они позволяют работать с задачами, где критична скорость вычислений.
Расскажем, что именно изменилось и какие задачи можно теперь решать быстрее. Но сначала небольшая справка.
Когда нужны графические ускорители?
Вычисления можно разделить на две категории: последовательные, где каждая операция выполняется строго одна за другой, и параллельные, где тысячи операций могут выполняться одновременно.
Процессоры (CPU) — это универсальные рабочие лошадки. Они отлично справляются с последовательными вычислениями: обработкой запросов, работой с базами данных, выполнением бизнес-логики. Но когда речь заходит о сложных вычислениях, требующих параллельной обработки (обучение нейросетей, рендеринг, обработка видео), их мощностей недостаточно.
В отличие от CPU, GPU созданы для объемных параллельных вычислений: вместо 16–64 мощных ядер, как у процессора, у GPU могут быть тысячи более простых, но специализированных ядер. Подход идеален для задач, которые можно разбить на множество мелких операций, выполняемых одновременно, например для data-parallel computing, обработки данных или работы с графикой.
Где нужны GPU?
- Обучение и инференс больших языковых моделей LLM: развертывание on-premise решений для ChatGPT-подобных систем, RAG-архитектур (Retrieval-Augmented Generation), отраслевых LLM в медицине, юриспруденции, финансах.
- Распознавание речи: создание высокоточных систем распознавания речи для call-центров, виртуальных ассистентов и т. д.
- Корпоративные ИИ-решения: создание собственных решений на базе ИИ для повышения эффективности бизнес-процессов компании, аналитика Big Data с параллельной обработкой поведенческих данных.
- Графика и рендеринг: в 3D-графике расчет сложных моделей в реальном времени возможен только с профессиональными GPU-картами.
- Научные вычисления и инженерные расчеты: моделирование химических соединений, симуляции физических процессов, анализ Big Data.
- Медицинская аналитика: обработка МРТ, КТ, рентгеновских снимков, трехмерная реконструкция изображений, системы поддержки принятий врачебных решений.
- Построение прогнозных моделей: алгоритмическая торговля, риск-менеджмент и обработка больших потоков данных.
- Визуализация больших массивов данных, например, в бизнес-аналитике.
Какие GPU доступны в BareMetal 2.0 и что они могут?
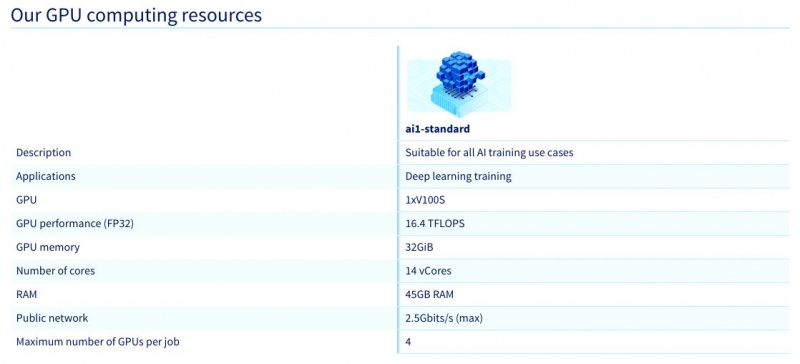
В составе «Публичного облака» на сегодня доступны конфигурации BareMetal серверов с процессорами от 36 физических ядер, объемом оперативной памяти от 512 ГБ. Для хранения данных можно использовать локальное SSD-хранилище или внешнюю систему хранения.
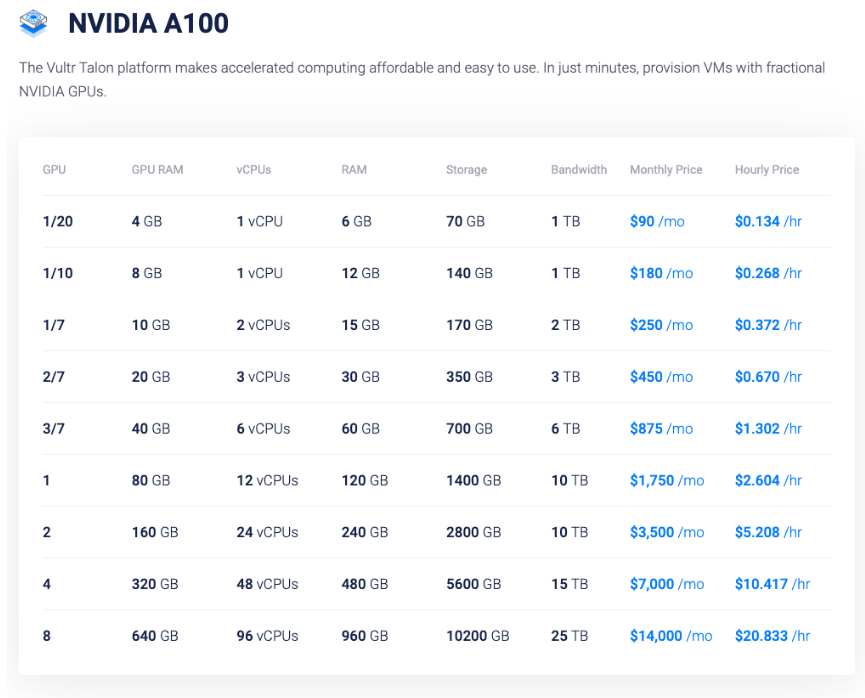
Обновленный сервис предоставляет три ключевые модели графических ускорителей под определенные нагрузки: NVIDIA L4 (24 ГБ VRAM), RTX A6000 (48 ГБ VRAM), NVIDIA A100 (80 ГБ VRAM).

Универсальный ускоритель для ML и видео NVIDIA L4 (24 ГБ VRAM)
L4 — это оптимальный вариант для задач, связанных с обработкой видео, компьютерным зрением и легкими ML-вычислениями. Он быстрее предшественника Tesla T4 в 2,5 раза при генерации контента нейросетями, в 4 раза при рендеринге и в 3 раза при трассировке лучей.
Где нужен?
- Системы распознавания лиц — быстрая обработка потокового видео для аналитики и безопасности.
- Компьютерное зрение — анализ дорожной обстановки в сфере автономного транспорта, контроль качества в промышленности.
- Чат-боты и NLP — модели Transformer для обработки и генерации текстов в реальном времени.
- Медицинская визуализация — анализ снимков МРТ и КТ для диагностики на основе ИИ.
- VR/AR — создание интерактивных сред с высокой детализацией.
NVIDIA RTX A6000 (48 ГБ VRAM) для графики, рендеринга и AI-разработки
Когда нужна максимальная мощность для 3D-моделирования, симуляции и визуализации, то A6000 — отличный выбор. В сравнении с предыдущим поколением RTX-карт он дает в 2 раза большую производительность при рендеринге и в 3 раза более быструю обработку AI-алгоритмов.
Где нужен?
- Рендеринг в реальном времени — видеоигры, VR, киноиндустрия.
- Создание контента нейросетями — работа с GAN-моделями, генерация изображений и анимаций.
- Архитектурная и инженерная визуализация — быстрый расчет сложных 3D-моделей.
- Научные вычисления — биоинформатика, молекулярное моделирование, климатические симуляции.
- Медицина — рендеринг томографических снимков, анализ биоинженерных структур.
NVIDIA A100 (80 ГБ VRAM) — тяжелая артиллерия для больших моделей
A100 — это один из топовых ускорителей для обучения крупных нейросетей, аналитики Big Data и высокопроизводительных вычислений. Он в 8 раз быстрее, чем V100, в задачах Big Data Analytics, а его производительность для HPC-вычислений выше в 3 раза.
Где нужен?
- Обучение больших языковых моделей (GPT-4, BERT, T5) — ускорение обработки текстов на терабайтных датасетах.
- Финансовые вычисления — моделирование рисков, прогнозирование трендов на рынках.
- 3D-рендеринг в кино и анимации — создание сложных сцен с фотореалистичными эффектами.
- Научные исследования — моделирование климатических процессов, симуляция белков и молекулярное моделирование в биомеханике.
- Обработка больших видео и изображений — автоматическая сегментация, классификация и анализ.
Гибридная инфраструктура: GPU + облако
BareMetal 2.0 в составе «Публичного облака» — это не просто выделенные серверы с GPU. Это еще и возможность интеграции физических серверов с виртуальной инфраструктурой, что позволяет выстраивать гибридные IaaS-решения.
Что это дает пользователю?
- Гибкость. Можно использовать GPU-ускоренные серверы только для самых ресурсоемких задач, а остальные процессы запускать в облаке.
- Экономия. Можно избежать капитальных затрат на покупку и обслуживание оборудования (электропитание, ремонт, апгрейд), оплачивая только те ресурсы, которые используются здесь и сейчас.
- Масштабируемость. Можно легко добавлять мощности в зависимости от нагрузки.
Пример 1: Разработка чат-бота на основе нейросетей
Если ваша компания создает чат-бота с искусственным интеллектом, можно тренировать модель на A100, используя всю мощность выделенного GPU-сервера, а обработку пользовательских запросов выполнять на менее ресурсоемких инстансах с L4.
Пример 2: Анализ медицинских изображений
Допустим, у вас есть сервис, который анализирует снимки МРТ и КТ с помощью нейросетей. Обучение модели и сложные вычисления можно запускать на сервере BareMetal с RTX A6000, а облачная инфраструктура возьмет на себя хранение данных пациентов и обработку запросов врачей. Это исключит задержки в обращении к системе.
Этот подход позволяет комбинировать разные вычислительные мощности под конкретные задачи, создавая баланс между производительностью, стоимостью и эффективностью.
GPU в облаке — это не будущее, а реальность
Раньше высокопроизводительные вычисления были привилегией крупных корпораций. Теперь же благодаря BareMetal 2.0 доступ к GPU-решениям есть у любой компании, разработчика или исследовательской команды. Не надо инвестировать миллионы в собственные серверы, если нужна мощность для ИИ, анализа данных, графики или финансовых вычислений. Можно просто развернуть GPU в облаке и получить производительность как в дата-центрах мирового уровня.