Технологии, позволяющие повысить отказоустойчивость VPS
Недавно мы решили выйти за пределы сегмента бюджетных серверов: пересмотреть свое видение хостинга виртуальных машин и создать максимально отказоустойчивую услугу.
В этой статье я расскажу как организована наша стандартная платформа для VPS и какие приемы мы применили, чтобы ее улучшить.
Наша стандартная технология создания VDS
Сейчас хостинг виртуальных серверов у нас выглядит следующим образом:
В стойках установлены одноюнитные серверы примерно такой конфигурации:
Один из серверов является основным. На нем установлен VMmanager и к нему подключены узлы — дополнительные серверы.
Помимо VMmanager, на основном сервере располагаются клиентские виртуальные серверы.
Каждый сервер “смотрит” в мир своим сетевым интерфейсом. А для увеличения скорости миграции VDS между узлами, серверы связаны между собой отдельными интерфейсами.
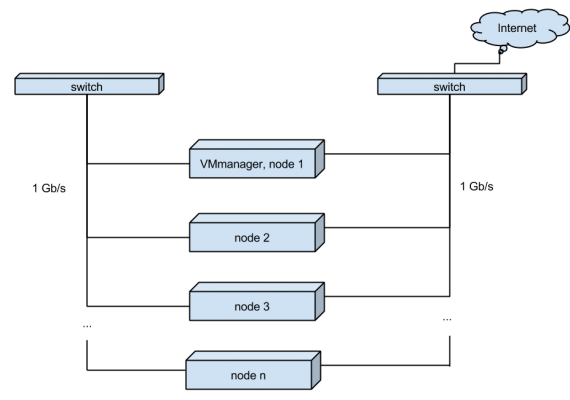
Рис. 1. Текущая схема хостинга виртуальных серверов)
Все серверы работают независимо друг от друга, и, в случае проблем с производительностью на одном из серверов, все виртуальные серверы могут быть разнесены (функция “Миграция” в VMmanager) на соседние узлы, либо перенесены на вновь добавленный узел.
Ситуации, когда сервер выходит из строя (kernel panic, высыпавшиеся диски, умерший БП и т.д.), влекут за собой недоступность виртуальных машин клиентов. Разумеется, система мониторинга немедленно извещает ответственных специалистов о проблеме, они приступают к выяснению причин и устранению аварии. В 90% случаев работы по замене вышедших из строя комплектующих занимают не более часа, плюс требуется время на устранение последствий аварийного выключения сервера (синхронизация системы хранения, ошибки файловой системы и прочие...).
Все это конечно неприятно для нас и клиентов, но простая схема позволяет избежать лишних трат и держать цены на низком уровне.
Новый облачный VDS
Чтобы удовлетворить самых требовательных клиентов, для которых критически важен Uptime сервера, мы создали услугу с максимально высокой надежностью.
Итак, нам был нужен новый софт и оборудование.
Поскольку мы уже работаем с продуктами компании ISPsystem, логичным шагом было посмотреть на VMmanager-Cloud. Эта панель как раз создавалась для решения задачи отказоустойчивости, на данный момент она хорошо проработана и достигла определенной стабильности. Она нас устроила и альтернативы мы не рассматривали.
В качестве распределенной файловой системы безоговорочно был принят Ceph. Это бесплатный, свободно развивающийся продукт, гибкий и масштабируемый. Мы пробовали другие системы хранилищ, но Ceph — это единственный продукт, который полностью удовлетворил наши требования к хранилищу. Он казался сложным на первых порах, с какой-то попытки мы с ним окончательно разобрались. И не пожалели об этом.
Узлы нового кластера собраны на том же самом аппаратном обеспечении, что и рабочий кластер VMmanager, но с небольшими изменениями:
Мы перешли на мультиноды с резервированием по питанию.
Для коммутации между нодами кластера, вместо обычного гигабитного соединения, мы использовали Infiniband. Он позволяет поднять скорость соединения до 56Gb (IB карты Mellanox Technologies MT27500 Family ConnectX-3, коммутатор — Mellanox SX6012)
В качестве операционной системы для узлов кластера был выбран дистрибутив CentOS 7. Правда чтобы заставить работать все вышеперечисенное вместе, пришлось собирать свое ядро, пересобирать qemu и просить о некоторых доработках в VMmanager-Cloud.
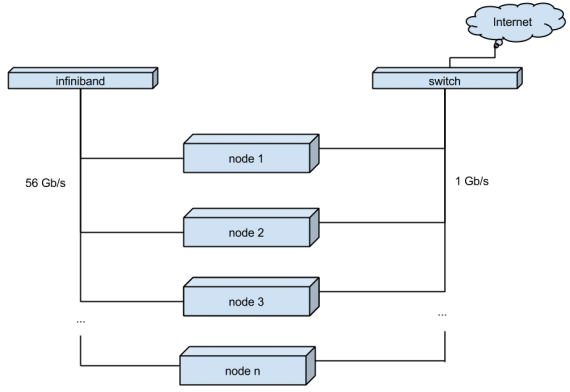
(Рис. 2. Новая схема облачного хостинга виртуальных серверов)
Выгоды использования новой технологии
В итоге мы получили следующее:
С начала декабря прошлого года кластер работает в боевом режиме, на данный момент он обслуживает несколько сотен клиентов, за это время мы наступили на множество граблей, разобрались с узкими местами, произвели необходимый тюнинг и смоделировали все внештатные ситуации.
Пока мы продолжаем тестирование, экономисты считают себестоимость. За счет дополнительного резервирования и использования более дорогих технологий она получилась выше, чем у предыдущего кластера. Мы это учли и разрабатываем новый тариф для самых требовательных клиентов.
Остается ряд рисков, которые мы никак на можем закрыть, это энергоснабжение дата-центра и внешние каналы связи. Для решения подобных вопросов обычно делают распределенные территориально гео-кластеры, возможно, это будет одним из следующих наших исследований.
Если вас заинтересуют технические подробности внедрения вышеописанной технологии, то мы готовы поделиться ими в комментариях или сделать отдельную статью по следам обсуждения.
В этой статье я расскажу как организована наша стандартная платформа для VPS и какие приемы мы применили, чтобы ее улучшить.
Наша стандартная технология создания VDS
Сейчас хостинг виртуальных серверов у нас выглядит следующим образом:
В стойках установлены одноюнитные серверы примерно такой конфигурации:
- CPU — 2 x Intel® Xeon® CPU E5-2630 v2 @ 2.60GHz
- Motherboard: Intel Corporation S2600JF
- RAM: 64 Gb
- DISK: 2 x HGST HDN724040ALE640/4000 GB, INTEL SSDSC2BP480G4 480 GB
Один из серверов является основным. На нем установлен VMmanager и к нему подключены узлы — дополнительные серверы.
Помимо VMmanager, на основном сервере располагаются клиентские виртуальные серверы.
Каждый сервер “смотрит” в мир своим сетевым интерфейсом. А для увеличения скорости миграции VDS между узлами, серверы связаны между собой отдельными интерфейсами.
Рис. 1. Текущая схема хостинга виртуальных серверов)
Все серверы работают независимо друг от друга, и, в случае проблем с производительностью на одном из серверов, все виртуальные серверы могут быть разнесены (функция “Миграция” в VMmanager) на соседние узлы, либо перенесены на вновь добавленный узел.
Ситуации, когда сервер выходит из строя (kernel panic, высыпавшиеся диски, умерший БП и т.д.), влекут за собой недоступность виртуальных машин клиентов. Разумеется, система мониторинга немедленно извещает ответственных специалистов о проблеме, они приступают к выяснению причин и устранению аварии. В 90% случаев работы по замене вышедших из строя комплектующих занимают не более часа, плюс требуется время на устранение последствий аварийного выключения сервера (синхронизация системы хранения, ошибки файловой системы и прочие...).
Все это конечно неприятно для нас и клиентов, но простая схема позволяет избежать лишних трат и держать цены на низком уровне.
Новый облачный VDS
Чтобы удовлетворить самых требовательных клиентов, для которых критически важен Uptime сервера, мы создали услугу с максимально высокой надежностью.
Итак, нам был нужен новый софт и оборудование.
Поскольку мы уже работаем с продуктами компании ISPsystem, логичным шагом было посмотреть на VMmanager-Cloud. Эта панель как раз создавалась для решения задачи отказоустойчивости, на данный момент она хорошо проработана и достигла определенной стабильности. Она нас устроила и альтернативы мы не рассматривали.
В качестве распределенной файловой системы безоговорочно был принят Ceph. Это бесплатный, свободно развивающийся продукт, гибкий и масштабируемый. Мы пробовали другие системы хранилищ, но Ceph — это единственный продукт, который полностью удовлетворил наши требования к хранилищу. Он казался сложным на первых порах, с какой-то попытки мы с ним окончательно разобрались. И не пожалели об этом.
Узлы нового кластера собраны на том же самом аппаратном обеспечении, что и рабочий кластер VMmanager, но с небольшими изменениями:
Мы перешли на мультиноды с резервированием по питанию.
Для коммутации между нодами кластера, вместо обычного гигабитного соединения, мы использовали Infiniband. Он позволяет поднять скорость соединения до 56Gb (IB карты Mellanox Technologies MT27500 Family ConnectX-3, коммутатор — Mellanox SX6012)
В качестве операционной системы для узлов кластера был выбран дистрибутив CentOS 7. Правда чтобы заставить работать все вышеперечисенное вместе, пришлось собирать свое ядро, пересобирать qemu и просить о некоторых доработках в VMmanager-Cloud.
(Рис. 2. Новая схема облачного хостинга виртуальных серверов)
Выгоды использования новой технологии
В итоге мы получили следующее:
- еще более профессиональную услугу виртуальных серверов с высоким Uptime. Её стабильность не зависит от проблем с аппаратным обеспечением узлов кластера.
- увеличение надежности хранения данных за счет распределенной файловой системы с хранением нескольких копий.
- быструю миграцию виртуальных машин. Перенос работающей VPS с ноды на ноду происходит практически мгновенно без потери пакетов и пингов. В случае необходимости это быстро освобождает узел для обслуживания.
- когда узел выходит из строя, виртуальные машины клиентов автоматически запускаются на других узлах. Для клиента это выглядит как внеплановая перезагрузка по питанию, время простоя равно времени перезагрузки ОС.
С начала декабря прошлого года кластер работает в боевом режиме, на данный момент он обслуживает несколько сотен клиентов, за это время мы наступили на множество граблей, разобрались с узкими местами, произвели необходимый тюнинг и смоделировали все внештатные ситуации.
Пока мы продолжаем тестирование, экономисты считают себестоимость. За счет дополнительного резервирования и использования более дорогих технологий она получилась выше, чем у предыдущего кластера. Мы это учли и разрабатываем новый тариф для самых требовательных клиентов.
Остается ряд рисков, которые мы никак на можем закрыть, это энергоснабжение дата-центра и внешние каналы связи. Для решения подобных вопросов обычно делают распределенные территориально гео-кластеры, возможно, это будет одним из следующих наших исследований.
Если вас заинтересуют технические подробности внедрения вышеописанной технологии, то мы готовы поделиться ими в комментариях или сделать отдельную статью по следам обсуждения.
1 комментарий
Вставка изображения
Оставить комментарий