Мы в Vultr гордимся тем, что делаем облачную инфраструктуру доступной для всех — разработчиков, малых и средних предприятий и крупных предприятий. Это желание снизить цены привело нас к созданию Vultr Talon, революционной платформы, которую мы представляем сегодня в бета-версии. С Vultr Talon мы теперь предлагаем лучшие в своем классе виртуализированные графические процессоры, начиная с графического процессора с тензорными ядрами NVIDIA A100, по цене в несколько раз дешевле полноценного графического процессора. Vultr — первый поставщик облачных услуг, предлагающий виртуализацию графических процессоров NVIDIA A100 для обеспечения совместного использования графических процессоров и обеспечения оптимального использования ресурсов.
Сегодняшний запуск представляет собой инновацию, создающую категорию, предоставляющую совершенно новый тип облачных виртуальных машин, который устраняет некоторые из самых больших препятствий на пути создания и развертывания производственных приложений с поддержкой ИИ с использованием графических процессоров.
Повышение рентабельности и использования экземпляров GPU
За последние несколько лет популярность графических процессоров NVIDIA резко возросла, и на то есть веские причины. Один графический процессор содержит тысячи специализированных ядер, идеально подходящих для параллельных вычислений. В дополнение к огромной вычислительной мощности графические процессоры NVIDIA — невероятно универсальные ускорители, которые можно использовать для искусственного интеллекта, машинного обучения, анализа данных, научных вычислений и многого другого.
Тем не менее, когда речь идет о рабочих нагрузках клиентов, не существует универсального решения. Разнообразные рабочие нагрузки имеют различные требования к вычислительным ресурсам, начиная от доли графического процессора и заканчивая несколькими графическими процессорами на одном узле или на нескольких узлах.
Предоставление нужного размера ускорения для вашей рабочей нагрузки и максимальное использование имеют решающее значение для оптимизации затрат на облако.
Исторически сложилось так, что пользователи облачных вычислений могли приобретать только целые физические графические процессоры, работающие в транзитном режиме и подключенные к экземплярам облачных вычислений. Высококачественные графические процессоры, поставляемые таким образом, обычно стоят тысячи долларов в месяц.
Эта стоимость часто оправдана для самых больших корпоративных рабочих нагрузок, некоторые из которых настолько ресурсоемки, что требуют параллельной работы нескольких графических процессоров. Но для многих предприятий и разработчиков стоимость даже одного графического процессора может быть непомерно высокой для начала работы, экспериментов или запуска приложений в средах разработки и тестирования. Даже предприятия со значительными ИТ-бюджетами могут в конечном итоге растратить значительные суммы денег, предоставив больше ресурсов графических процессоров, чем им действительно нужно, или просто решив вообще не использовать графические процессоры.
Виртуализация графического процессора NVIDIA A100 в облаке, обеспечивающая эффективные вычисления и снижающая затраты на ИИ
Графические процессоры имеют огромное потенциальное влияние, но многие клиенты, которые могли бы извлечь выгоду из этих возможностей, не могут ими воспользоваться. Дело в том, что удовлетворение потребности в вычислительных ресурсах для поддержки различных рабочих нагрузок ИИ не может быть универсальным подходом.
Используя наш опыт в области виртуализации и облачной инфраструктуры, мы стремились перевернуть модель предоставления GPU с ног на голову. Вместо того, чтобы предлагать целые физические графические процессоры по менее доступным ценам, мы стремились обеспечить совместное использование графических процессоров с помощью виртуализации всего за небольшую часть стоимости. Работая в тесном сотрудничестве с NVIDIA, мы разработали платформу Vultr Talon на базе графических процессоров NVIDIA и программного обеспечения NVIDIA AI Enterprise, которую мы представляем в сегодняшней бета-версии.
Изменившая мир технология графических процессоров NVIDIA теперь доступна по цене от 90 долларов в месяц или всего 0,13 доллара в час.
В основе Vultr Talon лежит современная платформа виртуализации графических процессоров NVIDIA. Вместо того, чтобы подключать целые физические графические процессоры к виртуальным машинам, мы подключаем только часть в виде виртуального графического процессора (vGPU). Виртуальные графические процессоры работают на базе NVIDIA AI Enterprise, которая включает программное обеспечение NVIDIA vGPU и оптимизирована для удаленного выполнения рабочих нагрузок ИИ и высокопроизводительного анализа данных.
Для вашей машины виртуальный графический процессор выглядит так же, как физический графический процессор. Каждый vGPU имеет собственную выделенную память, которая является частью памяти базовой карты. vGPU имеет доступ к соответствующей части вычислительной мощности физического GPU.
Vultr Talon использует технологию NVIDIA Multi-Instance GPU для виртуальных машин с объемом памяти GPU не менее 10 ГБ, что повышает ценность производительности за счет предоставления арендаторам гарантированного QoS, полностью изолированной памяти GPU с высокой пропускной способностью, кэш-памяти и выделенных вычислительных ядер.
Вы можете использовать виртуальные машины Vultr с виртуальными графическими процессорами для запуска всех тех же платформ, библиотек и операционных систем, которые вы бы запускали на физическом графическом процессоре. Как и во всех продуктах Vultr, вы можете легко увеличивать или уменьшать объемы использования, чтобы точно сопоставить расходы на GPU с вашими реальными потребностями.
 Части NVIDIA A100 всего от 90 долларов в месяц
Части NVIDIA A100 всего от 90 долларов в месяц
Графический процессор NVIDIA A100 с тензорными ядрами обеспечивает невероятное ускорение для глубокого обучения, высокопроизводительных вычислений (HPC) и анализа данных. Благодаря технологическим прорывам в архитектуре NVIDIA Ampere, таким как тензорные ядра третьего поколения, точность TensorFloat-32 (TF32) и структурная разреженность, NVIDIA A100 обеспечивает унифицированный ускоритель рабочих нагрузок для анализа данных, обучения ИИ, вывода ИИ и высокопроизводительных вычислений.
В сочетании с программным пакетом NVIDIA AI Enterprise, который оптимизирован для разработки и развертывания ИИ и сертифицирован для работы в виртуализированных средах, NVIDIA A100 ускоряет работу всех основных сред глубокого обучения и анализа данных, таких как TensorFlow и PyTorch, а также более 700 приложений HPC.
Облачные экземпляры с одним или несколькими физическими графическими процессорами обычно продаются за тысячи долларов в месяц. Напротив, сегодня мы представляем набор планов Vultr, которые дают вам часть графического процессора NVIDIA A100 с тензорными ядрами, а также выделенные виртуальные ЦП, ОЗУ, хранилище и пропускную способность по цене от 90 долларов в месяц или 0,13 доллара в час. Эти экземпляры позволяют выделять ресурсы графического процессора с большей степенью детализации и предоставляют разработчикам оптимальный объем ускоренных вычислений.
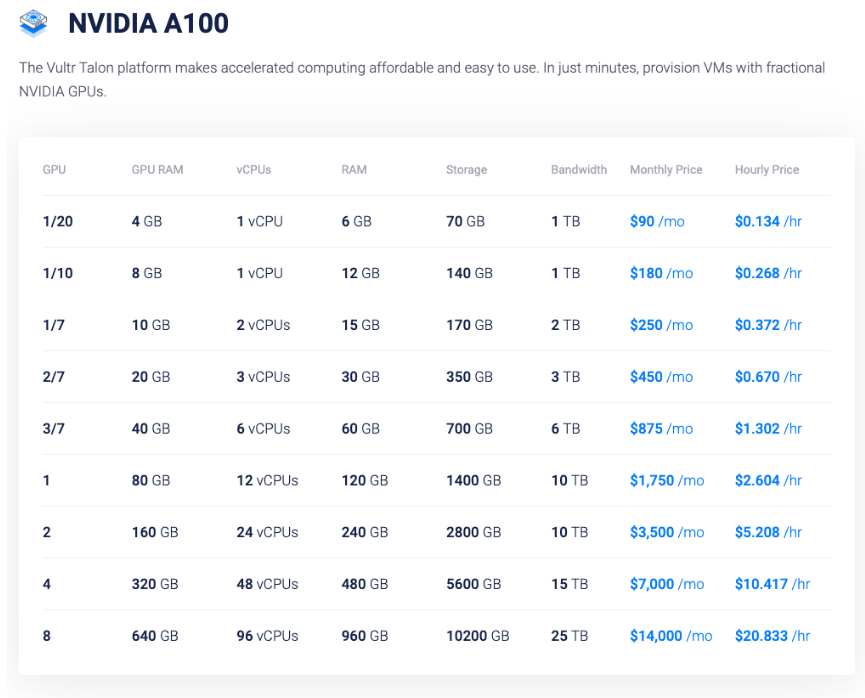
Прямо сейчас в нашей панели управления вы можете предоставить инстансы GPU с широким спектром спецификаций.
Что вы можете делать с виртуализированным графическим процессором NVIDIA A100 с тензорными ядрами?
Планы Vultr с графическим процессором NVIDIA A100 и программным обеспечением NVIDIA AI Enterprise подходят для широкого спектра сценариев использования в производстве и разработке. В частности, мы рекомендуем их для рабочих нагрузок вывода ML и построения моделей для обработки естественного языка, распознавания голоса и компьютерного зрения.
В дополнение к пакету программного обеспечения NVIDIA AI Enterprise, NVIDIA также предлагает каталог NGC, центр дополнительного программного обеспечения для искусственного интеллекта и высокопроизводительных вычислений, оптимизированного для графических процессоров. NGC включает в себя контейнеры корпоративного уровня, фреймворки, предварительно обученные модели, диаграммы Helm и отраслевые комплекты разработки программного обеспечения (SDK) для специалистов по данным, разработчиков и команд DevOps, чтобы быстрее создавать и развертывать свои решения. С помощью NGC разработчики могут развертывать оптимизированные по производительности программные контейнеры AI/HPC, предварительно обученные модели AI и ноутбуки Jupyter, которые ускоряют разработку AI и рабочие нагрузки HPC в любых локальных, облачных и пограничных системах с GPU.
Для ресурсоемких рабочих нагрузок ИИ, таких как подготовка данных и обучение глубокому обучению, клиенты могут выбрать использование нескольких графических процессоров или полноценного NVIDIA A100. Менее ресурсоемкие рабочие нагрузки, такие как вывод ИИ или периферийный ИИ, часто не требуют полной вычислительной мощности графического процессора и могут выполняться на предложениях меньшего размера виртуальных графических процессоров.
Графический процессор Bare Metal для больших рабочих нагрузок
Если вы хотите выполнить рабочую нагрузку, требующую нескольких физических графических процессоров, у нас также есть серверы Bare Metal с четырьмя графическими процессорами NVIDIA A100 и двумя 24-ядерными процессорами Intel Xeon.
Сегодняшний запуск — это бета-версия с начальной мощностью в Нью-Джерси. В ближайшие недели мы добавим глобальный ассортимент графических процессоров
NVIDIA A100, A40 и A16, чтобы лучше поддерживать дополнительные регионы и более широкий спектр вариантов использования.
Если вы заинтересованы в том, чтобы попробовать Vultr Talon, вы можете предоставить экземпляры через нашу панель управления. Вы найдете дополнительные рекомендации о том, как начать работу, в разделе документации на нашем веб-сайте.
Если вы хотите поговорить с нами о ваших потребностях, мы рекомендуем вам связаться с нашим отделом продаж.