Более десяти лет мы были и остаемся лидером в области проектирования, строительства и эксплуатации центров обработки данных.
Когда мы приступили к строительству нашего первого центра обработки данных, мы столкнулись со многими проблемами, такими как: Как оптимизировать энергетический охват таких объектов? Как мы можем предотвратить потерю мощности? Как обеспечить надлежащее охлаждение? Как сделать его модульным? В первые годы эксплуатации все эти вопросы часто не давали нам спать по ночам. Тем не менее, путем проб и ошибок, упорный труд и настойчивость, мы, наконец, получили опыт, чтобы сделать наши центры обработки данных эффективным и масштабируемым. В настоящее время наши центры обработки данных — это проверенные временем объекты, которыми управляют профессиональные и преданные своему делу команды. На сегодняшний день мы являемся одним из крупнейших операторов центров обработки данных во Франции с производственной площадью более 42 000 квадратных метров и мощностью 43 МВт.
Наш новый объект DC5 — один из самых значительных проектов центров обработки данных во Франции. Предлагая более 24 МВт ИТ-мощности, DC5 состоит из 12 частных люксов, каждый из которых обеспечивает 1,8 МВт ИТ-мощности на общей площади 16 000 квадратных метров. Мы разработали это средство для масштабируемых облачных вычислений и инфраструктур больших данных.
В этом сообщении блога мы подробно рассказываем, как мы превратили здание сортировки почты в беспрецедентный гипер-масштабный центр обработки данных. Сообщение состоит из трех разделов:
- Стратегическое расположение здания
- Эффективная система охлаждения
- Сверхвысокая плотность по дизайну
Стратегическое расположение здания
Этот объект, расположенный на северо-западе Парижа, изначально был офисом по сортировке почты, который работал до 2013 года. Это здание имеет множество стратегических преимуществ, которые заставили нас принять решение преобразовать его в гипермасштабный центр обработки данных.
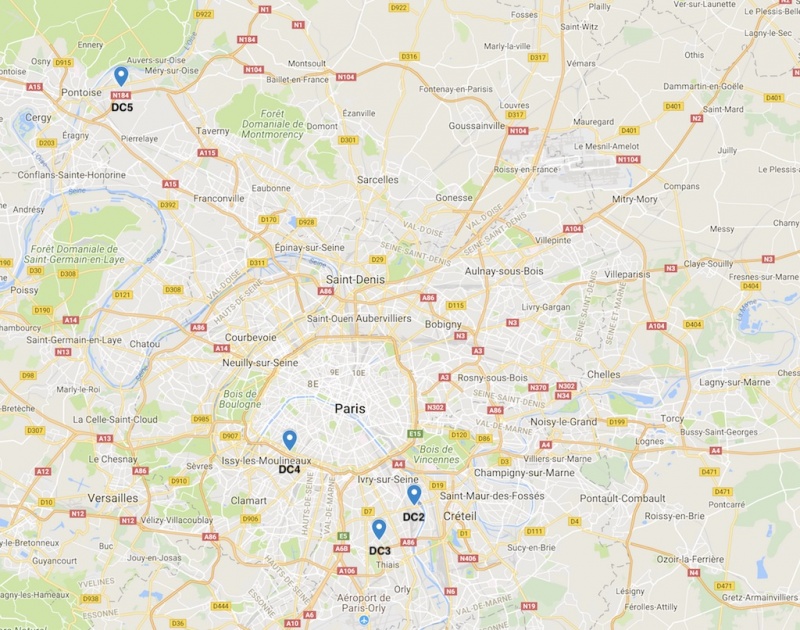
Во-первых, здание расположено в Saint-Ouen-l'Aumône в крупнейшем бизнес-парке Европы и недалеко от двух магистральных сетей Интернет операторов Tier-1. Более того, его локализация выигрывает от огромной мощности. Наконец, он находится на расстоянии более 40 км от других наших центров обработки данных, что позволяет нам предлагать (средне- и долгосрочную) отдельную зону доступности для региона Парижа.
На картинке выше вы можете увидеть географическое расположение каждого из наших центров обработки данных и расположение DC5 по сравнению с DC2, DC3 и DC4.
Эффективная система охлаждения
В DC5 мы используем систему прямого естественного охлаждения с испарительным охлаждением для охлаждения ИТ-помещений и прямое естественное охлаждение с традиционными чиллерами для охлаждения как комнат Meet Me, так и помещений UPS. Таким образом, нет настоящего кондиционера, что усложняется во Франции, потому что в стране умеренный климат. В отличие от Финляндии, температура не настолько низкая, чтобы использовать наружный воздух круглый год, и, в отличие от Испании, здесь недостаточно жарко, чтобы использовать теплообменник холодный воздух каждый день.
Благодаря использованию системы прямого естественного охлаждения с испарительным охлаждением воздух, поступающий в центр обработки данных, охлаждается перед попаданием в ИТ-помещения. Этот метод предлагает эффективную альтернативу механическому охлаждению. В DC5 испарительное охлаждение включается, когда температура воздуха превышает 30 ° C. Благодаря системе прямого естественного охлаждения с испарительным охлаждением мы можем поддерживать постоянную температуру 30 ° C ± 1 ° C в холодных коридорах.
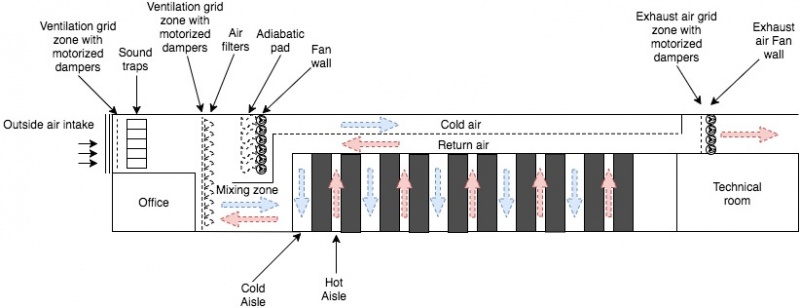
В DC5 из двух этажей один — это ИТ-комната, а другой — пленум, предназначенный для перемещения огромных объемов воздуха. Затем холодный воздух нагнетается в холодный коридор, а горячий воздух удаляется из горячего коридора.

Охлаждение, электрическое и сетевое распределение осуществляется через потолок, тогда как в традиционном дизайне распределение обычно осуществляется через пол.

Решетки воздухозаборника на картинке выше пропускают только воздух и защищают от дождя, птиц и других авантюрных животных.
Сразу за решетками воздухозаборника зона вентиляционной решетки оборудована программируемыми логическими контроллерами (ПЛК) для регулирования открытия решетки и управления воздушным потоком. Чем прохладнее воздух, тем больше закрывается решетка и наоборот.
ПЛК контролируются датчиками температуры и влажности для регулирования их открытия и использования адиабатической среды. В общей сложности мы можем обрабатывать более 400 данных в режиме реального времени для настройки и оптимизации системы с использованием искусственного интеллекта и сложных алгоритмов.
Как только воздух поступает, воздушный поток направляется ко второму ряду решеток. Их роль заключается в обеспечении равномерного распределения воздушного потока по всей фильтрующей стенке. Без этих решеток поток воздуха между низом и верхом стены будет неравным.
Чтобы заблокировать и удалить частицы воздуха в здании, мы установили воздушные фильтры класса F7.
Сразу за воздушными фильтрами стенка вентилятора выталкивает очищенный воздух в холодные коридоры с потолка.
Для охлаждения как комнат Meet Me, так и механических зон мы используем прямое естественное охлаждение с традиционными чиллерами. Эти чиллеры используются только при наружной температуре выше 20 ° C. Наша конструкция является новаторской, поскольку мы также используем ледохранилище мощностью 6 МВтч. Блок хранения льда предлагает несколько преимуществ:
- Он быстро удовлетворяет потребности в охлаждении без использования чиллеров.
- Это позволяет избежать короткого цикла на чиллерах.
- Он обеспечивает потребность в охлаждении в случае отказа чиллера.
- Это рентабельно, поскольку лед производится ночью, когда энергия дешевле.
Кроме того, систему охлаждения DC5 инновационной можно считать:
- 100% воздуха снаружи проходит адиабатический процесс, который позволяет воздуху испаряться через систему охлаждения и увлажнения.
- Он перерабатывает воздух, поступающий из горячих коридоров. Отработанное тепло смешивается с наружным воздухом в зоне смешивания для достижения заданной температуры и нагревает воздух перед его поступлением в центр обработки данных для поддержания температуры 30 ° C в холодных коридорах.
- Мы используем ледоколы для всей инфраструктуры, где требуется механическое охлаждение и низкая температура окружающей среды.
Использование прямого естественного охлаждения с испарительным охлаждением дает много преимуществ по сравнению с традиционной системой охлаждения. Эта конструкция достаточно энергоемкая и значительно снижает потери воды в отличие от чиллеров или градирен. Кроме того, его невысокая сложность сводит к минимуму риск отказа охлаждающего оборудования. Наконец, простота конструкции делает систему проще в обслуживании и эксплуатации для команды на месте.
Сверхвысокая плотность по дизайну
Мы разработали DC5 для инфраструктуры сверхвысокой плотности и гипермасштабирования. Каждая стойка может поддерживать до 6 кВт с общей емкостью 300 стоек на комнату.

В DC5 стойки получают двойное питание по двум различным каналам.
Только один путь защищен автономными ИБП и генераторами. ИБП работают только тогда, когда сеть не соответствует нашим критериям качества. Другой путь защищен только генератором. Поскольку все наши серверы двухкабельные, это абсолютно не влияет.
Такой дизайн дает нам правильный уровень резервирования с гораздо более эффективной инфраструктурой и почти 100% установленной емкости, пригодной для использования в любое время, в отличие от традиционной архитектуры 2N с максимальной 50% установленной емкости, используемой для серверов.

В случае сбоя питания путь A становится недоступным до тех пор, пока не включатся генераторы, так как он не защищен ИБП. Путь B обеспечивает бесперебойную подачу электроэнергии до тех пор, пока генераторы не будут полностью готовы к работе. Эта операция занимает менее 12 секунд. Наши генераторы — это двигатели с непрерывным режимом работы, работающие синфазно и синхронизированные с сетью. Другими словами, они могут работать одновременно с использованием сетки. Когда электросеть восстановится, нагрузка может быть передана от генераторов к сети без перебоев и отключения электроэнергии на пути А.
Вывод
Дизайн DC5 позволил нам построить очень эффективный объект со сверхвысокой плотностью размещения. Используя более простую конструкцию, мы повысили надежность. Меньшее количество компонентов означает более высокую надежность, так как меньше деталей могут выйти из строя.