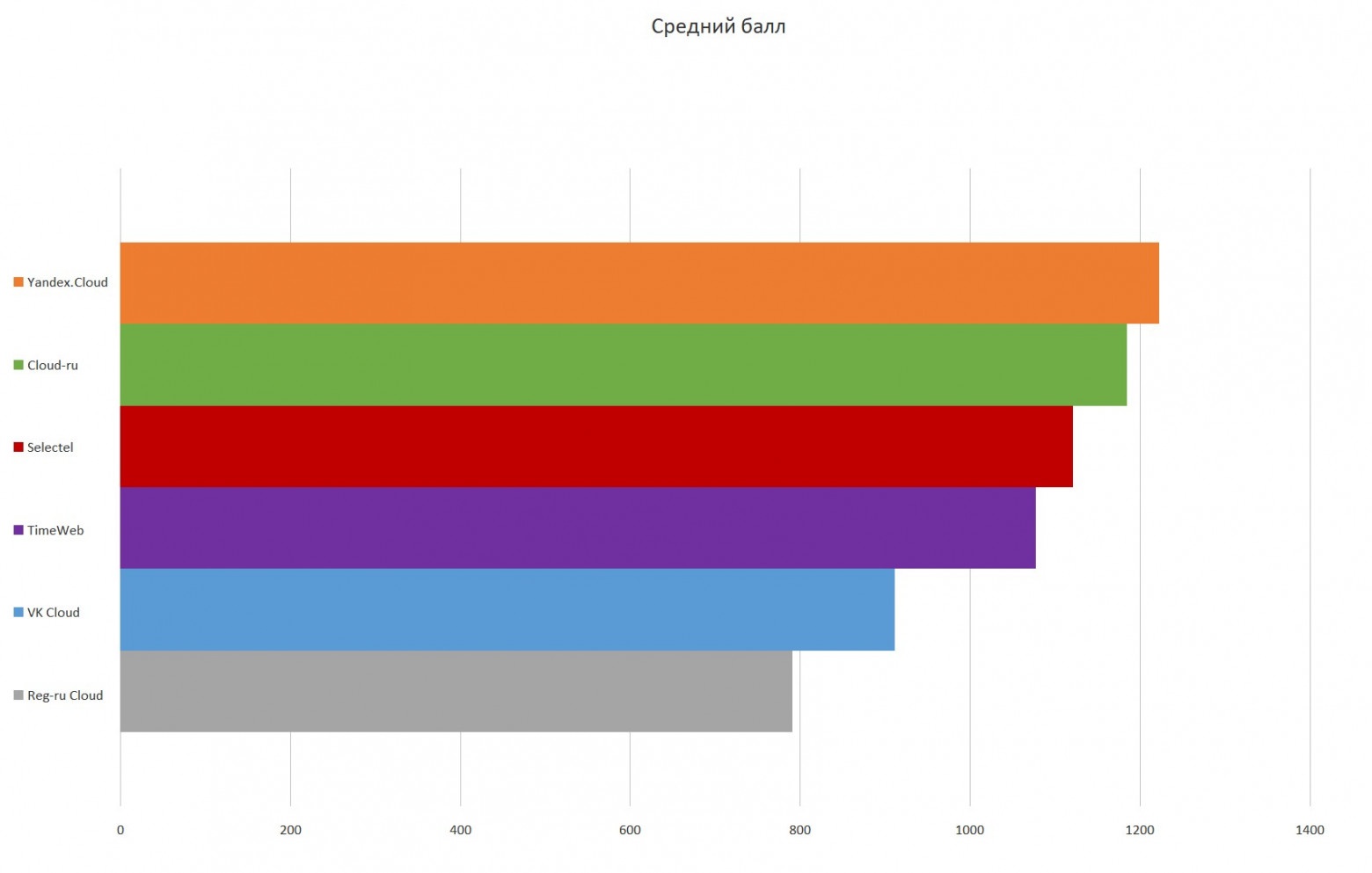
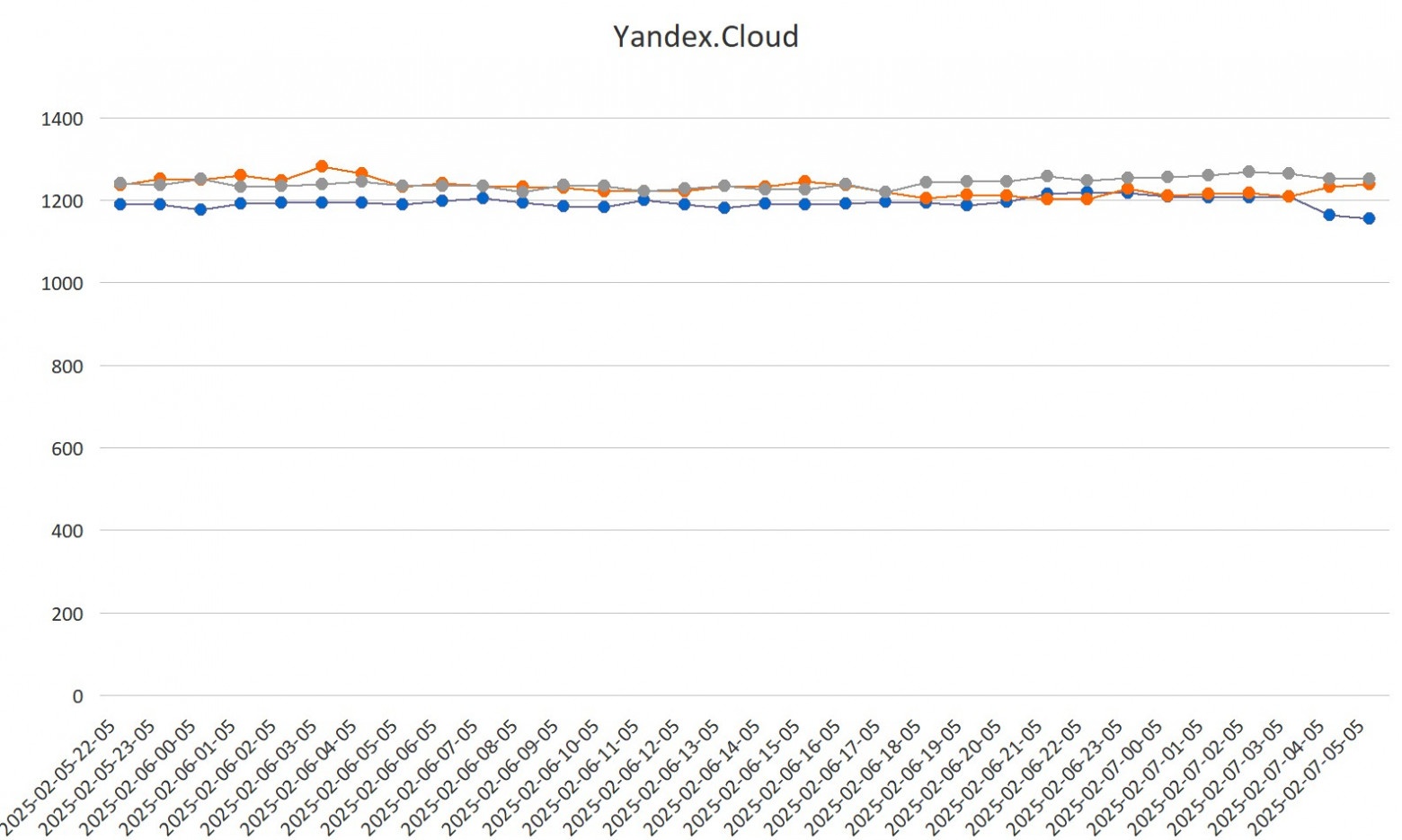
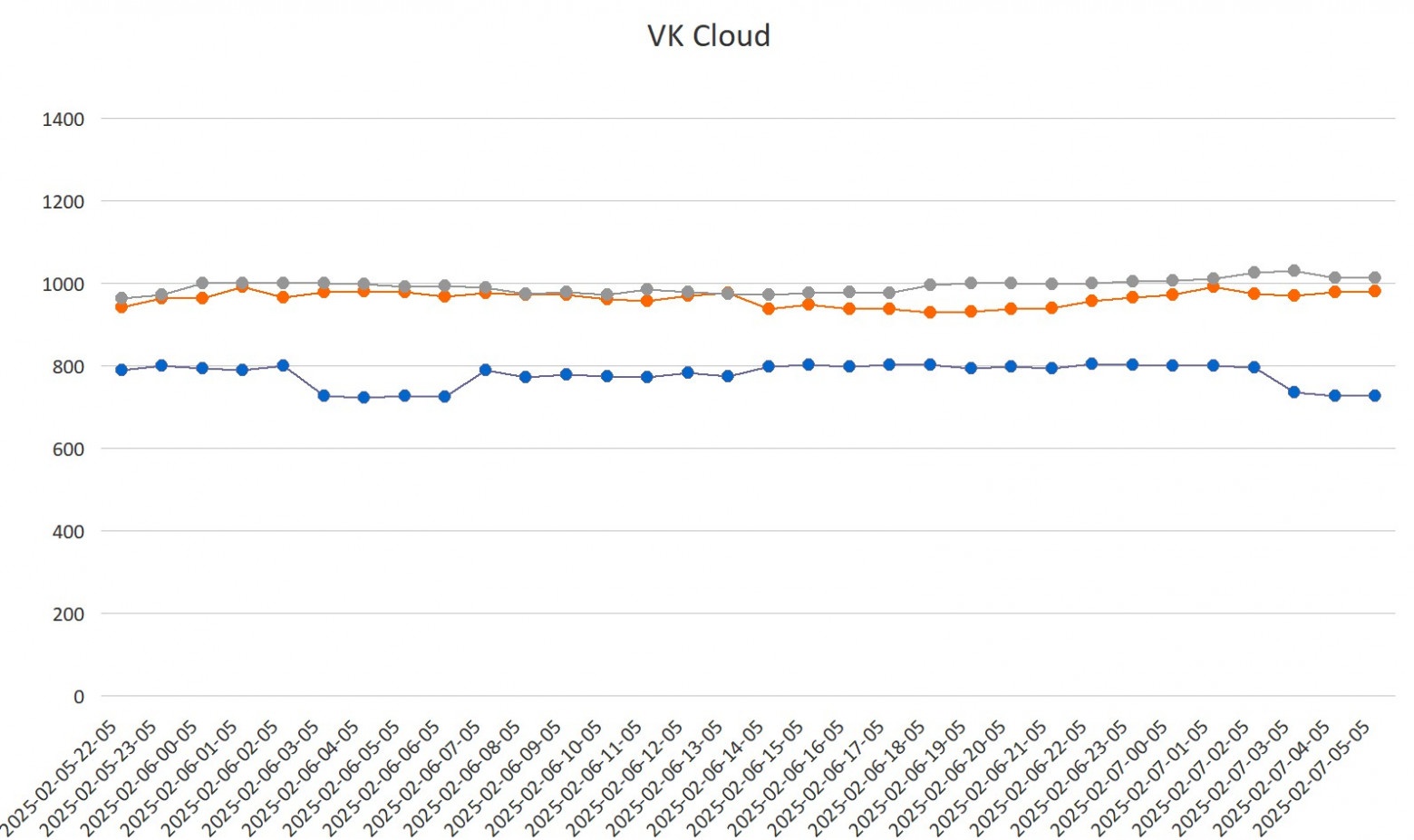
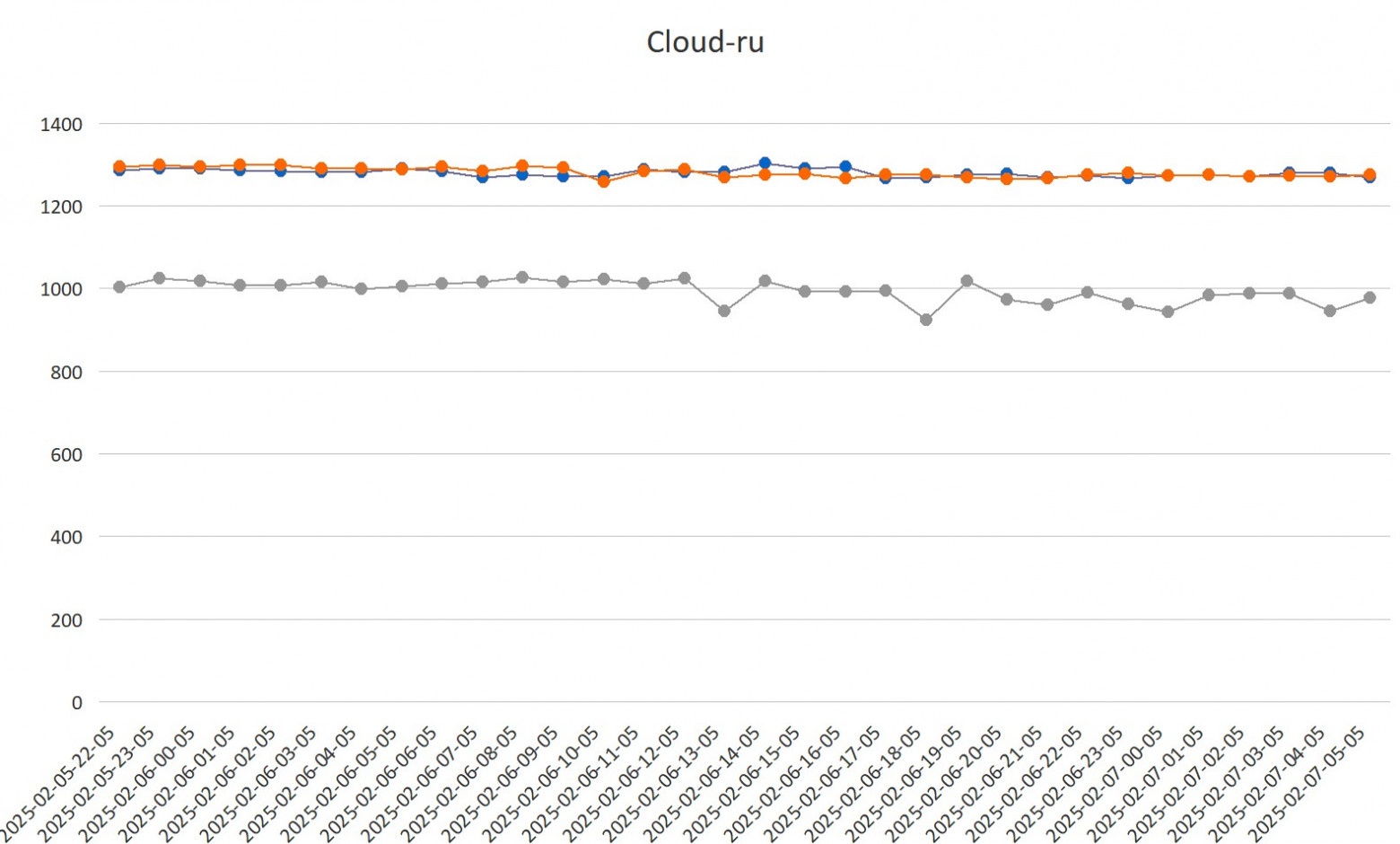
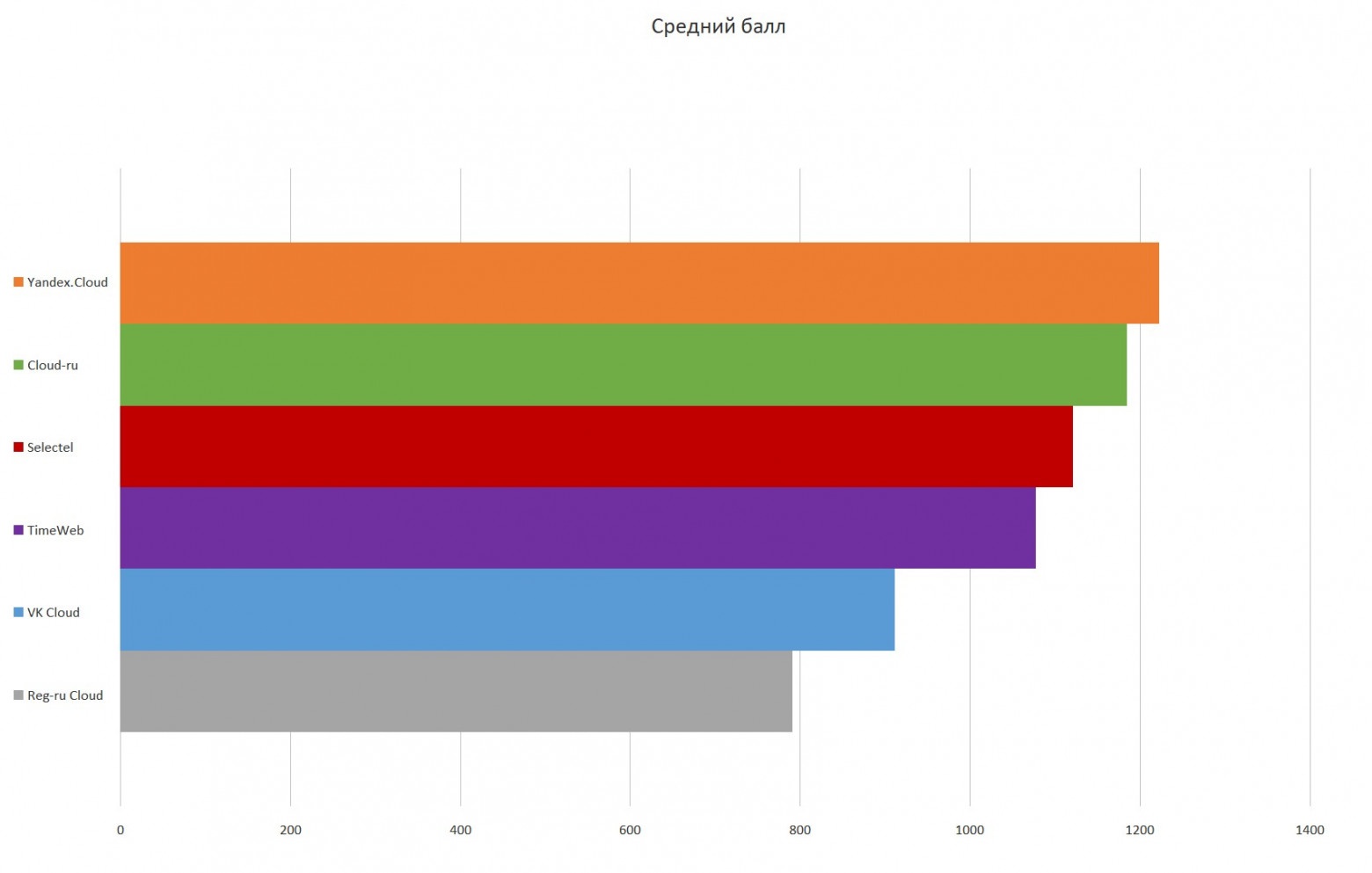
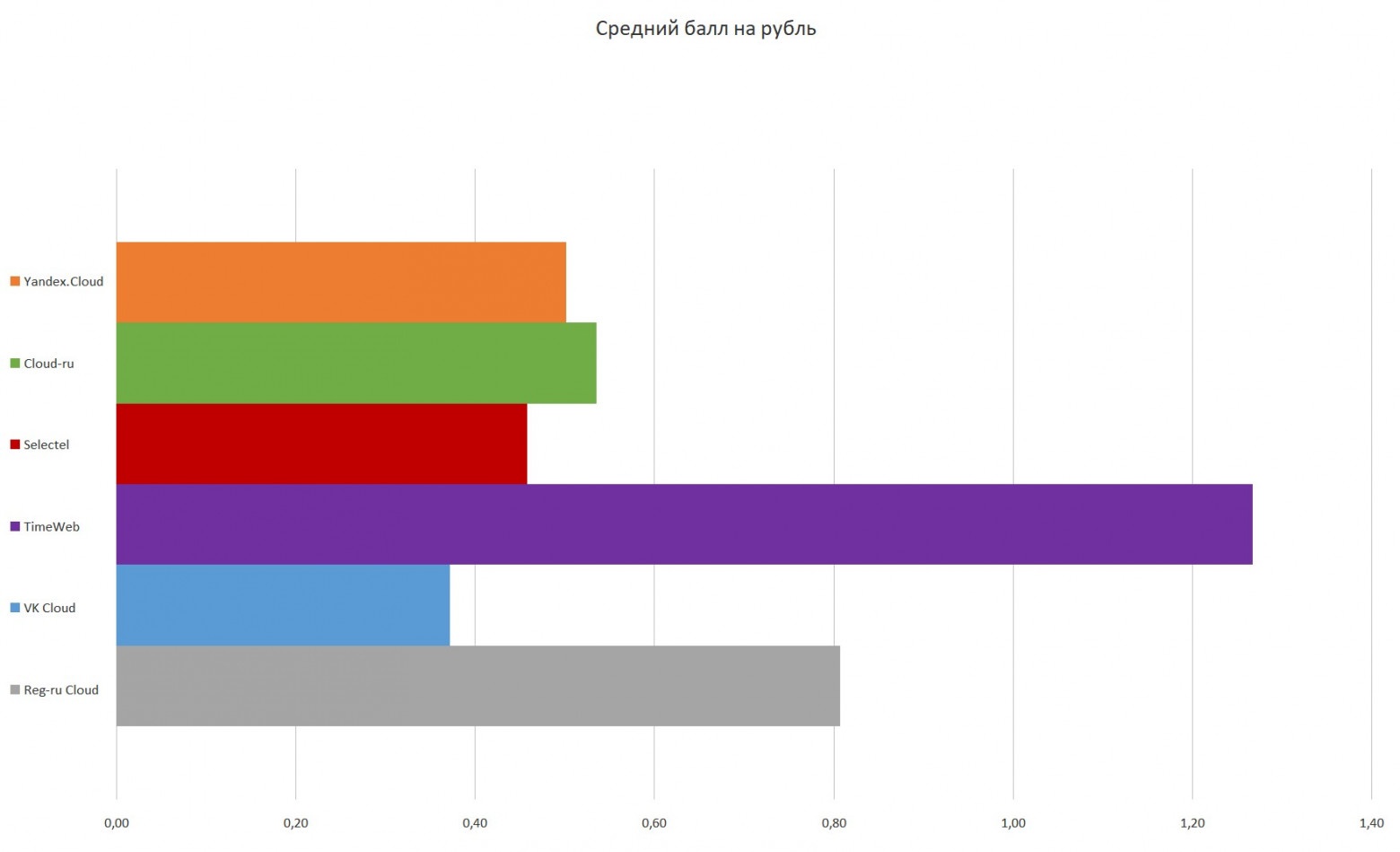
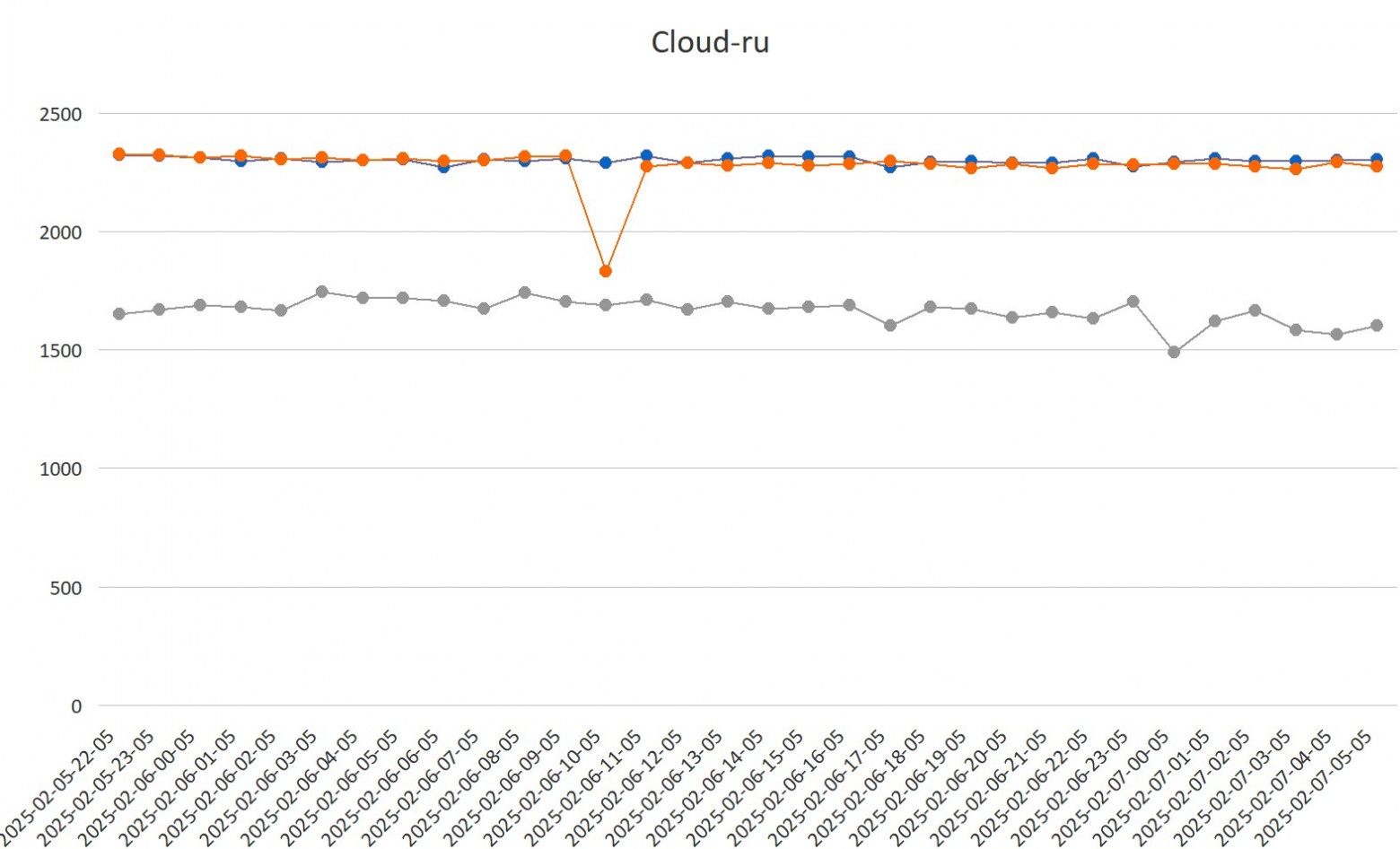
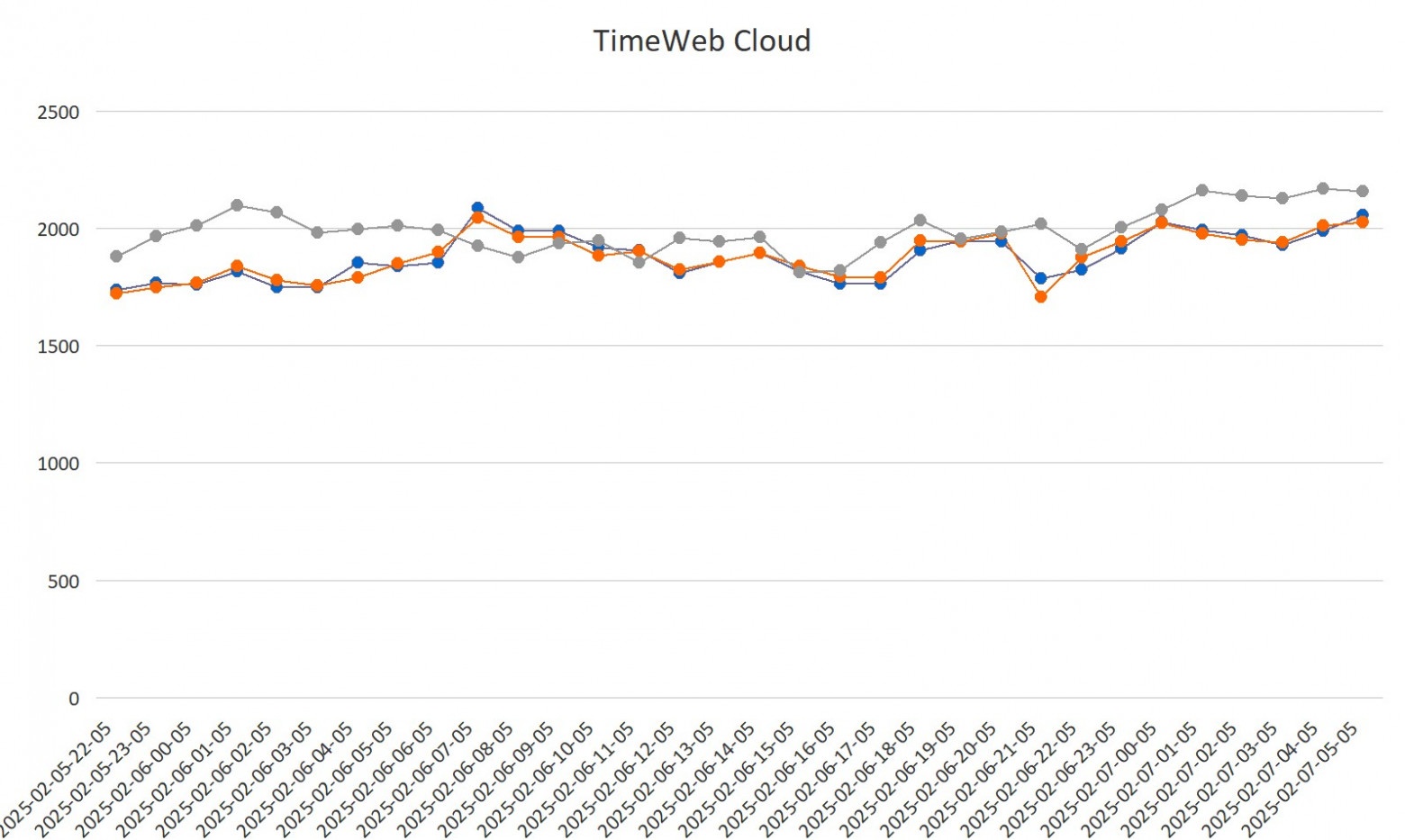
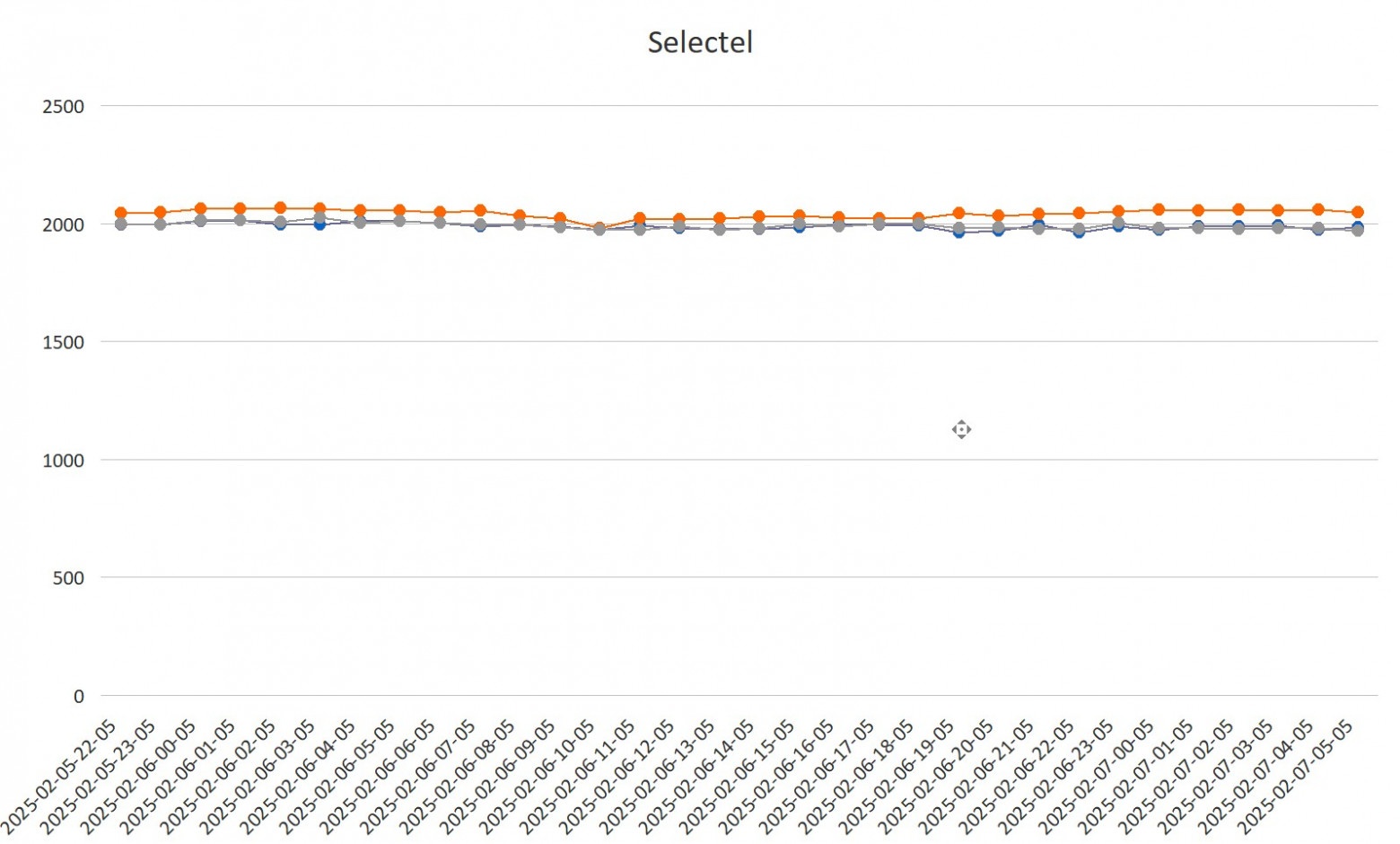
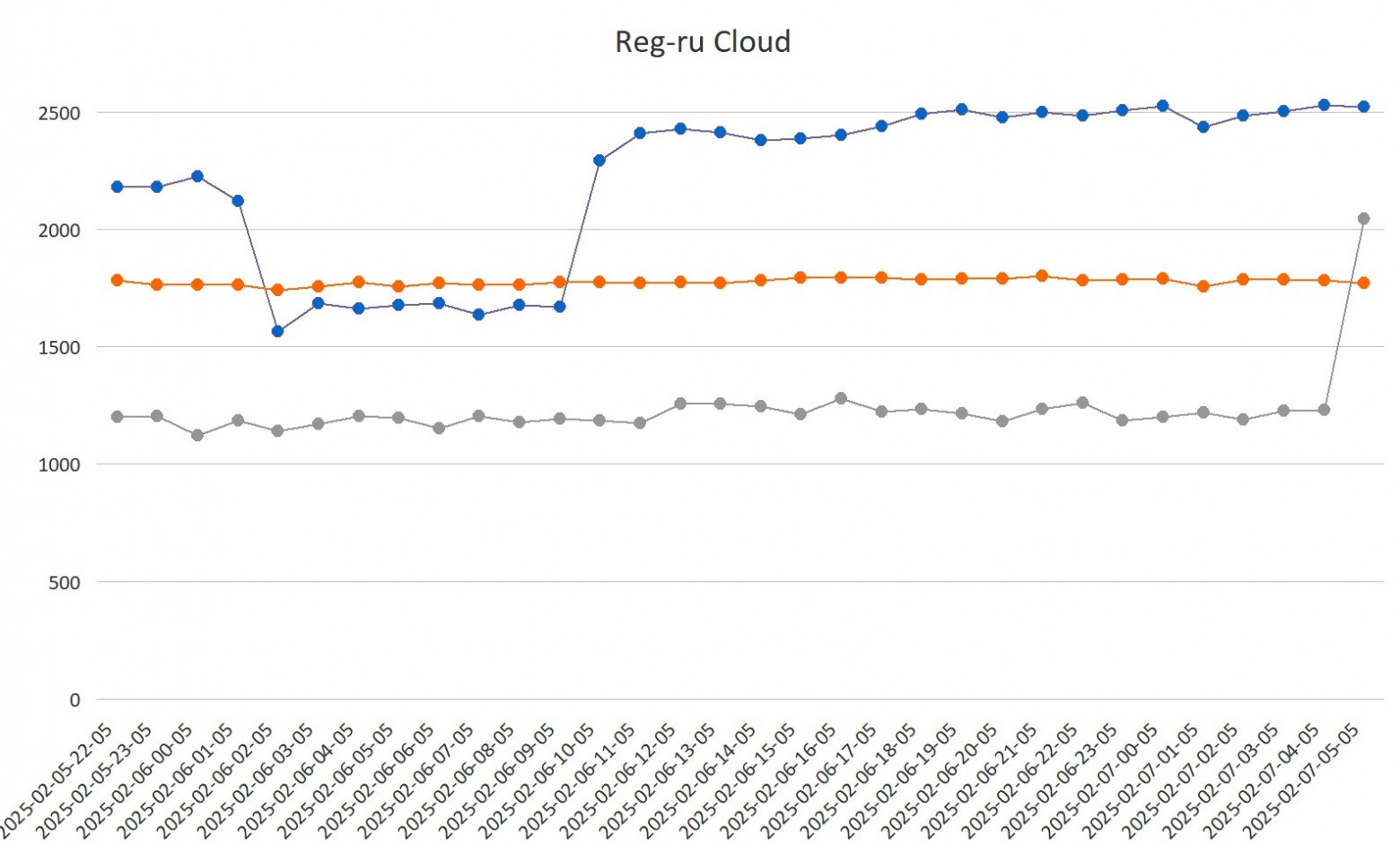
Это один из тех адских опенсорсных проектов, которые отлично начинались в 2010-м, но потом с сообществом что-то пошло конкретно не так. Можно сказать, что перед нами — опенсорс, болеющий всеми корпоративными проблемами.
В целом с 2019 года развитие проекта буксует, а количество участников комьюнити постепенно снижается. Некоторые сервисы не развиваются или вовсе закрываются из-за недостатка мейнтейнеров.
Но при этом, если вы строите публичное облако в России, варианты выбора у вас очень богатые: либо на OpenStack с собственной разработкой, либо на OpenStack, но коммерческом.
Просто чтобы вы понимали уровень ситуации:
- Архитектура — заявленная как микросервисная, по факту — распределённый монолит, причём взаимодействие с компонентами вроде файловых хранилищ разного типа не вынесено в отдельные модули, а затянуто в ядро.
- 49 команд разработки, которые делят сервисы по зоне ответственности, а не архитектурной задаче. Десятки комитетов, которые добавляют бюрократии.
- Документация не соответствует реальности.
- Иногда баг в одном модуле исправляется специальной утилитой, убирающей его последствия от другой команды разработки, а не апдейтом исходного модуля.
- Код неоптимальный, сервисы работают медленно, есть бутылочные горлышки.
- Обновляться очень тяжело.
- ИБ часто делается по остаточному принципу.
В общем, в 2025 году я никак не могу советовать идти в OpenStack, но особого выбора-то и нет.
Чтобы не быть голословным, ниже будет полный каталог проблем, с которыми мы столкнулись на практике.
Выбор стека
2023 год, Россия. Проприетарные компании уходят, с VMware люди мигрируют куда угодно, и остаётся только собственная разработка или опенсорс. Яндекс — единственный, кто делал что-то своё, но так и не показал, что собственная разработка — не такой уж и геморрой в сравнении с допиливанием напильником опенсорса.
В альтернативах в опенсорсе есть проекты CloudStack и OpenNebula. Они несколько проще, чем OpenStack, и функционал у них поменьше. Нам для решения задач коммерческого облака они не подходят.
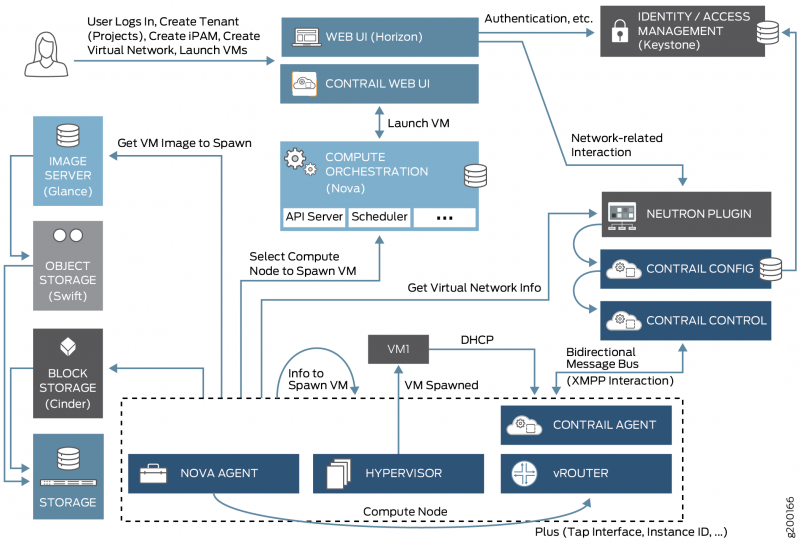
Остаётся, собственно, сам OpenStack. Он отвечает за инфраструктуру: выделяет физические ресурсы, разбивает их на виртуальные машины, управляет образами, подтягивает хранилища, делает идентификацию и так далее. Можно сказать, что это бэкенд облака, а большая часть современной разработки сосредоточивается в middleware и фронтах.
У него есть открытая эталонная реализация и несколько коммерческих. Забегая вперёд, каждая коммерческая реализация — это фактически набор патчей и утилит для того, чтобы это можно было хоть как-то поддерживать. Они несильно отличаются по функциональности от эталона, но зато каждая отдельная команда научилась их готовить и способна продавать поддержку.
В опенсорсе коммитят коммерческие компании, которые так делают, плюс есть пожертвования от крупных игроков рынка для развития проекта, на которые нанимаются команды разработки. Это, наверное, одна из самых страшных вещей, потому что эти команды разработки не особо-то и слушают конечных пользователей, а пилят то, что им нравится. Ну или у меня сложилось такое впечатление. Про результаты такого развития есть
пост 2017 года, когда всё уже было монструозным, запутанным и на краю пропасти. За восемь лет эта экосистема шагнула далеко вперёд.
Мы остановились тогда на версии 23.1.
Дальше нужен виртуализатор. У нас это KVM. Слышали про опыт Xen, но тот же Рег.ру ушёл с Xen не просто так. Собрали отзывы и решили, что всё же KVM. Плюс сверху — собственная контрольная панель: это уже наша разработка.
Ад подкрадывается незаметно
Начали строить. Накатили OpenStack в тестовом формате: сначала — ручками на несколько машин. Всё шло хорошо. Начали делать свой интерфейс, углублять техническую часть. Параллельно стали получать все атрибуты провайдера, необходимые на сегодняшний день, чтобы легально работать. Дальше начали углубляться в использование сервисов.
Первое, с чем мы столкнулись, — это проблема с инсталляцией. То есть, когда ставишь это не ручками, а автоматизированно на N хостов (у нас на старте было около сотни), начинаются танцы с бубном. Базовый набор таков: есть Ansible Playbooks. Это единственный официальный вариант, как развернуть OpenStack. Все системы — в докер-контейнерах, и, чтобы их развернуть, надо запустить плейбуки. Они поставят контейнеры, а дальше начнут конфигурировать сервисы, чтобы они были связаны друг с другом. То есть это не просто накатывание 100 образов, а 100 полноценных инсталляций со сложными взаимосвязями. Сервис состоит из множества компонентов, и их нужно подружить друг с другом. Подружить один раз и скопировать результат дружбы как образ, повторюсь, не выйдет. Нужно сделать 100 одинаково подготовленных хостов. Нужно с какой-то машины иметь к ним SSH-доступ. Дальше тысячи строчек конфига нужно подстроить под себя. И нельзя сказать, что все параметры там нормально документированы: некоторые не документированы совсем или документация не обновлялась очень давно.
Если вы неправильно развернули, то можно просто переустанавливать все 100 хостов и заново их разворачивать. Какой-то один неправильно настроенный параметр может положить всю инсталляцию.
Но! Даже если вы прошли этот квест, то знайте, что не все сервисы ставятся через этот инсталлятор. Мы хотели использовать контейнерный оркестратор Zun. Там классная задумка, что контейнер является First-Class Citizen, как и ВМ. Проблема заключается в том, что он не ставится. Даже в чистовой инсталляции вместо того, чтобы развернуть нужную схему в БД, он зачем-то идёт через миграции. В какой-то момент эти миграции ломаются, потому что поменялась версия внутреннего компонента, и некоторые типы полей больше не поддерживаются. Приходится вручную лезть в код и разбираться, что же там такое. И все, кто проходил этот путь, делают именно так. Знает ли об этом сообщество? Знает. Что-то поменялось? Да. Они положили это в беклог.
Дальше такие сюрпризы были примерно каждый день.
Вот наше короткое практическое резюме.
Он ОЧЕНЬ запутанный
На это жалуются как пользователи, так и само сообщество вокруг продукта.
Каждая служба (Nova, Neutron, Cinder, Keystone и т. д.) имеет множество зависимостей и конфигурационных опций. Любая ошибка в настройке или конфигурации сразу может привести к общесистемным проблемам.
Пример: Chris Dent, один из активных участников Технического комитета OpenStack, в 2021 году отметил, что «обилие сервисов и интеграционных компонентов приводит к усложнённому процессу сопровождения, особенно — в крупных развёртываниях». И дальше запустил опрос, который
показал, что разработчики не хотят участвовать в некоторых ветках из-за качества кода, скорость развития проекта пугающе медленная, в целом очень много работы, очень странная унаследованная архитектура и много легаси-кода.
Из-за этой невероятной запутанности просто развёртывание прод-системы без дополнительных модулей займёт у вас несколько недель для команды. После этого те же люди, вероятно, станут незаменимой поддержкой, потому что им придётся вбить некоторое количество костылей, чтобы всё развернуть.
Само по себе развёртывание OpenStack требует глубоких знаний Linux, виртуализации, сетевых технологий, а также специфики каждого из сервисов. Когда дойдёте до сетевых драйверов, вы, вероятно, поседеете.
Его почти невозможно обновить
Процесс обновления сопоставим с тем, как вы мигрировали бы с 1С, скажем, 7 на современную версию. А это, знаете ли, некий показатель.
Релизы выходят раз в полгода. Если у вас есть хоть один кастомный модуль — готовьтесь ковыряться в коде гораздо больше обычного, потому что это не «поправить конфиг», а, вероятно, «залезть в ядро и разобраться».
Примеры проблем при миграциях —
тут,
тут,
тут, и ещё вот
тут и
тут. Достаточно загуглить «Upgrade issues from Antelope to Bobcat» or «Openstack Problems after Caracal upgrade».
На практике очень болезненны бывают патчи по 0-day ИБ-проблемам. Часто компании вынуждены на долгое время «застревать» на более старых релизах, чтобы не рисковать стабильностью.
Он медленный. Нет, МЕДЛЕННЫЙ
После 100 хостов начинают возникать узкие места, которые не масштабируются. В частности, это основные компоненты Nova-scheduler, Neutron и Placement.
Наш пример: в Placement они даже не могут сделать нормальный веб-сервис, который будет отвечать на запросы быстрее чем за три секунды. Три секунды, Карл! Да, теперь они вытащили микросервис наружу из монолита, и он отвечает за полторы секунды. Но под нагрузкой он снова отвечает за три, а то и за пять секунд. Забиваем это всего лишь десятью тысячами записей — пять секунд!
Мы тут тестировали нагрузку созданных Scala-сервисов, которые сами пишем. У них ходит 200 миллионов сообщений в секунду, API отвечает на миллион запросов с одной машинки, с ноута безо всяких задержек без увеличения времени ответа. Под капотом у неё — база данных Кассандра, и 100 миллионов записей для неё — это какая-то мелочь.
Но вернёмся к Опенстеку. Вот статья
Fix Your Debt: Placement Performance Summary с тестами производительности Placement (зависимости Nova) после переноса в отдельный сервис. Ещё стоит погуглить Nova-scheduler meltdown bug и баги Neutron при создании большого числа сетей или портов.
На практике многие вынуждены применять нетривиальные хаки (например, использовать внешнюю маршрутизацию или кастомные плагины для Neutron) и постоянно тюнить базу данных (RabbitMQ, Galera Cluster и т. д.), что сильно усложняет поддержку.
Некоторые пользователи отмечают дополнительную прослойку абстракции, из-за чего теряется производительность по сравнению с «голой» виртуализацией (KVM, VMware). При большом количестве сервисов зачастую растут задержки при создании/удалении ресурсов и ведении баланса нагрузки.
Крупные инсталляции (100+ физических узлов) требуют выделенных команд администраторов, девопсов и очень хороших внешних мониторингов типа Prometheus, Nagios, Zabbix.
Документация даже просто одного сервиса Nova (нова) — это тысяча+ страниц А4. Инструкция для оператора — ещё тысяча. Если взять материалы по автоматизированной установке, то ещё тысяча. Это только один сервис из семи корневых или десятка потенциально необходимых облачному провайдеру.
Наш пример: Ceph не подключился. Просто последняя версия у нас разворачивается, но не функционирует от слова «совсем» даже при абсолютно чёткой правильной инсталляции. Просто не работают тома. Синдер рубит создание виртуалок. Это проблема исключительно с багами последней версии. Надо лезть ручками и смотреть, что не так с настройками именно вот этой автоматической инсталляции. Ручная инсталляция работает, автоматическая — нет.
Ваш баг очень важен для нас
Нет единого системного подхода к логированию и централизованной диагностике. Разные сервисы генерируют логи в разных форматах, а документация не всегда актуальна.
На OpenStack Forum 2021 в ходе «круглого стола» о болевых точках (сессия «Troubleshooting the Hard Way») многие операторы жаловались на сложность анализа инцидентов из-за нестыковок логов разных сервисов. Видео доклада на YouTube OpenInfra Summit 2021 — «Troubleshooting in OpenStack» больше недоступно, но поиск выдаёт доклады с не менее обнадёживающими названиями:

На практике при проблемах, связанных одновременно с Nova, Neutron и Cinder, часто приходится манипулировать несколькими логами, отдельно просматривать состояние очередей в RabbitMQ, мониторить состояние баз данных и сервисов. Это точно к длительной отладке.
Что гораздо хуже — внутри есть известные баги, которые не правятся буквально годами. Например, Neutron — один из самых критикуемых компонентов из-за многослойной конфигурации сетей (L2-, L3-агенты, SDN, различные плагины). Это часто вызывает проблемы при отладке и обновлении. Известный баг, который ссылается на другой известный баг, —
Launchpad #1961740 (известен аж с 22.02.2022).
Интеграция с Kubernetes и контейнерами: конфликт интересов
С ростом популярности Kubernetes некоторые компании начинают сомневаться в необходимости OpenStack или пытаются интегрировать OpenStack и Kubernetes. В результате возникает ещё более сложная многоуровневая инфраструктура.
В некоторых компаниях при добавлении Kubernetes к уже существующему OpenStack пришли к выводу, что поддерживать две большие экосистемы становится слишком дорого с точки зрения DevOps-команд и вычислительных ресурсов.
Несмотря на большую активность в прошлом, часть разработчиков уходит в другие проекты (Kubernetes, Docker, Public Cloud Solutions). Это ведёт к тому, что некоторые модули OpenStack остаются без должного внимания.
Бюрократия
Внутри проекта OpenStack много подкомитетов (Technical Committee, Board of Directors), а также большое количество разных Special Interest Groups. Бюрократию это создаёт неиллюзорную.
Некоторые разработчики жаловались, что из-за бюрократии и постоянной смены приоритетов невозможно полноценно сфокусироваться на критических задачах. Упомянутый ранее отчёт указывает на нежелание разработчиков участвовать в некоторых проектах из-за их «клубности».
Планировать сроки выхода фичи никто не берётся, что местами останавливает конечных пользователей от того, чтобы планировать что-то на Опенстеке.
Нестабильность отдельных проектов и «призрачные» сервисы
В OpenStack исторически появлялось очень много новых проектов (Manila, Mistral, Barbican и др.). Некоторые из них теряли поддержку или переходили на «режим малой активности». Например, Mistral (Workflow as a Service) неоднократно признавался «низкоприоритетным» из-за отсутствия достаточного количества мейнтейнеров. Вот его
репозиторий с невысокой активностью коммитов. Вот аналогичный
Zaqar (Messaging Service).
Компании, которые такое поставили, часто были вынуждены уходить на сторонние внешние решения.
Некоторые сервисы просто нестабильны. В сообществе встречаются частые жалобы на нестабильную работу Manila (файловые шары), затягивание решения багов в Ironic (bare metal provisioning).
Также умерли:
- Trove (Database as a Service). Trove создавался для управления СУБД (MySQL, PostgreSQL и др.) в стиле «DBaaS» в рамках OpenStack. Многие операторы вообще не используют Trove, предпочитая управлять базами отдельно (через Kubernetes Operators или внешние PaaS-платформы).
- Sahara (Big Data as a Service). Sahara предназначен для разворачивания кластеров Hadoop/Spark через OpenStack. С развитием Kubernetes и появлением разнообразных операторов для Big Data-решений (Spark Operator, Airflow и т. п.) популярность Sahara упала.
- Karbor (Application Data Protection). Он создавался как сервис для бэкапов и восстановления приложений в OpenStack, но полноценной популярности не снискал. Несколько лет назад проект был малоактивным, и на данный момент упоминания о Karbor в комьюнити редки.
- Rally (Benchmark & Testing). Rally задумывался для нагрузочного тестирования и оценки производительности сервисов OpenStack. Хотя он всё ещё используется некоторыми командами CI/CD, его активное развитие снизилось: многие операторы переключились на собственные фреймворки тестирования или используют Performance-тесты в других инструментах.
Костыли
Orphaned Resource Allocation (Nova)
- При неполном или ошибочном удалении виртуальных машин (например, сбой в момент удаления, прерванная операция миграции) в базе данных Nova могут оставаться «осиротевшие» записи о зарезервированных ресурсах (CPU, RAM, диски).
- Следствие: гипервизор якобы «загружен» и отказывается принимать новые инстансы, хотя фактически ни одной рабочей ВМ не запущено.
- Рабочий костыль (workaround): использовать процедуру очистки «orphaned allocations» вручную или скриптами nova-manage placement heal_allocations, а также проверять состояние ВМ (stopped, error и т. д.), чтобы корректно завершать.
- При серьёзных сбоях — удалять «зависшие» записи напрямую из базы данных (что нежелательно в промышленной среде, но иногда это единственный выход).
- Официальная документация Nova Troubleshooting — Orphaned Allocations.
То есть они допустили баг в основном сервисе и выпустили утилиту для сборки «осиротевших» ресурсов, а не исправили баг.
«Зависшие» тома (Stuck Volumes) в Cinder
- Сценарий: том был выделен, но виртуальная машина, которая к нему подключалась, удалена с ошибкой. В результате в Cinder остаются «призрачные» тома в статусах deleting, error_deleting или даже «внешне доступные», но фактически они не прикреплены ни к одной ВМ.
- При повторных запросах на создание/удаление Cinder может сообщать «Не хватает места», «Ресурсы недоступны» и т. д., хотя физически дисковое пространство есть.
- Рабочий костыль: использовать команды cinder reset-state и cinder force-delete, вручную приводя томы в согласованное состояние. В некоторых случаях — чистить записи в базе данных Cinder или на уровне бэкенда (Ceph, LVM и т. п.), если стандартные инструменты не помогают.
«Забытые» порты и сети (Neutron Leftover Ports/Networks)
- При сбоях в процессе удаления инстансов или сетевых ресурсов могут оставаться порты, не привязанные к активным VM. Аналогично могут «зависать» сами сети, если они не были корректно отвязаны.
- Это мешает созданию новых сетевых ресурсов и приводит к путанице в конфигурации (особенно если используется DVR, L3-HA или VLAN trunking).
- Рабочий костыль: проверять через openstack port list (или neutron port-list) все «зависшие» порты, удалять их вручную openstack port delete. Если удаление не срабатывает, то искать в логах ошибки (конфликты с другими службами), а в крайних случаях — править базу данных Neutron или восстанавливать целостность через пересоздание сети.
«Призрачные» образы (Glance Ghost Images)
- Иногда процесс загрузки или удаления образа прерывается ошибкой сети, нехваткой места и т. д. В результате в Glance могут остаться «полусуществующие» записи: метаданные есть, но реального файла нет. Либо наоборот: файл в бэкенде хранится, а метаданные удалены.
- Это приводит к некорректным подсчётам объёма занимаемого места, а при попытке заново загрузить образ с тем же UUID возможно возникновение конфликтов.
- Рабочий костыль: проверка статусов образов (например, deleted, но всё ещё существующий) и при необходимости — ручная очистка метаданных или объектов в бэкенде (Swift, Ceph RBD и т. д.). Регулярное сканирование базы данных Glance и соответствующего хранилища для выявления рассинхронов.
Heat: «зависшие» стеки (Stuck Stacks)
- При сбоях в шаблонах (Templates) или ошибках в ссылках на внешние ресурсы (Nova, Neutron, Cinder) Heat может застревать в состоянии UPDATE_IN_PROGRESS или DELETE_IN_PROGRESS.
- Пользователь не может ни завершить операцию, ни перейти к следующему обновлению: «раскрутить» это бывает нелегко.
- Рабочий костыль: перевод стека в состояние FAILED через специальную команду heat stack update --mark-failed, а затем — повторное удаление. В самых тяжёлых случаях используют скрипты для массовой ручной очистки зависимых ресурсов. Если удаление отдельных ресурсов невозможно, то приходится корректировать записи в базе данных Heat.
Ceilometer/Gnocchi: некорректные метрики (Stale Metrics)
При сбоях в агенте сбора метрик (ceilometer-agent) или при неправильных настройках pipelining возникают «осиротевшие» записи о ресурсах, которые уже не существуют.
Это приводит к некорректным показателям в мониторинге и сбоям при выставлении счетов (биллинг), особенно если реализована auto-scaling через Heat или другой механизм.
Рабочий костыль: чистить «зависшие» записи в базе Gnocchi, скриптово пересоздавать индекс или вручную выгружать «битые» серии метрик. Отслеживать логи и периодически перезагружать сервисы телеметрии, чтобы избежать накопления устаревших данных.
Horizon: «подвисшие» действия в веб-интерфейсе
- В веб-панели иногда случаются ситуации, когда пользователь инициирует операцию (создание VM, присоединение тома), но обновление страницы «застряло», и остаётся неочевидным, сработало действие или нет.
- Повторный клик порождает дублирующиеся запросы, в итоге в бэкенде появляются «лишние» ресурсы, а Horizon может не отобразить их корректно.
- Рабочий костыль: ручной мониторинг через CLI (openstack server list, openstack volume list, openstack network list) в параллель с Horizon, чтобы убедиться в статусе. Если обнаружены дублирующиеся или «зависшие» ресурсы, то удалять их из CLI и/или чистить записи в базах данных.
В целом в экосистеме OpenStack есть существенный ряд тонких мест, где сбои в процессе создания или удаления ресурсов приводят к костыльным решениям и дополнительной ручной работе. Чаще всего это связано с неполными или прерванными операциями типа удаления ВМ, тома или порта, рассинхронизации сервисов, из-за которых ресурс считается занятым или существующим, хотя это уже не так. Есть и ошибки при обновлениях, из-за чего ресурсы «зависают» в промежуточных состояниях. Всё это надо чистить вручную силами команды поддержки.
Итог
В Опенстеке есть всё — от г**на до патрона, но там ничего, кроме базовых сервисов, нормально не работает. Многие из них даже не ставятся. Мы очень удивлялись, почему так. На самом деле все проблемы лежат на поверхности — это архитектура и устройство разработки. Но нам от этого несильно легче.
Это мы ещё не коснулись особенностей безопасности, ведь редкие релизы, нестыковки модулей, потеря мейнтейнеров и обновлений компонентов — это рай для взломов. И они происходят регулярно.
Пока же могу сказать, что, мы развернули Опенстек. Посмотрели в процессе и в тестовой эксплуатации два месяца. Оценили, как с ним жить,
и стали пилить свою платформу.
h3llo.cloud
auth.h3llo.cloud/register