BigQuery и суррогатные ключи: практический подход
При работе с таблицами в средах хранилища данных довольно часто встречается ситуация, при которой вам нужно генерировать суррогатные ключи. Суррогатный ключ — это сгенерированный системой идентификатор, который однозначно идентифицирует запись в таблице.
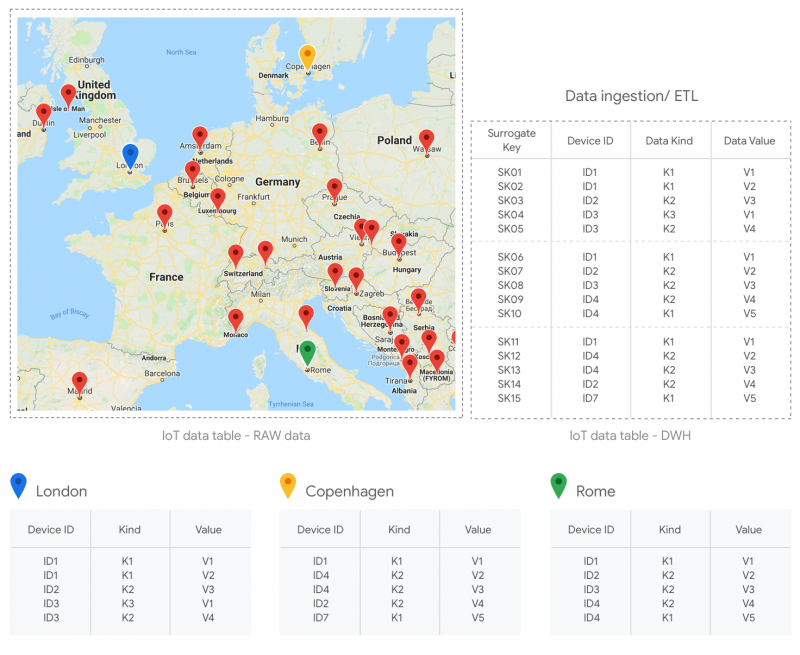
Почему нам нужно использовать суррогатные ключи? Совершенно просто: вопреки естественным ключам они сохраняются с течением времени (т. Е. Они не привязаны ни к каким бизнес-значениям), и они допускают неограниченные значения. Подумайте о таблице, которая собирает данные IoT с нескольких устройств в разных регионах: поскольку вы хотите хранить неограниченные данные, и у вас могут быть возможные совпадения с идентификаторами устройств, суррогатные ключи помогут многозначительно идентифицировать запись. Другим вариантом использования может быть таблица «items», в которой вы хотите хранить информацию, связанную не только со статьями, но и с историей изменений, сделанных на данных: даже в этом случае суррогатные ключи могут быть изящным решением, позволяющим легко присваивать уникальные идентификаторы всем записям
Как сгенерировать суррогатные ключи
Обычный способ генерации суррогатных ключей — назначить инкрементный номер каждой строке таблицы: вы можете достичь этой цели, используя стандартную функцию
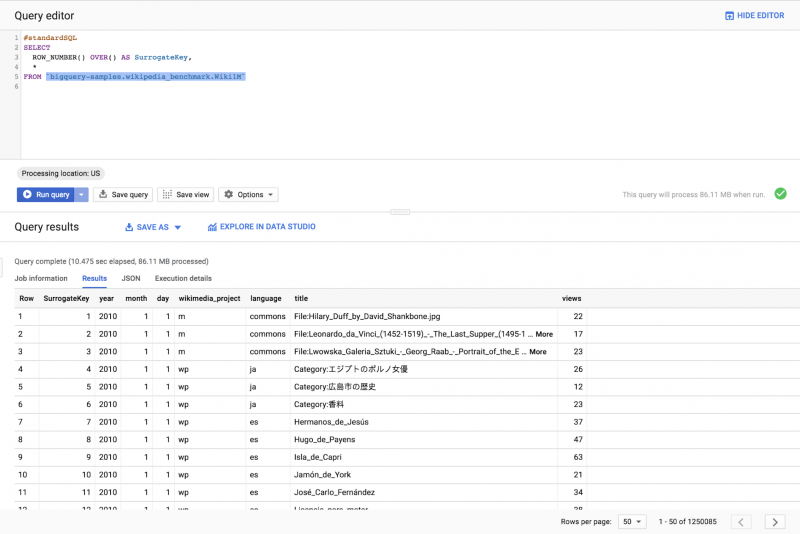
К сожалению, этот подход ограничен. Для реализации ROW_NUMBER () BigQuery необходимо сортировать значения в корневом узле дерева выполнения, который ограничен объемом памяти в одном узле выполнения.
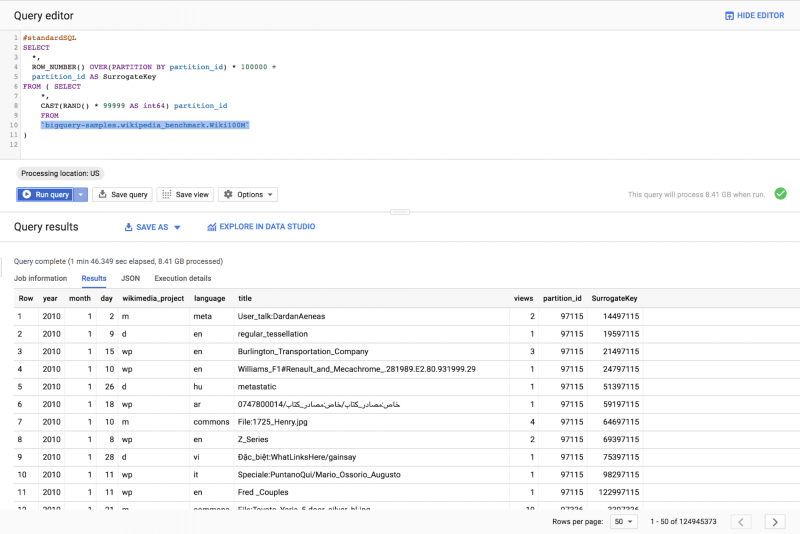
Общее решение заключается в разделении данных с использованием предиката PARTITION в сочетании с полями раздела, чтобы получить уникальный идентификатор для каждой строки.
Альтернативный подход
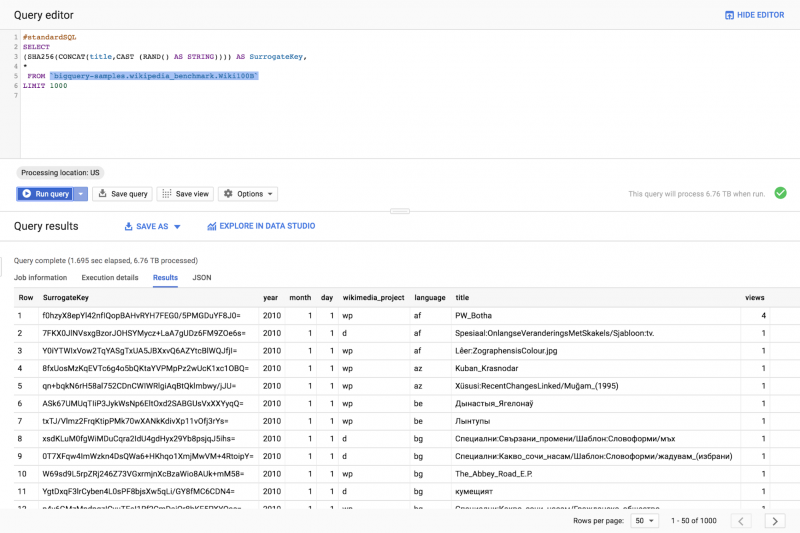
Другое решение, которое вы можете принять, особенно в потоковых сценариях, зависит от хэш-функций. Поскольку этот шаблон вычисляет суррогатные значения ключа во время выполнения, его можно применять к наборам данных любого измерения. Идея состоит в том, чтобы вычислить SHA256 дайджест выбранных полей записи и использовать результат в качестве суррогатного ключа.
Возможны два возможных подхода:
UPDATE, когда существующие записи необходимо обновить (играть с фильтрами, чтобы выбрать правильные данные для обновления)
Когда вы планируете свои действия, обратите внимание, что вы ограничены 1000 операций INSERT на таблицу в день и 200 операций UPDATE на таблицу в день.
В случае дублирования записей в исходной таблице случайное значение может быть объединено до вычисления дайджеста: это уменьшит вероятность столкновения с конфликтами. Если вы хотите быть в курсе будущих дополнений, подумайте о закладке страницы заметок выпуска.
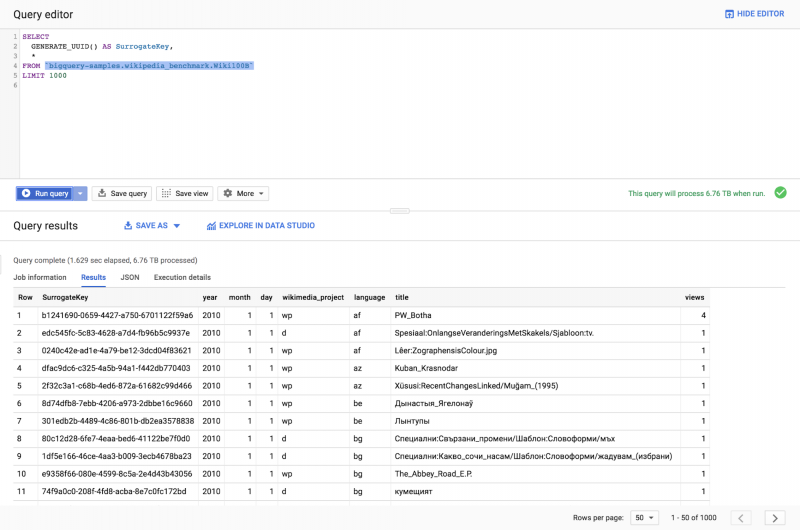
Другим способом достижения такого же результата является использование новой функции GENERATE_UUID (), которая генерирует уникальный идентификатор для каждой строки результата запроса во время выполнения. Сгенерированный ключ будет строчной строкой, состоящей из 32 шестнадцатеричных цифр в пяти группах, разделенных дефисом в форме 8-4-4-4-12.
Вывод
Суррогатные ключи распространены в средах хранилища данных, поскольку они:
BigQuery предоставляет конечным пользователям возможность легко справляться с суррогатными ключами, позволяя их генерировать и обновлять по шкале.
cloud.google.com/blog/products/data-analytics/bigquery-and-surrogate-keys-practical-approach
Почему нам нужно использовать суррогатные ключи? Совершенно просто: вопреки естественным ключам они сохраняются с течением времени (т. Е. Они не привязаны ни к каким бизнес-значениям), и они допускают неограниченные значения. Подумайте о таблице, которая собирает данные IoT с нескольких устройств в разных регионах: поскольку вы хотите хранить неограниченные данные, и у вас могут быть возможные совпадения с идентификаторами устройств, суррогатные ключи помогут многозначительно идентифицировать запись. Другим вариантом использования может быть таблица «items», в которой вы хотите хранить информацию, связанную не только со статьями, но и с историей изменений, сделанных на данных: даже в этом случае суррогатные ключи могут быть изящным решением, позволяющим легко присваивать уникальные идентификаторы всем записям
Как сгенерировать суррогатные ключи
Обычный способ генерации суррогатных ключей — назначить инкрементный номер каждой строке таблицы: вы можете достичь этой цели, используя стандартную функцию
ROW_NUMBER() OVER({window_name | (window_specification)})SELECT
ROW_NUMBER() OVER() AS SurrogateKey,
*
FROM `bigquery-samples.wikipedia_benchmark.Wiki1M`К сожалению, этот подход ограничен. Для реализации ROW_NUMBER () BigQuery необходимо сортировать значения в корневом узле дерева выполнения, который ограничен объемом памяти в одном узле выполнения.
Общее решение заключается в разделении данных с использованием предиката PARTITION в сочетании с полями раздела, чтобы получить уникальный идентификатор для каждой строки.
Альтернативный подход
Другое решение, которое вы можете принять, особенно в потоковых сценариях, зависит от хэш-функций. Поскольку этот шаблон вычисляет суррогатные значения ключа во время выполнения, его можно применять к наборам данных любого измерения. Идея состоит в том, чтобы вычислить SHA256 дайджест выбранных полей записи и использовать результат в качестве суррогатного ключа.
Возможны два возможных подхода:
INSERT INTO, когда новые записи должны быть вставлены в таблицу (воспроизведение с внутренним запросом для выбора целевых данных, которые необходимо вставить в таблицу целей)INSERT INTO `MyPrj.MyDataset.Wiki100B_With_SK`
(SurrogateKey,year,month,day,wikimedia_project,language,title,views)
SELECT (SHA256(title)) AS SurrogateKey,*
FROM `bigquery-samples.wikipedia_benchmark.Wiki100B`UPDATE, когда существующие записи необходимо обновить (играть с фильтрами, чтобы выбрать правильные данные для обновления)
UPDATE `MyPrj.MyDataset.Wiki100B_With_SK`
SET SurrogateKey = (SHA256(title))
WHERE year = 2010Когда вы планируете свои действия, обратите внимание, что вы ограничены 1000 операций INSERT на таблицу в день и 200 операций UPDATE на таблицу в день.
В случае дублирования записей в исходной таблице случайное значение может быть объединено до вычисления дайджеста: это уменьшит вероятность столкновения с конфликтами. Если вы хотите быть в курсе будущих дополнений, подумайте о закладке страницы заметок выпуска.
Другим способом достижения такого же результата является использование новой функции GENERATE_UUID (), которая генерирует уникальный идентификатор для каждой строки результата запроса во время выполнения. Сгенерированный ключ будет строчной строкой, состоящей из 32 шестнадцатеричных цифр в пяти группах, разделенных дефисом в форме 8-4-4-4-12.
SELECT
GENERATE_UUID() AS SurrogateKey,
*
FROM `bigquery-samples.wikipedia_benchmark.Wiki100B`Вывод
Суррогатные ключи распространены в средах хранилища данных, поскольку они:
- Контекстно-независимый
- Больше совместимости с будущим
- Потенциально бесконечно масштабируемый
BigQuery предоставляет конечным пользователям возможность легко справляться с суррогатными ключами, позволяя их генерировать и обновлять по шкале.
cloud.google.com/blog/products/data-analytics/bigquery-and-surrogate-keys-practical-approach