Дизайнеры «Спринтхост» сотворили «табуретку» — всем нравится.
 Стильный лого — отражение компании
Стильный лого — отражение компании
Логотип — это лицо компании, которое отражает её суть и привлекает внимание. Поэтому крайне важно создать правильный и запоминающийся логотип.
Кто-то сильно не заморачивается и просто использует своё название в качестве логотипа, кто-то, наоборот, изворачивается так, что это уже не просто отражение компании, но целый герб с тысячелетней историей происхождения. Однако большинство все-таки старается прибегать к минимализму. Например, Toyota, у которых в логотипе зашифрованы все буквы названия, или Puma, у которых изображена, не поверите, пума. Но что делать тем, у кого название компании является чем-то абстрактным? Приходится выкручиваться.
Спринтхост тоже абстрактное название. Единственное, с чем можно его связать, это скорость и хостинг. Если подумать, то изобразить и скорость, и хостинг можно, но наши дизайнеры решили пойти сложным, но интересным путем.
Проба пера — первые логотипы
Логотип компании всегда делился на знаковую и текстовую части. Первым вариантом было простое название в оранжево-черных цветах со знаком слева от текстовой части. Просто, но в то же время ничем особым не выделяется. Однако такой логотип прожил дольше всех остальных — 8 лет.
Позже появилась миловидная девочка-ракета все в тех же цветах, но поменялось расположение. Теперь знак находится над текстовой частью, что сделало логотип более компактным. Также изменился шрифт и ушло в небытие окончание «.ru».
В третьем логотипе уже преобразился знак — вместо ракеты появился самый настоящий космический корабль. Кроме того, несколько изменились оттенки цветов.
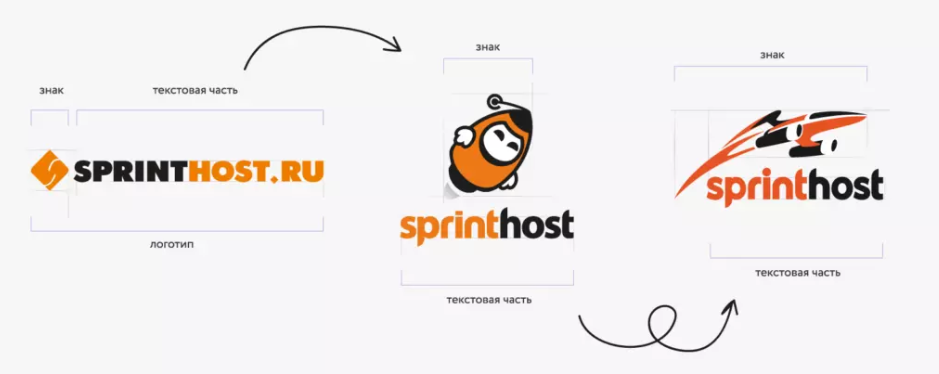 Сверхсветовой прыжок к новому логотипу
Сверхсветовой прыжок к новому логотипу
Чёрно-оранжевый летательный аппарат казался нашим дизайнерам дерзким, динамичным, но немного ретро. Космический корабль был детализированным, из-за чего было сложно его использовать в маленьком размере. Карандаши и кисточки требовали перемен, поэтому началась работа над новым современным логотипом.
Здесь нужно сделать небольшую ремарку о том, что помимо Спринтхост есть ещё и Спринтбокс со своим лого. Он был удобен и всем нравился, нужно было только немного подправить детали: дизайнер склеила все элементы, чтобы он стал цельным (в будущем это помогло нам в вывесках и трафаретах), убрала всё лишнее.
Новый логотип Спринтхост стал именно таким благодаря Спринтбокс. Была сохранена динамика знака, толщина линий и уровень абстракции. Нам не хотелось эксплуатировать прямые ассоциации по типу серверов, ведь это скучно, неприглядно и банальненько.
В этот же момент произошло импортозамещение букв в логотипе с латиницы на кириллицу. Выглядеть стало, действительно, живее, пропали символы с выносными элементами («i», «t», «h»), но название «Спринтхост» сильно длиннее англичанского варианта.

Соответственно, считываемость силуэта буквенной части снизилась. Началась долгая работа над текстом. Мы выбирали шрифт, подходящий под характеры всех знаков: гротеск, широкая апертура (открытые буквы), низкий контраст. Хорошо было бы взять шрифт с высокой ёмкостью, потому что слово длинное, но визуально ни один такой шрифт нам не нравился и к округлому знаку он не подходил. Сначала мы сделали логотип с простым набором в строку — мы отрицали возможность разбивать название на отдельные слова «Спринт» и «хост». Потом стало понятно, что такую длинную и узкую конструкцию далеко не всегда удобно использовать, поэтому появилась вторая версия знака с раздельным написанием, ставшая основной.

Знак Спринтхост существовал в двух версиях. Одна удобная для использования, но выбивающаяся из сетки остальных логотипов, которые уже были приведены к общему знаменателю (Спринтбокс, Спринтлабс). Вторая соотносится с другими лого, но менее удобная в использовании из-за торчащих слева хвостов.

Оптическая масса логотипа — это круг, центр логотипа — это центр круга, но из-за хвостов физический центр становится сильно левее оптического, что мешает выравниванию знака по левому краю или по центру.
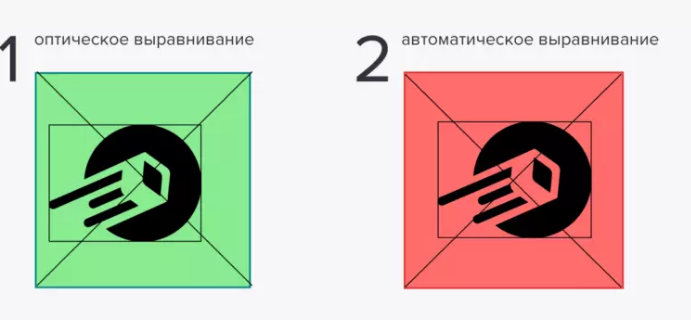
В итоге мы решили усидеть на двух стульях сразу: выбрали вариант с хвостами для общего использования, например, на сайте, а для аватарок в соцсетях и фавиконок взяли версию с обрезанными рожками.
Если кто-то спросит, какой смысл заложен в логотип, то мы ответим, что его нет. Нашему дизайнеру нравится цитата классика графического дизайна Пола Рэнда: «Логотип в первую очередь говорит кто, а не что, и в этом его функция». То есть логотип не продаёт сам по себе, а только идентифицирует и не противоречит своему бренду.
Логотип Спринтхост — это просто динамичная технологичная штуковина, которая куда-то стремительно движется. Но есть забавные смыслы, которые вкладывают в логотип те, кто его видит. Например, что это табуреточка или карандаш с ластиком (я вообще здесь вижу медузу — прим. автора). Такие безобидные и в чем-то необычные ассоциации нам даже на руку, больше шансов запомнить.
Под конец творческая работа уже закончилась, началась техническая часть — подогнать все знаки и логотипы под один формат. Нужно было проследить за тем, чтобы у логотипов была единая оптическая масса в пятнах, один вес. Убедились, что они хорошо выравниваются друг с другом, все базовые линии совпадают.
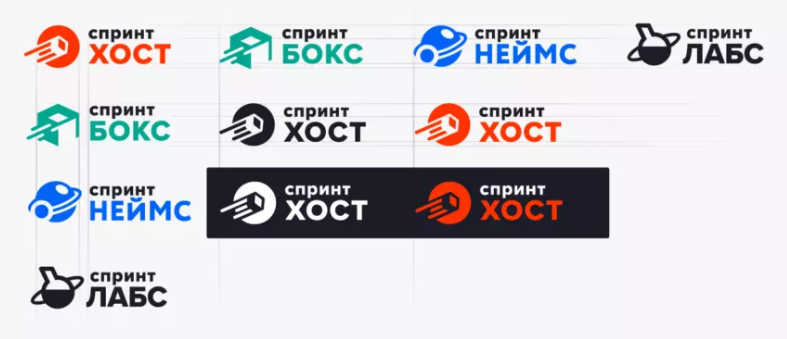
Дальше сделали цветные, белые и латинские версии. Конечно, не забыли написать обо всём этом гайдлайн. Теперь у нас есть система, которая отлично расширяется. Позже появился Спринтнеймс, и с поиском решений для него не было проблем. Он хорошо вписался в линейку остальных знаков. Основные цвета остались прежними, только подкорректировали оттенки.
Что будет дальше и когда логотип снова нужно будет менять, мы не знаем. Но мы всегда готовы меняться, чтобы стать лучше. Это касается не только логотипов, но и всего нашего сервиса. Сейчас наши логотипы нам нравятся, поэтому их редизайн в ближайшее время не планируем.