Управление Kubernetes над Kubernetes было хорошей идеей
Управление Kubernetes над Kubernetes было хорошей идеей для компонентов без контроля состояния плоскости управления… но как насчет etcd?

В нашем предыдущем посте мы описали архитектуру Kubinception, как мы запускаем Kubernetes над Kubernetes для компонентов без состояний в плоскостях управления кластерами клиентов. Но как насчет компонента с состоянием, etcd?
Необходимость очевидна: каждый кластер клиентов должен иметь доступ к etcd, чтобы иметь возможность хранить и извлекать данные. Весь вопрос в том, где и как развернуть etcd, чтобы сделать его доступным для каждого кластера клиентов.
Самая простая идея не всегда хорошая
Первый подход заключается в простом следовании логике Kubinception: для каждого клиентского кластера развертывание кластера etcd в качестве модулей, работающих на административном кластере.
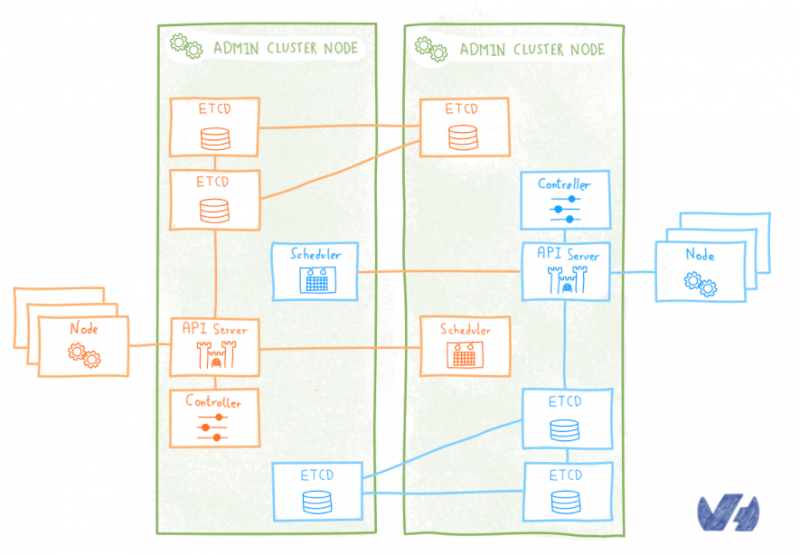
Этот полный подход Kubinception имеет преимущество быть простым, он кажется продолжением того, что мы делаем с компонентами без сохранения состояния. Но если взглянуть на него подробно, он показывает свои недостатки. Развертывание кластера etcd не так просто и просто, как развертывание без сохранения состояния и является критически важным для работы кластера, мы не могли просто обработать его вручную, нам был необходим автоматизированный подход для управления им на более высоком уровне. www.diycode.cc/projects/coreos/etcd-operator
Использование оператора
Мы были не единственными, кто думал, что сложность работы с развертыванием и работой кластера etcd на Kubernetes была чрезмерной, люди из CoreOS заметили это, и в 2016 году они выпустили элегантное решение проблемы: etcd оператор coreos.com/blog/introducing-the-etcd-operator.html
Оператор — это специальный контроллер, который расширяет API Kubernetes для простого создания, настройки и управления экземплярами сложных (часто распределенных) приложений с отслеживанием состояния в Kubernetes. Для записи, понятие оператора было введено CoreOS с оператором etcd.
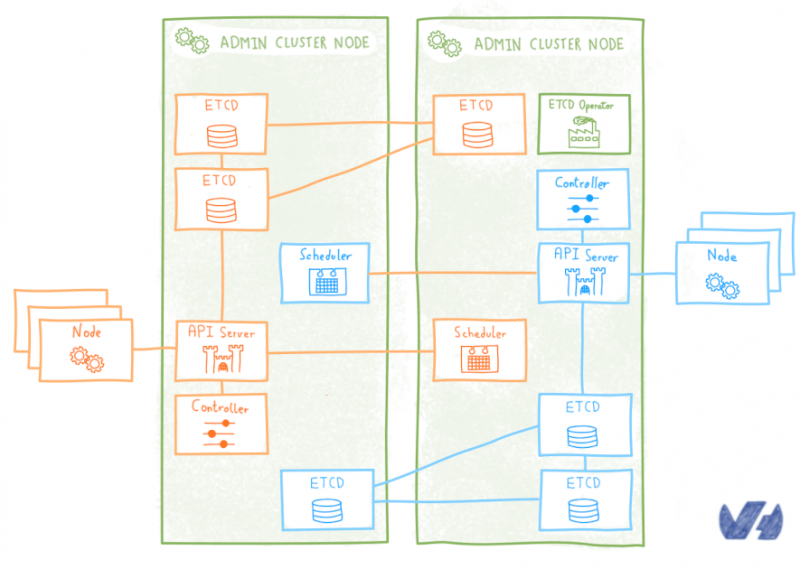
Оператор etcd управляет кластерами etcd, развернутыми в Kubernetes, и автоматизирует рабочие задачи: создание, уничтожение, изменение размера, аварийное переключение, непрерывное обновление, резервное копирование
kubernetes.io
Как и в предыдущем решении, кластер etcd для каждого клиентского кластера развертывается в качестве модулей в административном кластере. По умолчанию оператор etcd развертывает кластер etcd, используя локальное непостоянное хранилище для каждого модуля etcd. Это означает, что если все модули умирают (маловероятно) или перепланируются и появляются в другом узле (гораздо более вероятно), мы можем потерять данные etcd. А без этого заказчик Kubernetes оказывается в кирпиче.
Оператор etcd может быть настроен на использование постоянных томов (PV) для хранения данных, поэтому теоретически проблема была решена. Теоретически, поскольку управление томами не было достаточно зрелым, когда мы тестировали его, и если модуль etcd был убит и переназначен, новый модуль не смог получить свои данные на PV. Таким образом, риск полной потери кворума и блокирования клиентского кластера все еще был у оператора etcd.
kubernetes.io/docs/concepts/storage/persistent-volumes/
Короче говоря, мы немного поработали с оператором etcd и обнаружили, что он недостаточно зрел для нашего использования.
StatefulSet
Помимо оператора, другим решением было использование StatefulSet, своего рода распределенного развертывания, хорошо подходящего для управления распределенными приложениями с отслеживанием состояния.
kubernetes.io/docs/concepts/workloads/controllers/statefulset/
kubernetes.io/docs/concepts/workloads/controllers/deployment/
github.com/helm/charts/tree/master/incubator/etcd
Существует официальная диаграмма ETCD Helm, которая позволяет развертывать кластеры ETCD в виде StafefulSets, которая обменивает некоторую гибкость оператора и удобство для пользователя на более надежное управление PV, которое гарантирует, что перепланированный модуль etcd будет получать свои данные.
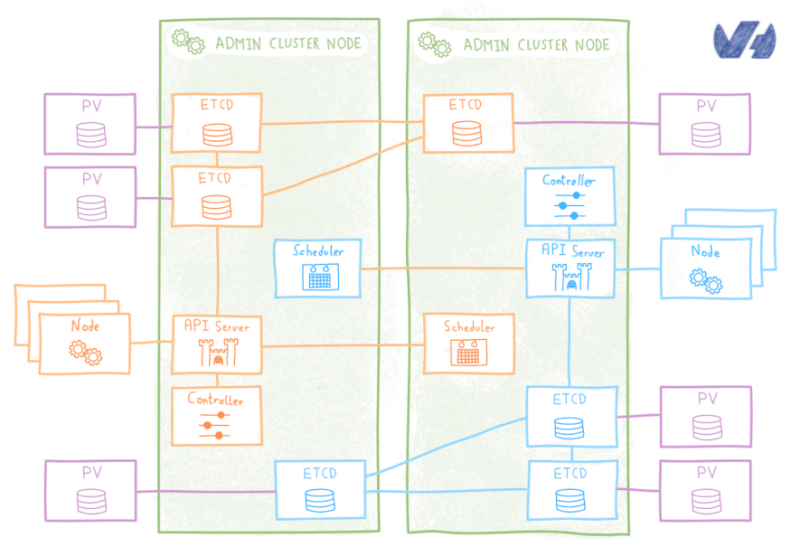
Etcd StatefulSet менее удобен, чем оператор etcd, поскольку он не предлагает простого API для операций, таких как масштабирование, отработка отказа, последовательное обновление или резервное копирование. Взамен вы получаете некоторые реальные улучшения в управлении PV. StatefulSet поддерживает липкую идентификацию для каждой записи etcd, и этот постоянный идентификатор сохраняется при любом перепланировании, что позволяет просто связать его с PV.
Система настолько устойчива, что даже если мы потеряем все модули etcd, когда Kubernetes перепланирует их, они найдут свои данные, и кластер продолжит работать без проблем.
Постоянные объемы, задержка и простой расчет затрат
Etcd StatefulSet казался хорошим решением… пока мы не начали интенсивно его использовать. В etcd StatefulSet используются PV, то есть тома сетевого хранилища. И т.д.DD довольно чувствительны к задержке в сети, ее производительность сильно ухудшается, когда сталкивается с задержкой.
Даже если задержку можно держать под контролем (и это очень важно), чем больше мы думаем об этой идее, тем больше она кажется дорогостоящим решением. Для каждого клиентского кластера нам нужно будет развернуть три модуля (фактически удваивая количество модулей) и три связанных PV, это плохо масштабируется для управляемой службы.
В сервисе OVH Managed Kubernetes мы выставляем счета нашим клиентам в соответствии с количеством рабочих узлов, которые они используют, то есть плоскость управления свободна. Это означает, что для обеспечения конкурентоспособности сервиса важно держать под контролем ресурсы, потребляемые плоскостями управления, поэтому нет необходимости удваивать количество пакетов с помощью etcd.
С Kubinception мы пытались мыслить нестандартно, казалось, что для etcd нам нужно было выбраться из этой коробки еще раз.
Мультитенантный кластер etcd
Если мы не хотели развертывать etcd внутри Kubernetes, альтернативой было бы развернуть его снаружи. Мы решили развернуть мультитенантный кластер etcd на выделенных серверах. Все клиентские кластеры будут использовать один и тот же ETCD, каждый сервер API получает свое место в этом мультитенантном кластере etcd.
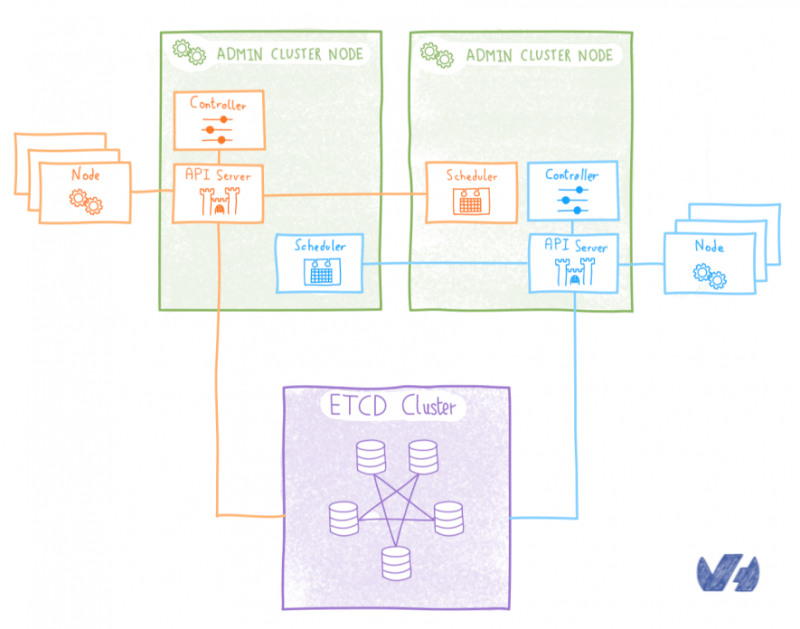
Благодаря такому решению устойчивость обеспечивается обычными механизмами etcd, проблемы с задержкой не возникает, поскольку данные находятся на локальном диске каждого узла etcd, а количество модулей остается под контролем, поэтому оно решает основные проблемы, которые у нас возникли с другими решение. Компромисс здесь заключается в том, что нам нужно установить и использовать этот внешний кластер etcd, а также управлять контролем доступа, чтобы каждый сервер API имел доступ только к своим собственным данным.
Что дальше?
В следующих статьях из серии Kubernetes мы углубимся в другие аспекты построения OVH Managed Kubernetes и дадим клавиатуру некоторым из наших бета-клиентов, чтобы рассказать о своем опыте использования сервиса.
На следующей неделе давайте сосредоточимся на другой теме, мы разберемся с языком запросов TSL, и почему мы его создали и открыли
В нашем предыдущем посте мы описали архитектуру Kubinception, как мы запускаем Kubernetes над Kubernetes для компонентов без состояний в плоскостях управления кластерами клиентов. Но как насчет компонента с состоянием, etcd?
Необходимость очевидна: каждый кластер клиентов должен иметь доступ к etcd, чтобы иметь возможность хранить и извлекать данные. Весь вопрос в том, где и как развернуть etcd, чтобы сделать его доступным для каждого кластера клиентов.
Самая простая идея не всегда хорошая
Первый подход заключается в простом следовании логике Kubinception: для каждого клиентского кластера развертывание кластера etcd в качестве модулей, работающих на административном кластере.
Этот полный подход Kubinception имеет преимущество быть простым, он кажется продолжением того, что мы делаем с компонентами без сохранения состояния. Но если взглянуть на него подробно, он показывает свои недостатки. Развертывание кластера etcd не так просто и просто, как развертывание без сохранения состояния и является критически важным для работы кластера, мы не могли просто обработать его вручную, нам был необходим автоматизированный подход для управления им на более высоком уровне. www.diycode.cc/projects/coreos/etcd-operator
Использование оператора
Мы были не единственными, кто думал, что сложность работы с развертыванием и работой кластера etcd на Kubernetes была чрезмерной, люди из CoreOS заметили это, и в 2016 году они выпустили элегантное решение проблемы: etcd оператор coreos.com/blog/introducing-the-etcd-operator.html
Оператор — это специальный контроллер, который расширяет API Kubernetes для простого создания, настройки и управления экземплярами сложных (часто распределенных) приложений с отслеживанием состояния в Kubernetes. Для записи, понятие оператора было введено CoreOS с оператором etcd.
Оператор etcd управляет кластерами etcd, развернутыми в Kubernetes, и автоматизирует рабочие задачи: создание, уничтожение, изменение размера, аварийное переключение, непрерывное обновление, резервное копирование
kubernetes.io
Как и в предыдущем решении, кластер etcd для каждого клиентского кластера развертывается в качестве модулей в административном кластере. По умолчанию оператор etcd развертывает кластер etcd, используя локальное непостоянное хранилище для каждого модуля etcd. Это означает, что если все модули умирают (маловероятно) или перепланируются и появляются в другом узле (гораздо более вероятно), мы можем потерять данные etcd. А без этого заказчик Kubernetes оказывается в кирпиче.
Оператор etcd может быть настроен на использование постоянных томов (PV) для хранения данных, поэтому теоретически проблема была решена. Теоретически, поскольку управление томами не было достаточно зрелым, когда мы тестировали его, и если модуль etcd был убит и переназначен, новый модуль не смог получить свои данные на PV. Таким образом, риск полной потери кворума и блокирования клиентского кластера все еще был у оператора etcd.
kubernetes.io/docs/concepts/storage/persistent-volumes/
Короче говоря, мы немного поработали с оператором etcd и обнаружили, что он недостаточно зрел для нашего использования.
StatefulSet
Помимо оператора, другим решением было использование StatefulSet, своего рода распределенного развертывания, хорошо подходящего для управления распределенными приложениями с отслеживанием состояния.
kubernetes.io/docs/concepts/workloads/controllers/statefulset/
kubernetes.io/docs/concepts/workloads/controllers/deployment/
github.com/helm/charts/tree/master/incubator/etcd
Существует официальная диаграмма ETCD Helm, которая позволяет развертывать кластеры ETCD в виде StafefulSets, которая обменивает некоторую гибкость оператора и удобство для пользователя на более надежное управление PV, которое гарантирует, что перепланированный модуль etcd будет получать свои данные.
Etcd StatefulSet менее удобен, чем оператор etcd, поскольку он не предлагает простого API для операций, таких как масштабирование, отработка отказа, последовательное обновление или резервное копирование. Взамен вы получаете некоторые реальные улучшения в управлении PV. StatefulSet поддерживает липкую идентификацию для каждой записи etcd, и этот постоянный идентификатор сохраняется при любом перепланировании, что позволяет просто связать его с PV.
Система настолько устойчива, что даже если мы потеряем все модули etcd, когда Kubernetes перепланирует их, они найдут свои данные, и кластер продолжит работать без проблем.
Постоянные объемы, задержка и простой расчет затрат
Etcd StatefulSet казался хорошим решением… пока мы не начали интенсивно его использовать. В etcd StatefulSet используются PV, то есть тома сетевого хранилища. И т.д.DD довольно чувствительны к задержке в сети, ее производительность сильно ухудшается, когда сталкивается с задержкой.
Даже если задержку можно держать под контролем (и это очень важно), чем больше мы думаем об этой идее, тем больше она кажется дорогостоящим решением. Для каждого клиентского кластера нам нужно будет развернуть три модуля (фактически удваивая количество модулей) и три связанных PV, это плохо масштабируется для управляемой службы.
В сервисе OVH Managed Kubernetes мы выставляем счета нашим клиентам в соответствии с количеством рабочих узлов, которые они используют, то есть плоскость управления свободна. Это означает, что для обеспечения конкурентоспособности сервиса важно держать под контролем ресурсы, потребляемые плоскостями управления, поэтому нет необходимости удваивать количество пакетов с помощью etcd.
С Kubinception мы пытались мыслить нестандартно, казалось, что для etcd нам нужно было выбраться из этой коробки еще раз.
Мультитенантный кластер etcd
Если мы не хотели развертывать etcd внутри Kubernetes, альтернативой было бы развернуть его снаружи. Мы решили развернуть мультитенантный кластер etcd на выделенных серверах. Все клиентские кластеры будут использовать один и тот же ETCD, каждый сервер API получает свое место в этом мультитенантном кластере etcd.
Благодаря такому решению устойчивость обеспечивается обычными механизмами etcd, проблемы с задержкой не возникает, поскольку данные находятся на локальном диске каждого узла etcd, а количество модулей остается под контролем, поэтому оно решает основные проблемы, которые у нас возникли с другими решение. Компромисс здесь заключается в том, что нам нужно установить и использовать этот внешний кластер etcd, а также управлять контролем доступа, чтобы каждый сервер API имел доступ только к своим собственным данным.
Что дальше?
В следующих статьях из серии Kubernetes мы углубимся в другие аспекты построения OVH Managed Kubernetes и дадим клавиатуру некоторым из наших бета-клиентов, чтобы рассказать о своем опыте использования сервиса.
На следующей неделе давайте сосредоточимся на другой теме, мы разберемся с языком запросов TSL, и почему мы его создали и открыли