Работа с небольшими файлами с помощью OpenStack Swift (часть 2)
В первой части этих статей мы продемонстрировали, как хранение небольших файлов в Swift может вызвать проблемы с производительностью. Во второй части мы представим решение. Имея это в виду, я предполагаю, что вы прочитали первую часть или что вы знакомы со Swift.

Файлы внутри файлов
Мы остановились на простом подходе: мы будем хранить все эти небольшие фрагменты в больших файлах. Это означает, что использование inode в файловой системе намного ниже.
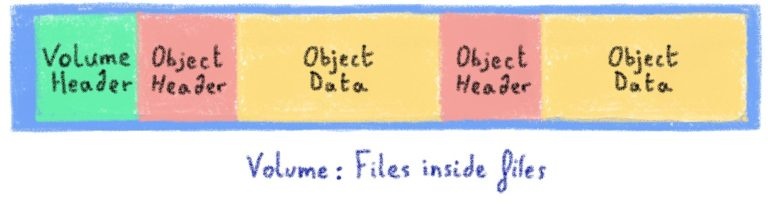
Эти большие файлы, которые мы называем «томами», имеют три важных характеристики:
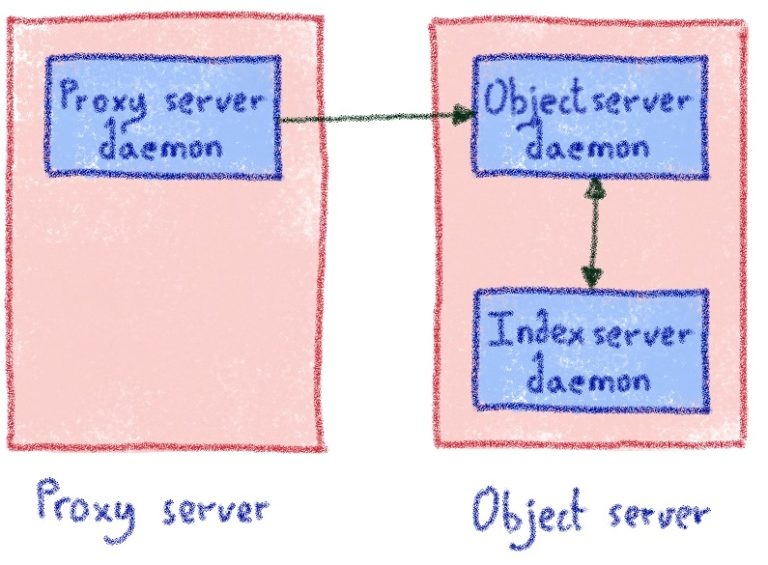
Для каждого диска существует один индекс-сервер. Это означает, что его домен сбоя совпадает с данными, которые он индексирует. Он связывается с существующим процессом объект-сервер через локальный сокет UNIX.
Использование на LevelDB
Мы выбрали LevelDB для хранения местоположения фрагмента на индексном сервере:
Наши первоначальные тесты были многообещающими: они показали, что нам нужно около 40 байтов для отслеживания фрагмента, по сравнению с 300 байтами, если мы использовали обычную файловую систему хранения. Мы только отслеживаем местоположение фрагмента, в то время как файловая система хранит много информации, которая нам не нужна (пользователь, группа, разрешения ..). Это означает, что значение ключа будет достаточно маленьким для кэширования в памяти, и список файлов будет не требует чтения с физического диска.
При записи объекта обычная быстрая серверная часть создаст файл для хранения данных. С LOSF вместо этого:
Удаление объектов
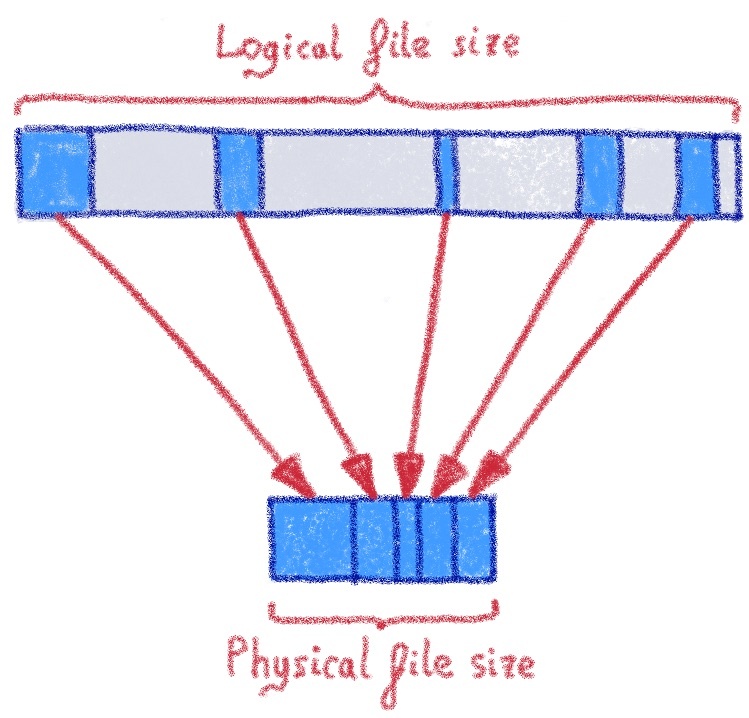
Когда клиент удаляет объект, как мы можем на самом деле удалить данные из томов? Помните, что мы добавляем данные только в том, поэтому мы не можем просто пометить пространство как неиспользуемое в томе и попытаться использовать его позже. Мы используем XFS, и она предлагает интересное решение: возможность «пробить дыру» в файле.
Логический размер не изменяется, что означает, что фрагменты, расположенные после отверстия, не меняют смещение. Однако физическое пространство освобождается для файловой системы. Это отличное решение, так как оно означает, что мы можем продолжать добавлять тома, освобождать пространство внутри тома и разрешать файловой системе распределять пространство.
Структура каталогов
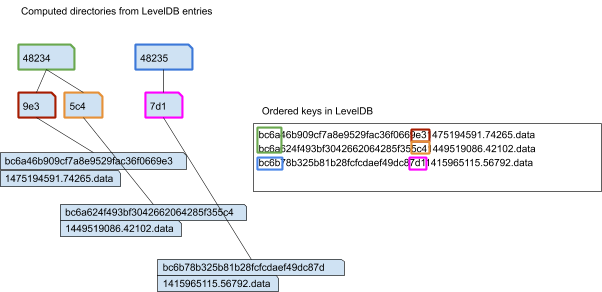
Индекс-сервер будет хранить имена объектов в плоском пространстве имен, но Swift использует иерархию каталогов.
Каталог разделов — это раздел, к которому принадлежит объект, а каталог суффиксов — это только три последние буквы контрольной суммы md5. (Это было сделано, чтобы избежать слишком большого количества записей в одном каталоге)
Если вы ранее не использовали Swift, «индекс раздела» объекта указывает, какое устройство в кластере должно хранить объект. Индекс раздела вычисляется путем взятия нескольких битов из пути объекта MD5. Вы можете узнать больше здесь.
Мы не храним эти каталоги явно на сервере индексов, так как они могут быть вычислены из хэша объекта. Помните, что имена объектов хранятся в порядке LevelDB.
Перенос данных
Этот новый подход меняет формат на диске. Однако у нас уже было более 50 ПБ данных. Миграция в автономном режиме была невозможна. Мы написали промежуточную, гибридную версию системы. Он всегда будет записывать новые данные, используя новую разметку диска, но для чтения он сначала будет искать на индексном сервере, а если фрагмент не найден, он будет искать этот фрагмент в обычном внутреннем каталоге.
Между тем, фоновый инструмент будет медленно преобразовывать данные из старой системы в новую. Это заняло несколько месяцев, чтобы обойти все машины.
Результаты
После завершения миграции активность диска в кластере была намного ниже: мы заметили, что данные сервера индексирования будут помещаться в память, поэтому перечисление объектов в кластере или получение местоположения объекта не потребует ввода-вывода физического диска. Задержка улучшилась как для операций PUT, так и для операций GET, и задачи «реконструкции» кластера могли выполняться намного быстрее. (Реконструктор — это процесс, который восстанавливает данные после сбоя диска в кластере)
Будущая работа
В контексте хранения объектов жесткие диски по-прежнему имеют ценовое преимущество перед твердотельными накопителями. Их емкость продолжает расти, однако производительность на диск не улучшилась. При том же объеме используемого пространства, если вы переключаетесь с дисков объемом 6 ТБ на 12 ТБ, вы фактически вдвое снизили производительность.
Планируя следующее поколение кластеров Swift, мы должны найти новые способы использования этих более крупных дисков, сохраняя при этом высокую производительность. Это, вероятно, будет означать использование сочетания SSD и вращающихся дисков. В этой области происходит интересная работа, поскольку мы будем хранить больше данных на выделенных быстрых устройствах для дальнейшей оптимизации времени отклика кластера Swift.
Файлы внутри файлов
Мы остановились на простом подходе: мы будем хранить все эти небольшие фрагменты в больших файлах. Это означает, что использование inode в файловой системе намного ниже.
Эти большие файлы, которые мы называем «томами», имеют три важных характеристики:
- Они посвящены разделу Swift
- Они только добавляются: никогда не перезаписывают данные
- Нет одновременных записей: у нас может быть несколько томов на раздел
Для каждого диска существует один индекс-сервер. Это означает, что его домен сбоя совпадает с данными, которые он индексирует. Он связывается с существующим процессом объект-сервер через локальный сокет UNIX.
Использование на LevelDB
Мы выбрали LevelDB для хранения местоположения фрагмента на индексном сервере:
- Он сортирует данные на диске, что означает, что он эффективен на обычных вращающихся дисках
- Это экономит место благодаря библиотеке сжатия Snappy
Наши первоначальные тесты были многообещающими: они показали, что нам нужно около 40 байтов для отслеживания фрагмента, по сравнению с 300 байтами, если мы использовали обычную файловую систему хранения. Мы только отслеживаем местоположение фрагмента, в то время как файловая система хранит много информации, которая нам не нужна (пользователь, группа, разрешения ..). Это означает, что значение ключа будет достаточно маленьким для кэширования в памяти, и список файлов будет не требует чтения с физического диска.
При записи объекта обычная быстрая серверная часть создаст файл для хранения данных. С LOSF вместо этого:
- Получить блокировку файловой системы на томе
- Добавьте данные объекта в конец тома и вызовите fdatasync ()
- Зарегистрировать местоположение объекта на индексном сервере (номер тома и смещение внутри тома)
- Запросите индекс-сервер, чтобы узнать его местоположение: номер тома и смещение
- Откройте том и найдите смещение для обработки данных.
Удаление объектов
Когда клиент удаляет объект, как мы можем на самом деле удалить данные из томов? Помните, что мы добавляем данные только в том, поэтому мы не можем просто пометить пространство как неиспользуемое в томе и попытаться использовать его позже. Мы используем XFS, и она предлагает интересное решение: возможность «пробить дыру» в файле.
Логический размер не изменяется, что означает, что фрагменты, расположенные после отверстия, не меняют смещение. Однако физическое пространство освобождается для файловой системы. Это отличное решение, так как оно означает, что мы можем продолжать добавлять тома, освобождать пространство внутри тома и разрешать файловой системе распределять пространство.
Структура каталогов
Индекс-сервер будет хранить имена объектов в плоском пространстве имен, но Swift использует иерархию каталогов.
/mnt/objects/<partition>/<suffix>/<checksum>/<timestamp>.data
Каталог разделов — это раздел, к которому принадлежит объект, а каталог суффиксов — это только три последние буквы контрольной суммы md5. (Это было сделано, чтобы избежать слишком большого количества записей в одном каталоге)
Если вы ранее не использовали Swift, «индекс раздела» объекта указывает, какое устройство в кластере должно хранить объект. Индекс раздела вычисляется путем взятия нескольких битов из пути объекта MD5. Вы можете узнать больше здесь.
Мы не храним эти каталоги явно на сервере индексов, так как они могут быть вычислены из хэша объекта. Помните, что имена объектов хранятся в порядке LevelDB.
Перенос данных
Этот новый подход меняет формат на диске. Однако у нас уже было более 50 ПБ данных. Миграция в автономном режиме была невозможна. Мы написали промежуточную, гибридную версию системы. Он всегда будет записывать новые данные, используя новую разметку диска, но для чтения он сначала будет искать на индексном сервере, а если фрагмент не найден, он будет искать этот фрагмент в обычном внутреннем каталоге.
Между тем, фоновый инструмент будет медленно преобразовывать данные из старой системы в новую. Это заняло несколько месяцев, чтобы обойти все машины.
Результаты
После завершения миграции активность диска в кластере была намного ниже: мы заметили, что данные сервера индексирования будут помещаться в память, поэтому перечисление объектов в кластере или получение местоположения объекта не потребует ввода-вывода физического диска. Задержка улучшилась как для операций PUT, так и для операций GET, и задачи «реконструкции» кластера могли выполняться намного быстрее. (Реконструктор — это процесс, который восстанавливает данные после сбоя диска в кластере)
Будущая работа
В контексте хранения объектов жесткие диски по-прежнему имеют ценовое преимущество перед твердотельными накопителями. Их емкость продолжает расти, однако производительность на диск не улучшилась. При том же объеме используемого пространства, если вы переключаетесь с дисков объемом 6 ТБ на 12 ТБ, вы фактически вдвое снизили производительность.
Планируя следующее поколение кластеров Swift, мы должны найти новые способы использования этих более крупных дисков, сохраняя при этом высокую производительность. Это, вероятно, будет означать использование сочетания SSD и вращающихся дисков. В этой области происходит интересная работа, поскольку мы будем хранить больше данных на выделенных быстрых устройствах для дальнейшей оптимизации времени отклика кластера Swift.
0 комментариев
Вставка изображения
Оставить комментарий