История создания облачного сервиса, приправленная киберпанком

С ростом стажа работы в IT начинаешь замечать, что системы имеют свой характер. Они могут быть покладистыми, молчаливыми, взбалмошными, суровыми. Могут располагать к себе или отталкивать. Так или иначе, приходится «договариваться» с ними, лавировать между «подводными камнями» и выстраивать цепочки их взаимодействия.
Вот и нам выпала честь построить облачную платформу, а для этого потребовалось «уговорить» пару подсистем работать с нами. Благо, у нас есть «язык API», прямые руки и куча энтузиазма.
В этой статье не будет технического хардкора, но будет описание проблем, с которыми мы столкнулись при построении облака. Я решил описать наш путь в виде легкой технической фантазии о том, как мы искали общий язык с системами и что из этого вышло.
Начало пути
Некоторое время назад перед нашей командой была поставлена задача — запустить облачную платформу для наших клиентов. В нашем распоряжении была поддержка руководства, ресурсы, аппаратный стек и свобода в выборе технологий для реализации программной части сервиса.
Был также и ряд требований:
- сервису нужен удобный личный кабинет;
- платформа должна быть интегрирована в существующую систему биллинга;
- программно-аппаратная часть: OpenStack + Tungsten Fabric (Open Contrail), которые наши инженеры научились достаточно хорошо «готовить».
О том, как собиралась команда, разрабатывался интерфейс личного кабинета и принимались дизайнерские решения, расскажем в другой раз, если у хабра-сообщества будет интерес.
Инструменты, которые мы решили использовать:
- Python + Flask + Swagger + SQLAlchemy — вполне стандартный Python набор;
- Vue.js для фронтенда;
- взаимодействие между компонентами и сервисами решили делать с помощью Celery поверх AMQP.
Предвосхищая вопросы о выборе в сторону Python, поясню. Язык занял свою нишу в нашей компании и вокруг него сложилась небольшая, но всё же культура. Поэтому было решено начинать строить сервис именно на нём. Тем более, что скорость разработки в таких задачах зачастую решает.
Итак, начнем наше знакомство.
Молчаливый Билл — биллинг
С этим парнем мы были знакомы давно. Он всегда сидел рядом и что-то молча считал. Иногда переправлял нам запросы пользователей, выставлял клиентские счета, управлял услугами. Обычный работящий парень. Правда, были сложности. Он молчалив, иногда задумчив и часто — себе на уме.

Биллинг — это первая система, с которой мы попытались подружиться. И первая же трудность встретилась нам при обработке услуг.
Например, при создании или удалении, задача попадает во внутреннюю очередь биллинга. Таким образом реализована система асинхронной работы с услугами. Для обработки своих типов услуг нам нужно было «складывать» свои задачи в эту очередь. И здесь мы столкнулись с проблемой: нехватка документации.

Судя по описанию программного API, решить эту задачу все же можно, но времени заниматься реверс-инжинирингом у нас не было, поэтому мы вынесли логику наружу и организовали очередь задач поверх RabbitMQ. Операция над услугой инициируется клиентом из личного кабинета, оборачивается в «задачу» Celery на бэкенде и выполняется на стороне биллинга и OpenStack’a. Celery позволяет достаточно удобно управлять задачами, организовывать повторы и следить за состоянием. Подробнее про «сельдерей» можно почитать, например, здесь.
Также биллинг не останавливал проект, на котором закончились деньги. Общаясь с разработчиками, мы выяснили, что при подсчете по статистике (а нам нужно реализовать именно такую логику) есть сложная взаимосвязь правил остановки. Но эти модели плохо ложатся под наши реалии. Также реализовали через задачи на Celery, забирая на сторону бэкенда логику управления услугами.
Обе вышеуказанные проблемы привели к тому, что код немного раздулся и нам в будущем придется заняться рефакторингом, чтобы вынести в отдельный сервис логику работы с задачами. Нам также нужно хранить часть информации о пользователях и их услугах в своих таблицах, чтобы поддерживать эту логику.
Еще одна проблема — молчаливость.
На часть запросов к API Билли молча отвечает «Ок». Так, например, было, когда мы делали зачисления обещанных платежей на время теста (о нем позже). Запросы корректно выполнялись и мы не видели ошибок.

Пришлось изучать логи, работая с системой через UI. Оказалось, что сам биллинг выполняет подобные запросы, изменяя scope на конкретного пользователя, например, admin, передавая его в параметре su.
В целом, несмотря на пробелы в документации и небольшие огрехи API, все прошло достаточно неплохо. Логи вполне можно читать даже при большой нагрузке, если понимать, как они устроены и что нужно искать. Структура базы данных витиеватая, но вполне логичная и в чем-то даже привлекательная.
Итак, подводя итоги, основные проблемы, которые у нас возникли на этапе взаимодействия, связаны с особенностями реализации конкретной системы:
- недокументированные «фичи», которые так или иначе нас затрагивали;
- закрытые исходники (биллинг написан на C++), как следствие — невозможность решить проблему 1 никак, кроме «метода проб и ошибок».
К счастью, у продукта есть достаточно развесистый API и мы интегрировали в свой личный кабинет следующие подсистемы:
- модуль технической поддержки — запросы из личного кабинета «проксируются» в биллинг прозрачно для клиентов сервиса;
- финансовый модуль — позволяет выставлять счета текущим клиентам, производить списания и формировать платежные документы;
- модуль управления услугами — для него нам пришлось реализовать свой обработчик. Расширяемость системы сыграла нам на руку и мы «обучили» Билли новому типу услуг.
Прогулки по вольфрамовым полям — Tungsten Fabric
Вольфрамовые поля, усеянные сотней проводов, прогоняющих через себя тысячи бит информации. Информация собирается в «пакеты», разбирается, выстраивая сложные маршруты, как по волшебству.

Это вотчина второй системы, с которой нам пришлось подружиться — Tungsten Fabric (TF), бывший OpenContrail. Ее задача — управлять сетевым оборудованием, предоставляя программную абстракцию нам, как пользователям. TF — SDN, инкапсулирует в себе сложную логику работы с сетевым оборудованием. Про саму технологию есть неплохая статья, например, тут.
Система интегрирована с OpenStack (о нём речь пойдет ниже) через плагин Neutron’a.
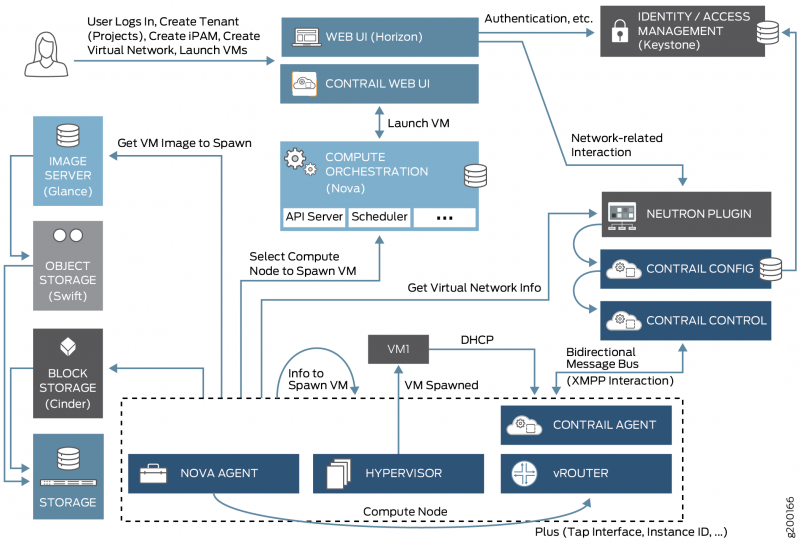
Взаимодействие сервисов OpenStack.
С этой системой нас познакомили ребята из отдела эксплуатации. Мы используем API системы для управления сетевым стеком наших услуг. Серьезных проблем или неудобств она нам пока не доставляет (за ребят из ОЭ говорить не возьмусь), однако были и некоторые курьезы взаимодействия.
Первый выглядел так: команды, требующие вывода большого количества данных на консоль инстанса при подключении по SSH просто «вешали» подключение, при этом по VNC все работало корректно.

Для тех, кто не знаком с проблемой, это выглядит достаточно забавно: ls /root отрабатывает корректно, тогда как, например, top «зависает» наглухо. К счастью, мы уже сталкивались с подобными проблемами. Решилось тюнингом MTU на маршруте от compute-нод до маршрутизаторов. К слову сказать, это и не проблема TF.
Следующая проблема ждала за поворотом. В один «прекрасный» момент магия маршрутизации исчезла, вот так просто. TF перестал управлять маршрутизацией на оборудовании.

Мы работали с Openstack с уровня admin и после этого переходили на уровень нужного пользователя. SDN, похоже, «перехватывает» скоуп пользователя, которым выполняются действия. Дело в том, что этот же админский аккаунт используется для связи TF и OpenStack. На шаге переключения под пользователя «магия» пропадала. Решено было завести отдельный аккаунт для работы с системой. Это позволило работать, не ломая функционал интеграции.
Силиконовые формы жизни — OpenStack
Силиконовое существо причудливой формы обитает недалеко от вольфрамовых полей. Больше всего оно похоже на ребенка переростка, который одним взмахом может раздавить нас, но явной агрессии от него не исходит. Оно не вызывает страха, но его размеры внушают опасение. Как и сложность того, что происходит вокруг.

OpenStack — ядро нашей платформы.
OpenStack имеет несколько подсистем, из которых активнее всего мы пока используем Nova, Glance и Cinder. Каждая из них имеет свой API. Nova отвечает за compute-ресурсы и создание instance’ов, Cinder — управление volume’ами и их снимками, Glance — image service, который управляет шаблонами ОС и метаинформацией по ним.
Каждый сервис запускается в контейнере, а брокером сообщений выступает «белый кролик» — RabbitMQ.
Эта система доставила нам больше всего неожиданных хлопот.
И первая проблема не заставила себя ждать, когда мы пытались подключить дополнительный volume к серверу. Cinder API наотрез отказывался выполнять эту задачу. Точнее, если верить самому OpenStack’у связь устанавливается, однако внутри виртуального сервера устройство диска отсутствует

Мы решили «пойти в обход» и запросили то же действие у Nova API. Результат — устройство корректно подключается и доступно внутри сервера. Похоже, что проблема возникает, когда block-storage не отвечает Cinder’у.
Очередная сложность ждала нас при работе с дисками. Системный volume не удавалось отсоединить от сервера.
Опять же, сам OpenStack «божится», что связь он уничтожил и теперь можно корректно работать с volume’ом отдельно. Но API категорически не желал производить операции над диском.

Здесь мы решили особенно не воевать, а изменить взгляд на логику работы сервиса. Уж коли есть instance, должен быть и системный volume. Поэтому пользователь пока не может удалить или отключить системный «диск», не удалив «сервер».
OpenStack — достаточно сложный комплекс систем со своей логикой взаимодействия и витиеватым API. Нас выручает достаточно подробная документация и, конечно, метод проб и ошибок (куда же без него).
Тестовый запуск
Тестовый запуск мы проводили в декабре прошлого года. Основной задачей ставили проверку в боевом режиме нашего проекта с технической стороны и со стороны UX. Аудиторию приглашали выборочно и тестирование было закрытым. Однако мы также оставили возможность запросить доступ к тестированию на нашем сайте.
Сам тест, разумеется, не обошелся без курьезных моментов, ведь на этом наши приключения только начинаются.
Во-первых, мы несколько некорректно оценили интерес к проекту и пришлось оперативно добавлять compute-ноды прямо во время теста. Обычный кейс для кластера, однако и тут были нюансы. В документации для конкретной версии TF указана конкретная версия ядра, на котором тестировалась работа с vRouter. Мы решили запускать ноды с более свежими ядрами. Как итог — TF не получил маршруты с нод. Пришлось экстренно откатывать ядра.

Другой курьез связан с функционалом кнопки «изменить пароль» в личном кабинете.
Мы решили использовать JWT для организации доступа в личный кабинет, чтобы не работать с сессиями. Так как системы разноплановые и широко разбросаны, мы управляем своим токеном, в который «заворачиваем» сессии от биллинга и токен от OpenStack’a. При изменении пароля токен, разумеется, «протухает», поскольку данные пользователя уже невалидны и его нужно перевыпускать.

Мы упустили этот момент из виду, а ресурсов, чтобы быстро дописать этот кусок, банально не хватило. Нам пришлось вырезать функционал перед самым запуском в тест.
На текущий момент мы выполняем logout пользователя, если пароль был изменен.
Несмотря на эти нюансы, тестирование прошло хорошо. За пару недель к нам заглянуло порядка 300 человек. Нам удалось посмотреть на продукт глазами пользователей, протестировать его в бою и собрать качественный фидбек.
Продолжение следует
Для многих из нас это первый проект подобного масштаба. Мы вынесли ряд ценных уроков о том, как работать в команде, принимать архитектурные и дизайнерские решения. Как с небольшими ресурсами интегрировать сложные системы и выкатывать их в продакшн.
Разумеется, есть над чем поработать и в плане кода, и на стыках интеграции систем. Проект достаточно молод, но мы полны амбиций вырастить из него надежный и удобный сервис.
Системы мы уже смогли уговорить. Билл послушно занимается подсчетом, выставлением счетов и запросами пользователей у себя в каморке. «Волшебство» вольфрамовых полей обеспечивает нас стабильной связью. И лишь OpenStack иногда капризничает, выкрикивая что-то вроде «'WSREP has not yet prepared node for application use». Но это совсем другая история…
Совсем недавно мы запустили сервис.
Все подробности вы можете узнать на нашем сайте.
clo.ru

OpenStack
docs.openstack.org/nova/latest/
docs.openstack.org/keystone/latest/
docs.openstack.org/cinder/latest/
docs.openstack.org/glance/latest/
Tungsten Fabric
docs.tungsten.io/en/latest/user/getting-started/index.html
www.juniper.net/documentation/en_US/contrail-cloud10.0/topics/concept/contrail-cloud-openstack-integration-overview.html
0 комментариев
Вставка изображения
Оставить комментарий