Приветы!
Зима близко, но у вас есть ещё четыре дня, чтобы насладиться осенней атмосферой. Тем более, напоследок осень не оставила без приятного – уже завтра во многих магазинах стартует Чёрная пятница. Самое время купить то, о чём мечталось весь год, или начать запасаться новогодними подарками.

В ноябрьском выпуске собрали для вас всё самое интересное за текущий месяц, а также приготовили список «очень важных дел» на декабрь, чтобы проводить 2020-й со спокойной душой.
Статьи и инструкции
Как подготовить сайт к Чёрной пятнице
«День Икс» уже завтра, готовы принимать гостей? Предлагаем в помощь статью – рассказываем, что нужно сделать, чтобы всё прошло гладко, и как проверить, что ваш сайт не упадёт из-за наплыва посетителей. Пунктов много, но советуем пройтись по каждому — лучше перестраховаться, особенно в такой ответственный момент.
Как подготовить сервер к Чёрной пятнице
firstvds.ru/blog/kak-podgotovit-server-k-chernoy-pyatnice
Если вы уже закончили все приготовления, предлагаем проверить себя в нашем новом тесте. А ваш сайт готов к Черной пятнице?
firstvds.ru/content/black_friday_2020
Как перенести сайт со стороннего хостинга
Давно хотели переехать на другой тариф, но всё не доходили руки? Или, может быть, ещё не закончили переносить свои проекты со стороннего хостинга? Чтобы не откладывать на следующий год то, что можно сделать в этом, написали для вас статьи о переносах. Обратите внимание, что с других хостингов, а также на более дорогие тарифы мы переносим ваши данные совершенно бесплатно.
Несколько статей для тех, у кого кроме VDS есть выделенный сервер. Если вам становится тесно на виртуалках и вы начинаете присматриваться к дедикам – сохраняйте, пригодятся на будущее.
Как установить ОС на выделенный сервер
Хотите вручную накатить ОС (например, чтобы сделать кастомную разметку диска), но не знаете как? У нас хорошие новости – составили две подробные инструкции по установке Debian и CentOS. Как и полагается, разложили всё по полочкам и объяснили каждый шаг.
Как настроить сеть на выделенных серверах с VPU
Чтобы настроить сеть при установке гипервизора на выделенный сервер с VPU, необходимо некоторое шаманство. Но не стоит паниковать, справиться с этим можно, вооружившись нашими инструкциями. Приготовили сразу две – для Proxmox и VMmanager 6.
Новости
А теперь главные новости ноября.
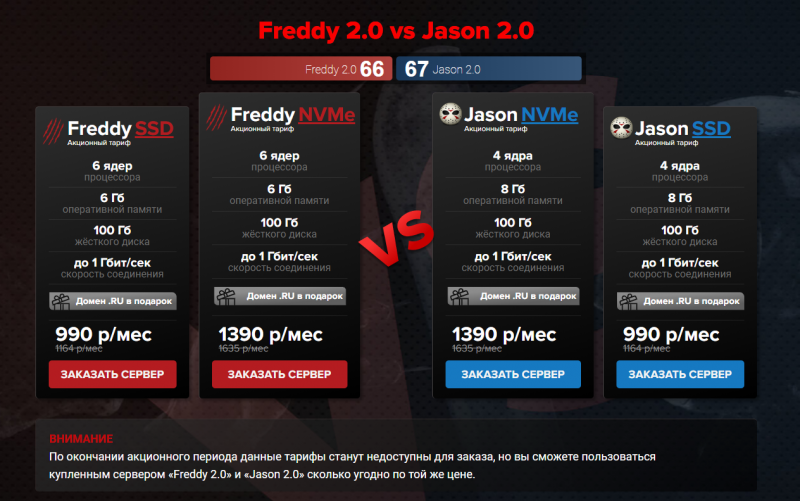
 Пятница 13-е: Фредди против Джейсона
Пятница 13-е: Фредди против Джейсона
В пятницу 13-го мы запустили самую злодейскую акцию – Фредди и Джейсон уже две недели соревнуются в нешуточной схватке. У вас есть ещё сутки, чтобы поддержать одного из злодеев и принять участие в розыгрыше призов. Для этого заказывайте сервер из линейки спецтарифов VDS Freddy 2.0 или VDS Jason 2.0.
На кону – Playstation 5, денежные призы на общую сумму 30 000 рублей, а также годовая скидка 20% на сервер для победившей стороны. Уже 30 ноября мы выйдем в прямой эфир, чтобы провести розыгрыш призов среди участников, следите за информацией в телеграм-канале TakeFirst.
firstvds.ru/friday13
 Аукцион от FirstDEDIC: дедики по максимально низким ценам
Аукцион от FirstDEDIC: дедики по максимально низким ценам
Пока растёт доллар, а вместе с ним и цены на оборудование – FirstDEDIC запустили аукцион с понижением цены. Стоимость выкупленного сервера не изменится на протяжении всего срока аренды. В акции участвуют как готовые конфигурации, так и серверы, собранные по запросам клиентов. Выберите подходящий сервер и следите за ценой, ваша задача – успеть выкупить его, пока кто-то другой вас не опередил. Подписывайтесь на специальный телеграм-канал, чтобы одним из первых узнать о новом лоте или снижении цены.
1dedic.ru/auction-2020
Совсем скоро, 6 декабря, будем праздновать 18-летие FirstVDS! Присоединяйтесь к нашему каналу и следите за новостями – готовим для вас кое-что интересное.
t.me/TakeFirstNews
Уязвимости и релизы месяца
Критическая уязвимость в системе управления контентом Drupal
В системе управления контентом Drupal обнаружена уязвимость критического уровня. Из-за некорректной проверки двойных расширений при загрузке файлов на сервер злоумышленник может удалённо выполнить на сервере произвольный PHP код. Чтобы закрыть уязвимость, обновитесь до версий Drupal 7.74, 8.9.9, 8.8.11 и 9.0.8.
Читать подробнее на opennet.ru
Сотрудники Github забыли продлить SSL-сертификат
2 ноября, примерно с 15 до 16 часов по мск, у веб-интерфейса GitHub были проблемы с вёрсткой – не отображались изображения, наблюдались проблемы с работой JavaScript-сценариев. Оказалось, что дело было в просроченном SSL-сертификате на домене githubassets.com (сервер CDN), сотрудники забыли вовремя продлить его. Несмотря на то, что сертификат основного домена github.com работал, загрузка ресурсов с незащищённого хоста была заблокирована браузерами.
Читать подробнее на opennet.ru
Атака NAT Slipstreaming для доступа к TCP/UDP-службам
Исследователь безопасности Сами Камкар представил новую атаку NAT Slipstreaming, позволяющую обойти защиту брандмауэра и получить удалённый доступ к любому UDP или TCP-порту на системе пользователя. Для этого злоумышленнику нужно, чтобы пользователь запустил JavaScript-код – например, открыл специально подготовленную страницу. При этом неважно, какой браузер использует пользователь. Для защиты разработчики Mozilla предложили ограничить возможность отправки HTTP-запросов на сетевые порты 5060 и 5061, аналогичное решение планирует принять и Chromium.
Узнать больше о механизме атаки на opennet.ru
Атака PLATYPUS на процессоры Intel и AMD
Исследователи из австрийского университета разработали новый способ атаки Platypus. Атака позволяет воссоздать данные на основе сведений, полученных непривилегированными пользователями через интерфейс мониторинга энергопотребления RAPL в процессорах Intel и AMD. Обе компании уже выпустили обновление драйверов для Linux, в котором доступ к RAPL разрешён только пользователям с правами root. Разработчики гипервизора Xen также выпустили исправление, блокирующее доступ к RAPL из гостевых систем.
Узнать больше о механизме атаки на opennet.ru