Visualize 2030: Google Cloud hosts data storytelling contest with the United Nations Foundation, the World Bank, and the Global Partnership for Sustainable Development Data
Примечание редактора: настройте завтра, вторник, 25 сентября 2018 года, в 12 часов вечера PST / 3 вечера EST, чтобы Cloud OnAir услышать от Шейна Гласса, премьер-министра для публичных наборов данных в Google Cloud, и Эндрю Уитби, научного сотрудника по данным Всемирного банка, приложений публичных наборов данных и визуализации данных в государственном секторе, а также о том, как учащиеся более высокого уровня могут участвовать в конкурсе Visualize 2030.
Узнайте больше о том, как Visualize 2030 поощряет рассказы, связанные с данными, о целях развития.
«Визуализация 2030» — это конкурс рассказов о событиях для студентов университетов, организованный в партнерстве со Всемирным банком, Фондом Организации Объединенных Наций и данными Глобального партнерства в интересах устойчивого развития. Мы приглашаем студентов на уровне колледжа и выпускников использовать Google Data Studio для анализа наборов данных из Всемирного банка и Организации Объединенных Наций и рассказать историю данных о Целях устойчивого развития ООН. Если вы активно участвуете в учебе, узнайте больше и применитесь здесь.
НПО, МПО и некоммерческие организации все чаще обращаются к аналитике данных и компьютерному обучению для достижения своих миссий в масштабе, изучают партнерские отношения и возможности для сотрудничества с частным сектором. В основе этого растущего «данных для хорошего» движения относятся междисциплинарные и международные партнерские отношения, приносящие частные и общественные организации, чтобы применять современные технологии к самым серьезным проблемам в мире.
Одной из таких возможностей для сотрудничества являются публичные наборы данных. Google Cloud запустила свою программу Public Datasets в 2016 году с целью облегчения доступа к данным и развития знаний, путем миграции более 100 наборов данных, которые анализируются во всем мире. Для каждого набора данных Google Cloud покрывает расходы на миграцию и хранение бесплатно, позволяя любому пользователю с действительной учетной записью GCP запрашивать до 1 ТБ в месяц — снова бесплатно. По сравнению с нашими наборами данных BigQuery, начиная с GSOD NOAA и заканчивая историей качества воздуха EPA, общий объем запросов данных превышает 100 петабайт. Стоит также отметить, что вертикали, такие как климат, здоровье и экономика, в частности, могут помочь некоммерческим организациям ускорить реализацию своих проектов по аналитике данных и продвинуть социальные причины.
Эти точки данных очень похожи на словарный запас: чтобы понять их, вы должны объединить их вместе в убедительное предложение. В противном случае, как и сами слова, метрики существуют только сами по себе, в строго ограниченных определениях и этимологиях. Такие предложения могут быть объединены в таблицы, группы и объединения, развиваясь в гладкие абзацы, которые сразу начинают рассказывать историю. Эта история может быть проиллюстрирована, то есть визуализирована. Визуализация данных — еще один полезный ресурс для миссионерских организаций, которые хотят внедрить аналитику данных, способствуя синтезированной и убедительной передаче информации. С помощью Google Data Studio любой пользователь может создавать интерактивные информационные панели или отчеты из BigQuery и более 500 других источников данных через экосистему сообщества сообщества Data Studio бесплатно. В то время как одна некоммерческая организация, например, Фонд Прецизионной Медицины, может использовать Data Studio для визуализации чувствительной медицинской информации, не покидая безопасную облачную среду, другая организация, такая как Harambee Youth Employment Accelerator, может использовать ее, чтобы лучше синтезировать свои данные и соответствовать безработной молодежи с заданиями в Южной Африке. Любая организация может рассказать историю, которая будет служить их цели, поддерживать их сообщество или даже изменить мир.
 datastudio.google.com/reporting/1jxiA_D8CXWu_rH0jQ2dXOGcfUJD9JrhV/page/2WOV
datastudio.google.com/reporting/1jxiA_D8CXWu_rH0jQ2dXOGcfUJD9JrhV/page/2WOV
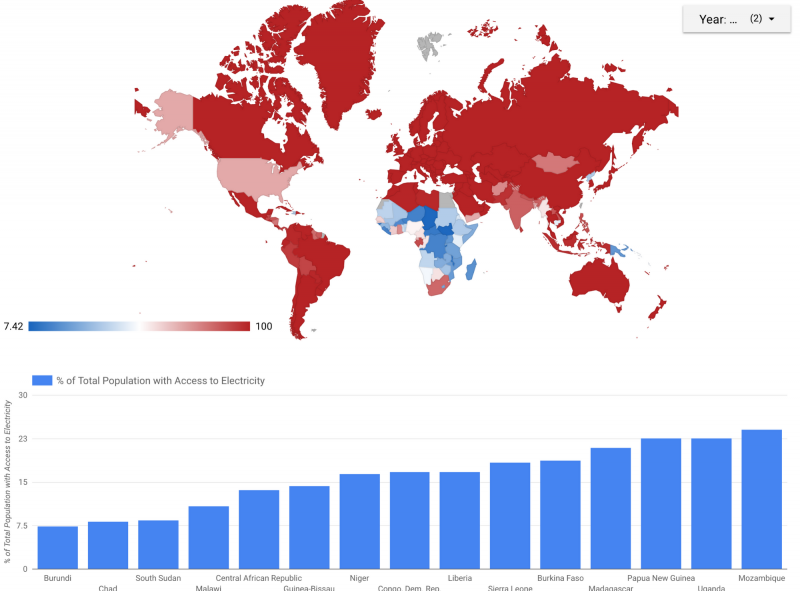
Эта визуализация предоставляет демонстрацию, которая может служить отправной точкой для пользователей, желающих визуализировать данные WDI. Глобальная тепловая карта показывает среднюю долю всего населения, имеющего доступ к электричеству по странам. На гистограмме внизу показаны 15 стран с самой низкой общей долей населения с доступом к электричеству за тот же период времени.
Именно с этим оптимизмом мы запустили еще одну инициативу в июле 2018 года: визуализировать 2030 | Истории данных для SDG (Цели устойчивого развития). В партнерстве с Фондом Организации Объединенных Наций, Всемирным банком и Глобальным партнерством по данным в области устойчивого развития мы поощряем учащихся на более высоком уровне анализировать наборы данных и рассказывать историю о повестке дня 2030 года, состоящую из 17 Устойчивого развития Цели (SDG). Эти СГД были определены Организацией Объединенных Наций и варьируются от сохранения биоразнообразия до прекращения бедности. В частности, мы просим учащихся проанализировать недавно перенесенные общедоступные наборы данных из Статистического отдела Организации Объединенных Наций и Всемирного банка и использовать Data Studio, чтобы рассказать историю данных о том, как по крайней мере две SDG влияют друг на друга и как мы можем их достичь 2030. Мы надеемся, что, работая вместе, мы можем вдохновить ученых нового поколения на то, чтобы принять меры и присоединиться к данным для хорошего движения. Если вы участвуете в университетском университете, который хочет узнать больше о Visualize 2030, посетите сайт
cloud.google.com/visualize-2030
В этом духе междисциплинарного сотрудничества мы будем участвовать в Неделе глобальных целей, которая состоится на этой неделе вокруг Генеральной Ассамблеи ООН в Нью-Йорке. Ребекка Мур, директор Google Earth Engine, будет представлять Google Earth и Google Cloud на сессии под названием «Большие данные для лучшей жизни: мобильная связь, статистика и анализ» 25 сентября вместе с представителями таких организаций, как ЮНИСЕФ и Мировая продовольственная программа (МПП), а также в Зоне СМИ SDG 27 сентября, чтобы поговорить об устойчивости и SDG.
https://cloud.google.com/blog/