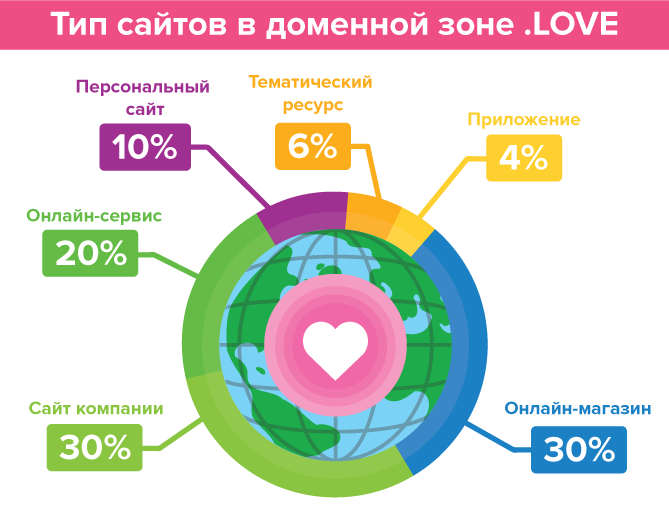
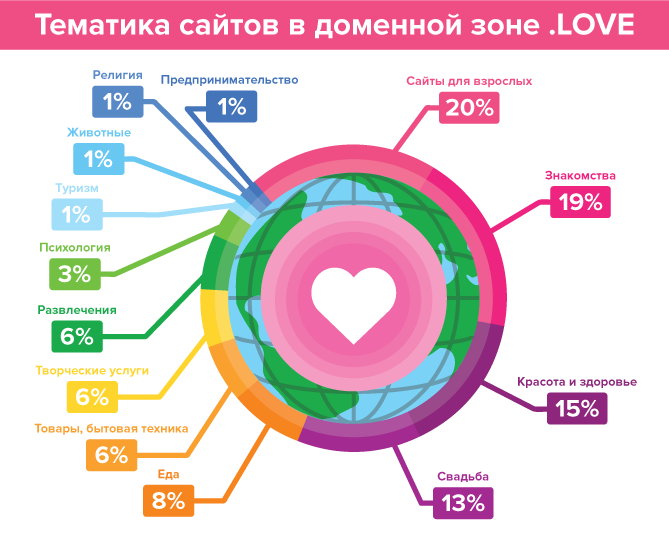
Опубликована методология оценки стоимости доменов .RU и .РФ на вторичном рынке
Координационный центр национальных доменов .RU и.РФ опубликовал «Методологию оценки рыночной стоимости доменных имён второго уровня в доменах верхнего уровня .RU и.РФ на вторичном рынке доменных имён». По мнению эксперта хостинг-провайдера и регистратора доменов REG.RU Павла Патрикеева, методология — шаг к эффективной работе бизнеса с цифровыми активами.
Методология разработана НАО «Евроэксперт» по заказу КЦ. Это набор методов и алгоритмов, с помощью которых можно спрогнозировать стоимость доменного имени на вторичном рынке, учитывая зависимость от ряда ценообразующих факторов, среди них:
Есть и другие характеристики, влияющие на стоимость, — количество символов, наличие дефиса, доля чисел среди символов доменного имени, количество поисковых запросов, соответствующих доменному имени, и т. п.
Всего в документе описано 8 разных моделей ценообразования для доменов в зависимости от их типов (короткие домены без смысловой составляющей, с несколькими смысловыми составляющими, с географической смысловой составляющей и другие).
«Проблема разработки отраслевых стандартов оценки такого важного для современной цифровой экономики актива как доменное имя назрела давно. Ценность домена для современного бизнеса — очевидна. Однако в мире отсутствуют единые общепринятые нормативы для оценки его коммерческой стоимости, которые хотя бы приблизительно могли бы соперничать с детальными методиками оценки более традиционных активов — недвижимого имущества и т. п.
Всё это способствует появлению различных практических проблем: например, под залог доменного имени, которое зачастую может быть оценено в шестизначную сумму, компании невозможно получить банковский кредит. А в случае банкротства этот ценный актив и вовсе может быть безвозвратно утерян. Потому появление и принятие таких стандартов, несомненно, важное событие. Это очередной шаг к стандартизации методик оценки, формированию профессиональных инструментов, с помощью которых бизнес сможет эффективно работать с собственными цифровыми активами», — комментирует руководитель юридического отдела REG.RU Павел Патрикеев.
Методика предназначена для аккредитованных регистраторов в зонах .RU и.РФ, специалистов по оценке интеллектуальной собственности, а также для всех участников вторичного рынка доменных имён: покупателей, продавцов, владельцев сервисов купли-продажи доменных имён. С полной версией можно ознакомиться на сайте КЦ: cctld.ru/upload/iblock/11c/KC_buklet_2020.pdf
REG.RU — хостинг-провайдер и аккредитованный регистратор доменных имён №1 в России (по данным StatOnline.ru, занимает первое место по количеству зарегистрированных доменов и размещённых сайтов в национальных зонах .RU и.РФ). Компания обслуживает более 3 300 000 доменов и предлагает регистрацию в 750 международных доменных зонах, а также предоставляет услуги хостинга, почты, VPS, аренды физических серверов и облачных вычислений на GPU. Занимает первое место в рейтинге хостинг-провайдеров России. В 2012 году REG.RU стал аккредитованным ICANN регистратором. Офисы REG.RU расположены в 30 городах России и СНГ.
Методология разработана НАО «Евроэксперт» по заказу КЦ. Это набор методов и алгоритмов, с помощью которых можно спрогнозировать стоимость доменного имени на вторичном рынке, учитывая зависимость от ряда ценообразующих факторов, среди них:
- соответствие доменного имени существующему слову или понятию (например, «mebel», «USSR» имеют смысловую составляющую, понятную широкой аудитории, а «rwghl», «pvk–5», «487921364», «wee––––ee», «dastek» такой составляющей не имеют);
- соответствие доменного имени второго уровня товарному знаку или бренду;
- численность и уровень доходов населения города, указанного в доменном имени (если в доменном имени присутствует такая смысловая составляющая).
Есть и другие характеристики, влияющие на стоимость, — количество символов, наличие дефиса, доля чисел среди символов доменного имени, количество поисковых запросов, соответствующих доменному имени, и т. п.
Всего в документе описано 8 разных моделей ценообразования для доменов в зависимости от их типов (короткие домены без смысловой составляющей, с несколькими смысловыми составляющими, с географической смысловой составляющей и другие).
«Проблема разработки отраслевых стандартов оценки такого важного для современной цифровой экономики актива как доменное имя назрела давно. Ценность домена для современного бизнеса — очевидна. Однако в мире отсутствуют единые общепринятые нормативы для оценки его коммерческой стоимости, которые хотя бы приблизительно могли бы соперничать с детальными методиками оценки более традиционных активов — недвижимого имущества и т. п.
Всё это способствует появлению различных практических проблем: например, под залог доменного имени, которое зачастую может быть оценено в шестизначную сумму, компании невозможно получить банковский кредит. А в случае банкротства этот ценный актив и вовсе может быть безвозвратно утерян. Потому появление и принятие таких стандартов, несомненно, важное событие. Это очередной шаг к стандартизации методик оценки, формированию профессиональных инструментов, с помощью которых бизнес сможет эффективно работать с собственными цифровыми активами», — комментирует руководитель юридического отдела REG.RU Павел Патрикеев.
Методика предназначена для аккредитованных регистраторов в зонах .RU и.РФ, специалистов по оценке интеллектуальной собственности, а также для всех участников вторичного рынка доменных имён: покупателей, продавцов, владельцев сервисов купли-продажи доменных имён. С полной версией можно ознакомиться на сайте КЦ: cctld.ru/upload/iblock/11c/KC_buklet_2020.pdf
REG.RU — хостинг-провайдер и аккредитованный регистратор доменных имён №1 в России (по данным StatOnline.ru, занимает первое место по количеству зарегистрированных доменов и размещённых сайтов в национальных зонах .RU и.РФ). Компания обслуживает более 3 300 000 доменов и предлагает регистрацию в 750 международных доменных зонах, а также предоставляет услуги хостинга, почты, VPS, аренды физических серверов и облачных вычислений на GPU. Занимает первое место в рейтинге хостинг-провайдеров России. В 2012 году REG.RU стал аккредитованным ICANN регистратором. Офисы REG.RU расположены в 30 городах России и СНГ.