Анализируй. Оптимизируй. Управляй
Выпущен новый релиз BI-системы в BILLmanager
Ранее команда разработки BILLmanager анонсировала BI-систему внутри продукта в режиме бета-тестирования для клиентов — собирала обратную связь и дорабатывала фичу. На основе полученных данных 12 ноября 2024 вышел новый релиз модуля бизнес-аналитики 0.3.0. Рассказываем, что в нем появилось.
Обновленный Apache Superset
Мы обновили Apache Superset с версии 2.1.0 на версию 4.0.2. Новая версия софта открывает новые возможности для визуализации данных: добавлены новые типы графиков, а также улучшена работа текущих; добавлены новые возможности по управлению и фильтрации графиков и дашбордов; повышена стабильность работы и внесены другие изменения.
Рассмотрим подробнее часть важных обновлений внутри Apache Superset 4.0.2 — все это поможет провайдерам создать удобный и понятный инструмент контроля за бизнесом.
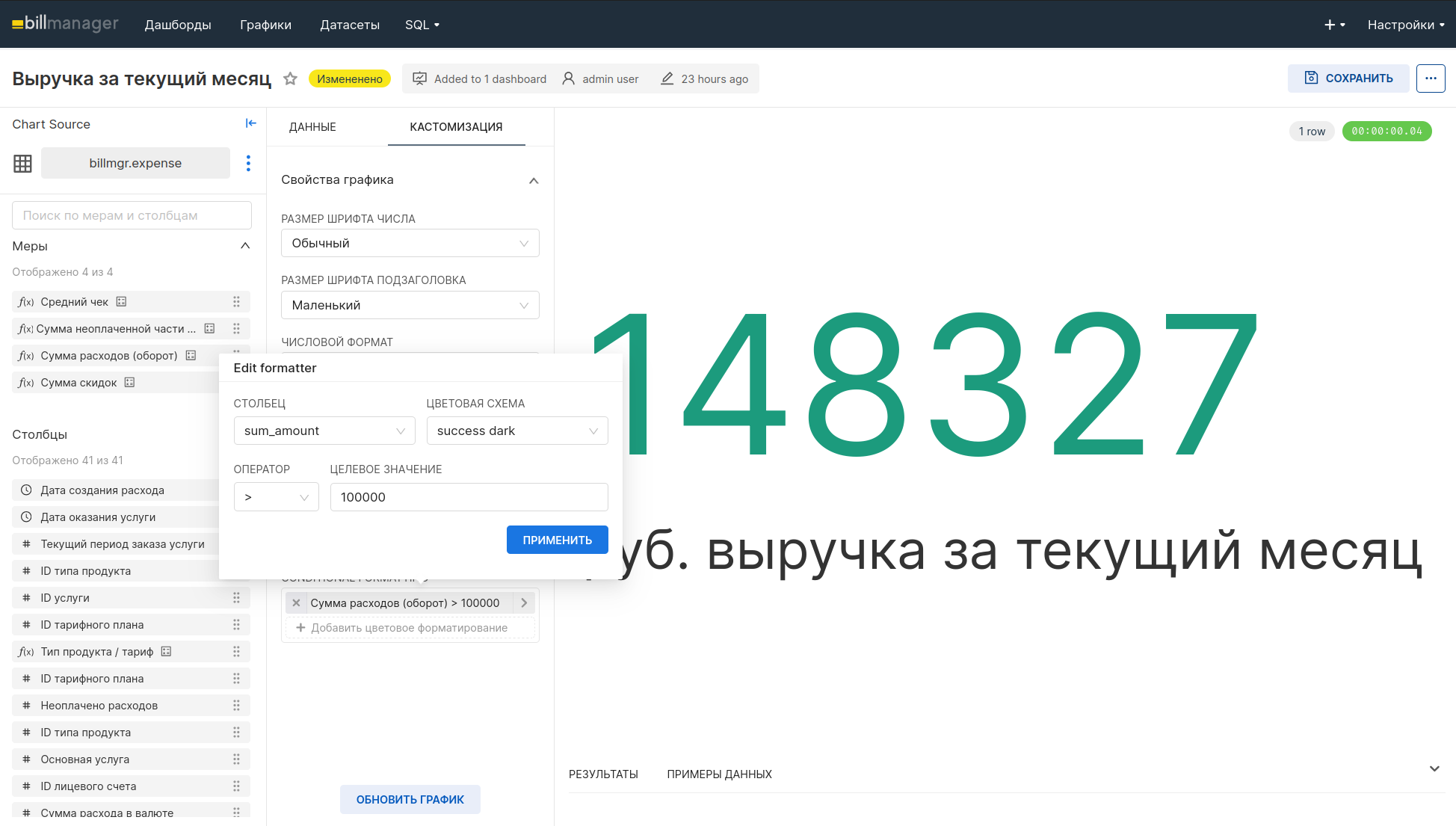
Условное форматирование в диаграммах больших чисел
Теперь вы можете выбрать столбец и задать несколько пороговых значений, чтобы применить к ним цвет состояния (красный, желтый, зеленый) на своих диаграммах больших чисел (как с использованием линии тренда, так и без нее).
Улучшенная сортировка диаграмм
Все диаграммы на основе серии Apache ECharts, в том числе ярусные варианты диаграмм, теперь поддерживают более гибкую сортировку по оси X в соответствии с совокупными метриками.

Так, если раньше сортировка выполнялась по имени, то теперь можно группировать диаграммы по значениям «минимум», «максимум», «итого» и «среднее», а также видеть результаты группировки в подсказках.

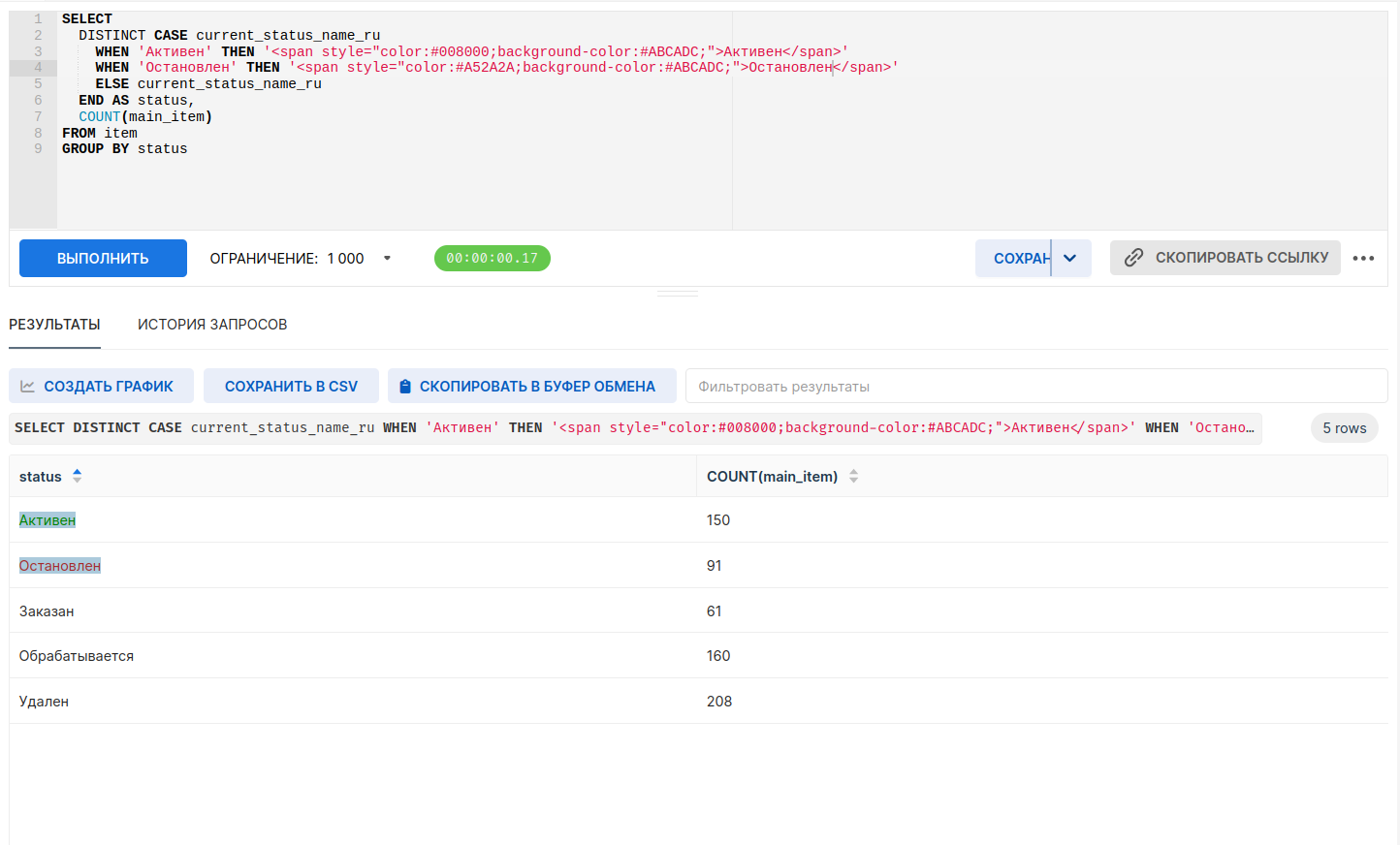
Улучшение поддержки HTML в таблицах
Apache Superset уже давно поддерживает небольшую часть функций HTML в ячейках визуализации таблицы (например, ссылки). Начиная с версии Superset 3.0, данная поддержка расширена до SQL Lab, таблиц Results и Samples модуля построения диаграмм, а также в функциях детализации. Вы можете не только использовать HTML-ссылки, но и добавлять простые HTML-файлы (например, изображения) в ячейку или обрамляющие элементы стиля вокруг содержимого ячейки (например, фоновую заливку или цвет текста для тега div).
Новые селекторы условных обозначений Inverse (обратить) и All (все)
В устаревших диаграммах предыдущих версий Superset была не очень заметная функция двойного нажатия на условные обозначения некоторых диаграмм для обращения в них серийного выбора. В этой версии используется набор функций ECharts, чтобы добавлять простые кнопки Invert и All для изменения серийного выбора, сделанного в условных обозначениях диаграммы.

Улучшения панели
Углубление/детализация по признаку
Начиная с версии 3.0.0, в Apache Superset добавлена функция детализации по признаку.
Теперь пользователь может нажать правой кнопкой мыши на элемент диаграммы и выбрать область, которую хочет детализировать. Superset применит фильтр (по области, на которую вы нажали), выполнит группировку по признаку (для выбранного вами столбца) и отобразит наложение, в котором вы увидите более подробные результаты.
drive.google.com/file/d/1kzAkQqst_p9rJH0DcHk7j8g0YBEFn9GY/view?usp=sharing
Переработанная система отображения фильтров
Диаграммы в панели, от которых выдаются перекрестные фильтры, имеют новую иконку (с подсказкой), а диаграммы в панели, которые получают перекрестные фильтры, отображают примененный(-е) фильтр(ы) во всплывающем указателе фильтров.
Кроме того, перекрестные фильтры, которые применены к панели, теперь появляются в панели фильтров в левой части экрана (вместе с диаграммой, от которой он выдается), и имеют кнопку Х для отключения фильтра.

Также в системе отображения фильтров были добавлены следующие возможности: экспорт в csv и Exel при использовании функции, новые диаграммы карт, возможность настраивать валюту по умолчанию, задавать формат чисел и др.
Полный текст информации об обновлении: preset.io/blog/superset-3-0-release-notes/#chart-improvements
Улучшение работы с функцией перетаскивания при редактировании панели
На скриншоте ниже заметно, что зона, в которую можно выполнить перетаскивание, подсвечивается в моменте действия для точного обозначения места, в котором будет размещен элемент.

Также улучшено отображение зон, в которые запрещено перетаскивание, чтобы предотвратить перемещение элементов в недопустимые места.

Улучшение работы с функцией перетаскивания при редактировании диаграммы
Теперь при перетаскивании подсвечиваются все зоны, в которые можно выполнить перетаскивание, с четким цветовым разграничением мест, которые доступны и недоступны для перетаскивания в них элементов.
Это улучшение наглядно демонстрирует потенциальные места, в которые можно выполнить перетаскивание, и помогает избежать случайного размещения в недопустимых областях. Обновление также связывает обратную связь при перемещении перетаскиваемого элемента с изменениями функционала перетаскивания в панели, обеспечивая единообразие и улучшение пользовательского опыта.

Миграция диаграмм Sunburst в ECharts
Теперь у пользователей есть возможность переместить лучевые диаграммы (Sunburst) в библиотеку графиков и диаграмм Apache ECharts.

Ранее команда разработки BILLmanager анонсировала BI-систему внутри продукта в режиме бета-тестирования для клиентов — собирала обратную связь и дорабатывала фичу. На основе полученных данных 12 ноября 2024 вышел новый релиз модуля бизнес-аналитики 0.3.0. Рассказываем, что в нем появилось.
Обновленный Apache Superset
Мы обновили Apache Superset с версии 2.1.0 на версию 4.0.2. Новая версия софта открывает новые возможности для визуализации данных: добавлены новые типы графиков, а также улучшена работа текущих; добавлены новые возможности по управлению и фильтрации графиков и дашбордов; повышена стабильность работы и внесены другие изменения.
Рассмотрим подробнее часть важных обновлений внутри Apache Superset 4.0.2 — все это поможет провайдерам создать удобный и понятный инструмент контроля за бизнесом.
Условное форматирование в диаграммах больших чисел
Теперь вы можете выбрать столбец и задать несколько пороговых значений, чтобы применить к ним цвет состояния (красный, желтый, зеленый) на своих диаграммах больших чисел (как с использованием линии тренда, так и без нее).
Улучшенная сортировка диаграмм
Все диаграммы на основе серии Apache ECharts, в том числе ярусные варианты диаграмм, теперь поддерживают более гибкую сортировку по оси X в соответствии с совокупными метриками.
Так, если раньше сортировка выполнялась по имени, то теперь можно группировать диаграммы по значениям «минимум», «максимум», «итого» и «среднее», а также видеть результаты группировки в подсказках.
Улучшение поддержки HTML в таблицах
Apache Superset уже давно поддерживает небольшую часть функций HTML в ячейках визуализации таблицы (например, ссылки). Начиная с версии Superset 3.0, данная поддержка расширена до SQL Lab, таблиц Results и Samples модуля построения диаграмм, а также в функциях детализации. Вы можете не только использовать HTML-ссылки, но и добавлять простые HTML-файлы (например, изображения) в ячейку или обрамляющие элементы стиля вокруг содержимого ячейки (например, фоновую заливку или цвет текста для тега div).
Новые селекторы условных обозначений Inverse (обратить) и All (все)
В устаревших диаграммах предыдущих версий Superset была не очень заметная функция двойного нажатия на условные обозначения некоторых диаграмм для обращения в них серийного выбора. В этой версии используется набор функций ECharts, чтобы добавлять простые кнопки Invert и All для изменения серийного выбора, сделанного в условных обозначениях диаграммы.
Улучшения панели
Углубление/детализация по признаку
Начиная с версии 3.0.0, в Apache Superset добавлена функция детализации по признаку.
Теперь пользователь может нажать правой кнопкой мыши на элемент диаграммы и выбрать область, которую хочет детализировать. Superset применит фильтр (по области, на которую вы нажали), выполнит группировку по признаку (для выбранного вами столбца) и отобразит наложение, в котором вы увидите более подробные результаты.
drive.google.com/file/d/1kzAkQqst_p9rJH0DcHk7j8g0YBEFn9GY/view?usp=sharing
Переработанная система отображения фильтров
Диаграммы в панели, от которых выдаются перекрестные фильтры, имеют новую иконку (с подсказкой), а диаграммы в панели, которые получают перекрестные фильтры, отображают примененный(-е) фильтр(ы) во всплывающем указателе фильтров.
Кроме того, перекрестные фильтры, которые применены к панели, теперь появляются в панели фильтров в левой части экрана (вместе с диаграммой, от которой он выдается), и имеют кнопку Х для отключения фильтра.
Также в системе отображения фильтров были добавлены следующие возможности: экспорт в csv и Exel при использовании функции, новые диаграммы карт, возможность настраивать валюту по умолчанию, задавать формат чисел и др.
Полный текст информации об обновлении: preset.io/blog/superset-3-0-release-notes/#chart-improvements
Улучшение работы с функцией перетаскивания при редактировании панели
На скриншоте ниже заметно, что зона, в которую можно выполнить перетаскивание, подсвечивается в моменте действия для точного обозначения места, в котором будет размещен элемент.
Также улучшено отображение зон, в которые запрещено перетаскивание, чтобы предотвратить перемещение элементов в недопустимые места.
Улучшение работы с функцией перетаскивания при редактировании диаграммы
Теперь при перетаскивании подсвечиваются все зоны, в которые можно выполнить перетаскивание, с четким цветовым разграничением мест, которые доступны и недоступны для перетаскивания в них элементов.
Это улучшение наглядно демонстрирует потенциальные места, в которые можно выполнить перетаскивание, и помогает избежать случайного размещения в недопустимых областях. Обновление также связывает обратную связь при перемещении перетаскиваемого элемента с изменениями функционала перетаскивания в панели, обеспечивая единообразие и улучшение пользовательского опыта.
Миграция диаграмм Sunburst в ECharts
Теперь у пользователей есть возможность переместить лучевые диаграммы (Sunburst) в библиотеку графиков и диаграмм Apache ECharts.