vSAN в облаке на базе VMware

Задачи хранения и доступа к данным являются болевой точкой для любой информационной системы. Даже у хорошо спроектированной системы хранения данных (далее СХД) в процессе эксплуатации выявляются проблемы, связанные со снижением производительности. Отдельного внимания заслуживает комплекс проблем масштабирования, когда количество задействованных ресурсов приближается к установленным лимитам, заложенным разработчиками СХД.
Фундаментальной причиной возникновения этих проблем является традиционная архитектура, основанная на жесткой привязке к аппаратным характеристикам используемых устройств хранения данных. Большинство клиентов до сих пор выбирают способ хранения и доступа к данным с учетом характеристик физических интерфейсов (SAS / SATA / SCSI), а не реальных потребностей используемых приложений.
Еще десяток лет назад это было логичным решением. Системные администраторы тщательно выбирали накопители информации с требуемой спецификацией, например SATA/SAS, и рассчитывали на получение уровня производительности, исходя из аппаратных возможностей дисковых контроллеров. Борьба шла и за объемы кэшей RAID-контроллеров и за опции, предотвращающие потерю данных. Сейчас такой подход к решению проблемы не является оптимальным.
В текущих условиях при выборе СХД имеет смысл отталкиваться не от физических интерфейсов, а от производительности, выраженной в IOPS (количество операций ввода-вывода в секунду). Использование виртуализации позволяет гибко использовать существующие аппаратные ресурсы и гарантировать требуемый уровень производительности. Мы со своей стороны готовы предоставить ресурсы с теми характеристиками, которые реально необходимы приложению.
Виртуализация СХД
С развитием систем виртуализации требовалось найти инновационное решение для хранения и доступа к данным, одновременно обеспечивая отказоустойчивость. Это стало отправной точкой для создания SDS (Software-Defined Storage). Чтобы удовлетворять бизнес-потребностям, такие хранилища проектировались с разделением программного и аппаратного обеспечения.
Архитектура SDS в корне отличается от традиционной. Логика хранения стала абстрагироваться на программном уровне. Организация хранения стала проще за счет унификации и виртуализации каждого из компонентов такой системы.
Что же является основным фактором, препятствующим внедрению SDS повсеместно? Этим фактором чаще всего оказывается некорректная оценка потребностей используемых приложений и неверная оценка рисков. Для бизнеса выбор решения зависит от затрат на внедрение, исходя из текущих потребляемых ресурсов. Мало кто думает — что будет, когда объем информации и требуемая производительность превысит возможности выбранной архитектуры. Мышление на базе методологического принципа «не следует множить сущее без необходимости», более известного как «лезвие Оккама», обуславливает выбор в пользу традиционных решений.
Лишь немногие понимают, что необходимость в масштабировании и надежности хранения данных важнее, чем кажется на первый взгляд. Информация это ресурс, а следовательно, риск ее потери необходимо страховать. Что будет, когда традиционная СХД выйдет из строя? Потребуется воспользоваться гарантией либо купить новое оборудование. А если СХД снята с производства или у нее закончился «срок жизни» (так называемый EOL — End-of-Life)? Это может стать «черным днем» для любой организации, которая не сможет продолжать использовать привычные собственные сервисы.
Не существует систем, которые бы не имели ни одной точки отказа. Зато есть системы, которые способны без проблем пережить отказ одного или нескольких компонентов. И виртуальные, и традиционные СХД создавались с учетом того, что рано или поздно произойдет сбой. Вот только «лимит прочности» традиционных СХД заложен аппаратно, а вот в виртуальных СХД он определяется в программном слое.
Интеграция
Кардинальные перемены в IT-инфраструктуре всегда нежелательное явление, чреватое простоями и потерей средств. Только плавное внедрение новых решений дает возможность избежать негативных последствий и улучшить работу сервисов. Именно поэтому Selectel разработал и запустил облако на базе VMware, признанного лидера на рынке систем виртуализации. Созданная нами услуга позволит каждой компании решить весь комплекс инфраструктурных задач, в том числе и по хранению данных.
Расскажем о том, как именно мы решили вопрос с выбором системы хранения данных, а также какие преимущества дал нам этот выбор. Разумеется, что рассматривались как традиционные системы хранения данных, так и SDS. Чтобы четко понимать все аспекты эксплуатации и риски, предлагаем детально углубиться в тему.
Еще на этапе проектирования к СХД предъявлялись следующие требования:
- отказоустойчивость;
- производительность;
- масштабирование;
- возможность гарантировать скорость работы;
- корректная работа в экосистеме VMware.
На рынке SDS присутствует несколько программных решений, которые бы подошли нам для построения облака на базе VMware vSphere. Среди этих решений можно отметить:
- Dell EMC ScaleIO;
- Datacore Hyper-converged Virtual SAN;
- HPE StoreVirtual.
Архитектура
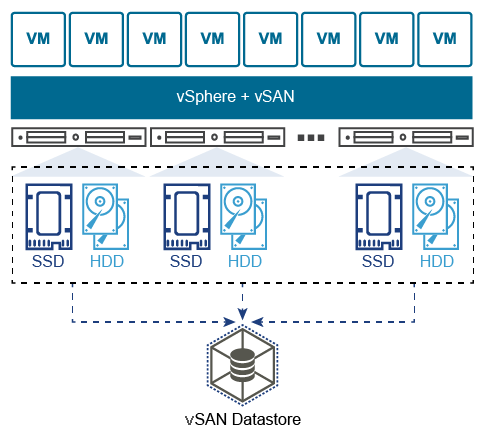
В отличие от традиционных СХД вся информация не хранится в какой-то одной точке. Данные виртуальных машин равномерно «размазаны» между всеми хостами, а масштабирование осуществляется добавлением хостов или установкой на них дополнительных дисковых накопителей. Поддерживается два варианта конфигурации:
- AllFlash-конфигурация (только твердотельные накопители, как для хранения данных, так и для кэша);
- Hybrid-конфигурация (магнитные накопители для хранения данных и твердотельные для кэша).
- отсутствие привязки к производителю оборудования;
- повышенная отказоустойчивость;
- обеспечение целостности данных в случае сбоя;
- единый центр управления из консоли vSphere;
- удобное горизонтальное и вертикальное масштабирование.
Сеть
Традиционная трехуровневая сетевая модель (ядро / агрегация / доступ) имеет ряд существенных недостатков. Ярким примером являются ограничения Spanning-Tree протоколов.
В модели Spine-Leaf используется только два уровня, что дает следующие преимущества:
- предсказуемое расстояние между устройствами;
- трафик идет по наилучшему маршруту;
- легкость масштабирования;
- исключение ограничений протоколов уровня L2.
Физическое соединение обеспечивается с помощью нескольких 10GbE-линков на каждый сервер, пропускная способность которых объединяется с помощью протокола агрегации. Таким образом, каждый физический хост получает высокую скорость доступа ко всем объектам хранилища.
Обмен данными реализуется с помощью проприетарного протокола, созданного VMware, позволяющего обеспечить быструю и надежную работу сети хранения на Ethernet-транспорте (от 10GbE и выше).
Переход к объектной модели хранения данных позволил гибко подстраивать использование хранилища в соответствие с требованиями заказчиков. Все данные хранятся в виде объектов, которые определенным образом распределяются по хостам кластера. Уточним значения некоторых параметров, которыми можно управлять.
Отказоустойчивость
- 1. FTT (Failures To Tolerate). Обозначает количество отказов хостов, которые кластер способен обработать, не прерывая штатной работы.
- 2. FTM (Failure Tolerance Method ). Метод обеспечения отказоустойчивости на уровне дисков.
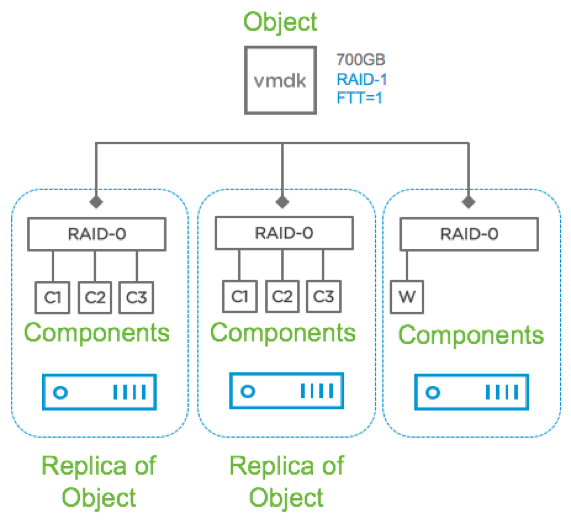
Представляет собой полное дублирование объекта, причем реплики всегда находятся на разных физических хостах. Ближайшим аналогом такого метода является RAID-1. Его использование позволяет кластеру штатно обработать до трех отказов любых компонентов (диски, хосты, потеря сети и прочее). Этот параметр настраивается посредством задания опции FTT.
По-умолчанию эта опция имеет значение 1, при этом для объекта создается 1 реплика (всего 2 экземпляра на разных хостах). При увеличении значения, количество экземпляров будет составлять N+1. Таким образом, при максимальном значении FTT=3 на разных хостах будут находиться 4 экземпляра объекта.
Такой метод позволяет достичь максимальной производительности в ущерб эффективности использования дискового пространства. Допускается использование как в гибридной, так и в AllFlash-конфигурации.
Erasure Coding (аналог RAID 5/6)
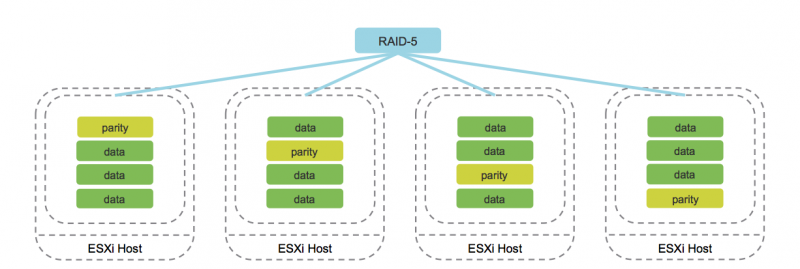
Работа данного метода поддерживается исключительно на AllFlash-конфигурациях. В процессе записи каждого объекта вычисляются соответствующие блоки четности, позволяющие однозначно восстановить данные при возникновении сбоя. Такой подход существенно экономит дисковое пространство по сравнению с Mirroring.
Разумеется, работа подобного метода повышает накладные расходы, которые выражаются в снижении производительности. Тем не менее, с учетом производительности AllFlash-конфигурации, этот недостаток нивелируется, делая использование Erasure Coding приемлемым вариантом для большинства задач.
Кроме того, VMware vSAN вводит понятие «доменов отказа», представляющих собой логическое группирование серверных стоек или дисковых корзин. Как только необходимые элементы сгруппированы, это приводит к распределению данных по разным узлам с учетом доменов отказа. Это позволяет кластеру пережить потерю целого домена, поскольку все соответствующие реплики объектов будут располагаться на других хостах в другом домене отказа.
Минимальным доменом отказа является дисковая группа, представляющая собой логически связанные дисковые накопители. Каждая дисковая группа содержит в себе носители двух типов — cache и capacity. В качестве cache-носителей система позволяет использовать только твердотельные диски, а в качестве capacity-носителей могут выступать как магнитные, так и твердотельные диски. Кэширующие носители помогают ускорить работу магнитных дисков и уменьшить задержку при доступе к данным.
Реализация
Поговорим о том, какие ограничения существуют в архитектуре VMware vSAN и зачем они нужны. Вне зависимости от используемых аппаратных платформ, архитектура предусматривает следующие ограничения:
- не более 5 дисковых групп на хост;
- не более 7 capacity-носителей в дисковой группе;
- не более 1 cache-носителя в дисковой группе;
- не более 35 capacity-носителей на хост;
- не более 9000 компонентов на хост (включая witness-компоненты);
- не более 64 хостов в кластере;
- не более 1 vSAN-datastore на кластер.
Помимо указанных ограничений следует помнить одну важную особенность. Не рекомендуется заполнять более 70% общего объема хранилища. Дело в том, что при достижении 80% автоматически запускается механизм ребалансировки, и система хранения начинает перераспределять данные по всем хостам кластера. Процедура достаточно ресурсоемкая и может серьезно сказаться на производительности дисковой подсистемы.
Чтобы удовлетворить потребности самых разных клиентов, нами было реализовано три пула хранения данных для удобства использования в различных сценариях. Давайте рассмотрим каждый из них по порядку.
Пул с быстрыми дисками
Приоритетом для создания этого пула было получить хранилище, которое обеспечит максимальную производительность для размещения высоконагруженных систем. Серверы из этого пула используют пару Intel P4600 в качестве кэша и 10 Intel P3520 для хранения данных. Кэш в этом пуле используется таким образом, чтобы чтение данных происходило напрямую с носителей, а операции записи происходили через кэш.
Для увеличения полезной емкости и обеспечения отказоустойчивости используется модель хранения данных под названием Erasure Coding. Такая модель схожа с обычным массивом RAID 5/6, но на уровне объектного хранилища. Чтобы исключить вероятность повреждения данных, vSAN использует механизм вычисления контрольных сумм для каждого блока данных, размером 4К.
Проверка осуществляется в фоновом режиме во время операций чтения/записи, а также для «холодных» данных, доступ к которым не запрашивался в течение года. При выявлении несовпадения контрольных сумм, а следовательно, повреждения данных, vSAN автоматически восстановит файлы путем перезаписи.
Пул с гибридными дисками
В случае с этим пулом, его основной задачей является предоставление большого объема данных, обеспечивая при этом хороший уровень отказоустойчивости. Для многих задач скорость доступа к данным не является приоритетной, гораздо более важен объем, а еще стоимость хранения. Использование твердотельных накопителей в качестве такого хранилища будет иметь необоснованно высокую стоимость.
Этот фактор и послужил причиной создания пула, который представляет собой гибрид из кэширующих твердотельных накопителей (как и в других пулах это Intel P4600) и жестких дисков корпоративного уровня, разработанные компанией HGST. Гибридная схема работы ускоряет доступ к часто запрашиваемым данным, за счет кэширования операций чтения и записи.
На логическом уровне данные зеркалируются для исключения потери в случае сбоя оборудования. Каждый объект разбивается на идентичные компоненты и система распределяет их по разным хостам.
Пул с Disaster Recovery
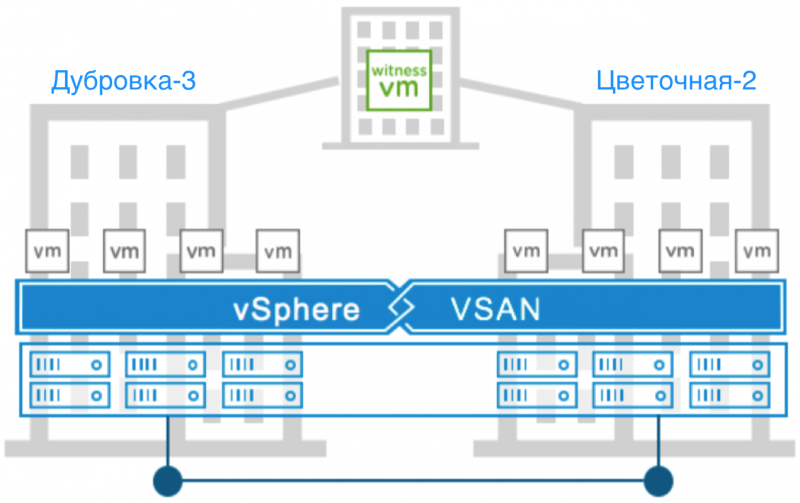
Основной задачей пула является достижение максимального уровня отказоустойчивости и производительности. Задействование технологии Stretched vSAN позволило нам разнести хранилище между дата-центрами Цветочная-2 в Санкт-Петербурге и Дубровка-3 в Ленинградской области. Каждый сервер из данного пула оснащен парой емких и высокоскоростных накопителей Intel® P4600 для работы кэша и по 6 штук Intel® P3520 для хранения данных. На логическом уровне это 2 дисковые группы на хост.
AllFlash-конфигурация лишена серьезного недостатка — резкого падения IOPS и увеличения очереди дисковых запросов при увеличенном объеме операций произвольного доступа к данным. Так же, как и в пуле с быстрыми дисками операции записи проходят через кэш, а чтение осуществляется напрямую.
Теперь о главном отличии от остальных пулов. Данные каждой виртуальной машины зеркалируются внутри одного дата-центра и при этом синхронно реплицируются в другой, принадлежащий нам, дата-центр. Таким образом, даже серьезная авария, такая как полное нарушение связности между дата-центрами не станет проблемой. Даже полная потеря дата-центра не затронет данные.
Авария с полным отказом площадки — ситуация достаточно редкая, однако vSAN с честью может ее пережить, не потеряв данные. Гости проводимого нами мероприятия SelectelTechDay 2018 смогли собственными глазами увидеть, как кластер Stretched vSAN пережил полный отказ площадки. Виртуальные машины стали доступны уже через одну минуту после того, как все серверы на одной из площадок были выключены по питанию. Все механизмы сработали именно так, как было запланировано, а данные остались нетронутыми.
Отказ от привычной архитектуры хранения данных влечет за собой массу изменений. Одним из таких изменений стало появление новых виртуальных «сущностей», к которым относятся и witness appliance. Смысл этого решения в том, чтобы отслеживать процесс записи реплик данных и определять, какая из них является актуальной. При этом самих данных на witness-компонентах не хранится, только метаданные о процессе записи.
Этот механизм вступает в действие в случае аварии, когда в процессе репликации происходит сбой, результатом которого является рассинхронизация реплик.
Чтобы определить, какая из них содержит актуальную информацию, используется механизм определения кворума. Каждый компонент обладает «правом голоса», и ему присваивается некоторое количество голосов (1 и более). Такое же «право голоса» имеют и witness-компоненты, играющие роль арбитров, при возникновении спорной ситуации.
Кворум достигается только в том случае, когда для объекта доступна полная реплика и количество текущих «голосов» составляет более 50%.
Заключение
Выбор VMware vSAN, как системы хранения данных, стал для нас достаточно важным решением. Этот вариант прошел нагрузочное тестирование и проверку отказоустойчивости, прежде чем был включен в проект нашего облака на базе VMware.
По результатам тестов стало ясно, что заявленный функционал работает как положено и удовлетворяет всем требованиям нашей облачной инфраструктуры.
https://selectel.ru