Не прошло и два года с момента анонса, как Intel представила второе поколение процессоров Intel Xeon Scalable на новой архитектуре Cascade Lake. Официально — 2 апреля. Сама компания называет это крупнейшим запуском в своей истории, стратегически очень важным для неё. Что ж, давайте разбираться, что в этих новых Scalable такого особенного.
Что оставили?
Процессоры
Cascade Lake, а точнее Cascade Lake SP, как и их предшественники Skylake, всё так же относятся к платформе Purley, теперь уже второго поколения — Purley Refresh. Они полностью совместимы со Skylake на уровне разъёма, чипсетов и материнских плат, доставшихся по наследству от первого поколения. Но с нюансами — например, новый bios.
Не изменился техпроцесс. Те же 14 nm, правда, с оптимизациями.
Общая схема наименований и названий для серий Platinum, Gold, Silver, Bronze осталась прежней. Правда, «суффиксов» стало больше. К имеющимся L, M и T добавились новые Y, N, V и S. В нумерации сменилось значение второй позиции (сотни): теперь вместо единицы — двойка, то есть преемником, например, Gold 6140 будет Gold 6240. В остальном базовые характеристики и набор возможностей не изменились. Число ядер и объёмы кэшей держат позиции: до 28 и по 1 Мбайт L2 на ядро + до 38,5 Мбайт общего L3. Число и тип линий PCI-E такие же, как были, — 48 линий версии 3.0. Масштабируемость та же: до 3 линий UPI на 10,4 GT/s и до 8 (бесшовно) сокетов в системе.
Что добавили?
В целом, различных микроапдейтов много, но из более-менее существенных я бы выделил эти.
Во-первых, в Cascade Lake появились аппаратные заплатки против нашумевших в прошлом году уязвимостей. Intel представил программно-аппаратные решения против вариантов 2 (Spectre), 3, 3a и 4 (Spectre NG), L1TF (Foreshadow). Для Spectre Variant 1 всё так же предлагается только программный патч. То есть всё то, что уже есть в линейке Intel Core i9. А так это выглядит в пресс-релизе:
- Вариант 1. Защита осуществляется средствами ОС и VMM (Virtual Machine Monitor)
- Вариант 2. Hardware Branch Prediction Hardening (предотвращение будущих атак по данному методу) + средствами ОС и VMM
- Вариант 3. Hardware Hardening Вариант 3a. Hardware
- Вариант 4. Hardware + ОС/VMM L1TF. Уже закрыта благодаря Hardware Hardening в варианте 3
Во-вторых, появилась поддержка памяти DDR4-2933. Но с оговорками: только для линеек Gold и Platinum (Bronze и Silver по-прежнему работают с DDR4-2400) и только с одним DIMM на канал — в конфигурации с двумя DIMM на канал частота снижается до 2666 MT/s.
В-третьих, состоялась премьера Intel Optane DC Persistent Memory (DCPM). Самая четкая формулировка о том, что это такое, получилась у
Тискома, поэтому цитирую:
Intel Optane DC Persistent Memory (DCPM) — новый класс технологий, сочетающий те понятия, которые называются «memory and storage» и предназначаются для использования в центрах обработки данных
Может помните, ранее Intel представлял технологию Intel Memory Drive Technology для Xeon Skylake: гипервизор (Xen) + NVMe-модули Optane. У нас даже случились тесты по этому поводу, но результаты были не вдохновляющие, и мы решили подождать более впечатляющего решения. Кажется, дождались =)
В основе нового решения от Intel лежат модули DCPMM, визуально похожие с DIMM, а также электрически и механически совместимые с ними. Работают на скорости 2666 MT/s и имеют объём 128/256/512 Гбайт. На логическом уровне используют протокол DDR4-T (Transaction), который, по словам Intel, одобрен JEDEC, но на практике его поддержка есть только в контроллерах памяти Cascade Lake. То есть на разъём DIMM DDR4 посадили энергоНЕзависимую память, выполненную по технологии 3D XPoint, обгоняющую, опять же со слов Intel, широко распространённую NAND Flash на три порядка (в 1000 раз) по таким характеристикам как скорость и срок службы.
Решение оказалось очень интересным и крайне неоднозначным: естественно, есть особенности эксплуатации (не без этого), цена и области применения. Но мы заострять внимание на этой, для данной линейки процессоров, killer фиче не будем, — более подробный рассказ о ней выходит сильно за рамки сегодняшней статьи. Как только будут готовы тесты во всех возможных режимах работы этой технологии, сразу выкатим лонгрид :-)
В-четвёртых, технологии Intel Resource Director Technology (RDT), Speed Select (SST) и Intel DL Boost прокачались по скиллам. Начну с RDT. Он представляет собой механизмы достаточно тонкого мониторинга и контроля над исполнением приложений и использованием ресурсов. Штука не новая, но в данной линейке к ней хорошо приложили руки и детально проработали. Суть в том, чтобы приложение с более высоким приоритетом вовремя получало всё, что ему нужно. Естественно, за счёт «ущемления в правах» других приложений.
Теперь SST. Тут то же самое, но на уровне ядер: позволяет жёстко выделять группу ядер, которая будет иметь повышенный приоритет над другими. Появление в этот раз не дебютное, но вполне эффектное.
И на десерт Intel DL Boost. Нововведение касается нового набора инструкций, известного ранее как Vector Neural Network Instructions (VNNI). Штуковина для ИИ, а точнее, для более гибкой тренировки сетей глубокого обучения. По сути ещё одна надстройка над AVX-512.
И наконец,
в-пятых. По старой традиции для рефрешей от Intel — больше частоты, больше ядер :-) Как базовые частоты, так и частоты в бусте подросли на 200-300 МГц. За некоторым исключением добавилось по два ядра на процессор. Увеличился объём поддерживаемой оперативной памяти. Отдельно стоит отметить работу Intel по оптимизации использования кэшей и оперативной памяти, вероятно, для минимизации негативного влияния заплаток от уязвимостей семейства Spectre и Meltdown.
Более детально с особенностями архитектуры Cascade Lake можно ознакомиться на
wikichip. Рекомендую к прочтению. А теперь — уже традиционное тестирование.
ТЕСТИРОВАНИЕ
В тестировании участвуют восемь процессоров Intel Xeon Scalable:
- первое поколение — Silver 4110, Silver 4114, Gold 6130, Gold 6140,
- второе поколение — Silver 4210, Silver 4214, Gold 6230 и Gold 6240.
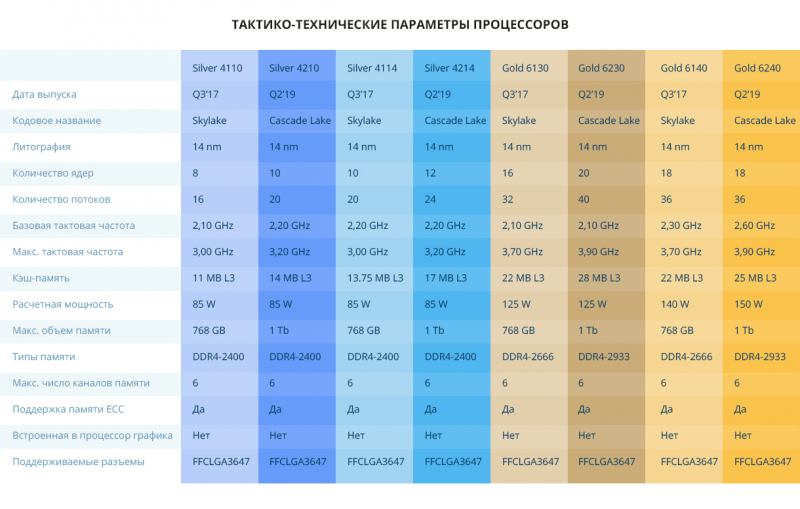 Тактико-технические характеристики платформ
Тактико-технические характеристики платформ
- Все процессоры имеют одинаковую базовую конфигурацию.
- Платформа: Intel Corporation S2600WFT (BIOS SE5C620.86B.02.01.0008.031920191559)
- Оперативная память:
- 16 Гб Samsung DDR4-2933 — 12 штук (по одной на каждый канал) для процессоров Gold 6230 и 6240
- 16 Гб Samsung DDR4-2666 — 12 штук (по одной на каждый канал) для процессоров Gold 6130 и 6140
- 16 Гб Samsung DDR4-2400 — 12 штук (по одной на каждый канал) для процессоров Silver обоих поколений
- SSD-накопитель: Intel DC S4500 480 Гб — 2 штуки в RAID1
- Двухпроцессорная конфигурация
- Программная часть: ОС CentOS Linux 7 x86_64 (7.6.1810)
- Ядро: 3.10.0-957.12.2.el7.x86_64
Внесённые оптимизации относительно штатной установки: добавлены опции запуска ядра elevator=noop selinux=0
Тестирование производится со всеми патчами от атак Spectre, Meltdown и Foreshadow, бэкпортироваными в данное ядро.
Список тестов, которые будем проводить:
- Geekbench
- Sysbench
- Phoronix Test Suite
РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯ
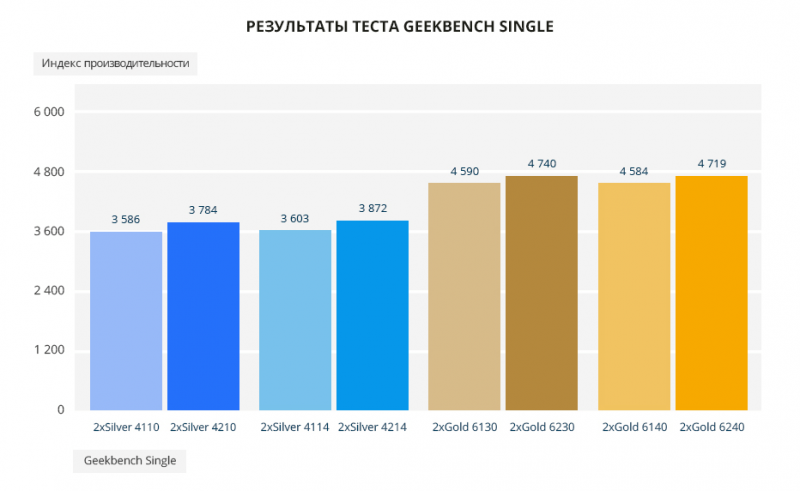
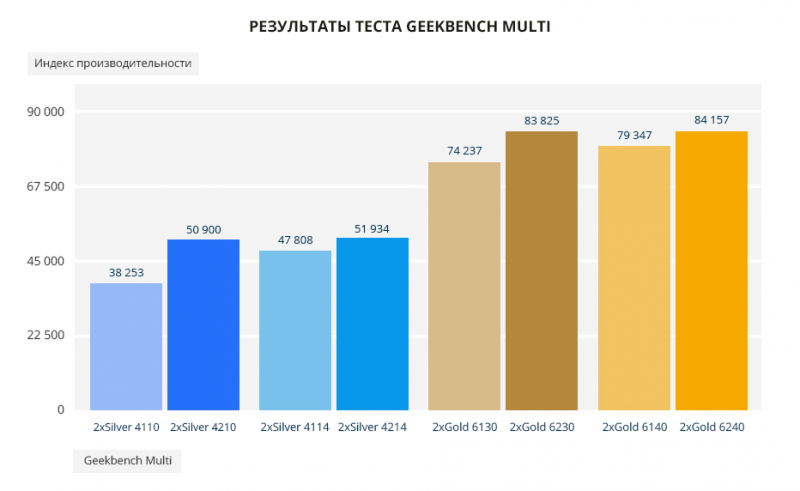
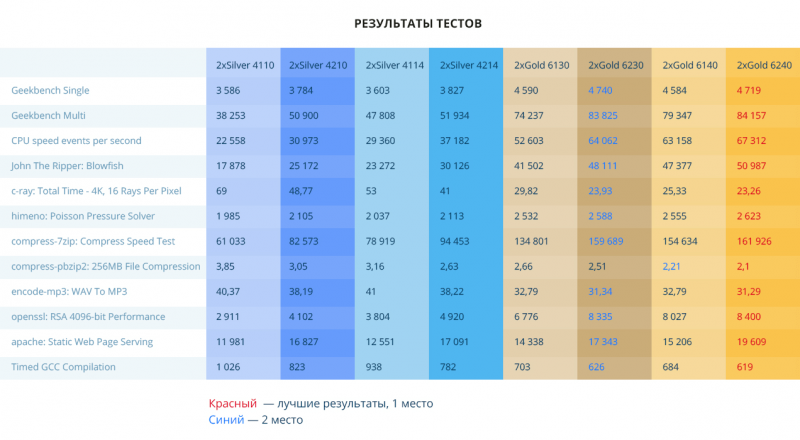
В тесте Geekbench в однопоточном и многопоточном варианте новые Scalable обходят старые по всем позициям. В однопоточном тесте от 3% до 6%, в многопоточном от 6% до 13%, и апофеоз — Silver 4210 лучше Silver 4110 аж на 33%.
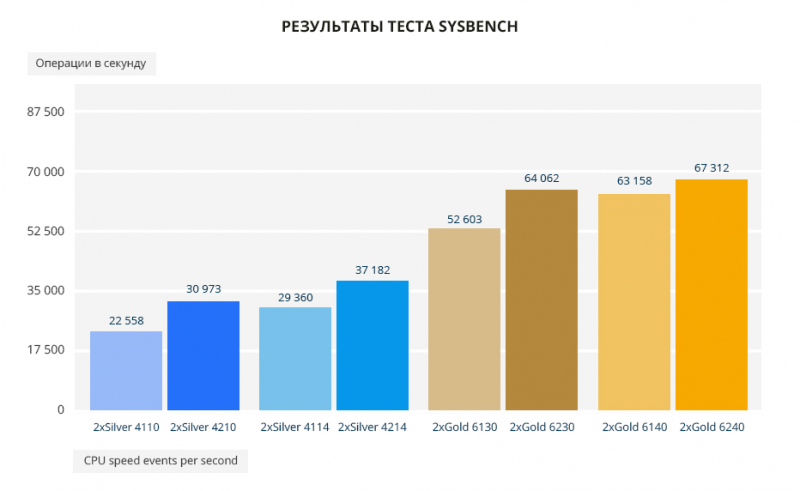
В тесте Sysbench разница от 22% до 37%. Минимальный разрыв между Gold 6140 и Gold 6240 — 7% в пользу нового.
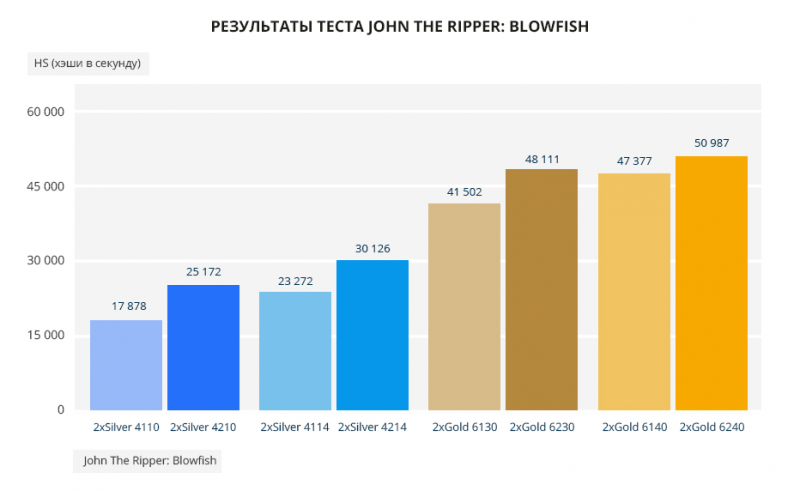
В тесте John The Ripper Silver 4210 обгоняет Silver 4110 на 41%, а между Silver 4214 и Silver 4114 разница почти на 30% — естественно, в пользу первого. Теперь голды. Gold 6230 быстрее Gold 6130 на 16%. Минимальный разрыв между Gold 6140 и Gold 6240 — 7,6%.
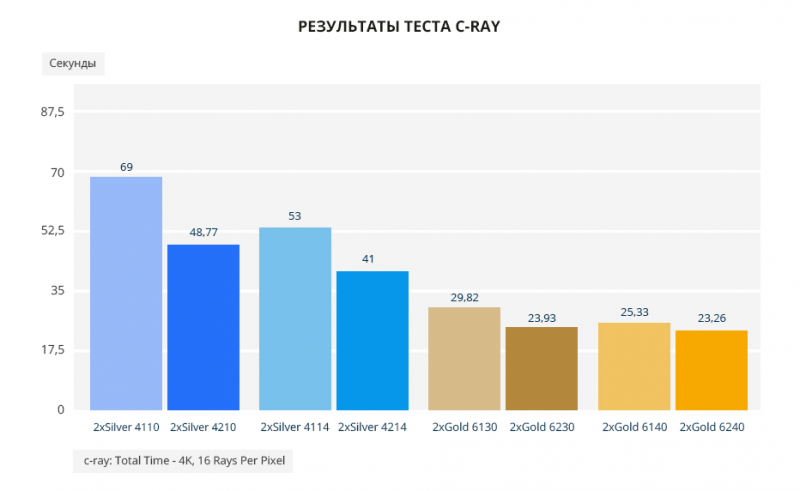
Silver 4210 обгоняет Silver 4110 на 29%, а Silver 4214 предшественника на 23%. Разрыв между парами Gold 20% и 8% соответственно.
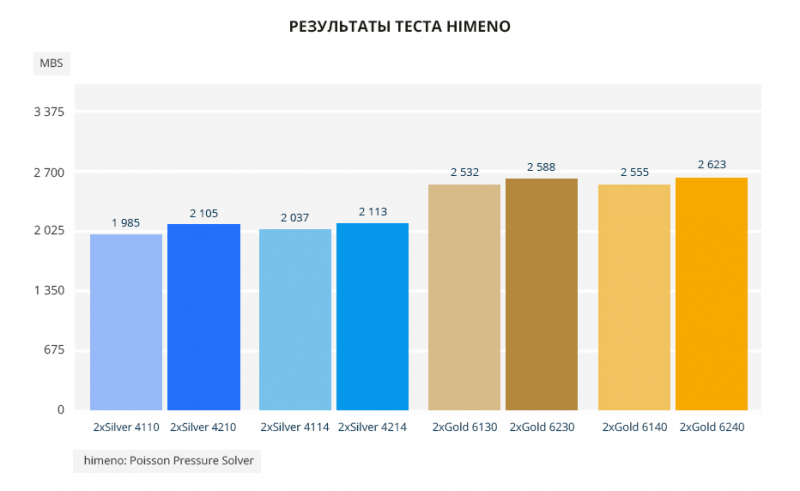
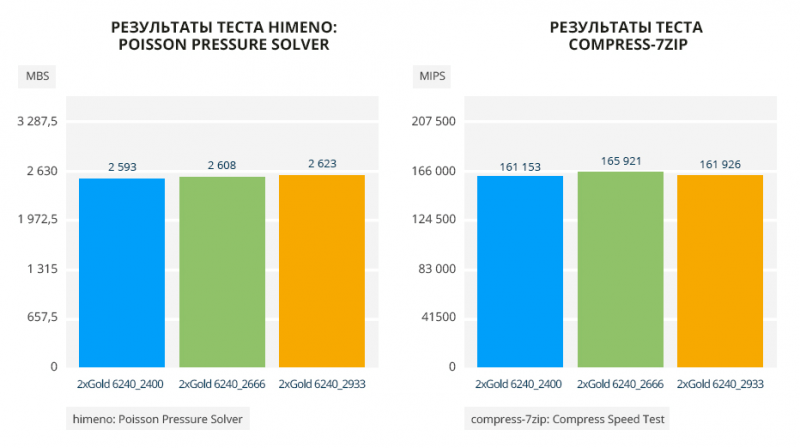
В однопоточном тесте Himeno можно увидеть чистый прирост 200-300 Мгц — от 2,2% до 6% в пользу нового поколения.
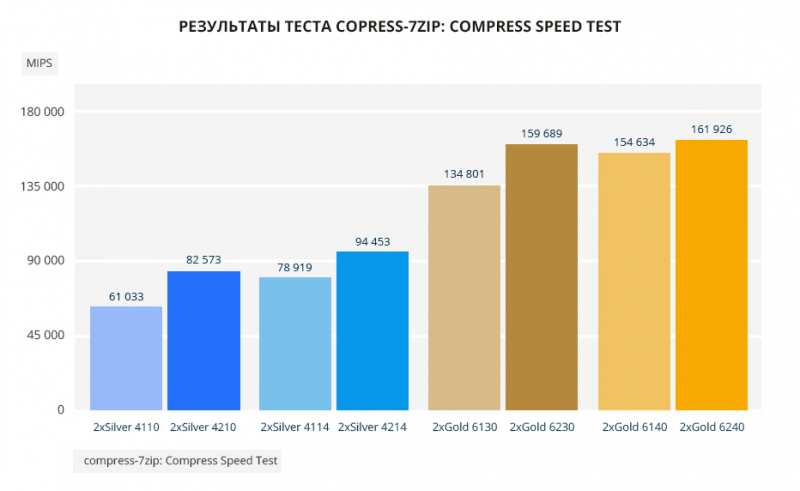
Тест compress-7zip почти полностью копирует результат теста John The Ripper: Blowfish. Красивый отрыв между Silver 4110 и Silver 4210: 4210 почти на 35% быстрее своего предшественника. Silver 4214 и Gold 6230 на 18% и 20% соответственно лучше 4114 и 6130. Минимальный разрыв между Gold 6140 и Gold 6240: новый лучше прежнего на 4,7%.
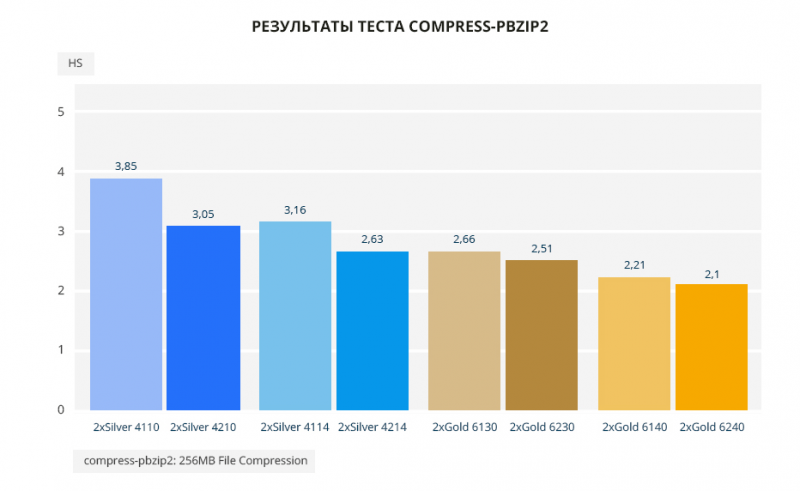
В тесте compress-pbzip2 картина аналогична тесту compress-7zip. Из существенных отличий — уменьшился разрыв между Gold 6130 и Gold 6230, здесь он составляет 5,6%.
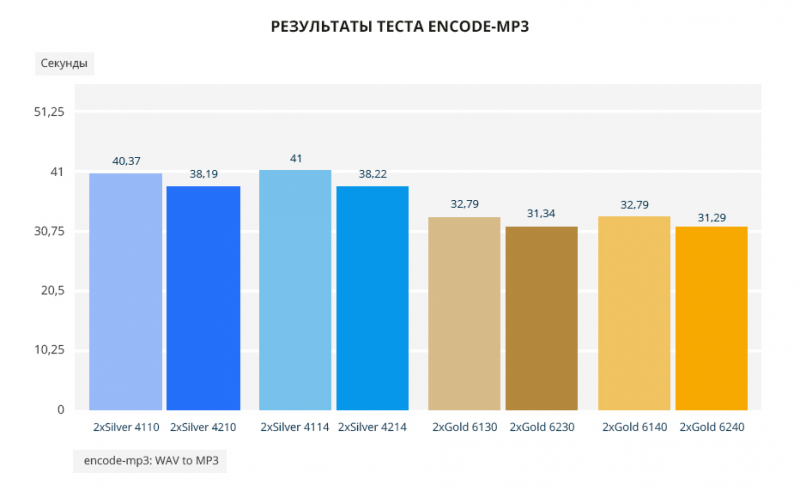
В однопоточном тесте Encode-mp3 снова видим разницу 200-300 МГц. От 4% до 7% — на столько Scalable второго поколения лучше первого в этом тесте.
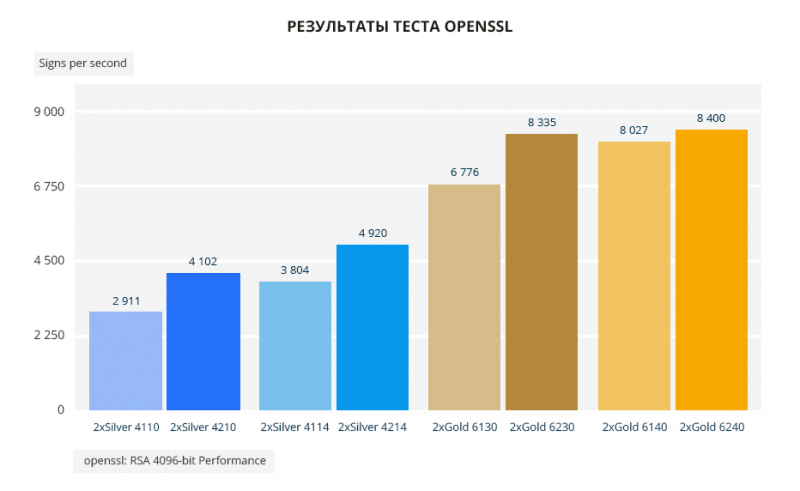
В тесте openssl самый большой разрыв между Silver 4110 и Silver 4210 — 41%. Между 4114 и 4214 — 29%. У голдов поменьше. Между Gold 6130 и 6230 — 23%. И в паре Gold 6140 и 6240 — 4,6%. Замечу, что Gold 6240 всего на 0,78% лучше Gold 6230.
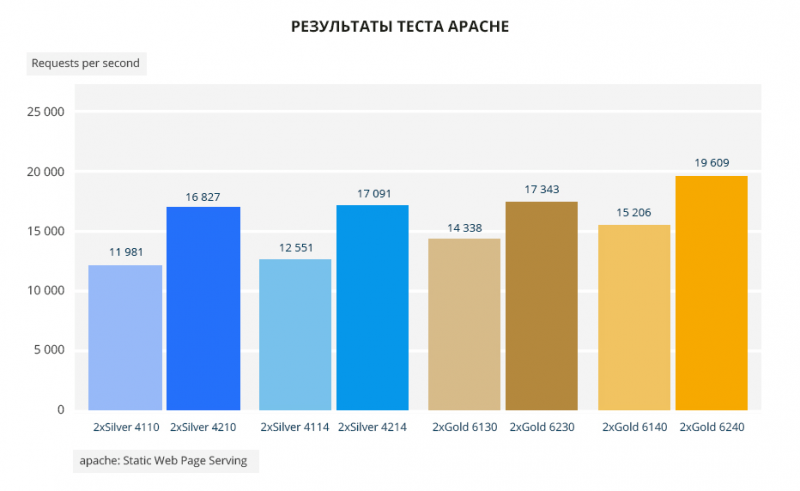
В тесте Apache Silver 4210 лучше Silver 4110 на 40%, Silver 4214 обгоняет Silver 4114 на 36%, Gold 6230 лучше Gold 6130 на 21% и Gold 6240 проходит этот тест лучше Gold 6140 на 29%. Особо заострю внимание на Silver 4210, Silver 4214 и Gold 6230: Gold 6230 на 3% лучше Silver 4210 и на 1,5% лучше Silver 4214. То есть разрыв минимален. Gold 6240 на 13% лучше Gold 6230.
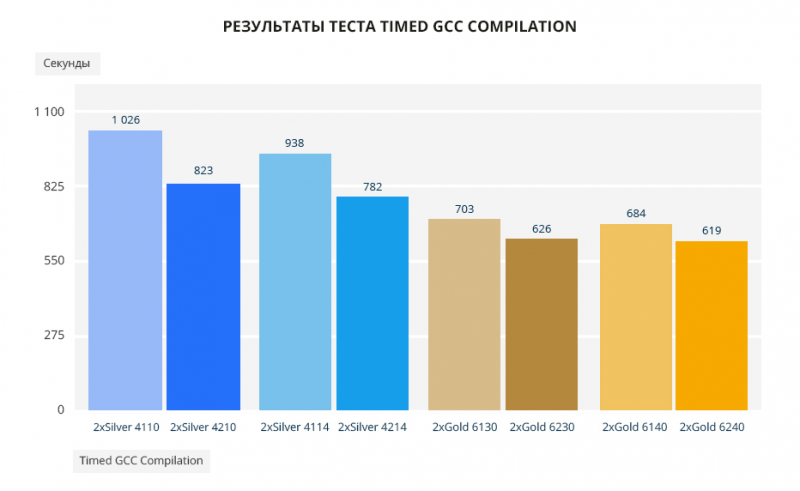
В тесте GCC новое поколение обгоняет своих предшественников примерно на 19%, 16%, 11% и 9,5% соответственно.
 Что получается в итоге.
Что получается в итоге.
Наблюдаем, значительный разрыв между Silver 4110 и Silver 4210 — новое поколение лучше предыдущего в многопоточных тестах примерно от 20% до 40%. Спасибо вам, частоты и ядра.
Между Silver 4114 и Silver 4214 разница уже меньше: тестовый максимум — в тесте Apache доходит до 36%.
Далее разрыв сокращается. Gold 6230 обгоняет Gold 6130 в пределах от 11% в тесте GCC и до 23% в тесте OpenSSL.
И наконец, минимальный разрыв у пары Gold 6140 и Gold 6240: новый опережает предыдущий на 3%-10% по результату большинства тестов. Исключение тест Apache: разница на 28% — меньше ядер, больше базовая частота (Apache вообще очень интересный тест).
А теперь переходим к дополнительным тестам. Но сначала краткая предыстория.
ТЕСТИРОВАНИЕ ОПЕРАТИВНОЙ ПАМЯТИ
Новые процессоры Intel Xeon Scalable линейки Gold 62xx стали поддерживать новый тип оперативной памяти DDR4-2933. Мы, что вполне логично, задались вопросом: насколько сильно частота оперативной памяти повлияет на общую производительность системы. Вообще, если исходить из предположения, что плюс на плюс всегда дает нечто положительное, верилось в то, что свежий процессор в паре с новой памятью покажут себя молодцами. Но одно дело предполагать, а другое — убедиться экспериментальным путём.
Для теста мы взяли процессор Gold 6240 в двухпроцессорной конфигурации. Тактико-технические характеристики платформы и программная составляющая не изменились. Память будем тестировать такую: DDR4-2400, DDR4-2666 и DDR4-2933.
Всегда радует, когда под рукой есть всё самое необходимое для проверки гипотез =) А теперь идём смотреть, что из этого получилось.
РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯ ОПЕРАТИВНОЙ ПАМЯТИ
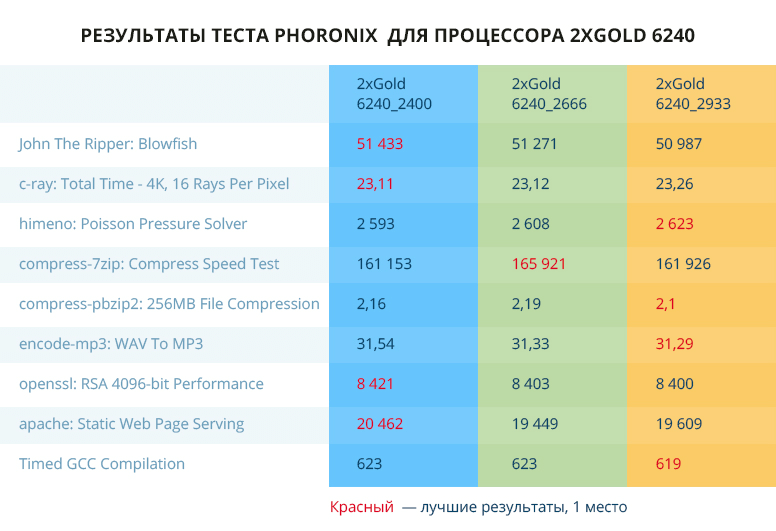
Когда слишком хорошо — это уже плохо. Поэтому я решил отказаться от идеи рисовать все графики и свёл результаты в таблицы — удобнее и быстрее, хотя и менее наглядно. Графики тоже будут, но лишь самые интересные, на мой взгляд.
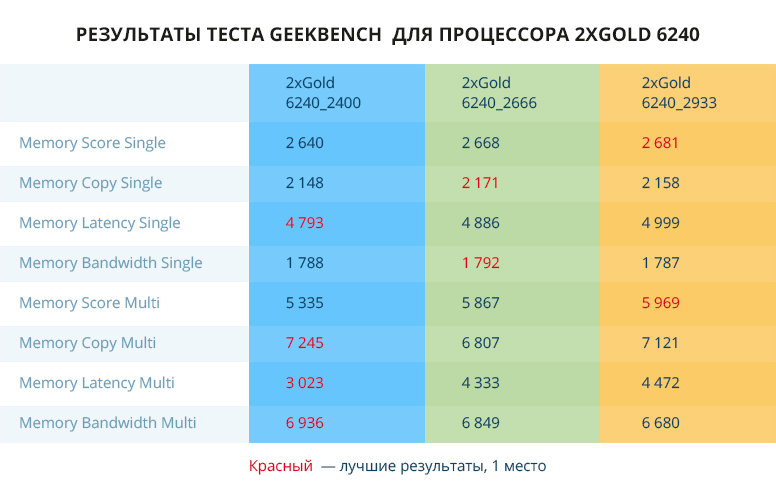
«Либо мы делаем что-то не так, либо одно из двух».
Цитата братьев Пилотов, пусть и слегка перефразированная, оказалась как нельзя кстати после того, как тестирование памяти было завершено…
Как и во всех тестах, мы сделали десять замеров и выбрали средние по ним показатели. Как видите, показания тестов разнятся так же сильно, как показания гражданки Кроликовой из кинофильма «Ширли-мырли».
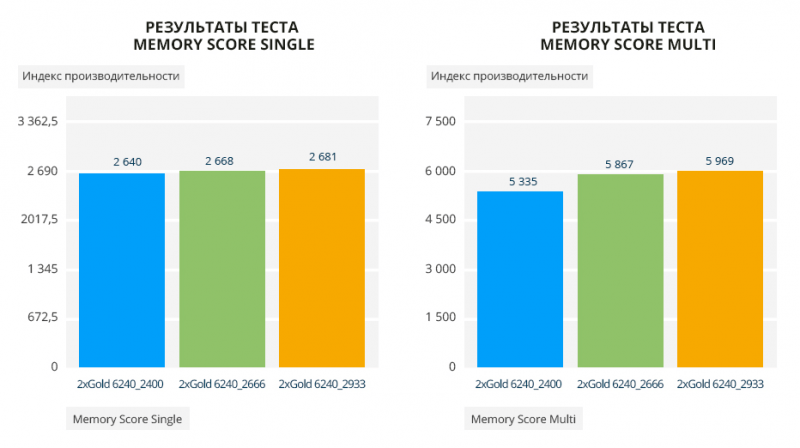
В тестах Phoronix 50 на 50 высокие результаты показывают конфигурации с ОЗУ 2400 и 2933 МГц. Тест Geekbench заценил 2933 память по параметрам Memory Score_Single и Memory Score_Multi, но общий результат удивляет.
Из предположений — влияние большей частоты на latency. А отсюда баланс между скоростью и временем отклика. Но, честно говоря, не уверен… Если есть, что сказать по этому поводу — прошу в комментарии.
В прошлый раз я убедился в том, что большее влияние на результаты тестов оказывает неиспользование всех каналов памяти процессора. В следующем тестировании процессора обязательно рассмотрим это влияние и я расскажу, что да как.
МАЛЕНЬКИЙ ШАГ ДЛЯ ЧЕЛОВЕКА, НО ОГРОМНЫЙ — ДЛЯ ЧЕЛОВЕЧЕСТВА
Как сказал бы товарищ Камнеедов (люблю я Стругацких), «примерно в таком аксепте» Intel и позиционирует новую линейку процессоров Xeon Scalable. Еще в начале статьи я говорил, что выход новых Scalable для самого Intel — важный стратегический шаг. Теперь поясню.
С одной стороны, новые Scalable положили начало глобальному обновлению платформы для центров обработки данных. И уже во второй половине года нас ожидает парочка интересных анонсов. С другой, все нововведения не случайны — это ответ на текущие запросы индустрии. И вполне себе достойный ответ. Мало памяти? Вот вам Optane DC Persistent Memory. Хотели аппаратную приоритезацию процессов и ядер? Пожалуйста, прокачали SST и RDT. Мечтали о профессиональной тренировке сетей? :-) Вот, распишитесь, новый набор инструкций для ИИ. За Intel можно только порадоваться.
Хотя, лично у меня, складывается впечатление, что в данный релиз вошли «хотелки», которые Intel не успели реализовать в прошлый раз. И, конечно, что-то нужно было делать с аппаратными дырами, поиск которых для разных спецов стал уже своеобразным развлечением. Всё, что Intel отобрал у пользователя дырами Спектрами-Мелтауны, он теперь вернул, сохранив цену.
К тому же со всех сторон наступает AMD, чьи решения в значительно меньшей степени оказались подвержены негативному влиянию Спектра-Мелтдаунов, и которая в последнее время особенно «труба шатал» Intel как в десктопном (хотел бы я иметь в таком солидном возрасте подобную моложавость), так и слегка в серверном сегменте. Кстати, в плане последнего очень интересно посмотреть, как покажут себя новые AMD Epyc Rome, так как нынешнее поколение Epyc лично меня не оставило равнодушным.
Но вернемся к Scalable.
Что же в сухом остатке получает пользователь, не отягощенный ИИ и тренированными сетями? Однозначно явный прирост производительности за счёт большего количества ядер, более высоких базовых частот и частот в турбобусте. И если для процессоров Gold разных поколений этот прирост в максимуме достигает 23% — хороши и те, и другие, то для Silver в некоторых тестах доходит до 40%. С учётом почти не изменившейся стоимости разница вполне приятная, хотя мне как всегда хочется большего =)
Если опираться на заявление самого Intel о том, что это только начало, даже такому скептику, как я, любопытно увидеть, что интересного нам предложат в будущем.
В тестировании использовались серверы на базе процессоров Intel Xeon Scalable: Silver 4110, Silver 4114, Silver 4210, Silver 4214, Gold 6130, Gold 6140, Gold 6230, Gold 6240.
Для вас тестировал и писал Григорий Прадедов, старший системный администратор отдела эксплуатации FirstDEDIC