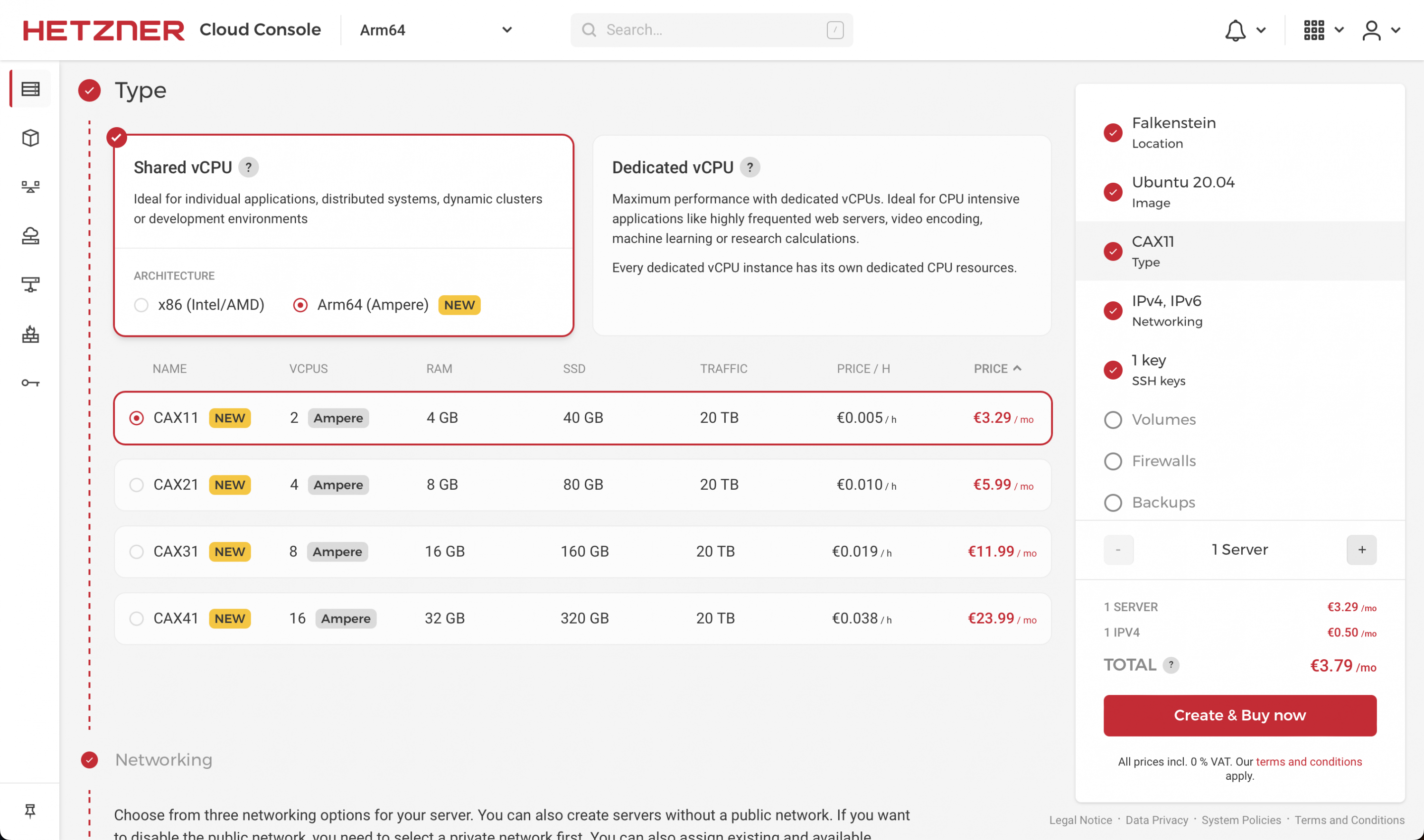
Ранее сегодня Hetzner, немецкий поставщик услуг хостинга и облачных вычислений, запустил четыре новых облачных сервера Hetzner, которые стали первыми серверами Hetzner, использующими инновационную технологию Arm. Они поставляются с 16 виртуальными ЦП на базе процессоров Ampere® Altra®. «Чрезвычайно эффективные и мощные облачные процессоры Ampere на базе Arm впечатляют пользователей с момента их выпуска. Они также представляют собой интересную альтернативу процессорам AMD и Intel, которые до сих пор были двумя основными вариантами для облачных серверов Hetzner. С новыми инстансами Arm64 Cloud мы можем предоставить нашим клиентам больше возможностей и гибкости, а также отличное соотношение цены и качества», — пояснил Маркус Шаде, руководитель группы облачной платформы в Hetzner. Более года назад Hetzner объявила о новом партнерстве с Ampere и представила выделенный сервер на базе Arm64. «Благодаря облачным серверам Hetzner CAX, построенным на семействе облачных процессоров Ampere® Altra®, клиенты по всему миру теперь получают доступ к самой эффективной доступной облачной инфраструктуре», — сказал Джефф Виттич, директор по продуктам Ampere. «Сочетая в себе высокую производительность, экономическую эффективность и самые устойчивые вычислительные ресурсы, доступные сегодня, клиентам Hetzner больше не нужно идти на компромисс, чтобы получить больше за меньшие деньги при аренде облачных серверов CAX».
Новая линейка планов облачных серверов Hetzner «CAX» включает до 32 ГБ ОЗУ ECC и до 320 ГБ хранилища на основе NVMe SSD. Благодаря отличной производительности облачные планы идеально подходят для веб-серверов, которые принимают много посетителей, для серверов, используемых для запуска различных приложений, и для других ресурсоемких рабочих нагрузок. Если пользователям потребуется масштабирование позже, можно легко добавить дополнительные ресурсы в любое время в соответствии с растущим вариантом использования, например, добавив дополнительное хранилище на основе SSD на свой облачный сервер. Все образы операционных систем Hetzner Cloud и приложения, запускаемые в один клик, поддерживают обширную экосистему Arm — клиенты могут использовать их так же, как и любые другие серверы Hetzner Cloud. Архитектура новой линейки CAX позволит пользователям создавать собственные приложения и облачные контейнеры на базе Arm64.
Для администрирования своего облачного сервера клиенты имеют доступ к интуитивно понятной и удобной облачной консоли Hetzner, которая включает в себя множество впечатляющих и полезных функций, таких как функция балансировки нагрузки, которая позволяет пользователям направлять свой трафик в предварительно настроенную инфраструктуру, а функция для создания безопасных частных сетей. Благодаря удобному для программиста инструменту REST-API и CLI от Hetzner клиенты могут автоматизировать процессы и интегрировать инструменты сторонних производителей. И, конечно же, Hetzner предоставляет обширную документацию и примеры программирования, чтобы сделать начало работы еще проще.
Новые планы серверов начинаются с непревзойденных цен всего за 3,79 евро в месяц, включая IPv4-адрес, без платы за установку или минимального срока действия контракта. Если серверы пользователей существуют только часть месяца, они будут платить только за часы, когда серверы существовали. Этот вариант почасовой оплаты дает клиентам еще большую гибкость и помогает снизить расходы.
Hetzner запустила все четыре новые модели облачных серверов в своем парке центров обработки данных, сертифицированном по стандарту ISO 27001, в Фалькенштайне, Германия, и постепенно добавит их в другие места.
Hetzner имеет репутацию поставщика мощных продуктов и услуг, и на протяжении многих лет ему доверяют разработчики веб-сайтов, приложений и игр; бизнес-клиенты; и отдельных пользователей. Поэтому неудивительно, что Hetzner Cloud уже завоевал множество наград на церемонии вручения наград Service Provider Awards. Тысячи читателей различных ИТ-порталов согласны с этим и выбрали Hetzner победителем этих наград.
См. полный обзор всех планов и цен на облачные серверы здесь:
www.hetzner.com/cloud