102 IX: как мы подключили больше ста точек обмена трафиком и автоматизируем пиринг
Качественный BGP-пиринг — одна из главных причин хорошей связности глобальной сети G-Core Labs, охватывающей пять континентов. Мы присутствуем уже на 102 точках обмена трафиком, работаем с 5000 партнёрами по пирингу и входим в топ-10 сетей мира по количеству прямых пирингов. О том, как нам это удаётся — под катом.
Что такое BGP-пиринг
BGP-пиринг — это обмен интернет-трафиком между автономными системами (AS) напрямую, в обход вышестоящих операторов связи (аплинков).
Он помогает участникам точки обмена трафиком (IX, Internet Exchange) сокращать маршруты передачи данных между сетями, снижать затраты на трафик, а также в большинстве случаев и время отклика (RTT). Через точку обмена трафиком проще соединиться сразу c несколькими участниками: вместо отдельного коннекта к каждому достаточно одного соединения с IX, где все эти участники присутствуют.
Каждый участник IX выигрывает за счёт экономии на каналах и закупке трафика у аплинков. Это выгодно и для конечного пользователя: сокращаются сетевые задержки и время отклика до ресурсов.
Таким образом, чем больше точек обмена трафиком, тем лучше связность интернета и тем он доступнее.
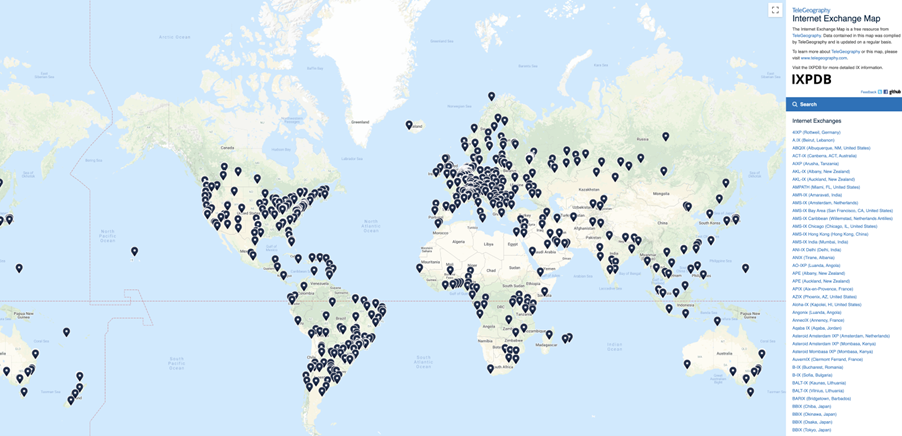
Первые точки обмена трафиком начали появляться с 1994 года в крупных европейских городах: Лондоне (LINX), Франкфурте (DE-CIX), Амстердаме (AMS-IX), Москве (MSK-IX). Сейчас во всём мире работает более 500 IX
Как мы выбираем дата-центры и точки обмена трафиком
Мы подбираем дата-центры по количеству операторов первого (Tier1) и второго (Tier2) уровней и локальных IX.
Почему пиринг требует нестандартных решений
BGP-пиринг — это не просто наше присутствие на отдельно взятой точке обмена трафика. Здесь требуются комплексный подход и слаженная работа всех команд.
Быть участником IX недостаточно, так как многие eyeball-операторы связи имеют закрытую пиринговую политику (например, Selective или Restrictive). Это означает, что оператор не отдаёт свои сети на Route Server (сетевой сервис, позволяющий упростить пиринговое взаимодействие между участниками IX и сократить количество индивидуальных администрируемых пиринговых сессий).
Поднятие пирингов с такими операторами — это результат долгих переговоров между пиринг-менеджерами, в результате которых появляется сам BGP-пиринг и обмен трафиком происходит напрямую.
Немалую роль здесь играет и автоматизация самого процесса по конфигурации. Когда количество точек обмена трафиком переваливает за 15, а общее количество пиров за 1000, управлять этим вручную силами инженеров становится невозможно. Поэтому мы разработали полностью автоматизированный цикл настройки и управления BGP-сессиями без участия человека. Сетевому инженеру остаётся лишь согласовать пиринг, остальное делает автоматика.
Почему мы не стали использовать готовые решения по автоматизации пиринга
Подходы к автоматизации пиринга от большой четвёрки глобальных операторов (Google, Microsoft, AWS, Cloudflare) нам не подошли.
Google и Microsoft используют Web Peering Portal, к которому непросто получить доступ. К тому же в случае Microsoft надо оформить минимальную подписку на Azure.
После получения доступа вам нужно заполнить информацию о себе (как об операторе), пройти верификацию и только потом получить возможность создавать запросы на пиринг. Для каждого запроса обычно создаётся отдельная задача, где также требуется заполнить информацию и внести (выбрать) параметры для BGP-сессии.
Как правило, на создание одного запроса может уходить до 10 минут. Теперь представим, что нам нужно сделать 200 таких запросов, чтобы поднять все нужные нам сессии по всему миру. И это только для одного оператора. Можно легко посчитать, сколько времени нужно затратить на такую задачу. И это без учёта времени ответа на письма, в которых могут быть дополнительные вопросы. Куда проще послать одно письмо из нескольких слов и в течение суток получить ответ уже с преднастроенной конфигурацией.
С какими проблемами пришлось столкнуться:
Как автоматизирован наш пиринг сегодня
Достаточно послать запрос на noc@gcore.lu с темой Peering и номером ASN, отличным от нашей (199524).
Зачастую наши потенциальные пиринг-партнёры сами направляют запросы на организацию пиринга. Далее эти запросы попадают в оркестратор и система проводит анализ их целесообразности. Если запрос удовлетворяет нашим критериям, система автоматически настраивает соответствующие сессии и высылает конфигурацию участнику.
Мы предпочитаем настраивать пиринг на всех точках обмена трафиком, где у нас есть совпадения с оператором, который запросил пиринг. Такой подход экономит время и для нашего пиринг-партнёра, позволяя добиваться максимальной эффективности. По мере роста сети этот подход оказался самым удобным и для нас, и для партнёров.
Бывают и обратные ситуации, когда мы делаем запрос на пиринг с потенциально интересующим нас партнёром, как правило, с крупным оператором.
Как мы оцениваем целесообразность пиринга:
Какие данные мы анализируем
Мы анализируем данные, которые собираются с наших пограничных маршрутизаторов посредством NetFlow/JFlow. Имея эти данные, мы знаем о своём трафике всё до последнего байта.
Как мы оцениваем эффективность пиринга и связность сети
Мы используем телеметрию с наших сервисов. Для этого у нас есть разные продукты, в том числе CDN, насчитывающая уже больше ста точек присутствия и входящая в топ-10 сетей доставки контента в Европе и Азии по данным CDNPerf.
Основные метрики, которые мы берём в расчёт со стороны сети, — это Packet Loss и Round-Trip Time до конечного пользователя.
На скольких IX мы присутствуем
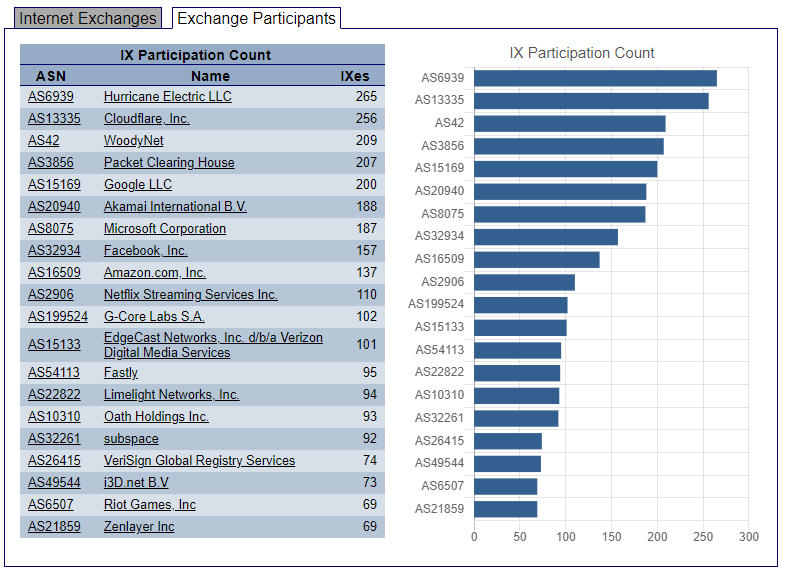
Мы присутствуем уже на 102 точках обмена трафиком по всему миру. Это стало возможным благодаря мощной сетевой инфраструктуре, без которой пирингов быть не может. Ведь чтобы включить точку обмена трафиком нужно локальное присутствие, а это уже подразумевает наличие инфраструктуры, сетевого оборудования и каналов передачи данных.
Как мы планируем улучшать связность сети
Сейчас в приоритете страны Латинской Америки, Африки и Азии. Это потенциально очень большой и перспективный рынок, над которым мы работаем и будем продолжать работать.
Приглашаем к бесплатному пирингу
G-Core Labs — быстро развивающийся контент-оператор с собственной экосистемой облачных сервисов и глобальной инфраструктурой. В её развитии нам помогают технологии Intel: в апреле 2021 мы одними из первых начали интеграцию Intel Xeon Scalable 3-го поколения (Ice Lake) в серверную инфраструктуру своих облачных сервисов.
Мы сформировали обширную пиринговую сеть и придерживаемся открытой пиринговой политики. Сейчас мы приглашаем всех заинтересованных участников к бесплатному пирингу через точки обмена трафиком.
Преимущественно мы заинтересованы в пиринге с крупными операторами широкополосного доступа, а также с мобильными операторами. Для получения более детальной информации посетите нашу страницу на PeeringDB или напишите нам по адресу noc@gcore.lu. Подробней о пиринге можно узнать на этой странице. gcorelabs.com/ru/internet-peering/
Что такое BGP-пиринг
BGP-пиринг — это обмен интернет-трафиком между автономными системами (AS) напрямую, в обход вышестоящих операторов связи (аплинков).
Он помогает участникам точки обмена трафиком (IX, Internet Exchange) сокращать маршруты передачи данных между сетями, снижать затраты на трафик, а также в большинстве случаев и время отклика (RTT). Через точку обмена трафиком проще соединиться сразу c несколькими участниками: вместо отдельного коннекта к каждому достаточно одного соединения с IX, где все эти участники присутствуют.
Каждый участник IX выигрывает за счёт экономии на каналах и закупке трафика у аплинков. Это выгодно и для конечного пользователя: сокращаются сетевые задержки и время отклика до ресурсов.
Таким образом, чем больше точек обмена трафиком, тем лучше связность интернета и тем он доступнее.
Первые точки обмена трафиком начали появляться с 1994 года в крупных европейских городах: Лондоне (LINX), Франкфурте (DE-CIX), Амстердаме (AMS-IX), Москве (MSK-IX). Сейчас во всём мире работает более 500 IX
Как мы выбираем дата-центры и точки обмена трафиком
Мы подбираем дата-центры по количеству операторов первого (Tier1) и второго (Tier2) уровней и локальных IX.
- Публичный пиринг. Выбираем ведущих интернет-провайдеров в каждом регионе и стыкуемся с ними в крупнейших точках обмена трафиком.
- Приватный пиринг. У нас более 5000 партнёров по пирингу по всему миру. Это позволяет сохранять локальность трафика в разных регионах, сокращая задержки доставки контента между сетями.
Почему пиринг требует нестандартных решений
BGP-пиринг — это не просто наше присутствие на отдельно взятой точке обмена трафика. Здесь требуются комплексный подход и слаженная работа всех команд.
Быть участником IX недостаточно, так как многие eyeball-операторы связи имеют закрытую пиринговую политику (например, Selective или Restrictive). Это означает, что оператор не отдаёт свои сети на Route Server (сетевой сервис, позволяющий упростить пиринговое взаимодействие между участниками IX и сократить количество индивидуальных администрируемых пиринговых сессий).
Поднятие пирингов с такими операторами — это результат долгих переговоров между пиринг-менеджерами, в результате которых появляется сам BGP-пиринг и обмен трафиком происходит напрямую.
Немалую роль здесь играет и автоматизация самого процесса по конфигурации. Когда количество точек обмена трафиком переваливает за 15, а общее количество пиров за 1000, управлять этим вручную силами инженеров становится невозможно. Поэтому мы разработали полностью автоматизированный цикл настройки и управления BGP-сессиями без участия человека. Сетевому инженеру остаётся лишь согласовать пиринг, остальное делает автоматика.
Почему мы не стали использовать готовые решения по автоматизации пиринга
Подходы к автоматизации пиринга от большой четвёрки глобальных операторов (Google, Microsoft, AWS, Cloudflare) нам не подошли.
Google и Microsoft используют Web Peering Portal, к которому непросто получить доступ. К тому же в случае Microsoft надо оформить минимальную подписку на Azure.
После получения доступа вам нужно заполнить информацию о себе (как об операторе), пройти верификацию и только потом получить возможность создавать запросы на пиринг. Для каждого запроса обычно создаётся отдельная задача, где также требуется заполнить информацию и внести (выбрать) параметры для BGP-сессии.
Как правило, на создание одного запроса может уходить до 10 минут. Теперь представим, что нам нужно сделать 200 таких запросов, чтобы поднять все нужные нам сессии по всему миру. И это только для одного оператора. Можно легко посчитать, сколько времени нужно затратить на такую задачу. И это без учёта времени ответа на письма, в которых могут быть дополнительные вопросы. Куда проще послать одно письмо из нескольких слов и в течение суток получить ответ уже с преднастроенной конфигурацией.
С какими проблемами пришлось столкнуться:
- Человеческий фактор. Управлять конфигурацией в ручном режиме не представлялось возможным — одной из главных проблем стал бы человеческий фактор. Поскольку как бы ни был хорош сетевой инженер, в таких глобальных масштабах и он может допускать ошибки, которые могут приводить к простою сервиса.
- Автоматизация. Мы разработали собственную систему автоматизации с нуля и постоянно её дорабатываем. Ведь важно не только настроить BGP-сессию, но и поддерживать дальнейшее оперирование. Например, по статистике ежедневно мы поднимаем более 40 сессий, а удаляем примерно 20. Если смотреть за месяц, то это примерно 1200 новых сессий и 600–800 удалённых.
Как автоматизирован наш пиринг сегодня
Достаточно послать запрос на noc@gcore.lu с темой Peering и номером ASN, отличным от нашей (199524).
Зачастую наши потенциальные пиринг-партнёры сами направляют запросы на организацию пиринга. Далее эти запросы попадают в оркестратор и система проводит анализ их целесообразности. Если запрос удовлетворяет нашим критериям, система автоматически настраивает соответствующие сессии и высылает конфигурацию участнику.
Мы предпочитаем настраивать пиринг на всех точках обмена трафиком, где у нас есть совпадения с оператором, который запросил пиринг. Такой подход экономит время и для нашего пиринг-партнёра, позволяя добиваться максимальной эффективности. По мере роста сети этот подход оказался самым удобным и для нас, и для партнёров.
Бывают и обратные ситуации, когда мы делаем запрос на пиринг с потенциально интересующим нас партнёром, как правило, с крупным оператором.
Как мы оцениваем целесообразность пиринга:
- В первую очередь оценивается количество indirect-трафика (то есть трафика через наши upstream-каналы) за последние 30 дней.
- Если значение выше порогового, то в оценку идут другие параметры, например, есть ли сети данного оператора на Route Server в полном составе.
- Затем идёт выбор точек обмена трафика наиболее эффективных для нас.
Какие данные мы анализируем
Мы анализируем данные, которые собираются с наших пограничных маршрутизаторов посредством NetFlow/JFlow. Имея эти данные, мы знаем о своём трафике всё до последнего байта.
Как мы оцениваем эффективность пиринга и связность сети
Мы используем телеметрию с наших сервисов. Для этого у нас есть разные продукты, в том числе CDN, насчитывающая уже больше ста точек присутствия и входящая в топ-10 сетей доставки контента в Европе и Азии по данным CDNPerf.
Основные метрики, которые мы берём в расчёт со стороны сети, — это Packet Loss и Round-Trip Time до конечного пользователя.
На скольких IX мы присутствуем
Мы присутствуем уже на 102 точках обмена трафиком по всему миру. Это стало возможным благодаря мощной сетевой инфраструктуре, без которой пирингов быть не может. Ведь чтобы включить точку обмена трафиком нужно локальное присутствие, а это уже подразумевает наличие инфраструктуры, сетевого оборудования и каналов передачи данных.
Как мы планируем улучшать связность сети
Сейчас в приоритете страны Латинской Америки, Африки и Азии. Это потенциально очень большой и перспективный рынок, над которым мы работаем и будем продолжать работать.
Приглашаем к бесплатному пирингу
G-Core Labs — быстро развивающийся контент-оператор с собственной экосистемой облачных сервисов и глобальной инфраструктурой. В её развитии нам помогают технологии Intel: в апреле 2021 мы одними из первых начали интеграцию Intel Xeon Scalable 3-го поколения (Ice Lake) в серверную инфраструктуру своих облачных сервисов.
Мы сформировали обширную пиринговую сеть и придерживаемся открытой пиринговой политики. Сейчас мы приглашаем всех заинтересованных участников к бесплатному пирингу через точки обмена трафиком.
Преимущественно мы заинтересованы в пиринге с крупными операторами широкополосного доступа, а также с мобильными операторами. Для получения более детальной информации посетите нашу страницу на PeeringDB или напишите нам по адресу noc@gcore.lu. Подробней о пиринге можно узнать на этой странице. gcorelabs.com/ru/internet-peering/
















